Flume 数据采集模块
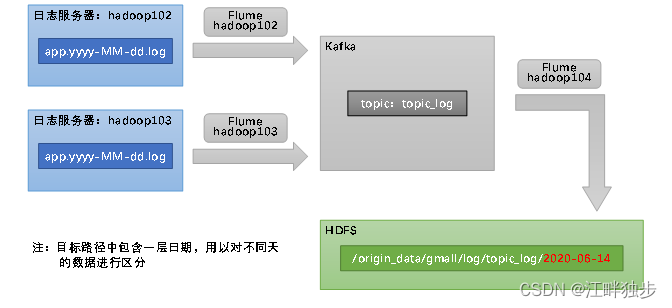
1.1 数据处理链路
1.2 环境准备
1.2.1?集群进程查看脚本
(1)在/home/bigdata_admin/bin目录下创建脚本xcall.sh
[bigdata_admin@hadoop102?bin]$ vim xcall.sh
(2)在脚本中编写如下内容
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
????echo --------- $i ----------
????ssh $i "$*"
done(3)修改脚本执行权限
[bigdata_admin@hadoop102 bin]$ chmod 777 xcall.sh
(4)启动脚本
[bigdata_admin@hadoop102 bin]$ xcall.sh jps
1.2.2 Hadoop安装
1)安装步骤
略
2)项目经验
(1)项目经验之HDFS存储多目录
虚拟机的项目不需要配置,我们只有一个磁盘。
1.生产环境服务器磁盘情况
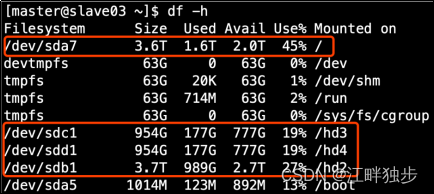
2.在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
HDFS的DataNode节点保存数据的路径由dfs.datanode.data.dir参数决定,其默认值为file://${hadoop.tmp.dir}/dfs/data,若服务器有多个磁盘,必须对该参数进行修改。如服务器磁盘如上图所示,则该参数应修改为如下的值。
<property>
????<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>注意:每台服务器挂载的磁盘不一样,所以每个节点的多目录配置可以不一致。单独配置即可。
(2)项目经验之集群数据均衡
1节点间数据均衡
开启数据均衡命令。
start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡命令。
stop-balancer.sh
2磁盘间数据均衡
生成均衡计划(我们只有一块磁盘,不会生成计划)。
hdfs diskbalancer -plan hadoop103
执行均衡计划。
hdfs diskbalancer -execute hadoop103.plan.json
查看当前均衡任务的执行情况。
hdfs diskbalancer -query hadoop103
取消均衡任务。
hdfs diskbalancer -cancel hadoop103.plan.json
(3)项目经验之Hadoop参数调优
1.HDFS参数调优hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
<property>
????<name>dfs.namenode.handler.count</name>
????<value>10</value>
</property>dfs.namenode.handler.count=20*log(e)(ClusterSize),比如集群规模为8台时,此参数设置为41。可通过简单的python代码计算该值,代码如下。
[bigdata_admin@hadoop102 ~]$ python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(8))
41
>>> quit()
2.YARN参数调优yarn-site.xml
情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
1.2.3?Zookeeper安装
1)安装步骤
略
2)ZK集群启动停止脚本
(1)在hadoop102的/home/bigdata_admin/bin目录下创建脚本
[bigdata_admin@hadoop102 bin]$ vim zk.sh
在脚本中编写如下内容。
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
????????echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
????????echo ---------- zookeeper $i 停止 ------------ ???
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
????????echo ---------- zookeeper $i 状态 ------------ ???
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac(2)增加脚本执行权限
[bigdata_admin@hadoop102 bin]$ chmod 777 zk.sh
(3)Zookeeper集群启动脚本
[bigdata_admin@hadoop102 module]$ zk.sh start
(4)Zookeeper集群停止脚本
[bigdata_admin@hadoop102 module]$ zk.sh stop
1.2.4?Kafka安装
1)安装步骤
略
1.2.5 Flume安装
按照采集通道规划,需在hadoop102,hadoop103,hadoop104三台节点分别部署一个Flume。可参照以下步骤先在hadoop102安装,然后再进行分发。
1)安装步骤
略
2)分发Flume到hadoop103、hadoop104
[bigdata_admin@hadoop102 ~]$ xsync /opt/module/flume/
3)项目经验
(1)堆内存调整
Flume堆内存通常设置为4G或更高,配置方式如下:
修改/opt/module/flume/conf/flume-env.sh文件,配置如下参数(虚拟机环境暂不配置)
export JAVA_OPTS="-Xms4096m -Xmx4096m -Dcom.sun.management.jmxremote"
注:
-Xms表示JVM Heap(堆内存)最小尺寸,初始分配;
-Xmx 表示JVM Heap(堆内存)最大允许的尺寸,按需分配。
1.3?日志采集Flume
1.3.1 日志采集Flume配置概述
按照规划,需要采集的用户行为日志文件分布在hadoop102,hadoop103两台日志服务器,故需要在hadoop102,hadoop103两台节点配置日志采集Flume。日志采集Flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到Kafka。
此处可选择TaildirSource和KafkaChannel,并配置日志校验拦截器。
选择TailDirSource和KafkaChannel的原因如下:
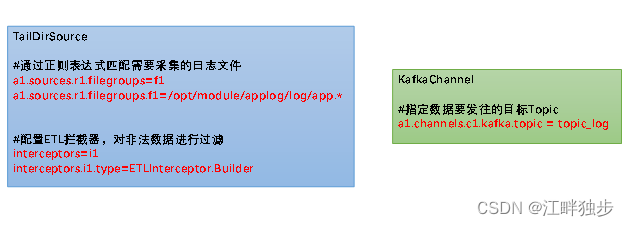
1)TailDirSource
TailDirSource相比ExecSource、SpoolingDirectorySource的优势。
TailDirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
ExecSource可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
SpoolingDirectorySource监控目录,支持断点续传。
2)KafkaChannel
采用Kafka?Channel,省去了Sink,提高了效率。
日志采集Flume关键配置如下:
1.3.2 日志采集Flume配置实操
1)创建Flume配置文件
(1)在hadoop102节点的Flume的job目录下创建file_to_kafka.conf。
[bigdata_admin@hadoop102 flume]$ mkdir job
[bigdata_admin@hadoop102 flume]$ vim job/file_to_kafka.conf
配置文件内容如下:
#为各组件命名
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = ?i1
a1.sources.r1.interceptors.i1.type = com.bigdata_admin.flume.interceptor.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1(2)分发配置文件到hadoop103
[bigdata_admin@hadoop102 flume]$ xsync?job
2)编写Flume拦截器
(1)创建Maven工程flume-interceptor
(2)创建包:com.bigdata_admin.flume.interceptor
(3)在pom.xml文件中添加如下配置
<dependencies>
????<dependency>
????????<groupId>org.apache.flume</groupId>
????????<artifactId>flume-ng-core</artifactId>
????????<version>1.9.0</version>
????????<scope>provided</scope>
????</dependency>
????<dependency>
????????<groupId>com.alibaba</groupId>
????????<artifactId>fastjson</artifactId>
????????<version>1.2.62</version>
????</dependency>
</dependencies>
<build>
????<plugins>
????????<plugin>
????????????<artifactId>maven-compiler-plugin</artifactId>
????????????<version>2.3.2</version>
????????????<configuration>
????????????????<source>1.8</source>
????????????????<target>1.8</target>
????????????</configuration>
????????</plugin>
????????<plugin>
????????????<artifactId>maven-assembly-plugin</artifactId>
????????????<configuration>
????????????????<descriptorRefs>
????????????????????<descriptorRef>jar-with-dependencies</descriptorRef>
????????????????</descriptorRefs>
????????????</configuration>
????????????<executions>
????????????????<execution>
????????????????????<id>make-assembly</id>
????????????????????<phase>package</phase>
????????????????????<goals>
????????????????????????<goal>single</goal>
????????????????????</goals>
????????????????</execution>
????????????</executions>
????????</plugin>
????</plugins>
</build>(4)在com.bigdata_admin.flume.interceptor包下创建JSONUtils类
package com.bigdata_admin.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
public class JSONUtils {
????public static boolean isJSONValidate(String log){
????????try {
????????????JSON.parse(log);
????????????return true;
????????}catch (JSONException e){
????????????return false;
????????}
????}
}(5)在com.bigdata_admin.flume.interceptor包下创建ETLInterceptor类
package com.bigdata_admin.flume.interceptor;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
????@Override
????public void initialize() {
????}
????@Override
????public Event intercept(Event event) {
????????byte[] body = event.getBody();
????????String log = new String(body, StandardCharsets.UTF_8);
????????if (JSONUtils.isJSONValidate(log)) {
????????????return event;
????????} else {
????????????return null;
????????}
????}
????@Override
????public List<Event> intercept(List<Event> list) {
????????Iterator<Event> iterator = list.iterator();
????????while (iterator.hasNext()){
????????????Event next = iterator.next();
????????????if(intercept(next)==null){
????????????????iterator.remove();
????????????}
????????}
????????return list;
????}
????public static class Builder implements Interceptor.Builder{
????????@Override
????????public Interceptor build() {
????????????return new ETLInterceptor();
????????}
????????@Override
????????public void configure(Context context) {
????????}
????}
????@Override
????public void close() {
????}
}(6)打包
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
(7)需要先将打好的包放入到hadoop102和hadoop103的/opt/module/flume/lib文件夹下面。
1.3.3 日志采集Flume测试
1)启动Zookeeper、Kafka集群
2)启动hadoop102的日志采集Flume
[bigdata_admin@hadoop102 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
3)启动一个Kafka的Console-Consumer
[bigdata_admin@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log
4)生成模拟数据
[bigdata_admin@hadoop102 ~]$ lg.sh
5)观察Kafka消费者是否能消费到数据
1.3.4 日志采集Flume启停脚本
1)分发日志采集Flume配置文件和拦截器
若上述测试通过,需将hadoop102节点的Flume的配置文件和拦截器jar包,向另一台日志服务器发送一份。
[bigdata_admin@hadoop102 flume]$ scp -r job hadoop103:/opt/module/flume/
[bigdata_admin@hadoop102 flume]$ scp lib/flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar hadoop103:/opt/module/flume/lib/
2)方便起见,此处编写一个日志采集Flume进程的启停脚本
(1)在hadoop102节点的/home/bigdata_admin/bin目录下创建脚本f1.sh
[bigdata_admin@hadoop102 bin]$ vim f1.sh
在脚本中填写如下内容。
#!/bin/bash
case $1 in
"start"){
????????for i in hadoop102 hadoop103
????????do
????????????????echo " --------启动 $i 采集flume-------"
????????????????ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
????????done
};;
"stop"){
????????for i in hadoop102 hadoop103
????????do
????????????????echo " --------停止 $i 采集flume-------"
????????????????ssh $i "ps -ef | grep file_to_kafka | grep -v grep |awk ?'{print \$2}' | xargs -n1 kill -9 "
????????done
};;
esac(2)增加脚本执行权限
[bigdata_admin@hadoop102 bin]$ chmod 777 f1.sh
(3)f1启动
[bigdata_admin@hadoop102 module]$ f1.sh start
(4)f2停止
[bigdata_admin@hadoop102 module]$ f1.sh stop
1.4 日志消费Flume
1.4.1 日志消费Flume配置概述
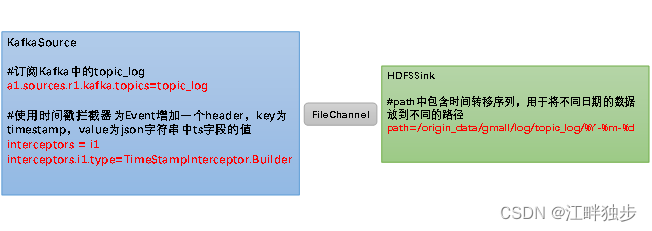
按照规划,该Flume需将Kafka中topic_log的数据发往HDFS。并且对每天产生的用户行为日志进行区分,将不同天的数据发往HDFS不同天的路径。
此处选择KafkaSource、FileChannel、HDFSSink。
关键配置如下:
1.4.2 日志消费Flume配置实操
1)创建Flume配置文件
在hadoop104节点的Flume的job目录下创建kafka_to_hdfs_log.conf。
[bigdata_admin@hadoop104 flume]$ vim job/kafka_to_hdfs_log.conf
配置文件内容如下:
## 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.bigdata_admin.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1注:配置优化
(1)FileChannel优化
通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。
官方说明如下:
Comma?separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据。
(2)HDFS Sink优化
①HDFS存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,影响Namenode性能和使用寿命。
计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能。同时也影响磁盘寻址时间。
②HDFS小文件处理
官方默认的这三个参数配置写入HDFS后会产生小文件,hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount。
基于以上hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount?=0几个参数综合作用,效果如下:
- 文件在达到128M时会滚动生成新文件
- 文件创建超3600秒时会滚动生成新文件
2)编写Flume拦截器
(1)在com.bigdata_admin.flume.interceptor包下创建TimeStampInterceptor类
package com.bigdata_admin.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor {
????private ArrayList<Event> events = new ArrayList<>();
????@Override
????public void initialize() {
????}
????@Override
????public Event intercept(Event event) {
????????Map<String, String> headers = event.getHeaders();
????????String log = new String(event.getBody(), StandardCharsets.UTF_8);
????????JSONObject jsonObject = JSONObject.parseObject(log);
????????String ts = jsonObject.getString("ts");
????????headers.put("timestamp", ts);
????????return event;
????}
????@Override
????public List<Event> intercept(List<Event> list) {
????????events.clear();
????????for (Event event : list) {
????????????events.add(intercept(event));
????????}
????????return events;
????}
????@Override
????public void close() {
????}
????public static class Builder implements Interceptor.Builder {
????????@Override
????????public Interceptor build() {
????????????return new TimeStampInterceptor();
????????}
????????@Override
????????public void configure(Context context) {
????????}
????}
}(2)重新打包
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
(3)需要先将打好的包放入到hadoop104的/opt/module/flume/lib文件夹下面。
1.4.3 日志消费Flume测试
1)启动Zookeeper、Kafka集群
2)启动日志采集Flume
[bigdata_admin@hadoop102 ~]$ f1.sh start
3)启动hadoop104的日志消费Flume
[bigdata_admin@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_log.conf -Dflume.root.logger=info,console
4)生成模拟数据
[bigdata_admin@hadoop102 ~]$ lg.sh
5)观察HDFS是否出现数据
1.4.4 日志消费Flume启停脚本
若上述测试通过,为方便,此处创建一个Flume的启停脚本。
1)在hadoop102节点的/home/bigdata_admin/bin目录下创建脚本f2.sh
[bigdata_admin@hadoop102 bin]$ vim f2.sh
在脚本中填写如下内容:
#!/bin/bash
case $1 in
"start")
????????echo " --------启动 hadoop104 日志数据flume-------"
????????ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")
????????echo " --------停止 hadoop104 日志数据flume-------"
????????ssh hadoop104 "ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac2)增加脚本执行权限
[bigdata_admin@hadoop102 bin]$ chmod 777 f2.sh
3)f2启动
[bigdata_admin@hadoop102 module]$ f2.sh start
4)f2停止
[bigdata_admin@hadoop102 module]$ f2.sh stop
1.5 采集通道启动/停止脚本
1)在/home/bigdata_admin/bin目录下创建脚本cluster.sh
[bigdata_admin@hadoop102 bin]$ vim cluster.sh
在脚本中填写如下内容:
#!/bin/bash
case $1 in
"start"){
????????echo ================== 启动 集群 ==================
????????#启动 Zookeeper集群
????????zk.sh start
????????#启动 Hadoop集群
????????cdh.sh start
????????#启动 Kafka采集集群
????????kf.sh start
????????#启动 Flume采集集群
????????f1.sh start
????????#启动 Flume消费集群
????????f2.sh start
????????};;
"stop"){
????????echo ================== 停止 集群 ==================
????????#停止 Flume消费集群
????????f2.sh stop
????????#停止 Flume采集集群
????????f1.sh stop
????????#停止 Kafka采集集群
????????kf.sh stop
????????#停止 Hadoop集群
????????cdh.sh stop
#循环直至 Kafka 集群进程全部停止
#xcall.sh 是我们写的脚本,作用是在集群的每个节点都执行一次后面的命令。此处 xcall.sh jps 的作用是查看所有节点的 java?进程
#grep?Kafka?的作用是过滤所有 Kafka?进程
#wc?-l?是统计行数,每个进程会在 jps?中单独占据一行,因此行数等于进程数
#$()的作用是将括号内命令的执行结果作为值取出来
#因此如下命令的作用是统计集群未停止的 Kafka?进程数然后将进程数赋值给 kafka_count 变量
kafka_count=$(xcall.sh jps | grep Kafka | wc -l)
#判断 kafka_count?变量的值是否大于零,如果是则说明仍有未停止的 Kafka?进程,此时不能停止 Zookeeper,因为 Kafka?的工作要依赖于 Zookeeper?的节点,如果在?Kafka?进程停止之前停止了 Zookeeper,可能会导致本次 Kafka?进程无法正常停止。所以当 Kafka?进程数大于零时进入循环,休眠一秒,然后重新统计 Kafka?进程数,直至 Kafka?进程数为零跳出循环,才能进行下一步(停止 Zookeeper?集群)
while [ $kafka_count -gt 0 ]
do
sleep 1
kafka_count=$(?xcall.sh jps | grep Kafka | wc -l)
????????????echo "当前未停止的 Kafka 进程数为 $kafka_count"
done
????????#停止 Zookeeper集群
????????zk.sh stop
};;
esac2)增加脚本执行权限
[bigdata_admin@hadoop102 bin]$ chmod u+x cluster.sh
3)cluster集群启动脚本
[bigdata_admin@hadoop102 module]$ cluster.sh start
4)cluster集群停止脚本
[bigdata_admin@hadoop102 module]$ cluster.sh stop