一、Datax安装
1 Datax下载
DataX工具下载地址:https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/20220530/datax.tar.gz
1.1 Datax安装
1.1.1 把下载好的 datax.tar.gz 上传到Linux
1.1.2 解压 tar -xzvf datax.tar.gz ,会有/datax 目录,进入cd datax 目录
1.1.3 先删除datax目录中的所有隐藏文件,否则执行脚本会失败
find ./ -name '._*' -print0 |xargs -0 rm -rf
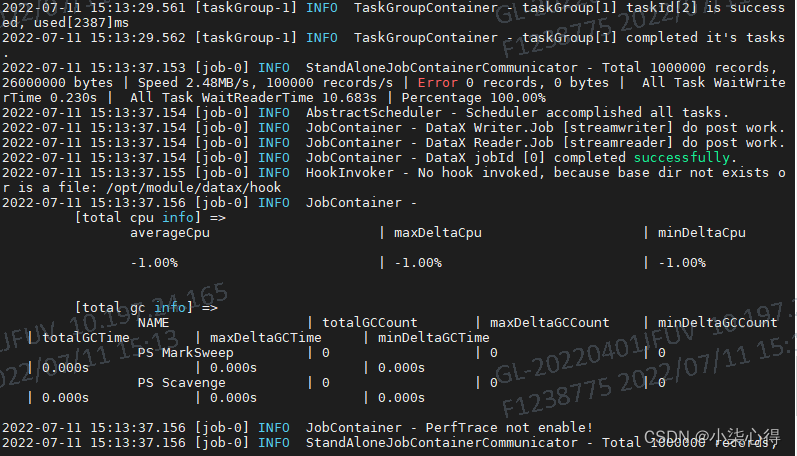
1.1.4 执行测试脚本:./bin/datax.py job/job.json ,看到下图的效果,说明环境正常
2.DataX 全量同步数据,oracle 到 mysql
2.1oracle数据库表
2.2 使用navicat 工具-数据传输-设置原数据-目标文件
将orcale中的表导出为mysql建表语句格式
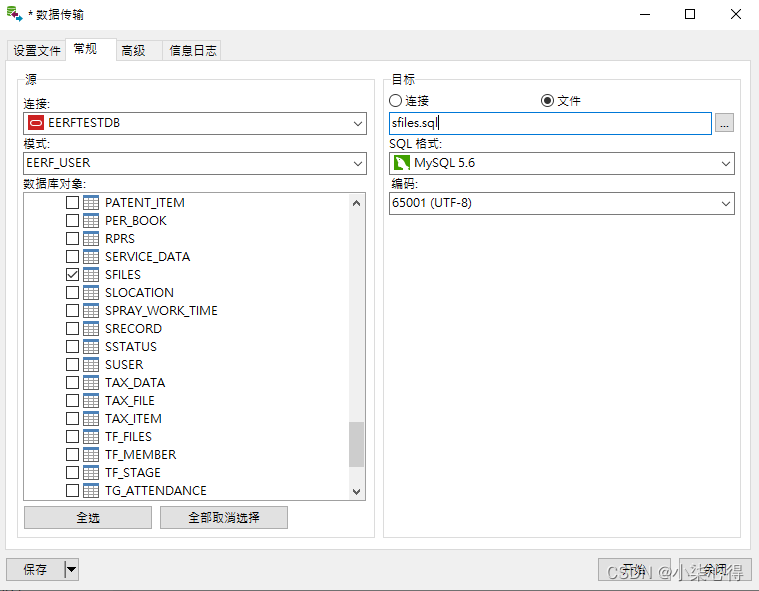
2.3 sfiles.sql 目标文件
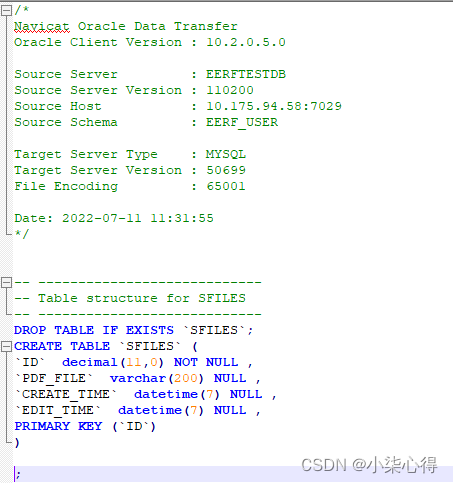
因为mysql和orcale数据库的建表语句类型有差异
2.4 修改sfiles.sql文件
- 1.主键类型修改
- 2.时间类型修改
修改后的内容
CREATE TABLE `SFILES` (
`ID` int(11) NOT NULL ,
`PDF_FILE` varchar(200) NULL ,
`CREATE_TIME` datetime(6) NULL ,
`EDIT_TIME` datetime(6) NULL ,
PRIMARY KEY (`ID`)
);
2.5 执行建表语句
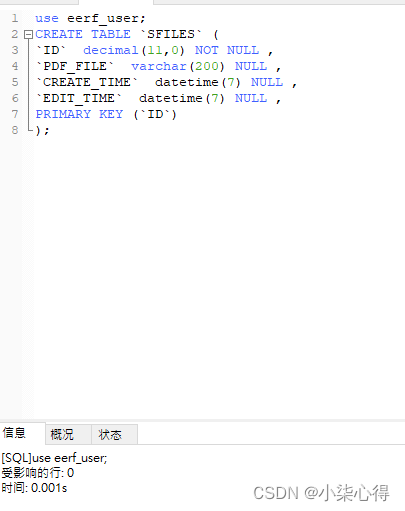
此时mysql中就有和orcale中一样的表了。
2.6 在Datax目录下 执行./bin/datax.py -r oraclereader -w mysqlwriter ,获取示例json配置,然后去修改里面的参数。
#在job 目录中创建 vi osflies_to_msfiles.json,这是改完后能同步的参数配置
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@127.0.0.1:7029:EERFDB"],
"table": ["SFILES"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://node1:3306/eerf_user?useUnicode=true&characterEncoding=UTF-8",
"table": ["SFILES"]
}
],
"password": "123456",
"preSql": [],
"session":["set session sql_mode='ANSI'"],
"username": "root",
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}
执行全量同步:./bin/datax.py job/oracle_to_mysql.json ,可以看到有 1045条记录被同步到mysql了
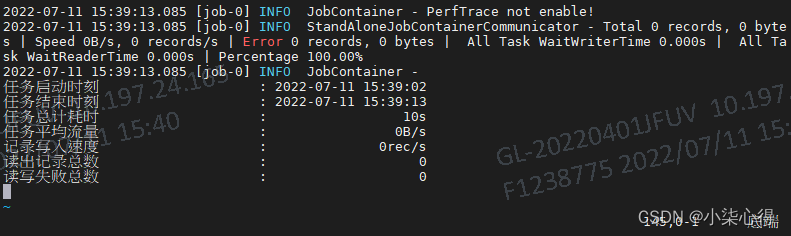
3. Datax 新增及变化同步
vim /opt/module/datax/job/osfiles_to_msfiles1.json
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["*"],
"where": "EDIT_TIME >to_date('${start_time}','yyyy-mm-dd hh24:mi:ss') and EDIT_TIME <= to_date('${end_time}','yyyy-mm-dd hh24:mi:ss')",
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@10.175.94.58:7029:EERFDB"],
"table": ["SFILES"]
}
],
"password": "123456",
"username": "eerf_user"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://node1:3306/eerf_user?useUnicode=true&characterEncoding=UTF-8",
"table": ["SFILES"]
}
],
"password": "123456",
"preSql": [],
"session":["set session sql_mode='ANSI'"],
"username": "root",
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}
vim /opt//datax/shell/test_file.sh
#!/bin/bash
source /etc/profile
#当前时间戳
cur_time=$(date +%s)
#结束时间
end_time="'$(date -d @$cur_time +"%Y-%m-%d %H:%M:%S")'"
#开始时间,为当前时间的前300s
start_time="'$(date -d @$(($cur_time-300)) +"%Y-%m-%d %H:%M:%S")'"
# 执行datax脚本,传入时间范围
/opt/module/datax/bin/datax.py /opt/module/datax/job/osfiles_to_msfiles.json -p "-Dcreate_time=$start_time -Dend_time=$end_time" &
并给test_file.sh赋可执行权限:chmod -R 777 test_file.sh
然后设置 crontab 定时任务,每5分钟执行一次,和上面脚本中的300s对应
crontab -e
*/5 * * * * /opt/module/datax/shell/test_file.sh >/dev/null 2>&1
前提条件:
- 1.在orcale中有新数据产生时,create_time 和 edit_time 默认为当前时间
修改数据时edit_time 动态改为当前时间 . - 2.在条件1 已成立的情况下可以保证mysql新增及变化同步成功
好了,此时就完成了新增及变化同步
4.DataX同步流程:
- 1.第一次部署datax时,手动执行全量同步脚本,同步已有客户数据
- 2.再进行增量同步,用Linux的crontab和脚本配合,能按时间进行增量同步
- 3.oracle同步mysql时,有几种同步模式,建议"writeMode"设置为"update":
- 3.1.mysql的"writeMode"设置为"insert",在有重复数据记录时,不会同步,直接跳过,就算oracle中该条数据已经修改了,也不会同步
- 3.2.mysql的"writeMode"设置为"replace",在有重复数据记录时,会先删除mysql中的记录,再把oracle中的记录新增进去
- 3.3.mysql的"writeMode"设置为"update",在有重复数据记录时,会把oracle中的列,覆盖mysql中的列,未配置同步的列,不会覆盖