Ŀ¼
һ��������
������Ϊ�˵����ٶȲ�һ�µ�����������ͬ�����ʵ��ٶ�,���м���ٶȽ�����һ����������,����CPU��һ�������������DZ�����CPU����������ʵ�����,�ڴ��DZ���CPU��������Ӳ�̵�����,����Ӳ��Ҳ�д�С��һ�Ļ���,������������������raid ����Ҳ����,����Ϊ������CPU ����Ӳ�����ݵ�Ŀ��,��ΪCPU���ٶ�̫����,CPU��Ҫ����������Ӳ�����������ڶ�ʱ��������CPU������,���CPU���桢�ڴ桢Raid �������Լ�Ӳ�̻������һ���̶���������CPU����������,��CPU �ӻ����ȡ���ݿ��Դ�����CPU�Ĺ���Ч�ʡ�
1.1 ϵͳ����
buffer: ����Ҳ��д����,һ������д����,���Խ�������д���ڴ���д�����,buffer һ������д����,���ڽ����ͬ���ʵ��ٶȲ�һ�µĻ���,�Ƚ�������ʱд�뵽���Լ�����ĵط�,�����д���ٶ�,CPU���������д���ڴ�Ĵ��̻�����,Ȼ�����Ϊ�����Ѿ�д����ɿ�,Ȼ�����ں��ں�����ʱ����д�����,���Է�����ͻȻ�ϵ�ᶪʧ�ڴ��еIJ������ݡ�
cache: ����Ҳ�ж�����,һ�����ڶ�����,CPU���ļ����ڴ��,����ڴ�û�о��ȴ�Ӳ�̶����ڴ��ٶ���CPU,����ҪƵ����ȡ�����ݷ������Լ�����Ļ�������,�´ζ�ȡ��ʱ�ɿ��ٶ�ȡ��
1.2 ���汣��λ�ü��ֲ�ṹ
�û���: �����DNS����,Ӧ�ó���DNS����,����ϵͳDNS����ͻ���
������: CDN,�����������
Web��: Web����������
Ӧ�ò� : ҳ�澲̬��
���ݲ�: �ֲ�ʽ����,���ݿ�
ϵͳ��: ����ϵͳcache
������: ����cache,,Raid Cache
1.2.1 DNS����
�������DNS����Ĭ��Ϊ60��,��60��֮���ڷ���ͬһ�������Ͳ��ڽ���DNS����
1.2.2 Ӧ�ò㻺��
1��Nginx��PHP��web�����������Ӧ�û����Լ�����Ӧ�û�����,������Щ����������,����:PHP/Python/Java����ֱ������,��Ҫ�ȱ�����ֽ���,���ֽ�����Ҫ����������Ϊ������֮�����ִ��,����ֽ���Ҳ��һ�ֻ���,��ʱ����ֳ���������ߺ��ֽ���û�и��µ���������һ�������°�ǰ,��Ҫ�Ƚ�Ӧ�û�������,�������°档
2������������ö�̬ҳ�澲̬������,���ٷ���,����:���������ݿ�����ݵĶ�̬ҳ��,��ǰ�ó������ɾ�̬ҳ���ļ�html ������վ����Ʒ����,������Ϣ��ʵʱ���ݵȽԿ����ô˼���ʵ�֡�
1.2.3 ���ݲ㻺��
�ֲ�ʽ�������
1.Redis
2.Memcached
���ݿ�
1.MySQL ��ѯ����
2.innodb���桢MYISAM����
1.2.4 Ӳ������
1.CPU����(L1�����ݻ����L1��ָ���)���������桢��������
2.���̻���:Disk Cache
3.�������л���: Raid Cache,��ʹ�õ�ط�ֹ�ϵ綪ʧ����
���� ��ϵ���ݿ�ͷǹ�ϵ���ݿ�
2.1 ʲô�ǹ�ϵ�����ݿ�
1.һ���ṹ�������ݿ�,�����ڹ�ϵģ�ͻ����� (��ά����ģ��)������
2.һ�������ڼ�¼
3.SQL���(�����ݲ�ѯ����):
����һ�ֻ��ڹ�ϵ�����ݿ������,����ִ�жԹ�ϵ�����ݿ������ݵļ����Ͳ����� ����:Oracle��MySQL��SQL Server��Microsoft Access��DB2��
2.2 ʲô�Ƿǹ�ϵ�����ݿ�
1.NoSQL (NoSQL=NotOnlySQL), ��˼�ǡ���������SQL",�Ƿǹ�ϵ�����ݿ���ܳơ�
2.���������Ĺ�ϵ�����ݿ�������ݿ�,����Ϊ�Ƿǹ�ϵ�͡�
3.������NoSQL���ݿ���Redis��MongBD��Hbase��Memcached�ȡ�
2.3 �ǹ�ϵ�����ݿ�IJ�������
1.High performance���������ݿ�߲�����д����
2.Huge Storage�����Ժ������ݸ�Ч�洢���������
3.High Scalability && High Availability���������ݿ�߿���չ����߿���������
2.4 ��ϵ�����ݿ�ͷǹ�ϵ�����ݿ�����
(1)���ݴ洢��ʽ��ͬ
1.��ϵ�ͺͷǹ�ϵ�����ݿ����Ҫ���������ݴ洢�ķ�ʽ��
��ϵ��������Ȼ���DZ���ʽ��,��˴洢�����ݱ����к����С����ݱ����Ա˴˹���Э���洢,Ҳ��������ȡ���ݡ�
2.�ǹ�ϵ�������෴,���ݲ��ʺϴ洢�����ݱ����к�����,���Ǵ�������һ�𡣷ǹ�ϵ������ͨ���洢�����ݼ���,�����ĵ�����ֵ�Ի���ͼ�ṹ��������ݼ���������ѡ�����ݴ洢����ȡ��ʽ����ҪӰ�����ء�
��ϵ��:�����ڹ�ϵģ��E-Rͼ,ͬʱ�Ա���ʽ�ķ�ʽ�洢����
�ǹ�ϵ��:�����Ա�����ʽ�洢֮��,ͨ�����Դ�����ʽ�����һһ����д洢����
(2)��չ��ʽ��ͬ
SQL��NoSQL���ݿ����IJ�����������չ��ʽ��,Ҫ֧����������������ȻҪ��չ��
1.Ҫ֧�ָ��ಢ����,SQL���ݿ���������չ,Ҳ����˵��ߴ�������,ʹ���ٶȸ����ٵļ����,����������ͬ�����ݼ������ˡ���Ϊ���ݴ洢�ڹ�ϵ����,����������ƿ�������漰�ܶ����,�ⶼ��Ҫͨ���������������ͷ�����ȻSQL���ݿ��кܴ���չ�ռ�,�����տ϶���ﵽ������չ�����ޡ�
2.��NoSQL���ݿ��Ǻ�����չ�ġ���Ϊ�ǹ�ϵ�����ݴ洢��Ȼ���Ƿֲ�ʽ��,NoSQL���ݿ����չ����ͨ������Դ�����Ӹ�����ͨ�����ݿ������(�ڵ�) ���ֵ����ء�
��ϵ:����(��Ȼ����ʽ)
�ǹ�:����(��Ȼ�ֲ�ʽ)
(3) �������Ե�֧�ֲ�ͬ
������ݲ�����Ҫ�������Ի��߸������ݲ�ѯ��Ҫ����ִ�мƻ�,��ô��ͳ��SQL���ݿ�����ܺ��ȶ��Է��濼�������ѡ��SQL���ݿ�֧�ֶ�����ԭ����ϸ���ȿ���,�������ڻع�������ȻNoSQL���ݿ�Ҳ����ʹ���������,���ȶ��Է���û����ϵ�����ݿ�Ƚ�,�����������������ļ�ֵ���ڲ�������չ�Ժʹ��������������档
��ϵ��:�ر��ʺϸ�������Ҫ�����Ҫ����ִ�мƻ������� �ǹ�ϵ:�˴�����������,���ֵ�����ڸ���չ�Ժʹ���������������
2.5 ��ϵ�����ݿ⡢�ǹ�ϵ�����ݿ��
��ϵ�����ݿ�: ʵ���C> ���ݿ�C> ��(table)�C> ��¼��(row)�������ֶ�(column)
�ǹ�ϵ�����ݿ�: ʵ���C> ���ݿ�C> ����(collection)�C> ��ֵ��(key-value) �ǹ�ϵ�����ݿⲻ��Ҫ�ֶ������ݿ�ͼ���(��)��
�� ��Redis
3.1 ���
1��Redis��һ����Դ�ġ�ʹ��C���Ա�д��NoSOL���ݿ�,Redis�����������ǵ�����ģ�͡�
2��Redis�����ڴ����в�֧�ֳ־û�(֧�ִ洢�ڴ���),����key-value(��ֵ��)�Ĵ洢��ʽ,��Ŀǰ�ֲ�ʽ�ܹ��в��ɻ�ȱ��һ����
3��Redis������һ̨�������Ͽ���ͬʱ�������Redis����,Redis��ʵ�ʴ����ٶ�������ȫ�����������̵�ִ��Ч�ʡ�
4�����ڷ�������ֻ����һ��Redis����, ������ͻ���ͬʱ����ʱ, �������Ĵ��������ǻ���һ���̶ȵ��½�;
5������ͬһ̨�������Ͽ��� ���Redis����, Redis����߲�������������ͬʱ�����������CPU��ɺܴ�ѹ���� ����ʵ������������, ��Ҫ����ʵ�ʵ������������������ٸ�Redis���̡� (һ�㽨�鿪��2��,�������ݺͿ��߲���)
6�����Ը߲���Ҫ�����һЩ, ���ܻῼ����ͬһ̨�������Ͽ���������̡� ��CPU��Դ�ȽϽ���,���õ����̼��ɡ�
3.2 Redis�ŵ�
1�����м��ߵ����ݶ�д�ٶ�:���ݶ�ȡ���ٶ���߿ɴﵽ110000��/s,����д���ٶ���߿ɴﵽ81000��/s����
2.֧�ַḻ����������:֧��Key-value��strings��Lists��Hashes��Sets��Ordered Sets���������Ͳ���
ps :
string �ַ���(����Ϊ���Ρ�������ַ���,ͳ��ΪԪ��)
list�б�:(ʵ�ֶ���,Ԫ�ز�Ψһ,�ȳ��ȳ�ԭ��)
set ����:(������ͬ��Ԫ��)
hash hashɢ��ֵ: (hash��key������Ψһ�� )
set /ordered sets ����/����
3��֧�����ݵij־û�:���Խ��ڴ��е����ݱ����ڴ�����,������ʱ������ٴμ��ؽ���ʹ�á�
4��ԭ����:Redis���� ��������ԭ���Եġ�
5��֧�����ݱ���:��master-salve ģʽ�����ݱ��ݡ�
3.3 ���߳�
Redis 6.0�汾ǰһֱ�ǵ��̷߳�ʽ�����û�������
���߳�Ϊ����˿�?
1�����ڴ�
2��������
3�������߳��л��;�̬����
3.4 redis �Ա� memcached
1��֧�����ݵij־û�:���Խ��ڴ��е����ݱ����ڴ�����,����redis������߷�����֮����Դӱ����ļ��лָ����ݵ��ڴ����ʹ��
2��֧�ָ������������:֧��string(�ַ���)��hash(��ϣ����)��list(�б�)��set(����)��zset(����)
3��֧�����ݵı���:����ʵ�����������ݵ�master-slaveģʽ�����ݱ���,����Ҳ֧��ʹ�ÿ���+AOF
4��֧�ָ����value����:memcache����key value���ֻ֧��1MB,��redis���֧��512MB(���������鳬��2M,������Ӱ��)
5����Redis6�汾ǰ,Redis �ǵ��߳�,��memcached�Ƕ��߳�,���Ե��������û��memcached ������,���ܸ���,��redis ֧�ֲַ�ʽ��Ⱥ��ʵ�ָ��ߵIJ���,��Redisʵ������ʵ������
6��֧�ּ�Ⱥ������չ:����redis cluster�ĺ�����չ,����ʵ�ֲַ�ʽ��Ⱥ,����������ܺ����ݰ�ȫ��
7�����ǻ��� C ���Կ���
memcached redis
���� key-value key-value
���ڲ��� ֧�� ֧��
�������� ��һ�������� �����������
�־û� ��֧�� ֧��
���Ӹ��� ��֧�� ֧��
�����ڴ� ��֧�� ֧��
�ġ� Redis��װ����
4.1��������
systemctl stop firewalld
setenforce 0
yum install -y gcc gcc-c++ make
#��redis-5.0.7.tar.gzѹ�����ϴ���/optĿ¼��
tar zxvf redis-5.0.7.tar.gz -C /opt/
cd /opt/redis-5.0.7/
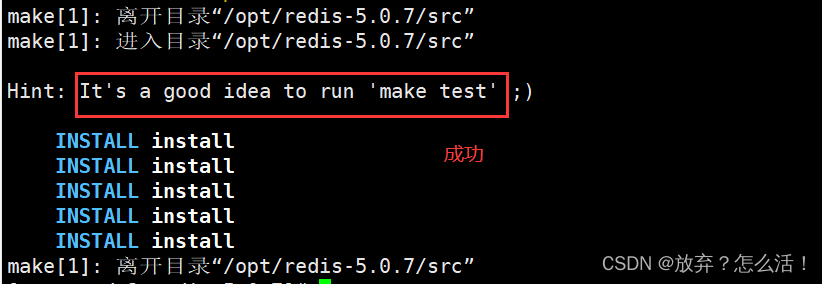
make
make PREFIX=/usr/local/redis install
#����RedisԴ�����ֱ���ṩ��Makefile�ļ�,�����ڽ�ѹ����������,������ִ��./configure��������,��ֱ��ִ��make��makeinstall������а�װ
#ִ���������ṩ��installserver.sh�ű��ļ�����Redis��������Ҫ����������ļ�
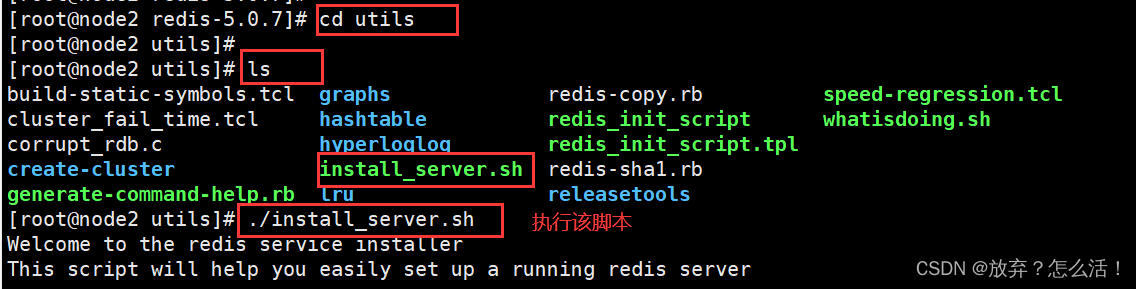
cd /opt/redis-5.0.7/utils
./install_server.sh
......
#һֱ�س�.
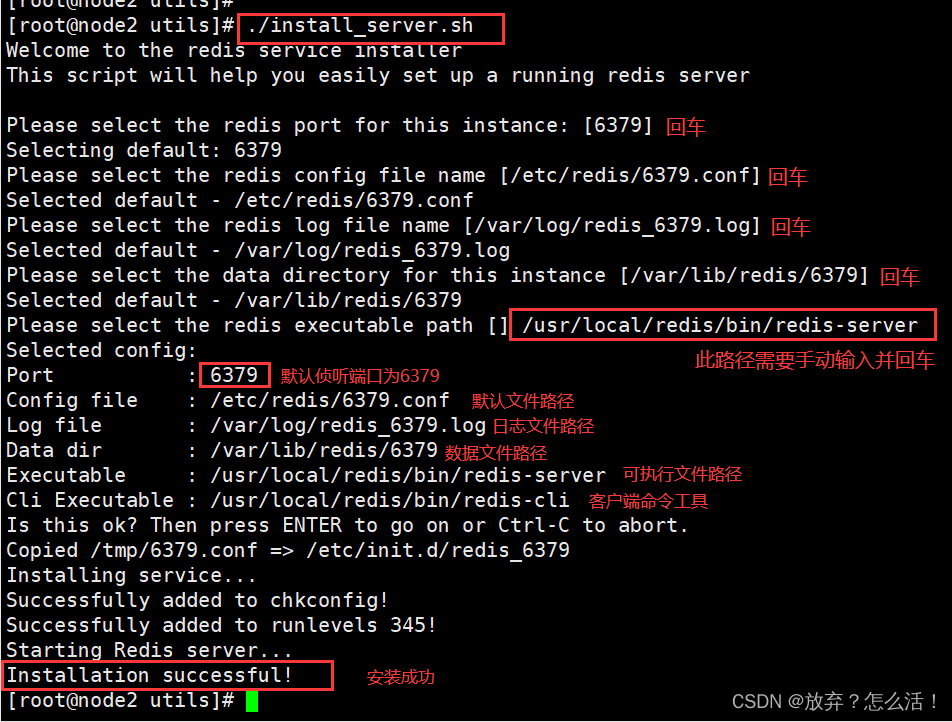
Please select the redis executable path [/usr/local/bin/redis-server]
/usr/local/redis/bin/redis-server
#��Ҫ�ֶ���Ϊ/usr/local/redis/bin/redis-server ע��Ҫһ������ȷ����
Selected config:
Port : 6379 #Ĭ�������˿�Ϊ6379
Config file : /etc/redis/6379.conf #�����ļ�·��
Log file : /var/log/redis_6379.log #��־�ļ�·��
Data dir : /var/lib/redis/6379 #�����ļ�·��
Executable : /usr/local/redis/bin/redis-server #��ִ���ļ�·��
Cli Executable : /usr/local/bin/redis-cli #�ͻ��������
#��redis�Ŀ�ִ�г����ļ�����·������������Ŀ¼�б���ϵͳʶ��
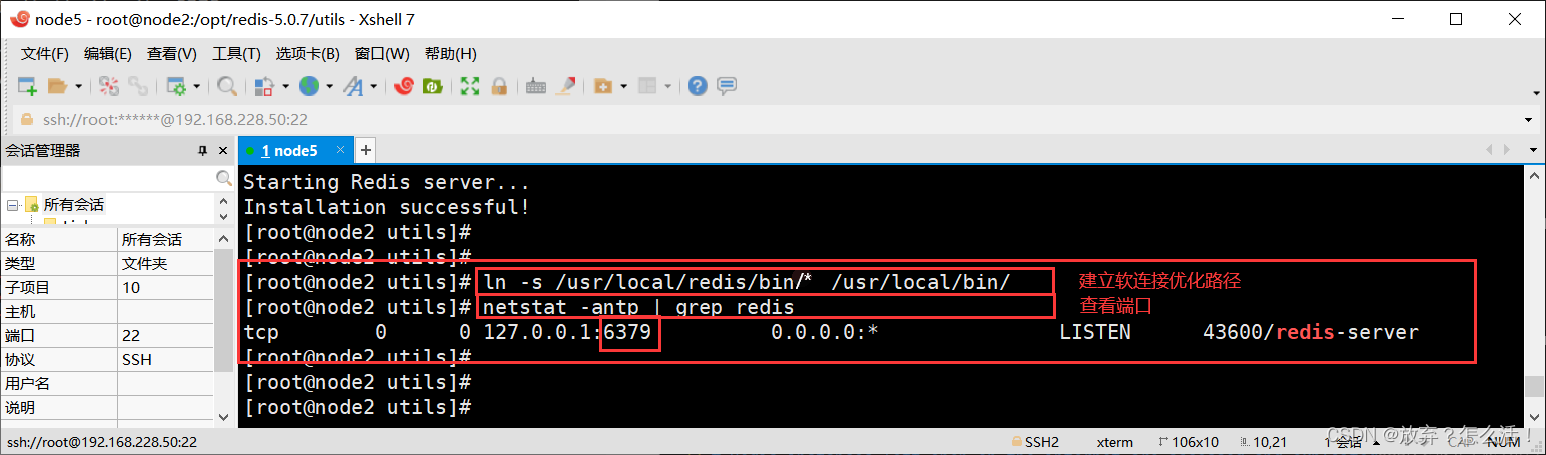
ln -s /usr/local/redis/bin/* /usr/local/bin/
#��install_server.sh �ű��������,Redis ������Ѿ�����,Ĭ�������˿�Ϊ6379
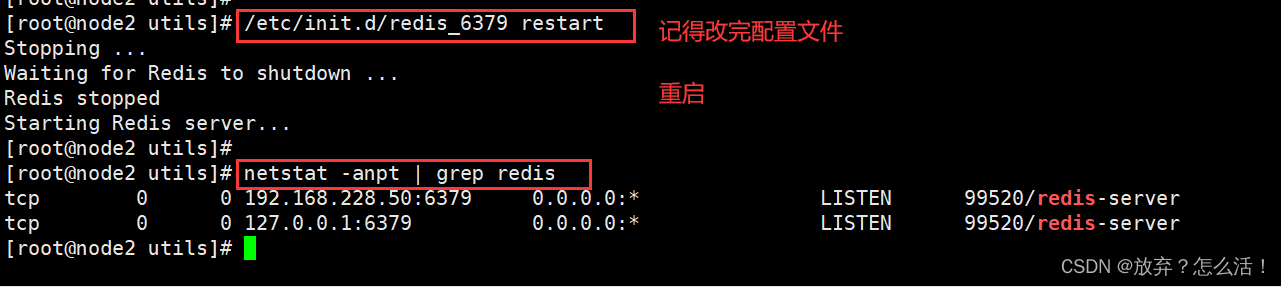
netstat -natp | grep redis
#Redis�������
/etc/init.d/redis_6379 stop
#ֹͣ
/etc/init.d/redis_6379 start
#����
/etc/init.d/redis_6379 restart
#����
/etc/init.d/redis_6379 status
#״̬
#������/etc/redis/6379.conf����
vim /etc/redis/6379.conf
bind 127.0.0.1 192.168.226.129
#70��,���Ӽ�����������ַ
port 6379
#93��,RedisĬ�ϵļ����˿�
daemonize yes
#137��,�����ػ�����
pidfile /var/run/redis_6379.pid
#159��,ָ��PID�ļ�
loglevel notice
#167��,��־����
logfile /var/log/redis_6379.log
#172��,ָ����־�ļ�
/etc/init.d/redis_6379 restart



ע:����RedisԴ�����ֱ���ṩ��Makefile�ļ�,�����ڽ�ѹ����������,������ִ��./configure��������,��ֱ��ִ��make��makeinstall������а�װ





4.2��Redis�����
redis-server �������� Redis ����
redis-benchmark ���ڼ�� Redis �ڱ���������Ч��
redis-check-aof �� AOF �־û��ļ�
redis-check-rdb �� RDB �־û��ļ�
redis-cli Redis�������
rdb��aof��redis�����г־û����ܵ�������ʽRDB AOF
redis-cli �����ڵ�½��redis���ݿ�
4.3��redis-cli �����й���(Զ�̵�¼)
�:redis-cli -h host -p port -a password
-h ָ��Զ������
-p ָ�� Redis ����Ķ˿ں�
-a ָ������,δ�������ݿ��������ʡ��-a ѡ��
���������κ�ѡ���ʾ,��ʹ�� 127.0.0.1:6379 ���ӱ����ϵ� Redis ���ݿ�
redis-cli -h 192.168.116.80 -p 6379


4.4��redis-benchmark ���Թ���
redis-benchmark �ǹٷ��Դ���Redis ���ܲ��Թ���,������Ч�IJ��� Redis ���������
�����IJ����:redis-benchmark ��ѡ� ��ѡ��ֵ��
-h:ָ��������������
-p:ָ���������˿�
-s:ָ�������� socket
-c:ָ������������
-n:ָ��������
-d:���ֽڵ���ʽָ�� SET/GET ֵ�����ݴ�С
-k:1=keep alive 0=reconnect
-r: SET/GET/INCR ʹ����� key, SADD ʹ�����ֵ
-P:ͨ���ܵ�����<numred>����
-q:ǿ���˳� redis������ʾ query/sec ֵ
�Ccsv:�� CSV ��ʽ���
-l:����ѭ��,����ִ�в���
-t:�������Զ��ŷָ��IJ��������б�
-I:Idle ģʽ������ N �� idle ���Ӳ��ȴ�
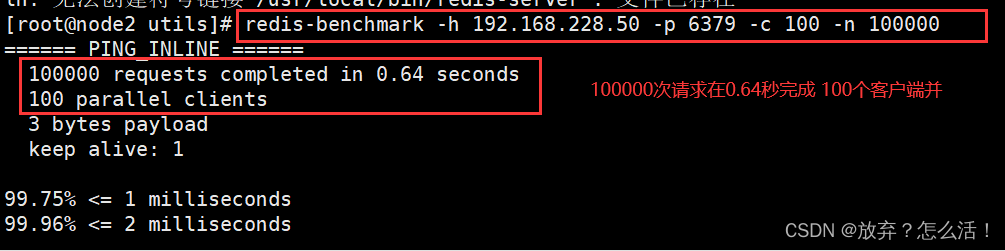
#�� IP ��ַΪ 192.168.116.80���˿�Ϊ 6379 �� Redis ���������� 100 ������������ 100000 �������������
redis-benchmark -h 192.168.116.80 -p 6379 -c 100 -n 100000
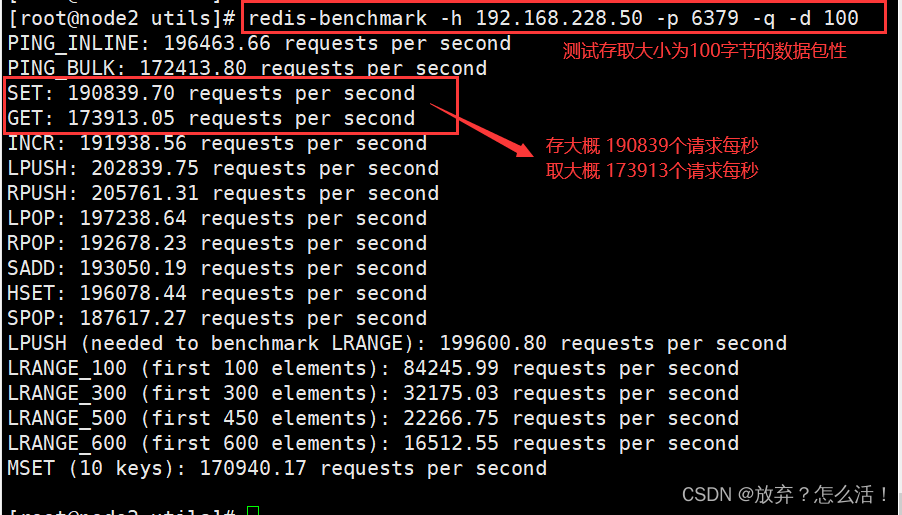
#���Դ�ȡ��СΪ 100 �ֽڵ����ݰ�������
redis-benchmark -h 192.168.116.80 -p 6379 -q -d 100
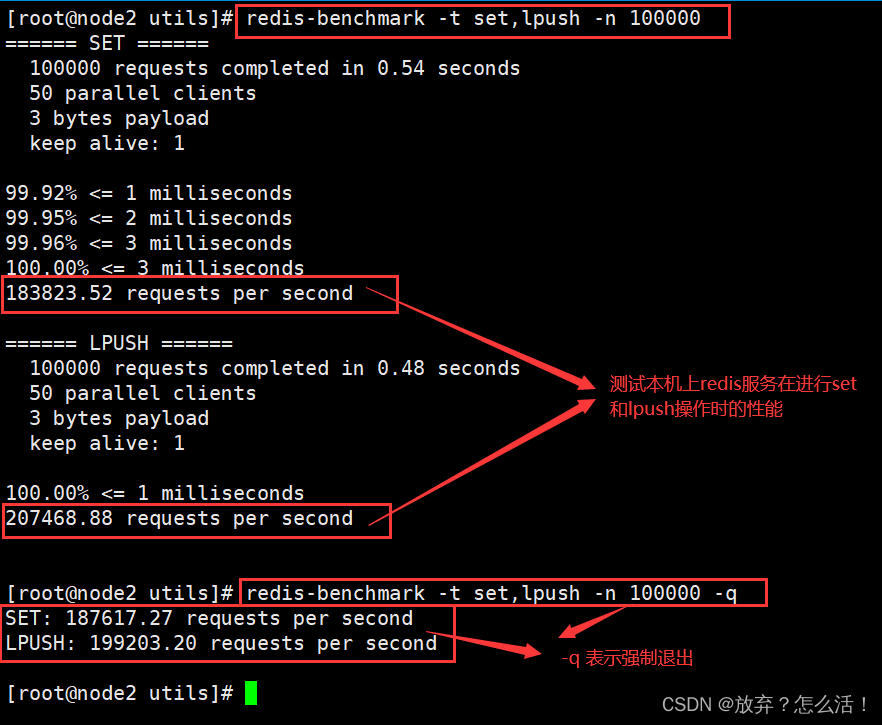
#���Ա����� Redis �����ڽ��� set �� lpush ����ʱ������
redis-benchmark -t set,lpush -n 100000 -q
4.5��Redis���ݿⳣ������
1.set: �������,�����ʽΪ set key value
2.get: ��ȡ����,�����ʽΪ get key
redis-cli
127.0.0.1:6379> set teacher zhangsan
OK
127.0.0.1:6379> get teacher
"zhangsan"
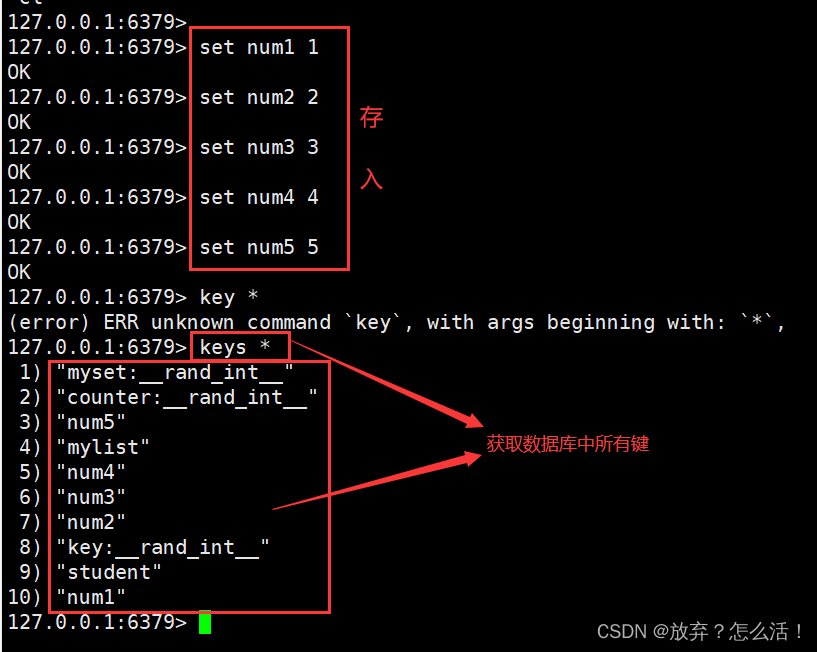
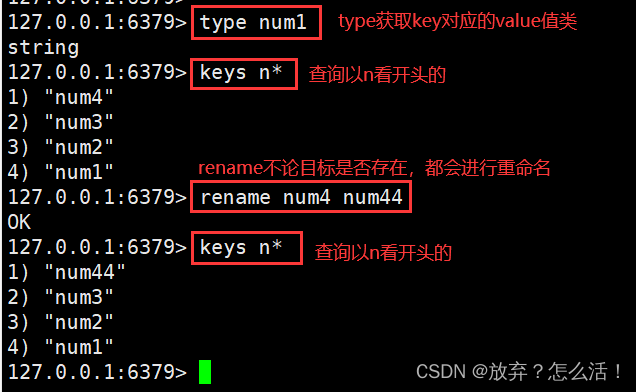
3.keys �������ȡ���Ϲ���ļ�ֵ�б�,ͨ��������Խ��*��?��ѡ����ʹ�á�
127.0.0.1:6379> set k1 1
127.0.0.1:6379> set k2 2
127.0.0.1:6379> set k3 3
127.0.0.1:6379> set v1 4
127.0.0.1:6379> set v5 5
127.0.0.1:6379> set v22 5
127.0.0.1:6379> KEYS * #�鿴��ǰ���ݿ������м�
1) "v5"
2) "myset:__rand_int__"
3) "v1"
4) "counter:__rand_int__"
5) "v22"
6) "teacher"
7) "k2"
8) "mylist"
9) "k3"
10) "key:__rand_int__"
11) "k1"
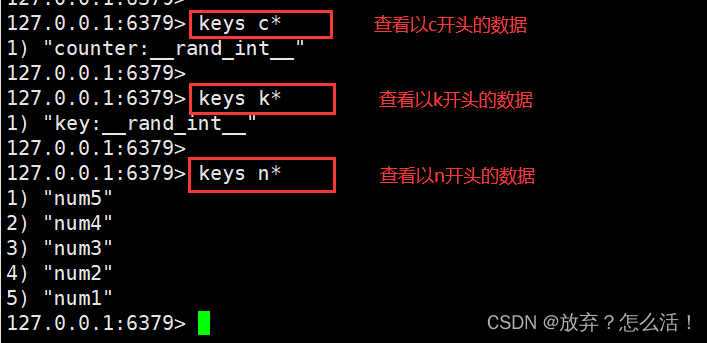
127.0.0.1:6379> KEYS v* #�鿴��ǰ���ݿ�����v��ͷ������
1) "v5"
2) "v1"
3) "v22"
127.0.0.1:6379> KEYS v? #�鿴��ǰ���ݿ�����v��ͷ�����������һλ������
1) "v5"
2) "v1"
127.0.0.1:6379> KEYS v?? #�鿴��ǰ���ݿ�����v��ͷv��ͷ�������������λ������
1) "v22"
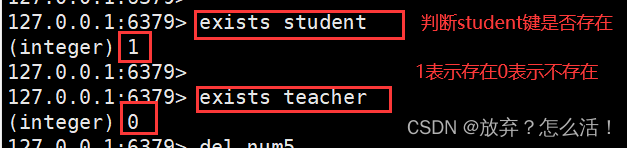
4.exists ��������жϼ�ֵ�Ƿ����
127.0.0.1:6379> exists teacher #�ж�teacher ���Ƿ����
(integer) 1 # 1��ʾteacher ���Ǵ���
127.0.0.1:6379> exists tea
(integer) 0 #0��ʾtea��������
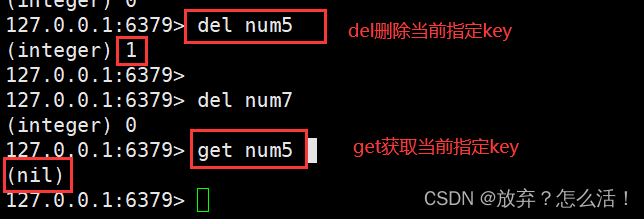
5.del �������ɾ����ǰ���ݿ��ָ��key
127.0.0.1:6379> keys *
127.0.0.1:6379> del v5
(integer) 1
127.0.0.1:6379> get v5
(nil)
6.type ������Ի�ȡkey��Ӧ�� value ֵ���͡�
127.0.0.1:6379> type k1
string
7.rename �����Ƕ�����key������������ (����)
�����ʽ: rename Դkey Ŀ��key
ʹ��rename�������������ʱ,����Ŀ��key�Ƿ���ڶ�����������,��Դkey��ֵ�Ḳ��Ŀ��key��ֵ����ʵ��ʹ�ù�����,�������� exists����鿴Ŀ��key�Ƿ����,Ȼ���پ����Ƿ�ִ��rename����,�Ա��⸲����Ҫ���ݡ�
127.0.0.1:6379> keys v*
1) "v1"
2) "v22"
127.0.0.1:6379> rename v22 v2
OK
127.0.0.1:6379> keys v*
1) "v1"
2) "v2"
127.0.0.1:6379> get v1
"4"
127.0.0.1:6379> get v2
"5"
127.0.0.1:6379> rename v1 v2
127.0.0.1:6379> get v1
(nil)
127.0.0.1:6379> get v2
"4"
8.renamenx ����������Ƕ�����key����������,����������Ƿ����,���Ŀ��key���������������� (������)
�����ʽ: renamenx Դkey Ŀ��key
127.0.0.1 :6379> keys *
127.0.0.1:6379> get teacher
"zhangsan"
127.0.0.1:6379> get v2
"4"
127.0.0.1:6379> renamenx v2 teacher
(integer) 0
127.0.0.1:6379> keys *
127.0.0.1 :6379> get teacher
"zhangsan"
127.0.0.1:6379> get v2
"4"
9.dbsize����������Dz鿴��ǰ���ݿ���key����Ŀ��
127.0.0.1:6379> dbsize
(integer) 9
#ʹ��config set requi repass yourpassword ������������
127.0.0.1:6379> config set requirepass 123456
#ʹ��config get requirepass ����鿴����(һ����������,��������֤ͨ������,�������в���������)
127.0.0.1 : 6379> auth 123456
127.0.0.1:6379> config get requirepass
# ɾ������
127.0.0.1:6379> auth 123123
127.0.0.1:6379> config set requirepass ''
# ���ϲ�����,������redis

4.6�� Redis �����ݿⳣ������
Redis֧�ֶ����ݿ�,Redis Ĭ������°���16�����ݿ�,���ݿ�������������0-15 ������������
�����ݿ������,��������
#�����ݿ���л�
�����ʽ: select ���
ʹ�� redis-cli ����Redis���ݿ��,Ĭ��ʹ�õ������Ϊ 0 �����ݿ⡣
127.0.0.1:6379> select 10 #�л������Ϊ10�����ݿ�
127.0.0.1:6379[10]> select 15 #�л������Ϊ15�����ݿ�
127.0.0.1:6379[15]> select 0 #�л������Ϊ0�����ݿ�
#�����ݿ���ƶ�����
��ʽ: move ��ֵ ���
127.0.0.1:6379> set k1 100
OK
127.0.0.1:6379> get k1
"100"
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> get k1
(nil)
127.0.0.1:6379[1]> select 0 #�л���Ŀ�����ݿ�0
OK
127.0.0.1:6379> get k1 #�鿴Ŀ�������Ƿ����
"100"
127.0.0.1:6379> move k1 1 #�����ݿ�0��k1�ƶ������ݿ�1��
(integer) 1
127.0.0.1:6379> select 1 #�л���Ŀ�����ݿ�1
OK
127.0.0.1:6379[1]> get k1 #�鿴���ƶ�����
"100"
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379> get k1 #�����ݿ�0�����鿴��k1��ֵ
(nil)
#������ݿ�������
FLUSHDB :��յ�ǰ���ݿ�����
FLUSHALL :����������ݿ������,����!!!


�塢Redis�߿���
��web��������,�߿�����ָ�����������������ʵ�ʱ��,�����ı����ڶʱ���ڿ����ṩ��������(99.9%�� 99.99%�� 99.999%�ȵ�)��������Redis�ᄈ��, �߿��õĺ����ƺ�Ҫ����һЩ,���˱�֤�ṩ��������(�����ӷ��롢�������ּ���),����Ҫ����������������չ,���ݰ�ȫ���ᶪʧ�ȡ�
��Redis��,ʵ�ָ߿��õļ�����Ҫ�����־û������Ӹ��ơ��ڱ��ͼ�Ⱥ,��������:
�־û�: �־û�����ĸ߿��÷���(��ʱ����������Ϊ�߿��õ��ֶ�),��Ҫ���������ݱ���,�������ݴ洢��Ӳ��,��֤���ݲ���������˳�����ʧ��
���Ӹ��� :���Ӹ����Ǹ߿���Redis�Ļ���,�ڱ��ͼ�Ⱥ���������Ӹ��ƻ�����ʵ�ָ߿��õġ����Ӹ�����Ҫʵ�������ݵĶ������,�Լ����ڶ������ĸ��ؾ���ͼĹ��ϻָ���ȱ��:���ϻָ����Զ���;д���������ؾ���;�洢�����ܵ����������ơ�
�ڱ� :�����Ӹ��ƵĻ�����,�ڱ�ʵ�����Զ����Ĺ��ϻָ���ȱ�� :д���������ؾ���;�洢�����ܵ����������ơ�
��Ⱥ : ͨ����Ⱥ, Redis�����д���������ؾ���,�Լ��洢�����ܵ��������Ƶ�����,ʵ���˽�Ϊ���� �ĸ߿��÷�����
����Redis�־û�
6.1 ���־û��Ĺ���
Redis ���ڴ����ݿ�,���ݶ��Ǵ洢���ڴ���,Ϊ�˱���������ϵ��ԭ���� Redis �����쳣�˳������ݵ����ö�ʧ,��Ҫ���ڽ� Redis �е�������ij����ʽ(���ݻ�����)���ڴ汣�浽Ӳ��;���´� Redis ����ʱ,���ó־û��ļ�ʵ�����ݻָ�������֮��,Ϊ�˽������ѱ���,���Խ��־û��ļ�������һ��Զ��λ�á�
6.2��Redis�ṩ���ַ�ʽ���г־û�
RDB�־û�(Redis DataBase) :ԭ���ǽ�Reids���ڴ��е����ݿ��¼��ʱ���浽�����ϡ�
AOF�־û�(append only file) :ԭ���ǽ�Reids�IJ�����־���ӵķ�ʽд���ļ�,������MySQL��binlog��
PS:����AOF�־û���ʵʱ�Ը���,�������������˳�ʱ��ʧ�����ݸ���,���AOF��Ŀǰ�����ij־û���ʽ,����RDB�־û���Ȼ��������֮��
�ߡ�RDB�־û�
RDB�־û���ָ��ָ����ʱ�����ڽ��ڴ��е�ǰ�����е��������ɿ��ձ��浽Ӳ��(���Ҳ�������ճ־û�),�ö�����ѹ���洢,������ļ�����rdb;��Redis��������ʱ,���Զ�ȡ�����ļ��ָ����ݡ�
7.1�� ��������
RDB�־û��Ĵ�����Ϊ:�ֶ��������Զ��������֡�
���ֶ�����
1��save ����� bgsave ����������� RDB �ļ���
2��save ��������� Redis ����������,ֱ�� RDB �ļ��������Ϊֹ,�� Redis �����������ڼ�,���������ܴ����κ���������
3��bgsave ����ᴴ��һ���ӽ���,���ӽ��������� RDB �ļ�,������ (�� Redis ������) �������������
4��bgsave����ִ�й�����,ֻ�� fork �ӽ���ʱ������������,������ save ����,�������̶�������������,��� save �ѻ���������,���ϻ���Ҫ���� save ��ʹ�á�
���Զ�����
���Զ�����RDB�־û�ʱ,RedisҲ ��ѡ��bgsave������save�����г־û���
#ͨ���������ô���
save m n
#�Զ����������������������ļ���ͨ��save m n,ָ����m���ڷ���n�α仯ʱ,�ᴥ��bgsave��
vim /etc/redis/6379.conf
-----219��--��������save������������һ��ʱ,��������bgsave�ĵ���
save 900 1 :��ʱ�䵽900��ʱ,���redis���ݷ���������1�α仯,��ִ��bgsave
save 300 10 :��ʱ�䵽300��ʱ, ���redis���ݷ���������10�α仯,��ִ��bgsave
save 60 10000 :��ʱ�䵽60��ʱ,���redis���ݷ���������10000�α仯, ��ִ��bgsave
-----242��--�Ƿ���RDB�ļ�ѹ��
rdbcompression yes
-----254��--ָ��RDB�ļ���
dbfilename dump.rdb
-----264��--ָ��RDB�ļ���AOF�ļ�����Ŀ¼
dir /var/lib/redis/6379
�������Զ���������
���� savemn ����,����һЩ��������ᴥ�� bgsave :
�����Ӹ��Ƴ�����,����ӽڵ�ִ��ȫ�����Ʋ���,�����ڵ��ִ�� bgsave ����,���� RDB �ļ������ӽڵ㡣
ִ�� shutdown ����ʱ,�Զ�ִ�� RDB �־û���
7.2��ִ������
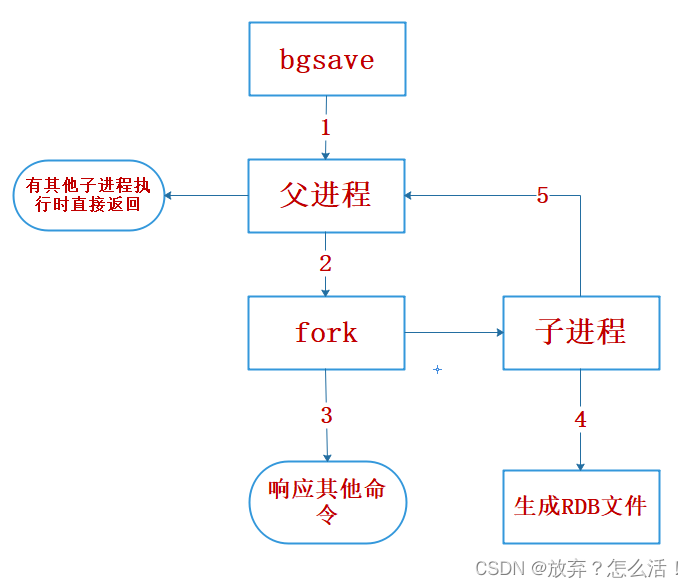
1��Redis�����������ж� :��ǰ�Ƿ���ִ�� save,��bgsave/bgrewriteaof���ӽ���,�����ִ����bgsave����ֱ�ӷ���,bgsave/bgrewriteaof ���ӽ��̲���ͬʱִ��,��Ҫ�ǻ������ܷ���Ŀ���:�����������ӽ���ͬʱִ�д����Ĵ���д����,�����������ص��������⡣
2��������ִ��fork���������ӽ���,��������и�������������,Redis����ִ�����Կͻ��˵��κ�����
3�������� fork ��,bgsave ����ء�Background saving started" ��Ϣ����������������,��������Ӧ��������
4���ӽ��̴���RDB�ļ�,���ݸ������ڴ����������ʱ�����ļ�,��ɺ��ԭ���ļ�����ԭ���滻
5���ӽ��̷����źŸ������̱�ʾ���,�����̸���ͳ����Ϣ
7.3�� ����ʱ����
RDB�ļ������빤�����ڷ���������ʱ�Զ�ִ�е�,��û��ר�ŵ������������AOF�����ȼ�����,��˵�AOF����ʱ,Redis����������AOF�ļ����ָ�����;ֻ�е�A0F�ر�ʱ,�Ż���Redis����������ʱ���RDB�ļ�,���Զ����롣����������RDB�ļ��ڼ䴦������״̬,ֱ���������Ϊֹ��
Redis����RDB�ļ�ʱ,���RDB�ļ�����У��,����ļ���,����־�л��ӡ����,Redis����ʧ�ܡ�
�ˡ�AOF�־û�
RDB�־û��ǽ���������д���ļ�,��AOF�־û�,���ǽ�Redisִ�е�ÿ��д��ɾ�������¼����������־�ļ���,��ѯ���������¼; ��Redis����ʱ�ٴ�ִ��AOF�ļ��е��������ָ����ݡ�
��RDB���,AOF��ʵʱ�Ը���,����ѳ�Ϊ�����ij־û�������
8.1�� ����AOF
vim /etc/redis/6379.conf
�C700�ШC��,����AOF
appendonly yes
�C704�ШCָ��AOF�ļ�����
appendfilename ��appendonly.aof��
�C796�ШC�Ƿ�������һ�����ܴ��������ָ��
aof-load-truncated yes
/etc/init.d/redis_6379 restart ��������
8.2��ִ������
������Ҫ��¼Redis��ÿ��д����,���AOF����Ҫ����,AOF��ִ����������
������(append):��Redis��д�����ӵ�������aof_ buf;
�ļ�д��(write)���ļ�ͬ��(sync):���ݲ�ͬ��ͬ�����Խ�aof_buf�е�����ͬ����Ӳ��;
�ļ���д(rewrite):������дAOF�ļ�,�ﵽѹ����Ŀ�ġ�
8.2.1�������� (append)
Redis�Ƚ�д�����ӵ�������,������ֱ��д���ļ�,��Ҫ��Ϊ�˱���ÿ����д���ֱ��д��Ӳ��,����Ӳ��IO��ΪRedis���ص�ƿ����
�����ӵĸ�ʽ��Redis���������Э���ʽ,����һ�ִ��ı���ʽ,���м����Ժá��ɶ���ǿ�����״���������������ο������ŵ㡣��A0F�ļ���,��������ָ�����ݿ��select���� (��select0Ϊѡ��0�����ݿ�) ����Redis���ӵ�,�������ǿͻ��˷�������д���
8.2.2���ļ�д��(write) ���ļ�ͬ�� (sync)
Redis �ṩ�˶���AOF��������ͬ���ļ�����,�����漰������ϵͳ��write������fsync����,˵������:
Ϊ������ļ�д��Ч��,���ִ�����ϵͳ��,���û�����write����������д���ļ�ʱ,����ϵͳͨ���Ὣ�����ݴ浽һ���ڴ滺������,������������������ָ��ʱ��,��������������������д�뵽Ӳ��������IJ�����Ȼ�����Ч��,��Ҳ�����˰�ȫ����:��������ͣ��,�ڴ滺�����е����ݻᶪʧ;���ϵͳͬʱ�ṩ��fsync��fdatasync��ͬ������,����ǿ�Ʋ���ϵͳ���̽��������е�����д�뵽Ӳ����,�Ӷ�ȷ�����ݵİ�ȫ�ԡ�
AOF��������ͬ���ļ����Դ�������ͬ����ʽ,���Ƿֱ���:
vim /etc/redis/6379.conf
---729---
appendfsync always
����:����д��aof_ buf����������ϵͳfsync����ͬ����AOF�ļ�,fsync��ɺ��̷߳��ء�
���������,ÿ����д���Ҫͬ����AOF�ļ�,Ӳ��IO��Ϊ����ƿ��,Redisֻ��֧�ִ�Լ����TPSд��,
���ؽ�����Redis������;������ʹ�ù�̬Ӳ��(SSD),ÿ���ԼҲֻ�ܴ������������,���һ���SSD��������
appendfsync everysec
����:����д��aof_ buf�����ϵͳwrite����,write��ɺ��̷߳���;
fsyncͬ���ļ�������ר�ŵ��߳�ÿ�����һ�Ρ�
everysec��ǰ�����ֲ��Ե�����,�����ܺ����ݰ�ȫ�Ե�ƽ��,
�����Redis��Ĭ������,Ҳ�������Ƽ������á�
appendfsync no
����:����д��aof_ buf�����ϵͳwrite����,����AOF�ļ���fsyncͬ��;
ͬ���ɲ���ϵͳ����,ͨ��ͬ������Ϊ30�롣���������,�ļ�ͬ����ʱ�䲻�ɿ�,
�һ������жѻ������ݻ�ܶ�,���ݰ�ȫ������֤��
8.2.3�� �ļ���д (rewrite)
? ����ʱ������,Redis������ִ�е�д����Խ��Խ��,AOF�ļ�Ҳ��Խ��Խ��:�����AOF�ļ�������Ӱ�����������������,Ҳ�ᵼ�����ݻָ���Ҫ��ʱ�������
? �ļ���д��ָ������дAOF�ļ�,��СAOF�ļ����������Ҫע�����,AOF��д�ǰ�Redis�����ڵ�����ת��Ϊд����,ͬ�����µ�AOF�ļ�;����Ծɵ�AOF�ļ������κζ�ȡ��д�����!
? �����ļ���д��Ҫע�����һ����:����AOF�־û���˵,�ļ���д��Ȼ��ǿ���Ƽ���,�������DZ����;��ʹû���ļ���д,����Ҳ���Ա��־û�����Redis������ʱ����:�����һЩʵ����,��ر��Զ����ļ���д,Ȼ��ͨ����ʱ������ÿ���ijһʱ�̶�ʱִ��
�ļ���д֮�����ܹ�ѹ��AOF�ļ�,ԭ������:
? ���ڵ����ݲ���д���ļ�
? ��Ч�������д���ļ�:����Щ���ݱ��ظ���ֵ(set mykey v1, set mykey v2)����Щ���ݱ�ɾ����(sadd myset v1, del myset) �ȡ�
? ����������Ժϲ�Ϊһ��:��sadd myset v1, sadd myset v2, sadd myset v3���Ժϲ�Ϊsadd myset v1 v2 v3
8.3���ļ���д�Ĵ���
�ļ���д�Ĵ���,��Ϊ�ֶ��������Զ�����
8.3.1���ֶ�����
ֱ�ӵ���bgrewriteaof����,�������ִ����bgsave��Щ����:����fork�ӽ��̽��о���Ĺ���,�Ҷ�ֻ����forkʱ������
8.3.2���Զ�����
ͨ������auto-aof-rewrite-min-sizeѡ���auto-aof-rewrite-percentageѡ�����Զ�ִ��BGREWRITEAOF��ֻ�е�auto-aof-rewrite-min-size��auto-aof-rewrite-percentage����ѡ��ͬʱ����ʱ,�Ż��Զ�����AOF��д,��bgrewriteaof������
vim /etc/redis/6379.conf
----771----
auto-aof-rewrite-percentage 100
#��ǰAOF�ļ���С(��aof_current_size)���ϴ���־��дʱAOF�ļ���С(aof_base_size)����ʱ,����BGREWRITEAOF����
auto-aof-rewrite-min-size 64mb
#��ǰA0F�ļ�ִ��BGREWRITEAOF�������Сֵ,����տ�ʼ����Reidsʱ�����ļ��ߴ��С����Ƶ����BGREWR ITEAOF
8.4���ļ���д������
(1) Redis�����������жϵ�ǰ�Ƿ��������ִ��bgsave/bgrewriteaof���ӽ���,���������bgrewriteaof����ֱ�ӷ���,�������bgsave�������bgsaveִ����ɺ���ִ��
(2) ������ִ��fork���������ӽ���,��������и�������������
(3.1) ������fork��,bgrewriteaof �����"Background append only file rewrite started" ��Ϣ����������������,��������Ӧ�������Redis������д������Ȼд��AOF������,������appendfsync����ͬ����Ӳ��,��֤ԭ��A0F���Ƶ���ȷ
(3.2) ����fork����ʹ��дʱ���Ƽ���,�ӽ���ֻ�ܹ���fork����ʱ���ڴ����ݡ����ڸ�������Ȼ����Ӧ����,���Redisʹ��AOF��д������(aof_ rewrite_buf) �����ⲿ������,��ֹ��AOF�ļ������ڼ䶪ʧ�ⲿ�����ݡ�Ҳ����˵,bgrewriteaofִ�� �ڼ�,Redis��д ����ͬʱ�ӵ�aof_ buf��aof_ rewirte_ buf����������
(4) �ӽ��̸����ڴ����,��������ϲ�����д�뵽�µ�AOF�ļ�
(5.1) �ӽ���д���µ�AOF�ļ���,���̷��ź�,�����̸���ͳ����Ϣ,�������ͨ��info persistence�鿴
(5.2) �����̰�AOF��д������������д�뵽�µ�AOF�ļ�,�����ͱ�֤����AOF�ļ�����������ݿ�״̬�ͷ�������ǰ״̬һ��
(5.3) ʹ���µ�AOF�ļ��滻���ļ�,���AOF��д
8.5����д����ע���
��д�ɸ�����fork�ӽ��̽���;
��д�ڼ�Redisִ�е�д����,��Ҫ�ӵ��µ�AOF�ļ���,Ϊ��Redis������aof_ rewrite_buf���档
8.6������ʱ����
��AOF����ʱ,Redis�� ��ʱ����������AOF�ļ����ָ�����;ֻ�е�AOF�ر�ʱ,�Ż�����RDB�ļ��ָ����ݡ�
��AOF����,��AOF�� ��������ʱ,��ʹRDB�ļ�����Ҳ������ء�
Redis����AOF�ļ�ʱ,���AOF�ļ�����У��,����ļ���,����־�л��ӡ����,Redis����ʧ�ܡ��������AOF�ļ���β������ (����ͻȻ崻����������ļ�β��������),��aof-load- truncated��������,����־�л��������,Redis ���Ե�AOF�ļ���β��,�����ɹ���
aof-load-truncated����Ĭ���ǿ����ġ�
�š�RDB��AOF����ȱ��
9.1 ��RDB�־û�
�ŵ�: RDB�ļ�����,���С,���紫���,�ʺ�ȫ������;�ָ��ٶȱ�AOF��ܶࡣ��Ȼ,��AOF���, RDB�� ��Ҫ���ŵ�֮һ�Ƕ����ܵ�Ӱ����Խ�С��
ȱ��: RDB�ļ�������ȱ�����������ݿ��յij־û���ʽ�����˱�Ȼ������ʵʱ�־û�,��������Խ��Խ��Ҫ�Ľ���,���ݵĴ�����ʧ�ܶ�ʱ���������ܵ�,���AOF�־û���Ϊ����������,RDB�ļ���Ҫ�����ض���ʽ,�����Բ�(���ϰ汾��Redis�������°汾��RDB�ļ�)�� ����RDB�־û�,һ������bgsave�ڽ���fork����ʱRedis�����̻�����,��һ����,�ӽ�����Ӳ��д����Ҳ�����IOѹ����
9.2��AOF�־û�
? ��RDB�־û����Ӧ,AOF���ŵ�����֧���뼶�־û��������Ժ�,ȱ�����ļ��ָ��ٶ�����������Ӱ���
? ����AOF�־û�,��Ӳ��д���ݵ�Ƶ�ʴ�����(everysec������Ϊ�뼶),IOѹ������,�����������AOF����������
? AOF�ļ�����д��RDB��bgsave����,����forkʱ���������ӽ��̵�I0ѹ�����⡣�����˵,����AOF��Ӳ����д���ݵ�Ƶ�ʸ���,��˶�Redis���������ܵ�Ӱ������
ʮ��Redis���ܹ���
10.1���鿴Redis�ڴ�ʹ��
info memory
10.2���ڴ���Ƭ��
����ϵͳ������ڴ�ֵused_ memory_ rss����Redisʹ�õ��ڴ�ֵused_ memory����ó��ڴ���Ƭ���ɲ���ϵͳ��Ч�ķ���/���������ڴ浼�µ� (�������������ڴ����)
�����ڴ���Ƭ�ʶ�����Redisʵ������Դ�����Ƿdz���Ҫ��:
? �ڴ���Ƭ���Դ���1�Ǻ�����,���ֵ��ʾ�ڴ���Ƭ�ʱȽϵ�
? �ڴ���Ƭ�ʳ���1.5,˵��Redis������ʵ����Ҫ�����ڴ��150��, ����50�����ڴ���Ƭ�ʡ���Ҫ��redis-cli����.������shutdown save����,������Redis ������
? �ڴ���Ƭ�ʵ���1��,˵��Redis�ڴ���䳬���������ڴ�,����ϵͳ���ڽ����ڴ潻������Ҫ���ӿ��������ڴ�����Redis�ڴ�ռ��
10.3���ڴ�ʹ����
redisʵ�����ڴ�ʹ���ʳ�����������ڴ�,����ϵͳ����ʼ�����ڴ���swap�ռ佻��
�����ڴ潻�������ķ���:
? ��Ի������ݴ�Сѡ��װRedis ʵ��
? �����ܵ�ʹ��Hash���ݽṹ�洢
? ����key�Ĺ���ʱ��
10.4���ڻ���key
? ��֤��������redis�����ڴ���Դ
? ���ﵽ���õ����ֵʱ,��ѡ��һ��key�Ļ��ղ���,Ĭ������»��ղ����ǽ�ֹɾ��
�����ļ�����maxmemory- policy����ֵ:
vim /etc/redis/6379.conf
--598--
maxmemory-policy noenviction
��volatile-lru :ʹ��LRU�㷨�������ù���ʱ������ݼ�������̭����
��volatile-ttl :�������ù���ʱ������ݼ�������ѡ�������ڵ�������̭
��volatile-random :�������ù���ʱ������ݼ����������ѡ������̭
��allkeys-lru :ʹ��LRU�㷨���������ݼ�������̭����
��allkeys-random :�����ݼ���������ѡ��������̭
��noenviction :��ֹ��̭����
�ܽ�
1��redis ��һ�ַǹ����ݿ�(�ڴ�/����)
redis����������ǹ����ݿ����Ƶĵط���Ҫ����:
���������ͷḻ
�ڳ־û�(���Խ��ڴ��ֵ����ݱ����ڴ�����)��ʽΪ:RDB��AOF
2��redis ��Ⱥģʽ:�ڱ������ӡ�cluster (��Ⱥ)
redis�ļ�Ⱥģʽ,ͬʱҲ��������Ϊ��redis�ĸ߿���ģʽ
����: �ṩ�˱�������,ȱ��:����Թ��Ͻ����Զ���,д���������ؾ���
�ڱ�: ������Ϊ�����ṩ�˹����Զ����Ĺ���,д���������ؾ���
��Ⱥ: �������ӻ���,����˹����Զ�����д�������ؾ��������,ͬʱ������Դ���������ǰ���ּ�Ⱥ�õ���һ���ĸ���
3���߿����еij־û�
RDB��AOF
(1)�־û���ʽ:
�� RDB:�����ԵĿ���
�� AOF :�ӽ�ʵʱ�ij־û�(��everysec��ʽ)
(2) redis ���õ����ȼ�
AOF>RDB,ͬʱ����AOF���ܹرյ������,redis�Ż�����������ʱʹ��RDB�ķ�ʽ���лָ�
(3)RDB��AOF�г־û�ģʽ
��RDB:
��redis������(������) fork �������ӽ��̶�redis�ڴ��е����ݽ��г־û�,���ɵ�. rdb�ļ���
��AOF:
���ݳ־û�����(alawys�� no�� everysec (Ĭ��) ),�Ƚ�redis�е���䱣���ڻ�������,�ٴӻ���
��ͬ����.aof�ļ���
4��redis�Ļָ�����/����
redis���������÷ǹ����ݿ�����,���ǽ����ݱ������ڴ���;
���������ڴ���ʱ,��redis ����,�ڴ����ݶ�ʧ,��redis ͨ��RDB��AOF�ij־û����ܿ�����redis ��������֮��,���ȶ�ȡAOF�ļ�,����AOF�ļ��������ݻָ����ַ�ʽ�����־û�����"����