CDH安装好后,需要进一步设置hive及spark,CDH安装部署参考
CDH安装部署
1、hive安装
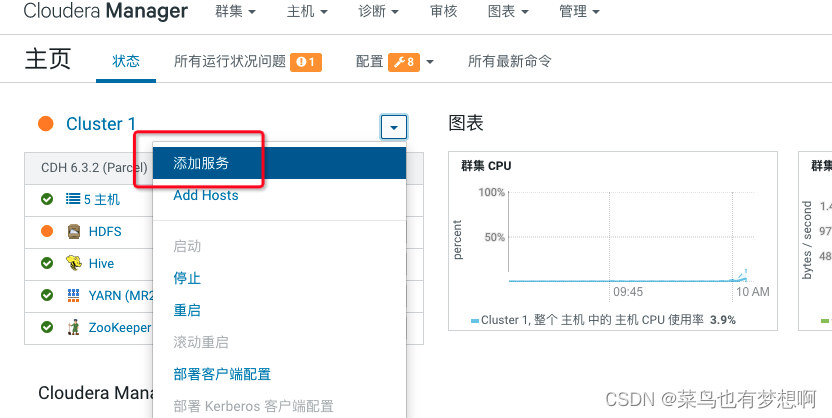
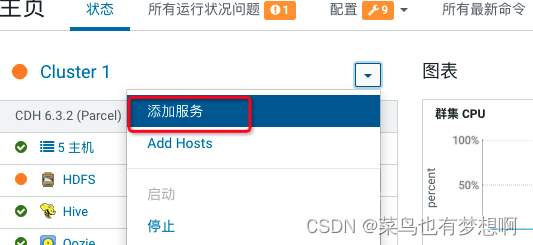
1.1 添加服务
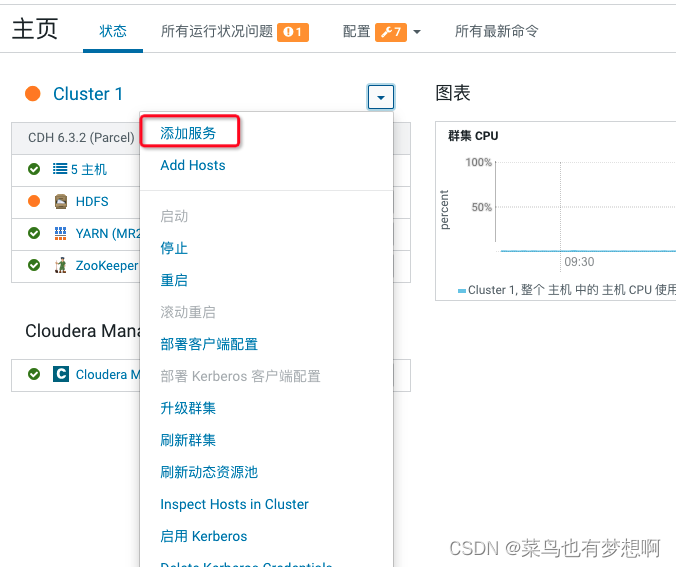
1.2 添加hive服务
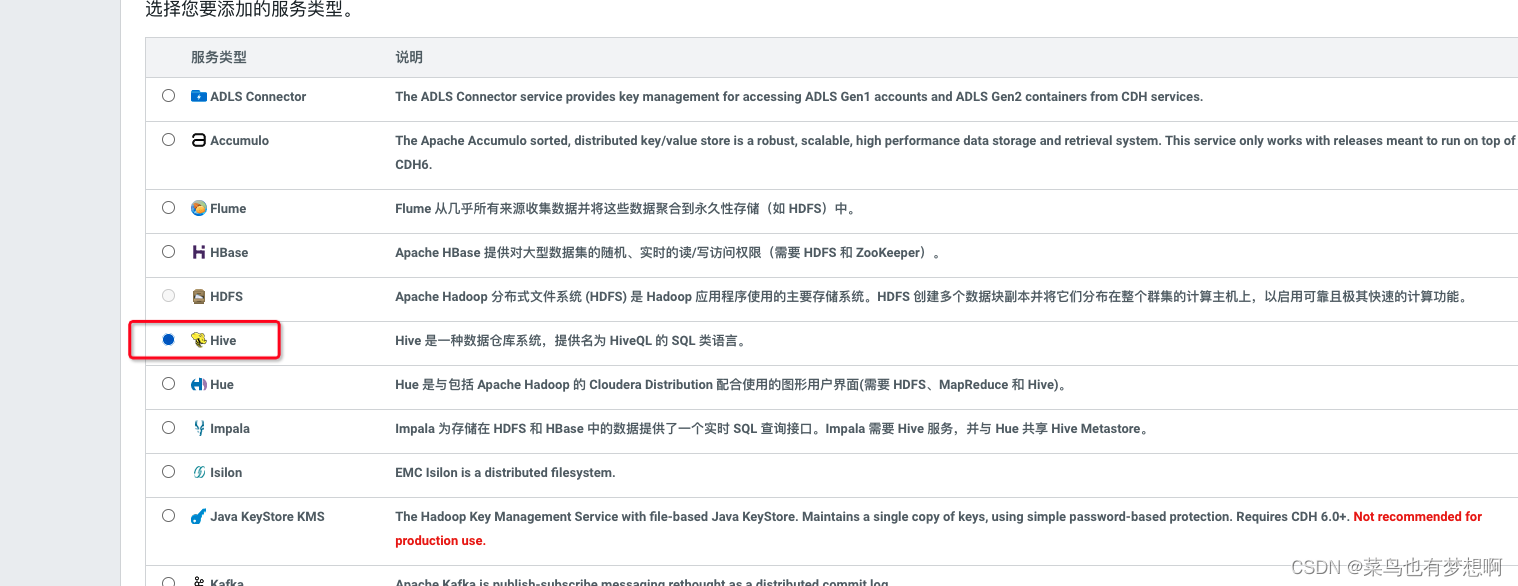
1.3 将hive服务添加到集群
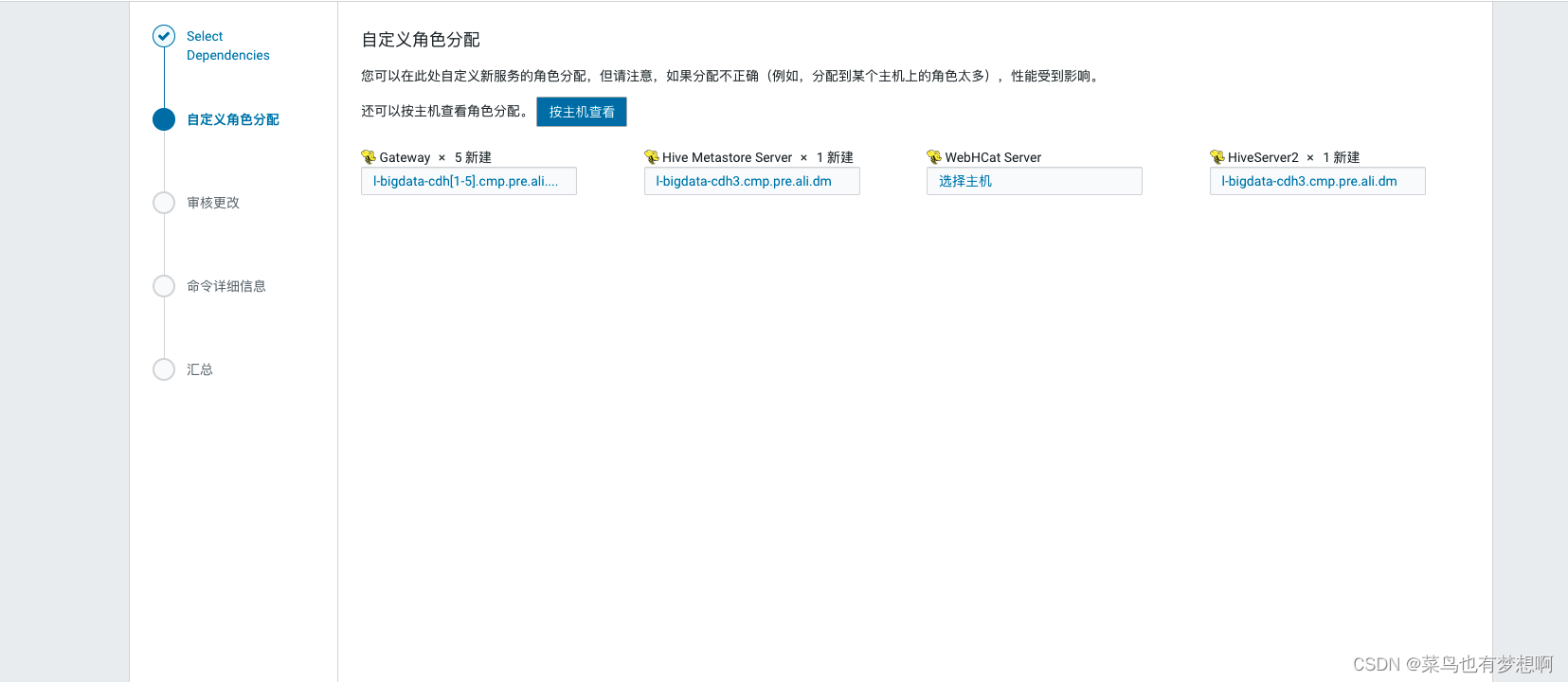
1.4 配置hive元数据

继续
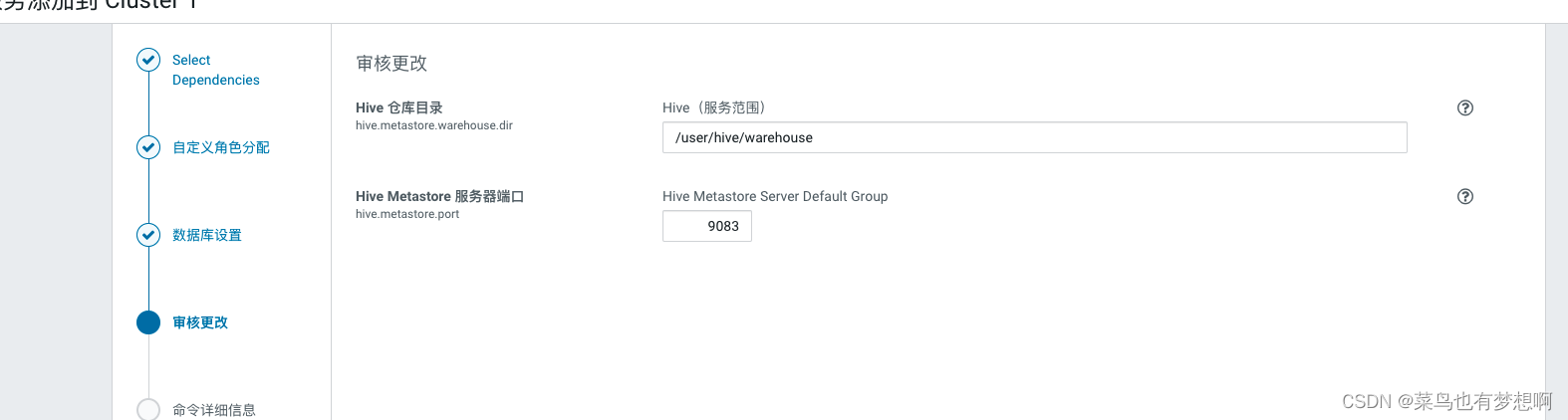
1.5 自动启动hive进程
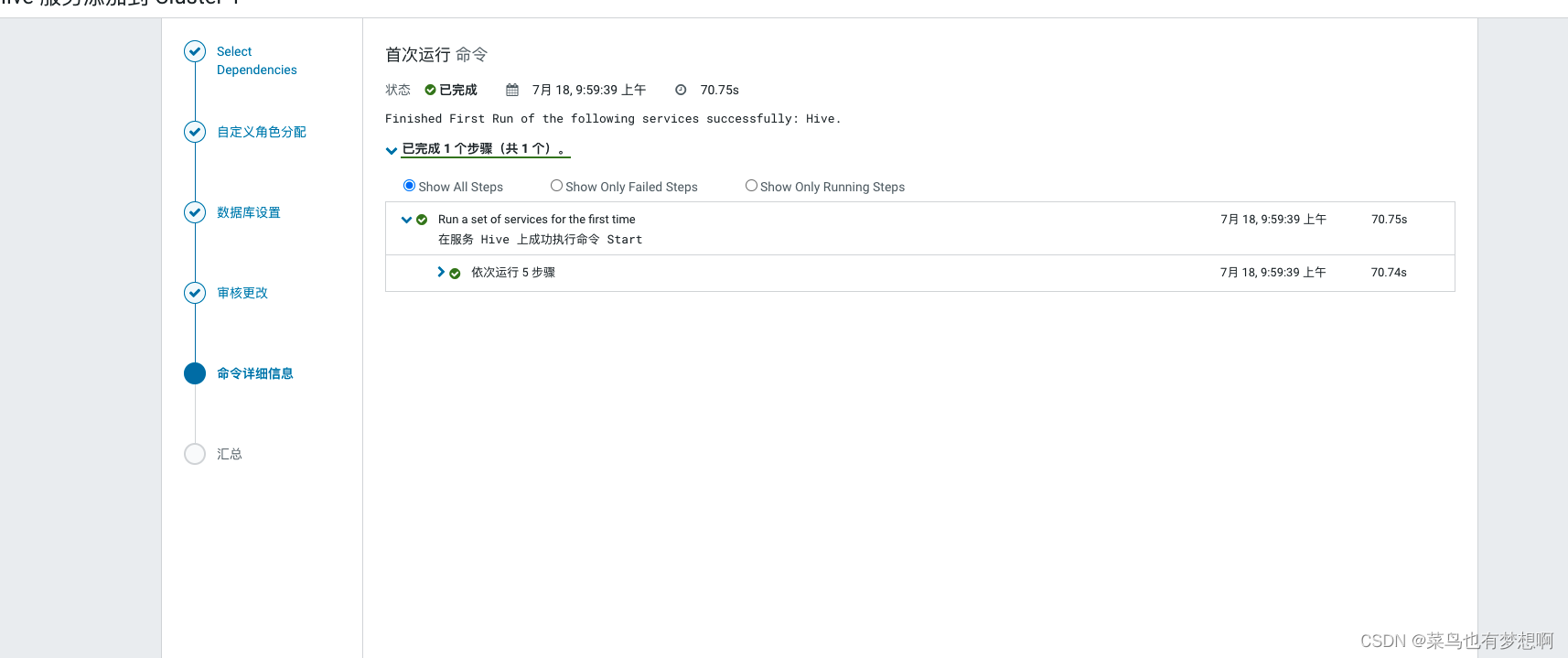
2 spark安装
CDH6.X自带spark2.4 无需升级
2.1 安装spark

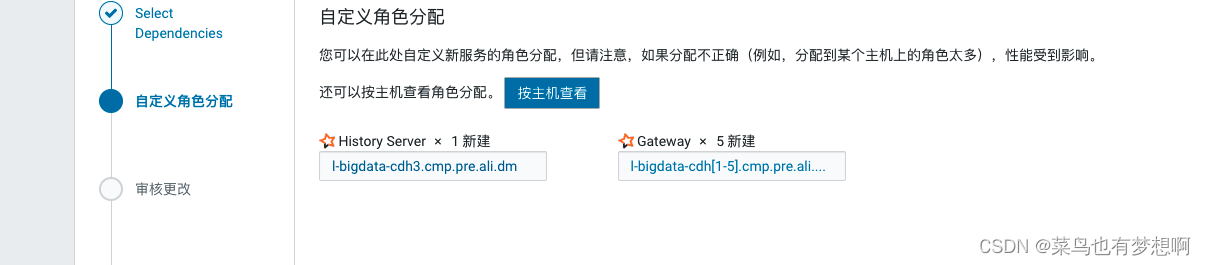
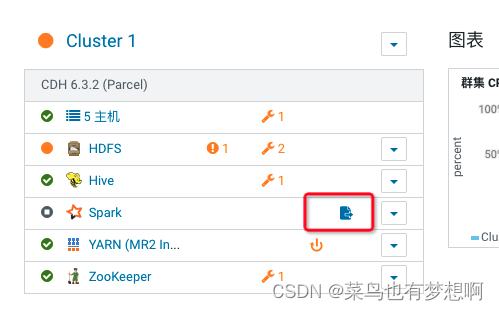
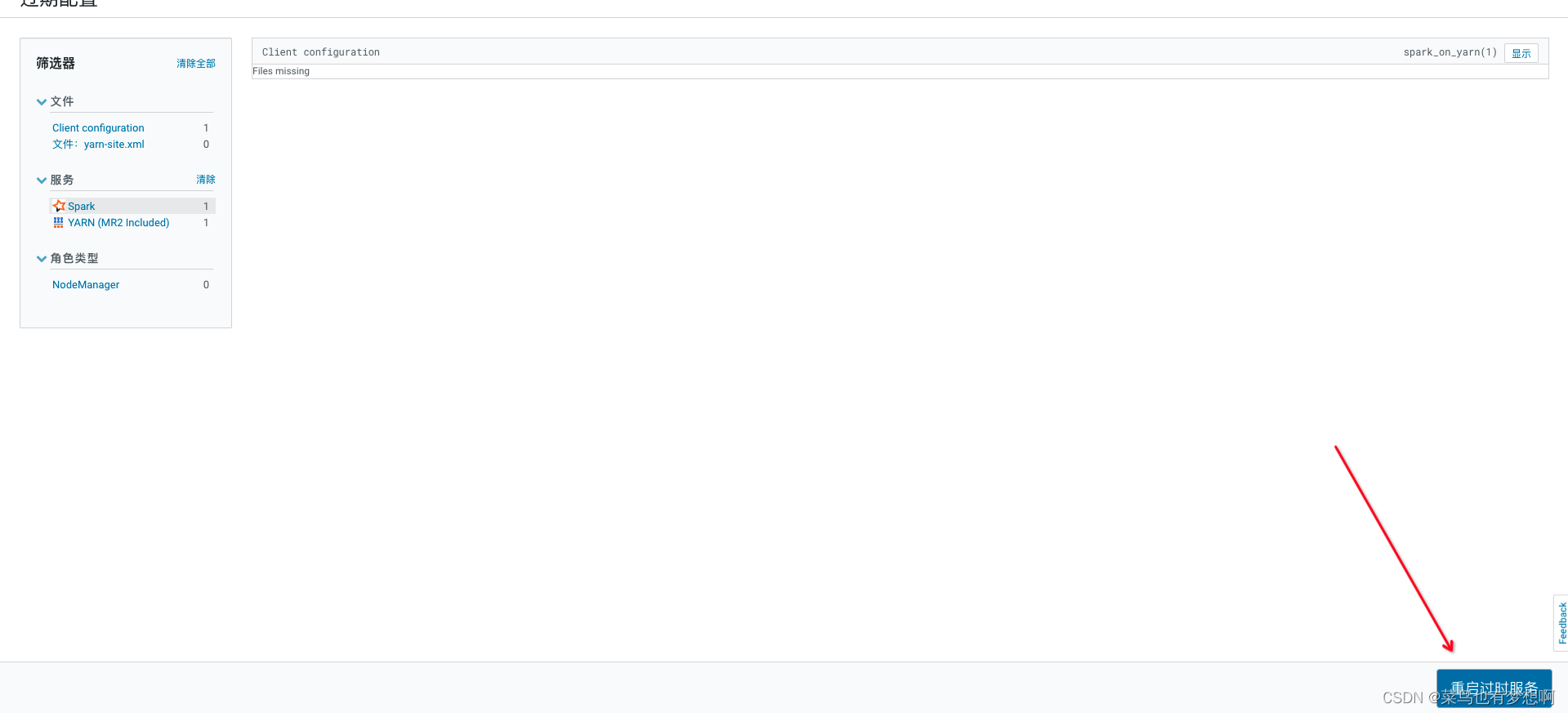
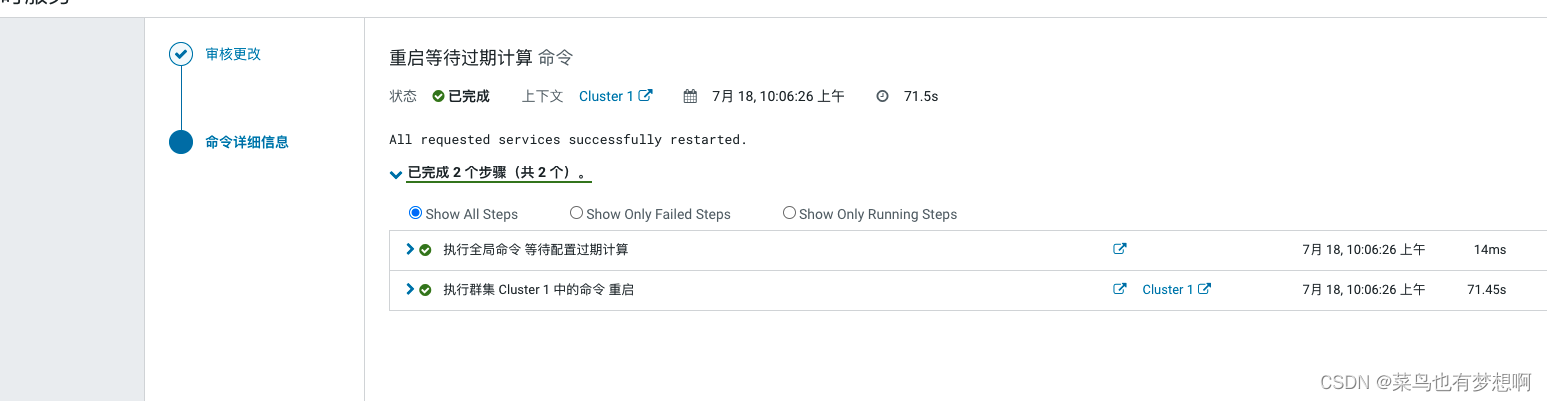
配置完成
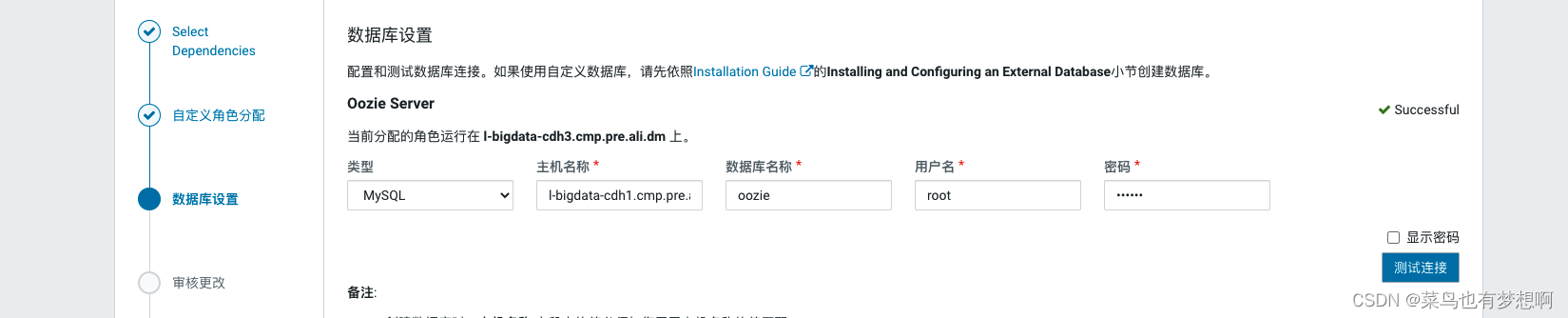
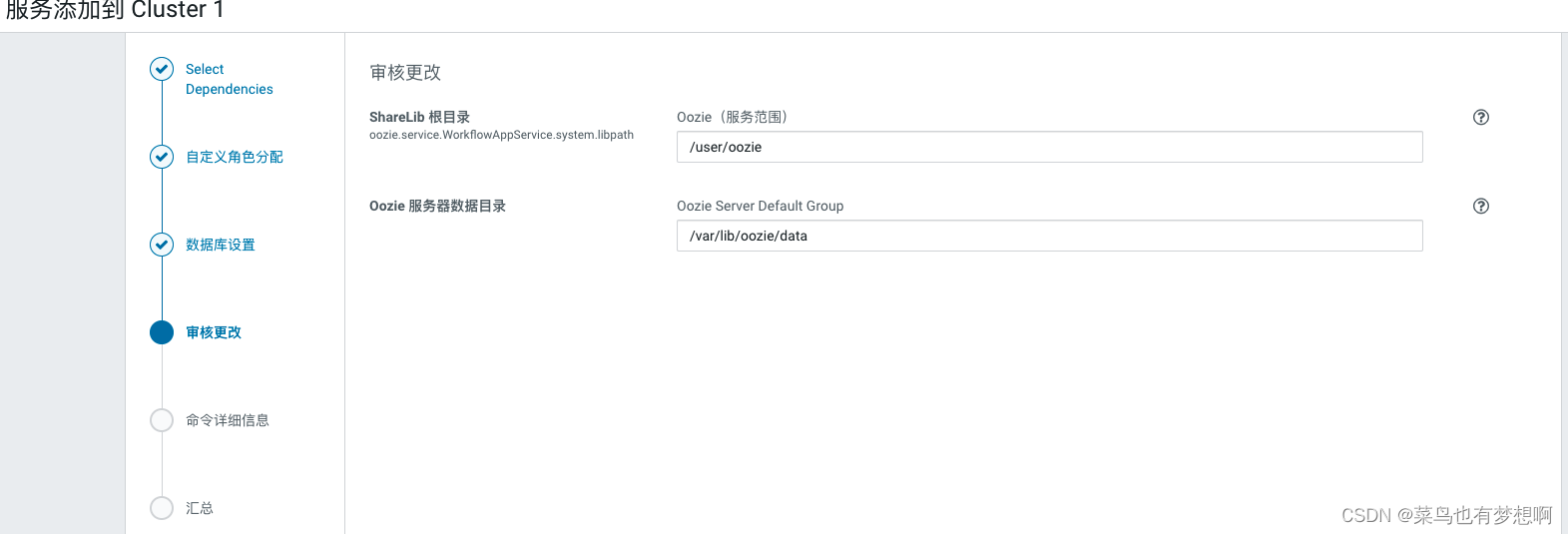
3 oozie配置


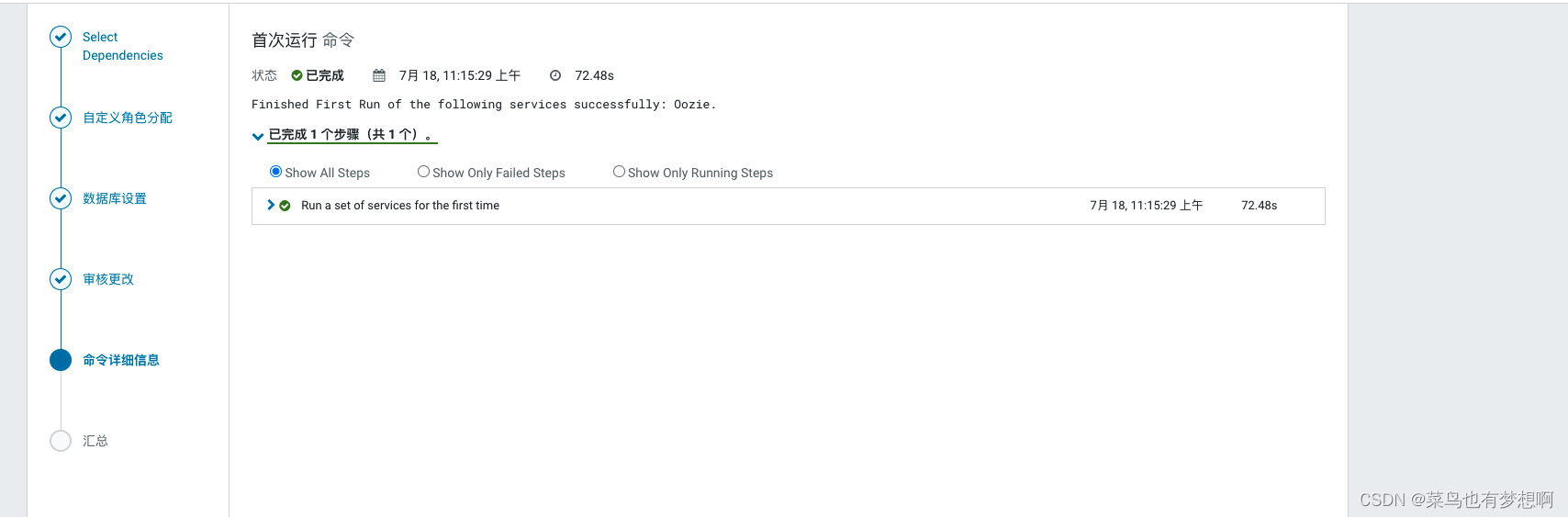
4 配置hue


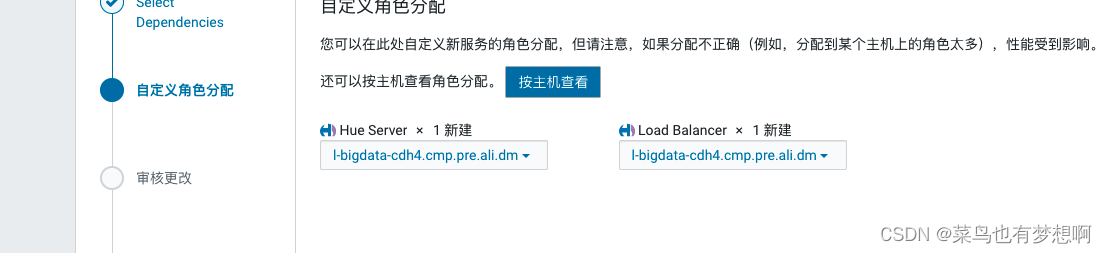

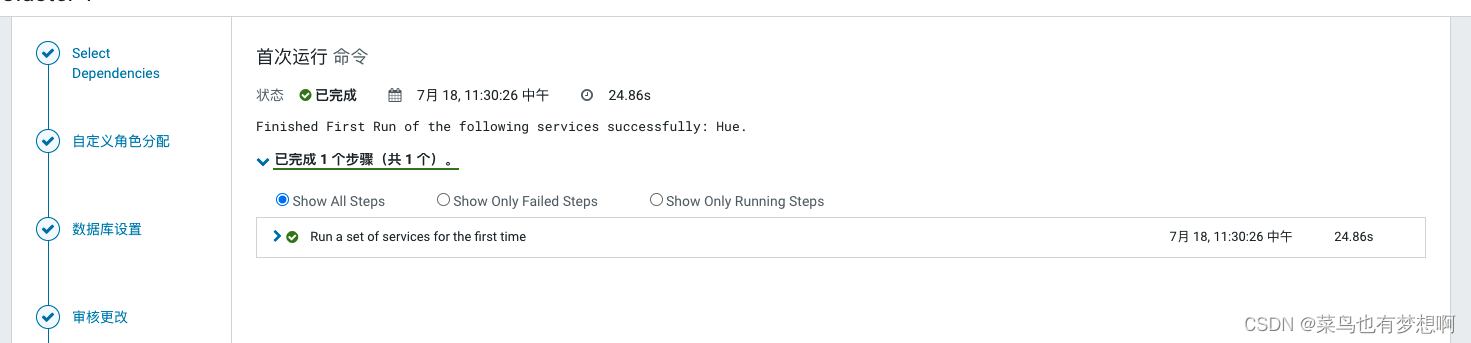

5 sqoop配置
和其余组件一样
6 其余配置
6.1 HDFS配置域名访问
因为服务器是阿里云的服务器,Hadoop集群必须用域名访问,不能ip访问,需要进行配置
dfs.client.use.datanode.hostname

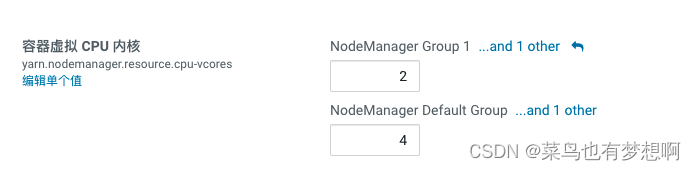
6.2设置物理核与虚拟核占比
当前机器的物理核分别是 4 4 8 8 8,因为是测试环境,可以略微扩大比例,生成环境是1:2 或1:2
>修改配置,每台服务器物理核2或4
yarn.nodemanager.resource.cpu-vcores
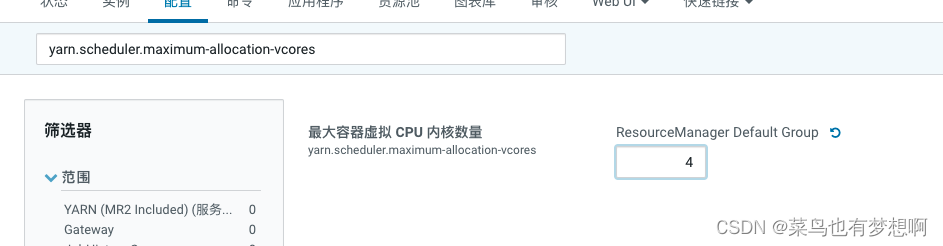
6.3 修改单个容器下最大cpu申请资源
修改yarn.scheduler.maximum-allocation-vcores为4
6.4 设置每个任务容器内存大小和单节点大小
将每个任务容器默认大小增大,物理内存为8的情况下 设置每个yarn可用内存为7
yarn.scheduler.maximum-allocation-mb
此处机器性能不佳 不做调整
yarn.nodemanager.resource.memory-mb
此处同样不做调整
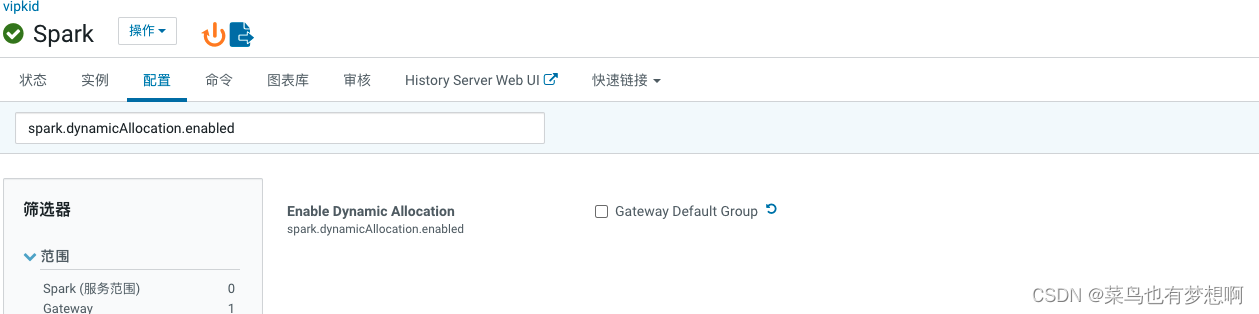
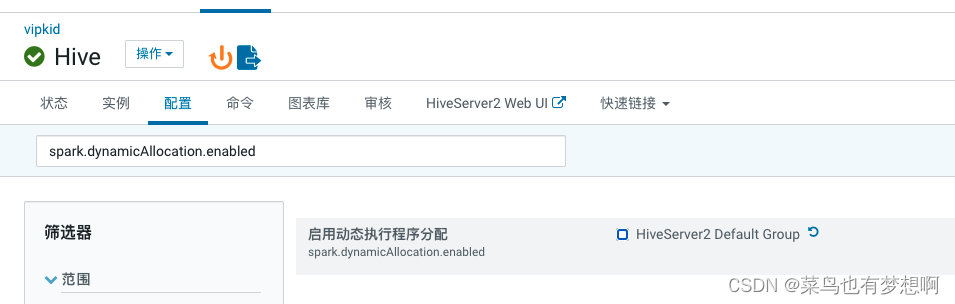
6.5 关闭spark动态分配资源参数
关闭此配置spark.dynamicAllocation.enabled
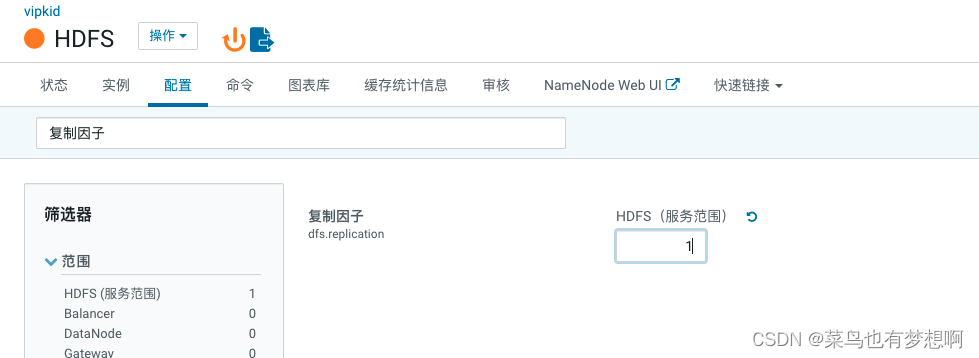
6.6 修改hdfs副本数
修改为1即可 修改复制因子
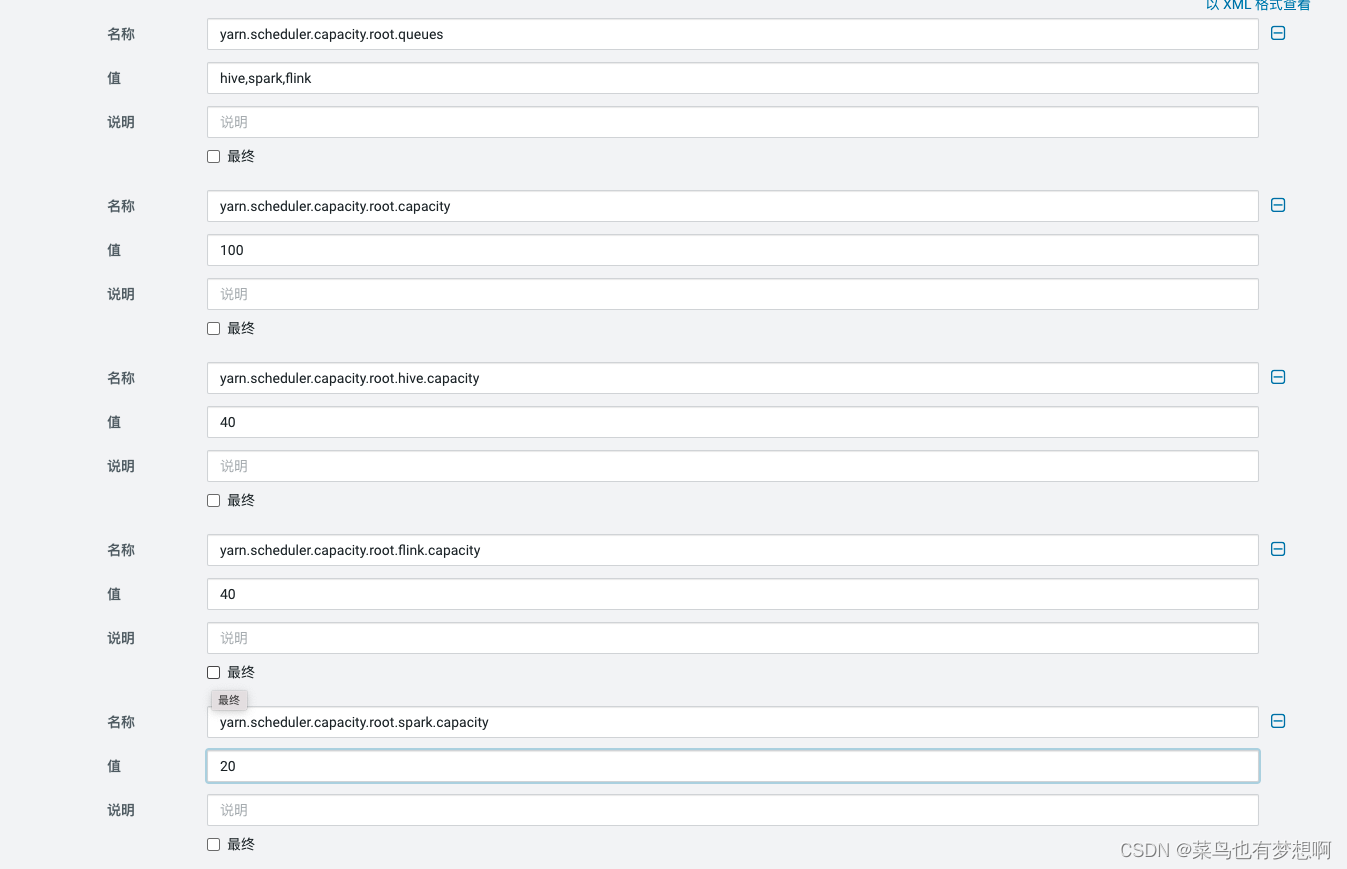
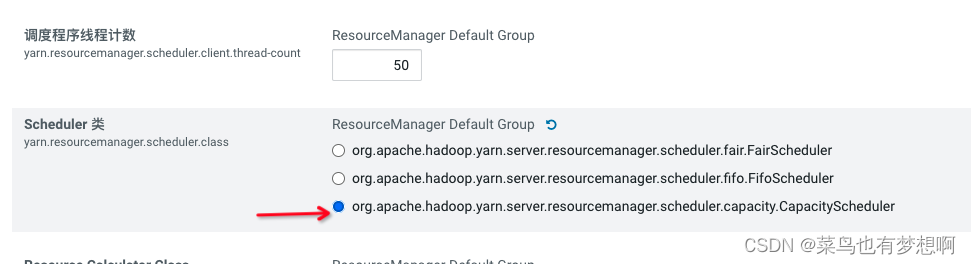
6.7 设置容量调度器
CDH默认公平调度,虽然在生成环境最好使用公平 ,但是测试环境容量调度会更有优势
6.8 增加队列
暂时通过页面直接增加hive、flink、spark队列,后续可使用api的方式增加