4.1 HBase简介

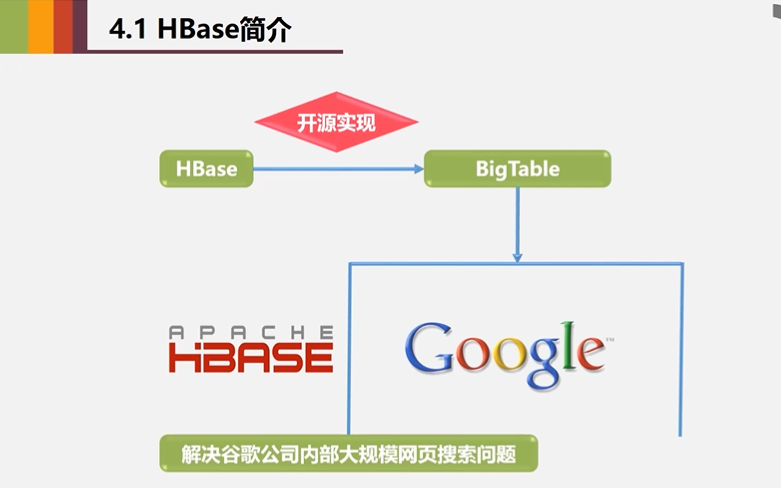
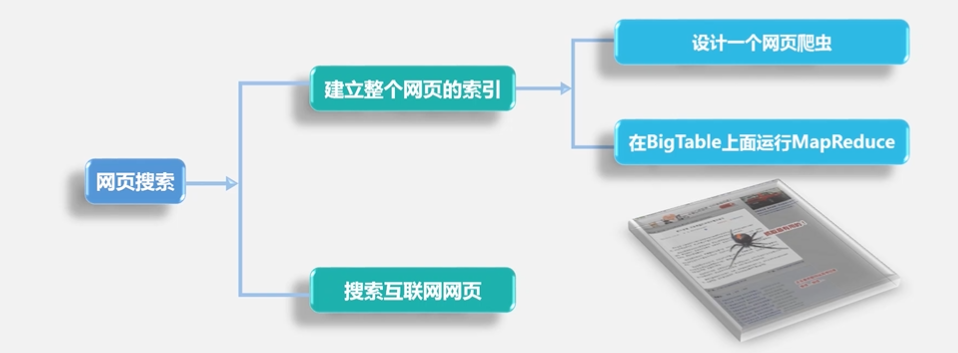

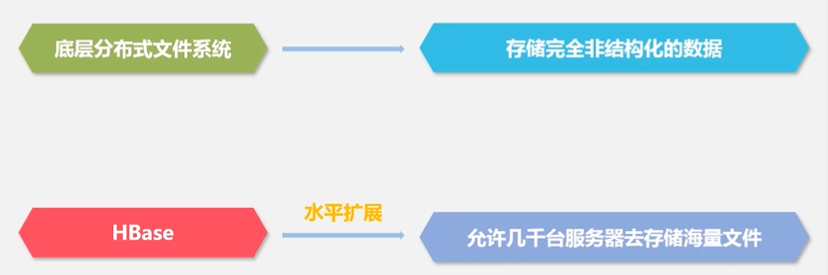

Hadoop没有办法满足大数据实时处理的需求,主要解决大规模数据离线批量处理Hadoop


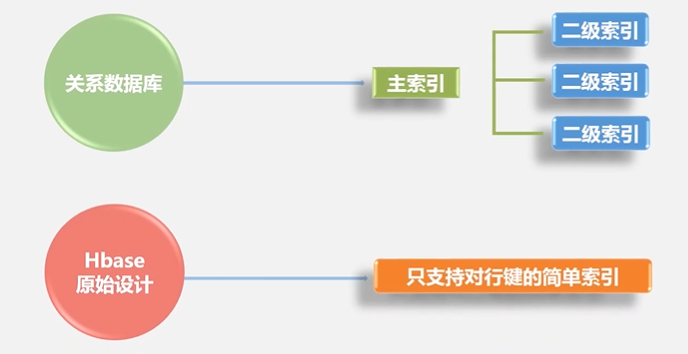
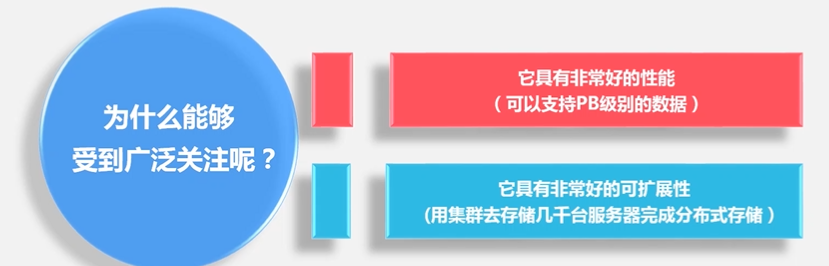
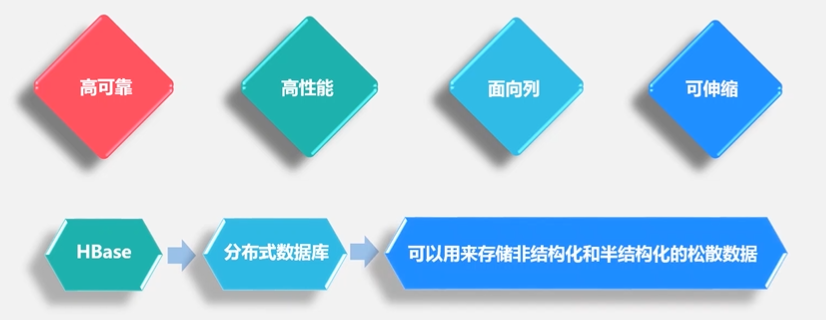
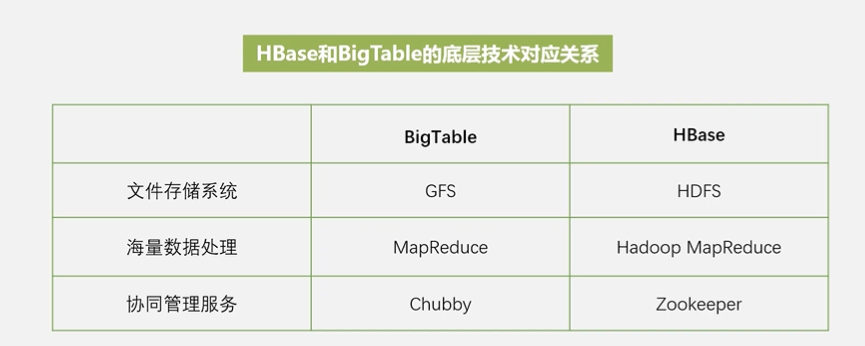
HBase它不是采用单台机器,它是完全借助整个分布式集群来存储海量数据,所以它的水平可扩展性非常好
4.2 HBasse数据模型
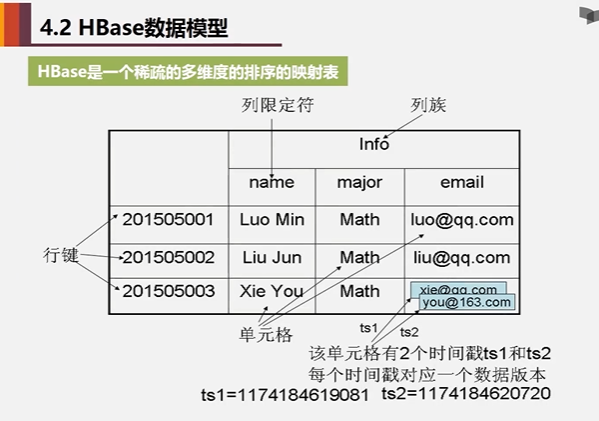
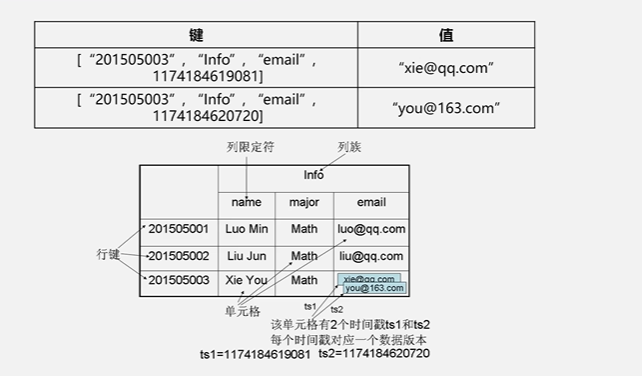
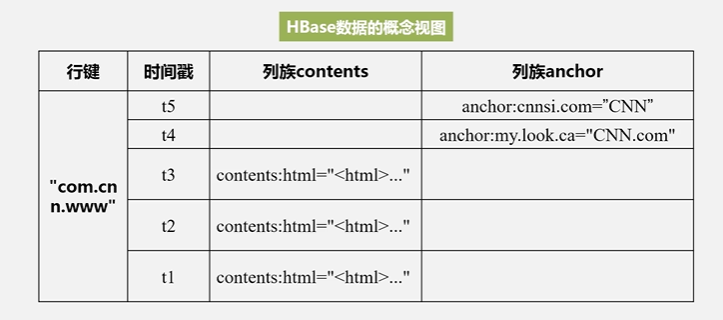
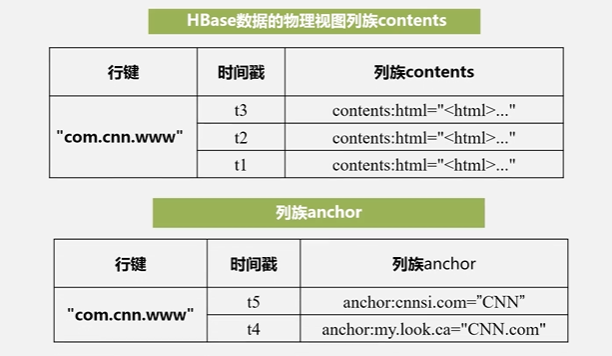
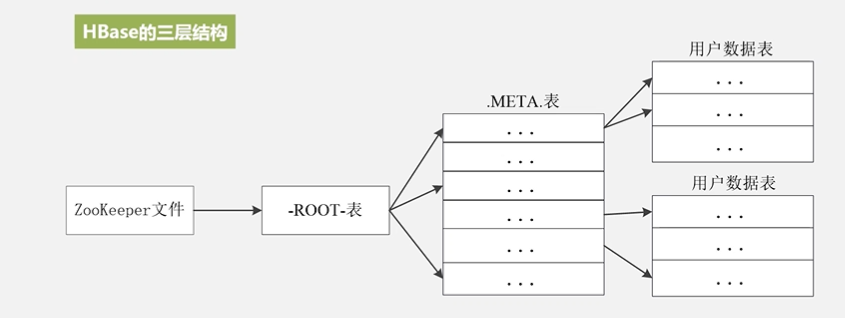
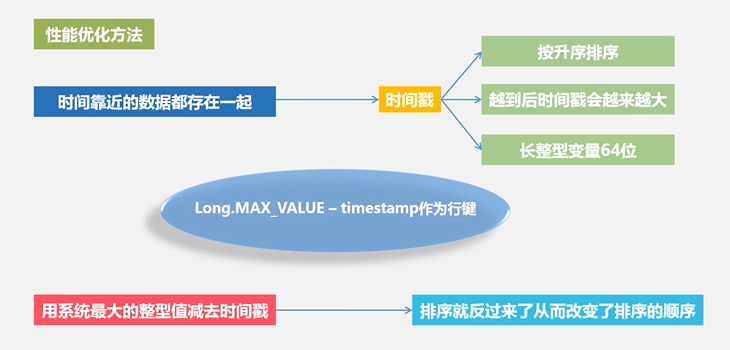
这个表它的索引是根据4个元素来定义:行键、列族、列限定符和时间戳来定位一个具体的数据的

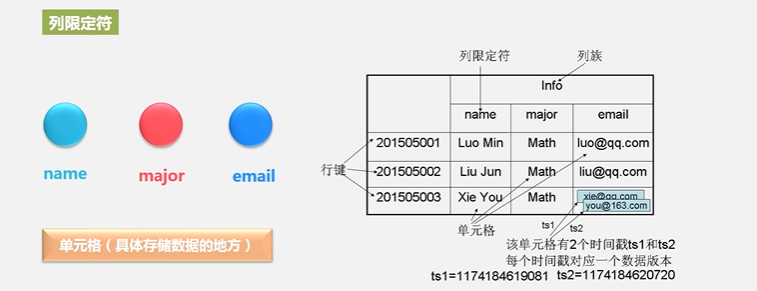
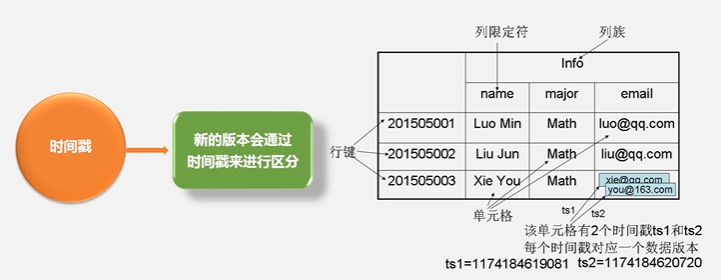
旧的版本会保留,新的版本会通过时间戳来进行区分
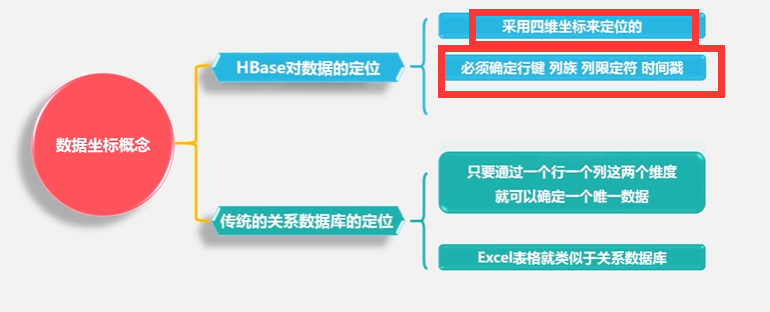
HBase是通过4个属性来定义一个具体的数据
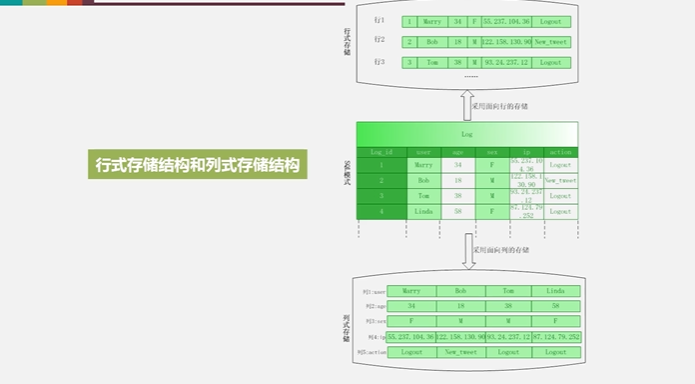

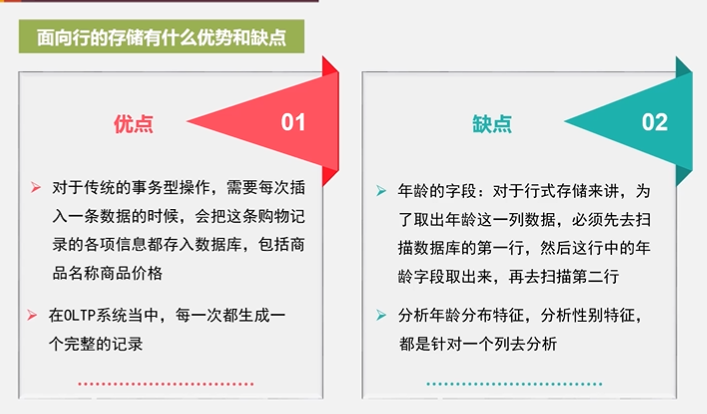
做分析的时候我们都不是一行一行的分析,而是针对某一列来分析(比如年龄特征、性别特征)
同一列的类型差别不大
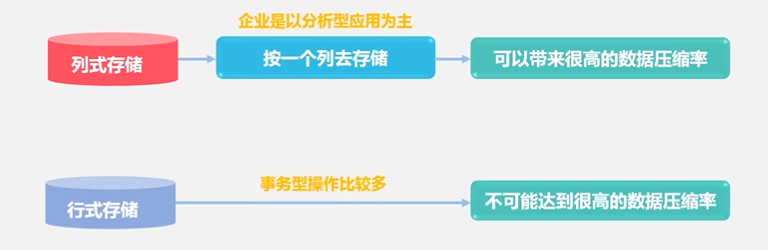
HBase通常是以分析性为主,采用的是列式存储
4.3 HBasse的实现原理
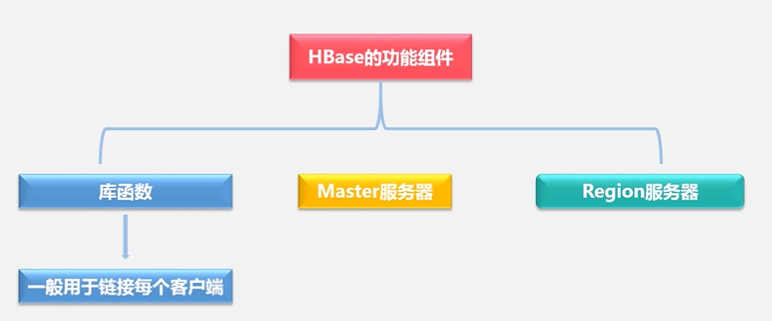



4.4 HBasse运行机制
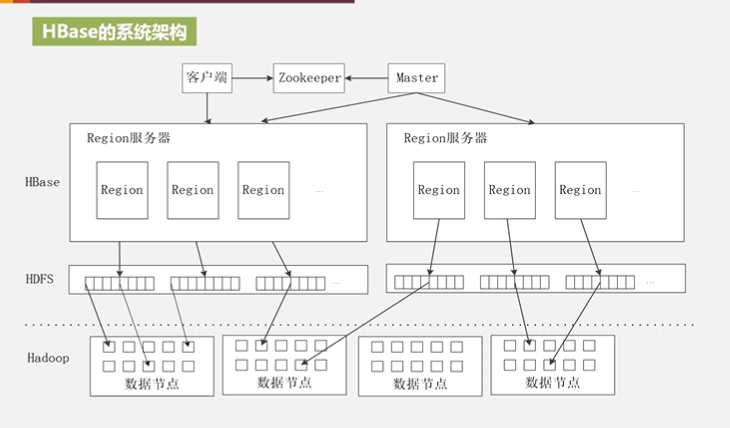
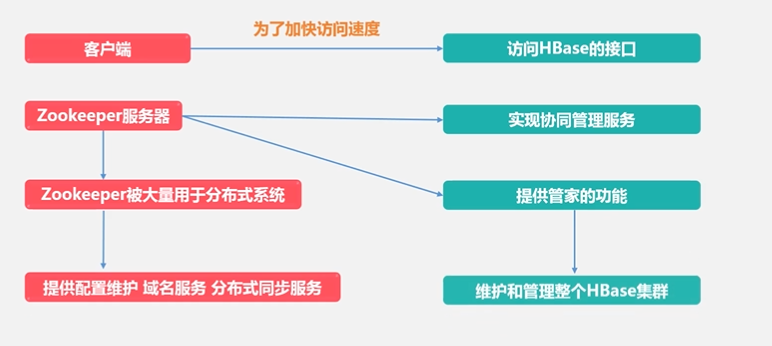
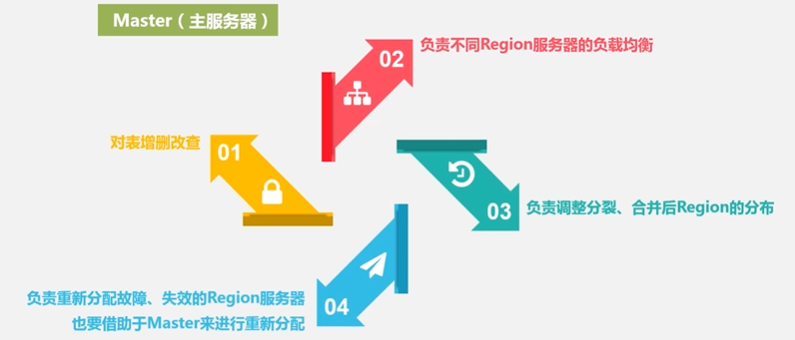
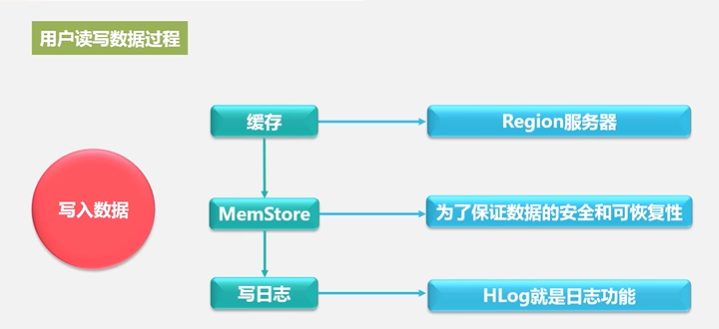
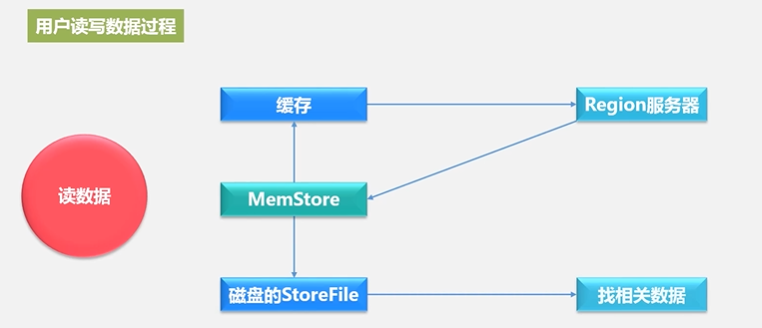
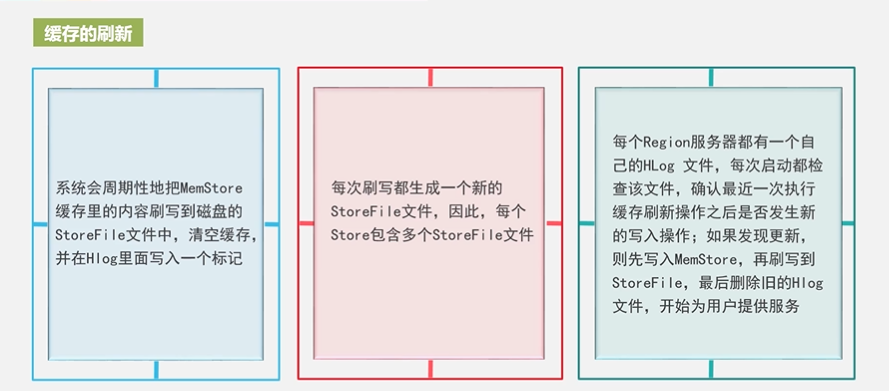
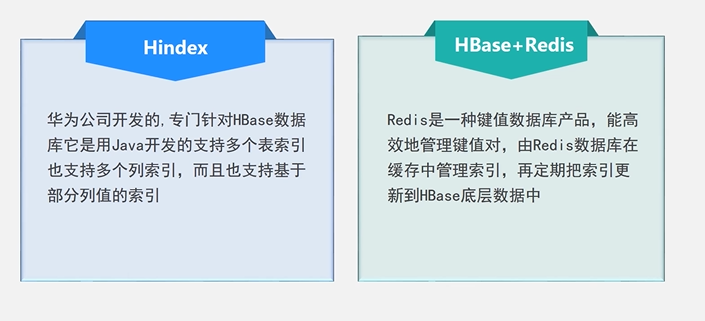
4.5 HBasse应用方案
4.6 HBasse的安装和编程实践
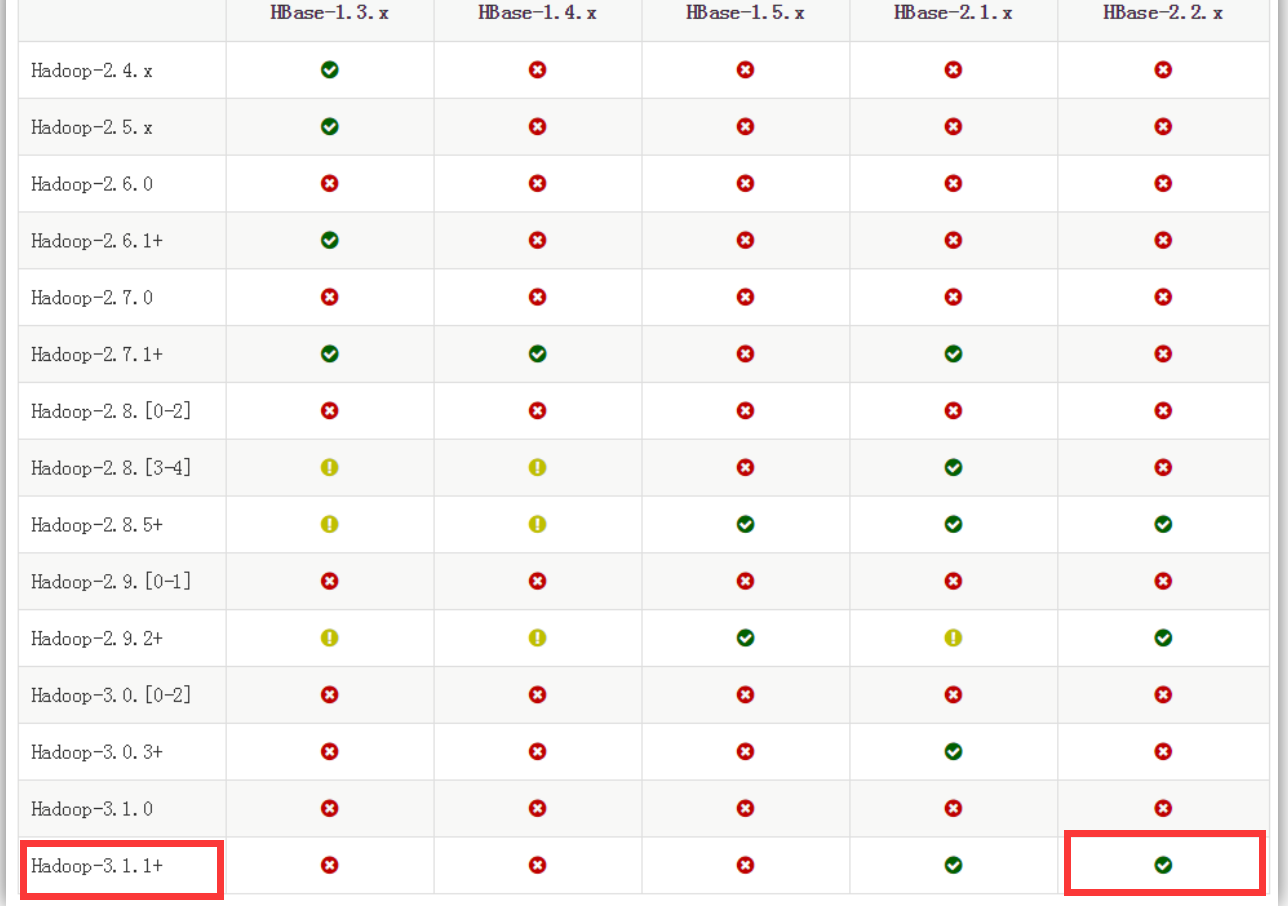
Hadoop与HBasede必须要兼容,否则不能安装
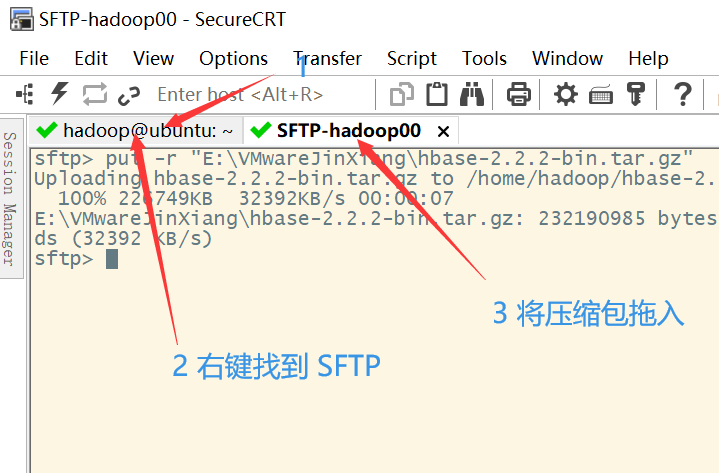
HBase的安装与编程
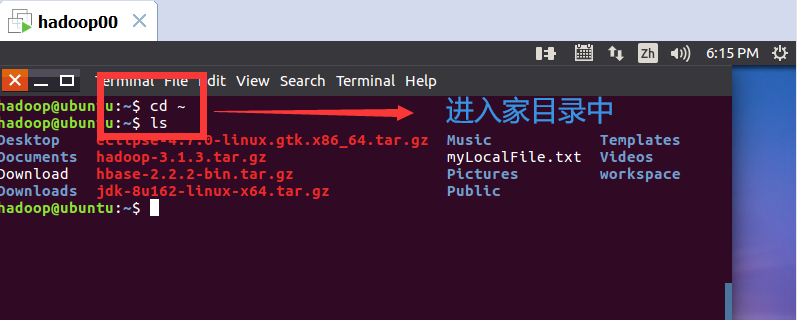
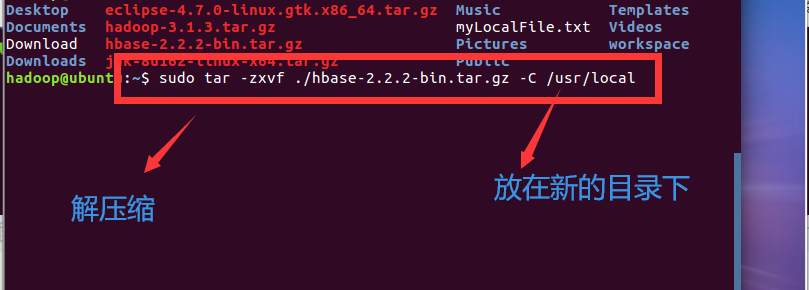
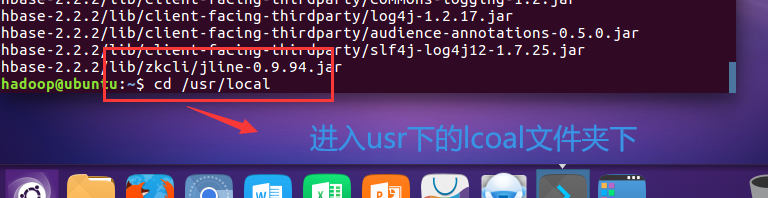
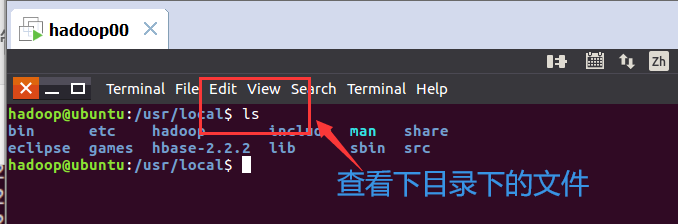
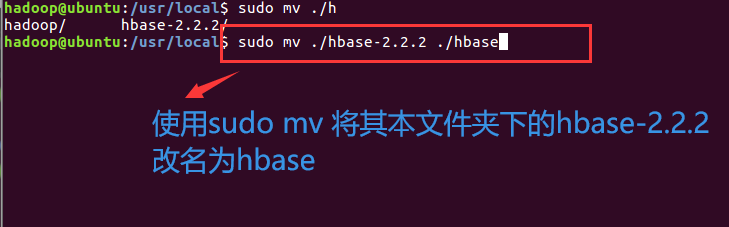
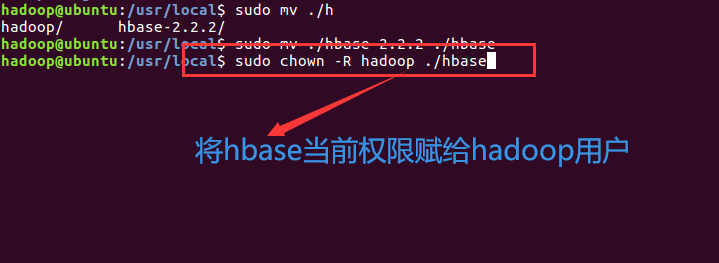
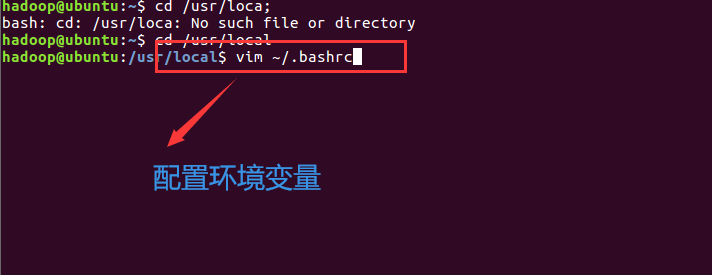
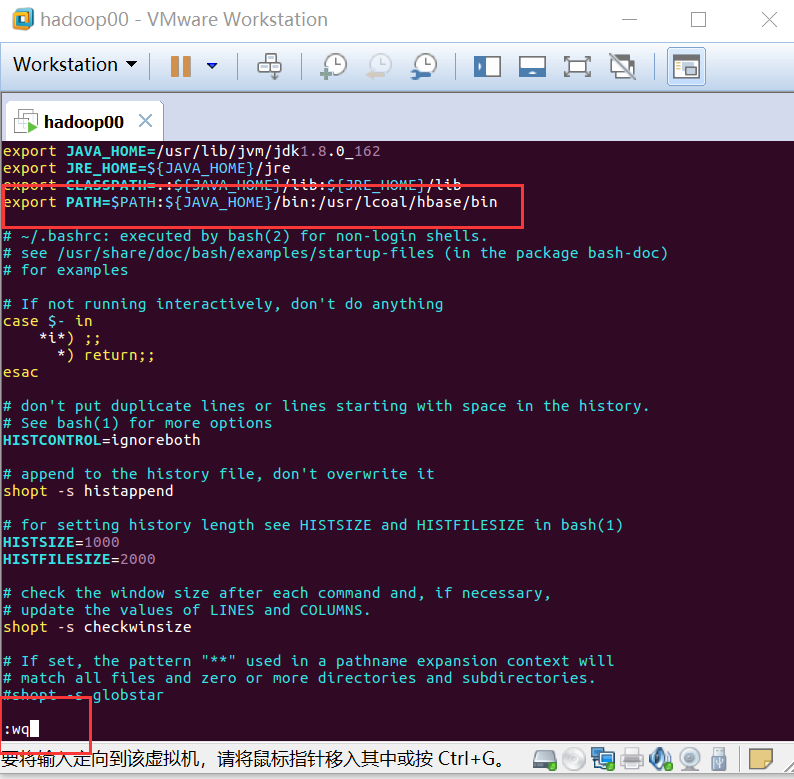
退出编辑:先按键盘左上角Esc键,再输入“:wq”
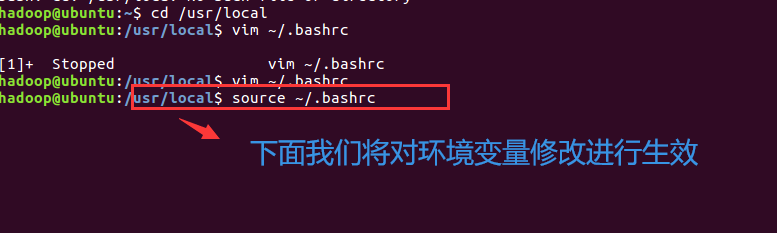
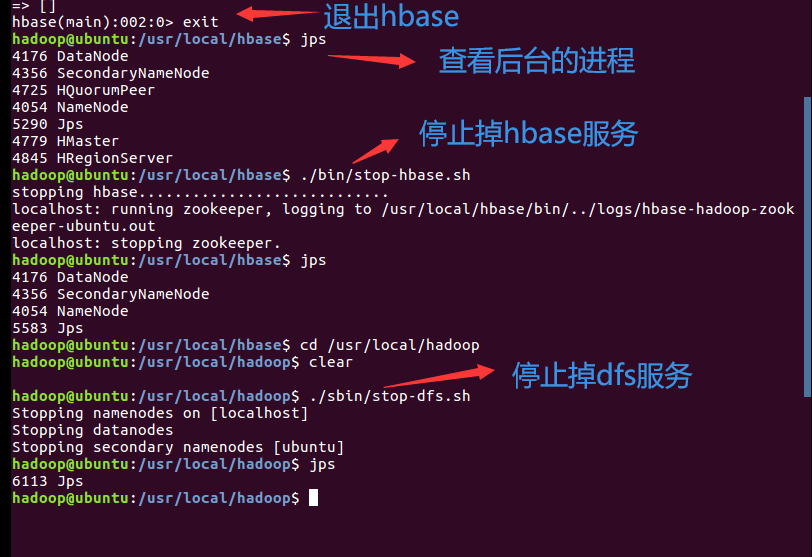
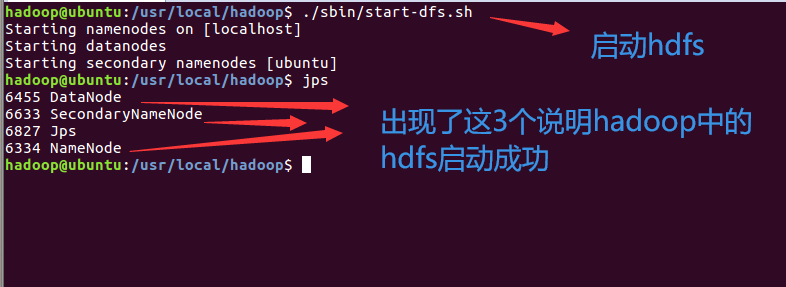
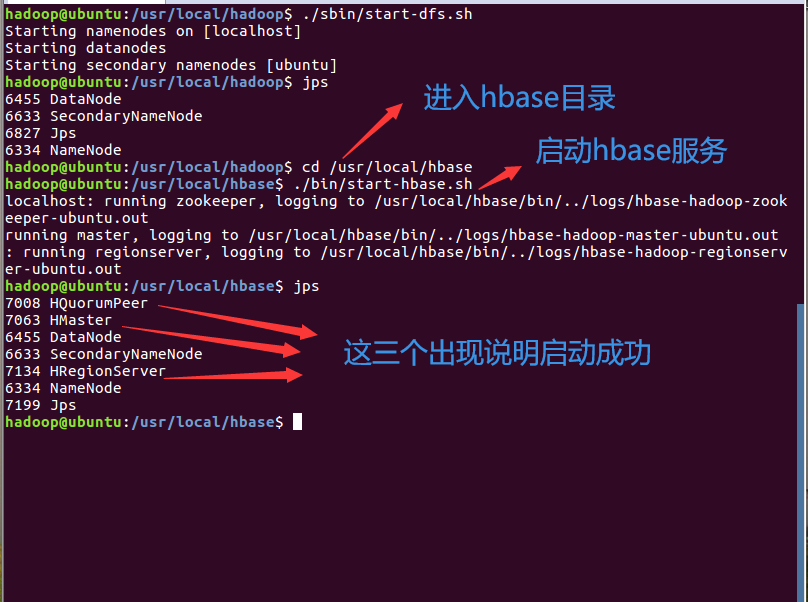
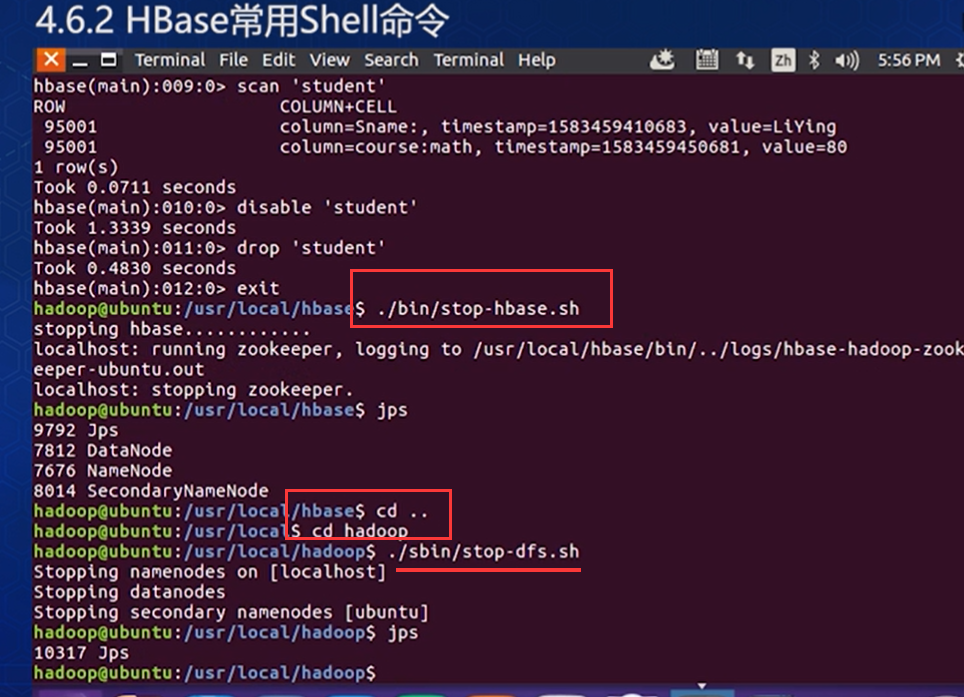
注意:我们每次用伪分布式服务时要注意它的顺序:先启动Hadoop,也就是hadoop里面的hdfs,然后
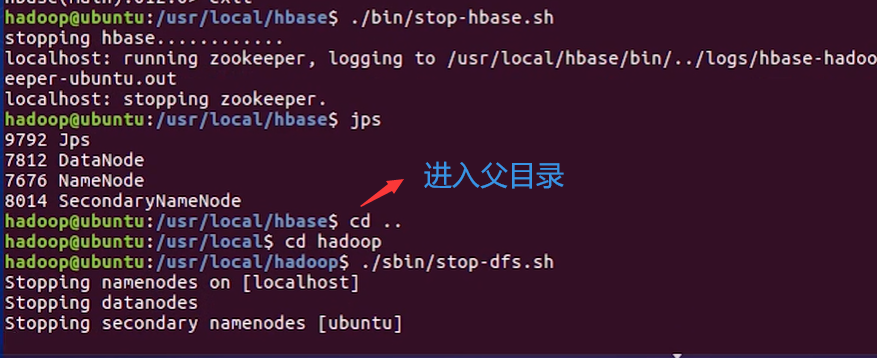
再启动Hbase;在关闭的时候是先关闭Hbase,再去关闭Hadoop
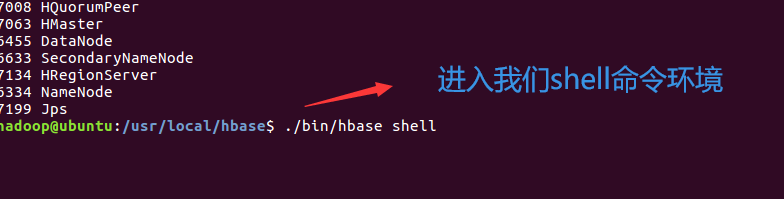
4.6.2 HBase常用Shell命令
用伪分布式服务时要注意它的顺序:先启动Hadoop,也就是hadoop里面的hdfs,然后
再启动Hbase;在关闭的时候是先关闭Hbase,再去关闭Hadoop
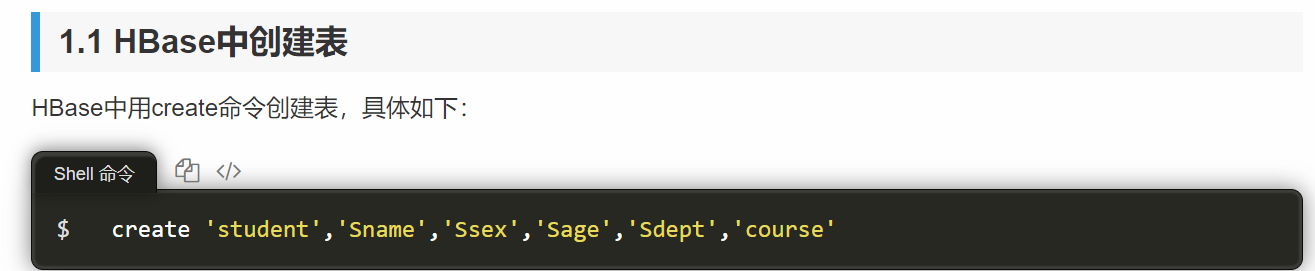
创建完“student”表后,可通过describe命令查看“student”表的基本信息

4.6.3 HBase常用Java API及其应用实例
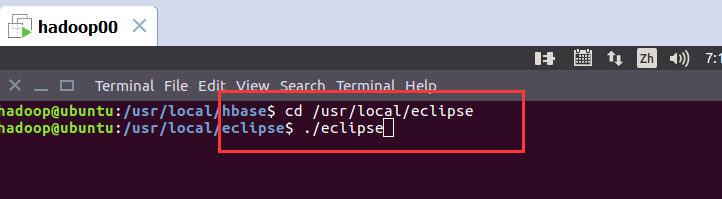
打开eclipse

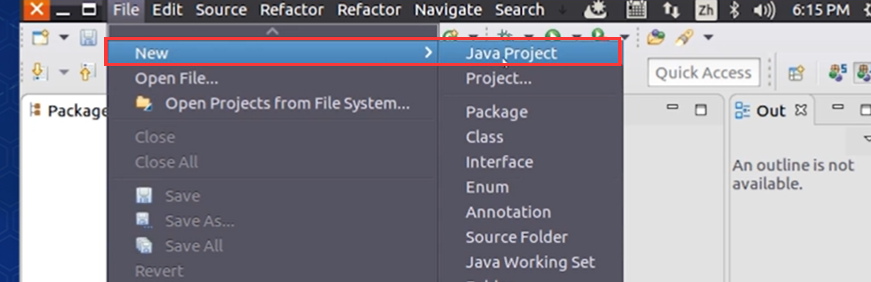
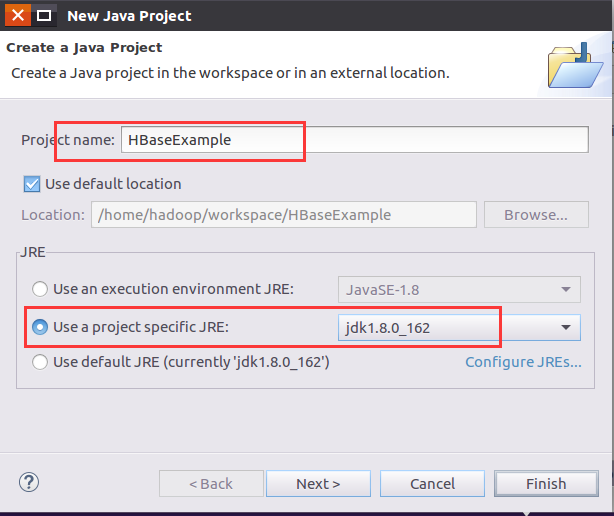
。。。
在启动之前,一定要确保HBase和HDFS已经启动,不然代码是运行不了的