数据清洗
背景及意义
? ? ? ? 当数据供给方将数据发布到一个位置后,我们采集到数据。但往往我们采集到的数据会有这样那样的问题,例如有很多完全重复的数据、数据中的某个字段的某个值是空值、数据中出现了异常值等等。我们为了能让数据完美的服务于各项业务需求,我们要对出现问题的数据进行特殊处理,最终使得处理后的数据不存在这样那样的问题----也就是进行数据清洗。
方案的选择
? ? ? ? 现在不仅能通过许多语言开发的脚本完成数据清洗的逻辑(功能),还可以通过许多ETL工具完成复杂的数据清洗逻辑。而我们具体选择的数据清洗方案要根据实际业务需求并综合考量不同方案下数据清洗的效率、准确度等众多因素。
有图有真相? ? ?
????????本文所清洗的数据依然是世界疫情数据,清洗之前观察一下原始数据中的数据大概有怎样的特点和问题,下面是本次清洗的原始数据部分截图:
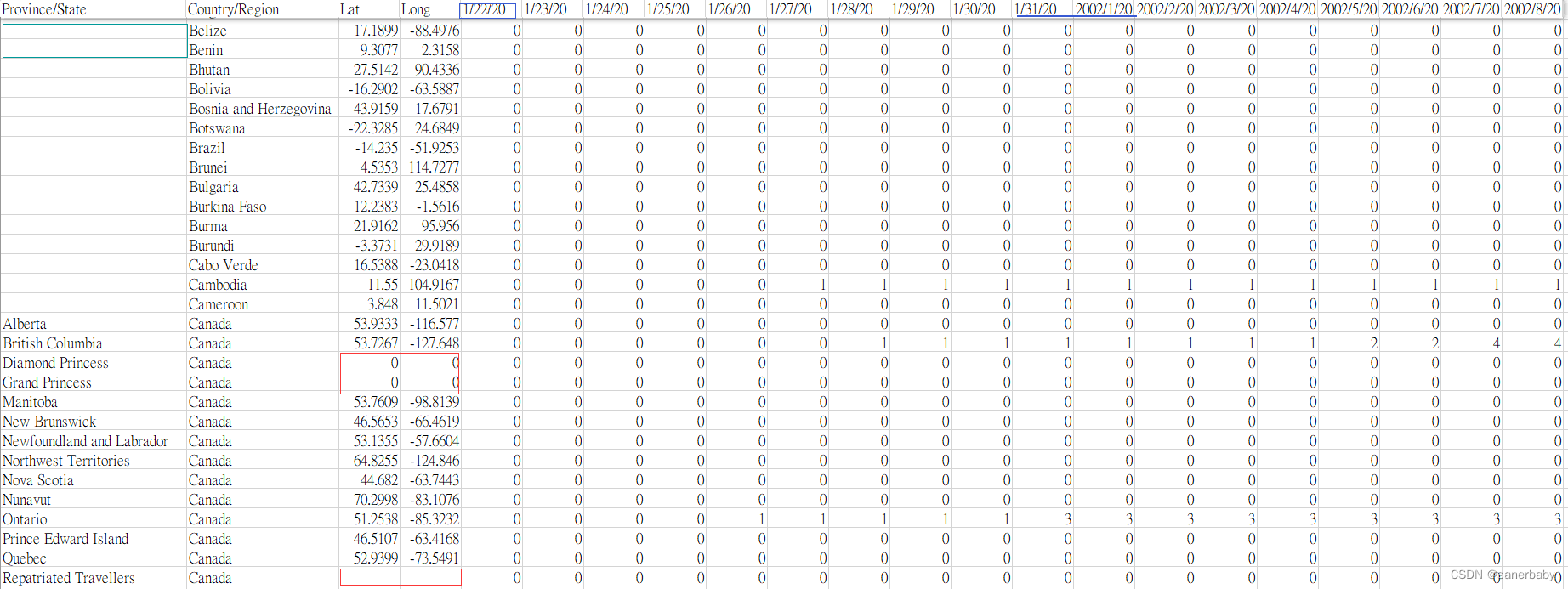 ? ? ? ?我们首先不考虑业务,就单纯的观察原始数据。发现有三列的数据存在空值字段(“Province/State”、“Lat”、“Long”),且文件第一行中日期的表达方式并不一致,"Lat"和"Long"两个字段存在值为“0”的字段,简单的观察后就只发现这些,那么我们分析一下这些问题需不需要调整。
? ? ? ?我们首先不考虑业务,就单纯的观察原始数据。发现有三列的数据存在空值字段(“Province/State”、“Lat”、“Long”),且文件第一行中日期的表达方式并不一致,"Lat"和"Long"两个字段存在值为“0”的字段,简单的观察后就只发现这些,那么我们分析一下这些问题需不需要调整。
对于本次的清洗,要考虑的点就一个。
存在问题的字段是否对后面的业务实现有影响,有则处理,无则pass。
? ? ? 1. “Province/State”这列代表的省/州的名称,存在空值就证明这个国家无省/州,这部分的空值的存在是合理的,且后面的业务分析也仅包含对于国内各省数据的分析,所以“Province/State”这列字段的值是不需要进行调整的;
? ? ? 2. “Lat”、“Long”这两个字段代表当前国家或这个国家的这个省/州所在地球上的经纬度。这部分的话我们要考虑是否要根据这个数据绘图,如果是那么要对数据进行调整处理。而我们对于分析结果的可视化实现使用的是Echarts的世界地图,其中的world.js文件中已经包含了各个国家所在的经纬度,换言之就是“Lat”、“Long”这两列字段的值我们是没有使用到的,所以这两列的数据依旧不需要进行调整修改。
? ? ? 3.?对于日期,我们这里暂时用hadate代表日期的字段名称,hadate我们需要考虑的点依旧有两个。首先是日期的表达方式不一样,这个是一定要调整的,除非后续的业务功能实现不需要日期这个字段---当然这是不可能的。其次我们要考虑使用怎样的日期格式来统一表达日期:
????????首先原始数据中的日期中是包含特殊符号"/"这个的,这个符号用来分隔年、月、日。如果使用带有这样的符号来统一表达日期,我们要明确数据分析过程中日期字段hadate是应用于什么,当hadate用于分组和聚合条件时,这样的用"/"表达日期时不影响数据分析的。而当日期字段hadate应用于计算时,由于“/”的存在影响了日期的值,我们无法使用这样的表达方式准确的将hadate用于计算,所以到这里结合业务我们已经可是舍弃用“/”这种表达日期的方案了。
? ? ? ? 既然存在特殊符号总会导致hadate应用于计算的准确性,那么我们就干脆用纯数字的方式表达日期,我们选择使用8位数字的表达方式来表示日期,前4位代表年份,五六位代表月份,七八位代表具体的日。
至此,所有的字段就已经观察分析好了,我们明确了数据清洗的方案,接下来准备实施
?上才艺
就像我们开头说的那样,通常数据的提供方是将数据发布到一个位置,我们采集这个位置的数据,然后对数据进行清洗或直接进行持久化操作。
这里默认数据提供方是将数据放到了某一台Linux主机上或是通过GitHub发布。我们采集清洗的流程就大概是:①flume(spooling directory source)采集目录文件->发送数据到Kafka的Topic->通过kafka ConsumerInterceptor消费者拦截器直接消费数据并完成对指定数据的调整修改并将修改后的数据持久化到磁盘。②直接Git到文件到指定的目录。然后还是上面一套流程,Git->flume(spooling directory source)采集目录文件->发送数据到Kafka的Topic->通过kafka ConsumerInterceptor消费者拦截器直接消费数据并完成对指定数据的调整修改并将修改后的数据持久化到
磁盘。
Kafka消费者拦截器实现简单的数据清洗
ps:这部分的很大部分是受到别人文章的启发,这里贴上原文链接,如有侵权,本人立马原地去世,感谢这位大佬的文章启发:CC00037.kafka――|Hadoop&kafka.V22|――|kafka.v22|消费者拦截器实验案例.v02|-pudn.com
环境:Zookeeper集群+Kafka集群(3台机器组成)
开发工具:idea
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yanqi</groupId>
<artifactId>com.yanqi.kafka.demo.consumer</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.2</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.25</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>拦截器OneInterceptor、TwoInterceptor、ThreeInterceptor
OneInterceptor.java
package com.yanqi.kafka.demo.interceptor;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Map;
public class OneInterceptor implements ConsumerInterceptor<String, String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
// poll方法返回结果之前最后要调用的方法
System.out.println("One -- 开始");
// 消息不做处理,直接返回
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
// 消费者提交偏移量的时候,经过该方法
System.out.println("One -- 结束");
}
@Override
public void close() {
// 用于关闭该拦截器用到的资源,如打开的文件,连接的数据库等
}
@Override
public void configure(Map<String, ?> configs) {
// 用于获取消费者的设置参数
configs.forEach((k, v) -> {
System.out.println(k + "\t" + v);
});
}
}TwoInterceptor.java
package com.yanqi.kafka.demo.interceptor;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Map;
public class TwoInterceptor implements ConsumerInterceptor<String, String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
// poll方法返回结果之前最后要调用的方法
System.out.println("Two -- 开始");
// 消息不做处理,直接返回
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
// 消费者提交偏移量的时候,经过该方法
System.out.println("Two -- 结束");
}
@Override
public void close() {
// 用于关闭该拦截器用到的资源,如打开的文件,连接的数据库等
}
@Override
public void configure(Map<String, ?> configs) {
// 用于获取消费者的设置参数
configs.forEach((k, v) -> {
System.out.println(k + "\t" + v);
});
}
}ThreeInterceptor.java
package com.yanqi.kafka.demo.interceptor;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Map;
public class ThreeInterceptor implements ConsumerInterceptor<String, String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
// poll方法返回结果之前最后要调用的方法
System.out.println("Three -- 开始");
// 消息不做处理,直接返回
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
// 消费者提交偏移量的时候,经过该方法
System.out.println("Three -- 结束");
}
@Override
public void close() {
// 用于关闭该拦截器用到的资源,如打开的文件,连接的数据库等
}
@Override
public void configure(Map<String, ?> configs) {
// 用于获取消费者的设置参数
configs.forEach((k, v) -> {
System.out.println(k + "\t" + v);
});
}
}消费者主程序
itConsumer.java
package com.yanqi.kafka.demo.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.io.*;
import java.util.*;
public class itConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "Hadoop303:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test-consumer-group");
// props.setProperty(ConsumerConfig.CLIENT_ID_CONFIG, "myclient");
// 如果在kafka中找不到当前消费者的偏移量,则设置为最旧的
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置拦截器
// One -> Two -> Three,接收消息和发送偏移量确认都是这个顺序
props.setProperty(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
"com.yanqi.kafka.demo.interceptor.OneInterceptor" +
",com.yanqi.kafka.demo.interceptor.TwoInterceptor" +
",com.yanqi.kafka.demo.interceptor.ThreeInterceptor"
);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
// 订阅主题
consumer.subscribe(Collections.singleton("tp_demo_01"));
//noinspection InfiniteLoopStatement
while (true) {
final ConsumerRecords<String, String> records = consumer.poll(3_000);
records.forEach(record -> {
System.out.println(record.topic());
System.out.println(record.partition());
System.out.println(record.offset());
System.out.println(record.key());
System.out.println(record.value());
String recccc = record.value();
String breathecc = record.value();
FileWriter writer;
try {
writer = new FileWriter("D:\\BIGDATA\\code\\tkafka.txt",true); // 如果已存在,以追加的方式写文件
String aa;
String bb;
String cc;
String dd;
String re;
String[] arr22 = new String[500];
String[] arr33 = new String[428];
if (recccc.contains(String.valueOf("/"))){
String arr3r[] =breathecc.split(",");
System.out.println( Arrays.toString(arr3r));
System.out.println( arr3r.length);
for (int i = 0;i<arr33.length;i++ ){
if(arr3r[i].length()<9 & arr3r[i].contains(String.valueOf("/2"))){
arr22 = arr3r[i].split("/");
aa = "20" + arr22[2] + "0"+ arr22[0] + arr22[1];
arr33[i] = aa;
}
else if (arr3r[i].length()>9 & arr3r[i].contains(String.valueOf("/2"))){
arr22 = arr3r[i].split("/");
bb = arr22[0] + arr22[1] + arr22[2];
arr33[i] = bb;
}
else if (arr3r[i].length()==9 & arr3r[i].contains(String.valueOf("/2"))) {
cc = arr3r[i];
arr22 = arr3r[i].split("/");
cc = arr22[0] + "0" + arr22[1] + arr22[2];
arr33[i] = cc;
}
else if (arr3r[i].contains(String.valueOf("e")) | arr3r[i].contains(String.valueOf("L"))) {
dd = arr3r[i];
arr33[i] = dd;
}
else {
System.out.println("^^");
}
}
System.out.println(Arrays.toString(arr33));
breathecc = Arrays.toString(arr33);
breathecc = breathecc.replace("[","");
breathecc = breathecc.replace("]","");
writer.write(breathecc+"\r\n");
writer.flush();
}
writer.write(recccc+"\r\n");
writer.flush();
writer.close()
// 我真棒,我是我自己的神
File inputFile = new File("D:\\BIGDATA\\code\\tkafka.txt");
File tempFile = new File("D:\\BIGDATA\\skafka.csv");
BufferedReader reader = new BufferedReader(new FileReader(inputFile));
BufferedWriter writer3 = new BufferedWriter(new FileWriter(tempFile));
String lineToRemove = "\uFEFFProvince/State,Country/Region,Lat,Long,1/22/20,1/23/20,1/24/20,1/25/20,1/26/20,1/27/20,1/28/20,1/29/20,1/30/20,1/31/20,2/1/20,2/2/20,2/3/20,2/4/20,2/5/20,2/6/20,2/7/20,2/8/20,2/9/20,2/10/20,2/11/20,2/12/20,2/13/20,2/14/20,2/15/20,2/16/20,2/17/20,2/18/20,2/19/20,2/20/20,2/21/20,2/22/20,2/23/20,2/24/20,2/25/20,2/26/20,2/27/20,2/28/20,2/29/20,3/1/20,3/2/20,3/3/20,3/4/20,3/5/20,3/6/20,3/7/20,3/8/20,3/9/20,3/10/20,3/11/20,3/12/20,3/13/20,3/14/20,3/15/20,3/16/20,3/17/20,3/18/20,3/19/20,3/20/20,3/21/20,3/22/20,3/23/20,3/24/20,3/25/20,3/26/20,3/27/20,3/28/20,3/29/20,3/30/20,3/31/20,4/1/20,4/2/20,4/3/20,4/4/20,4/5/20,4/6/20,4/7/20,4/8/20,4/9/20,4/10/20,4/11/20,4/12/20,4/13/20,4/14/20,4/15/20,4/16/20,4/17/20,4/18/20,4/19/20,4/20/20,4/21/20,4/22/20,4/23/20,4/24/20,4/25/20,4/26/20,4/27/20,4/28/20,4/29/20,4/30/20,5/1/20,5/2/20,5/3/20,5/4/20,5/5/20,5/6/20,5/7/20,5/8/20,5/9/20,5/10/20,5/11/20,5/12/20,5/13/20,5/14/20,5/15/20,5/16/20,5/17/20,5/18/20,5/19/20,5/20/20,5/21/20,5/22/20,5/23/20,5/24/20,5/25/20,5/26/20,5/27/20,5/28/20,5/29/20,5/30/20,5/31/20,6/1/20,6/2/20,6/3/20,6/4/20,6/5/20,6/6/20,6/7/20,6/8/20,6/9/20,6/10/20,6/11/20,6/12/20,6/13/20,6/14/20,6/15/20,6/16/20,6/17/20,6/18/20,6/19/20,6/20/20,6/21/20,6/22/20,6/23/20,6/24/20,6/25/20,6/26/20,6/27/20,6/28/20,6/29/20,6/30/20,7/1/20,7/2/20,7/3/20,7/4/20,7/5/20,7/6/20,7/7/20,7/8/20,7/9/20,7/10/20,7/11/20,7/12/20,7/13/20,7/14/20,7/15/20,7/16/20,7/17/20,7/18/20,7/19/20,7/20/20,7/21/20,7/22/20,7/23/20,7/24/20,7/25/20,7/26/20,7/27/20,7/28/20,7/29/20,7/30/20,7/31/20,8/1/20,8/2/20,8/3/20,8/4/20,8/5/20,8/6/20,8/7/20,8/8/20,8/9/20,8/10/20,8/11/20,8/12/20,8/13/20,8/14/20,8/15/20,8/16/20,8/17/20,8/18/20,8/19/20,8/20/20,8/21/20,8/22/20,8/23/20,8/24/20,8/25/20,8/26/20,8/27/20,8/28/20,8/29/20,8/30/20,8/31/20,9/1/20,9/2/20,9/3/20,9/4/20,9/5/20,9/6/20,9/7/20,9/8/20,9/9/20,9/10/20,9/11/20,9/12/20,9/13/20,9/14/20,9/15/20,9/16/20,9/17/20,9/18/20,9/19/20,9/20/20,9/21/20,9/22/20,9/23/20,9/24/20,9/25/20,9/26/20,9/27/20,9/28/20,9/29/20,9/30/20,10/1/20,10/2/20,10/3/20,10/4/20,10/5/20,10/6/20,10/7/20,10/8/20,10/9/20,10/10/20,10/11/20,10/12/20,10/13/20,10/14/20,10/15/20,10/16/20,10/17/20,10/18/20,10/19/20,10/20/20,10/21/20,10/22/20,10/23/20,10/24/20,10/25/20,10/26/20,10/27/20,10/28/20,10/29/20,10/30/20,10/31/20,11/1/20,11/2/20,11/3/20,11/4/20,11/5/20,11/6/20,11/7/20,11/8/20,11/9/20,11/10/20,11/11/20,11/12/20,11/13/20,11/14/20,11/15/20,11/16/20,11/17/20,11/18/20,11/19/20,11/20/20,11/21/20,11/22/20,11/23/20,11/24/20,11/25/20,11/26/20,11/27/20,11/28/20,11/29/20,11/30/20,12/1/20,12/2/20,12/3/20,12/4/20,12/5/20,12/6/20,12/7/20,12/8/20,12/9/20,12/10/20,12/11/20,12/12/20,12/13/20,12/14/20,12/15/20,12/16/20,12/17/20,12/18/20,12/19/20,12/20/20,12/21/20,12/22/20,12/23/20,12/24/20,12/25/20,12/26/20,12/27/20,12/28/20,12/29/20,12/30/20,12/31/20,1/1/21,1/2/21,1/3/21,1/4/21,1/5/21,1/6/21,1/7/21,1/8/21,1/9/21,1/10/21,1/11/21,1/12/21,1/13/21,1/14/21,1/15/21,1/16/21,1/17/21,1/18/21,1/19/21,1/20/21,1/21/21,1/22/21,1/23/21,1/24/21,1/25/21,1/26/21,1/27/21,1/28/21,1/29/21,1/30/21,1/31/21,2/1/21,2/2/21,2/3/21,2/4/21,2/5/21,2/6/21,2/7/21,2/8/21,2/9/21,2/10/21,2/11/21,2/12/21,2/13/21,2/14/21,2/15/21,2/16/21,2/17/21,2/18/21,2/19/21,2/20/21,2/21/21,2/22/21,2/23/21,2/24/21,2/25/21,2/26/21,2/27/21,2/28/21,3/1/21,3/2/21,3/3/21,3/4/21,3/5/21,3/6/21,3/7/21,3/8/21,3/9/21,3/10/21,3/11/21,3/12/21,3/13/21,3/14/21,3/15/21,3/16/21,3/17/21,3/18/21,3/19/21,3/20/21";
String currentLine;
while((currentLine = reader.readLine()) != null) {
// trim newline when comparing with lineToRemove
String trimmedLine = currentLine.trim();
if(trimmedLine.equals(lineToRemove)) continue;
writer3.write(currentLine + System.getProperty("line.separator"));
}
writer3.close();
reader.close();
boolean successful = tempFile.renameTo(inputFile);
System.out.println("完成");
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
}大概结构:
?详细介绍一下整体的运行思路和过程
下面我就用我自己启动运行时的命令:我的zk、flumekafka都是在/opt/module/下
我的flume的配置文件在flume下自己创建的job文件目录下
我的原始数据存储在/opt/learning/testdata/下
1. 首先启动Zookeeper集群的各个节点????????
cd /opt/module/zookeeper
[...../zookeeper] bin/zkServer.sh start2. 启动Kafka集群的各个节点
cd /opt/module/kafka
[..../kafka] bin/kafka-server-start.sh config/server.properties &3. 在生产和消费前,创建Kafka的topic
[..../kafka] bin/kafka-topics.sh --zookeeper Hadoop303:2181 \
--create --replication-factor 3 --partitions 1 --topic tp_demo_014.有了topic,我们就可以使用flume作为生产者向Kafka的主题发送数据了
①创建flume的配置文件
[..../flume] vim?cusint-dir-kafka.conf②把配置写入进去
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/learning/testdata
a3.sources.r3.deserializer=LINE
#a3.sources.r3.deserializer.maxLineLength=320000
a3.sources.r3.deserializer.maxLineLength=640000
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
#Describe the sink
#设置kafkaSink 注意大小写
a3.sinks.k3.type = org.apache.flume.sink.kafka.KafkaSink
#设置kafka的主题topic
a3.sinks.k3.topic = tp_demo_01
#设置消费者编码为UTF_8
#设置kafka 的 broker地址以及端口号
a3.sinks.k3.kafka.bootstrap.servers = Hadoop303:9092,Hadoop304:9092,Hadoop305:9092
#设置kafka序列化方式
a3.sinks.k3.serializer.class = kafka.serializer.StringEncoder
#use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
#Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3????????这里最终要的就是?a3.sources.r3.deserializer.maxLineLength=640000 这行,没什么含金量,但是比较重要,因为原始数据中有的行实在有点长,如果不设置的长一点,消费的过程是会出问题的。
③主题也有了,配置文件也写好了,下面就是启动flume的agent,向Kafka的topic发送数据----生产数据
[..../flume] bin/flume-ng agent --conf job/ --name a3 --conf-file job/cusint-dir-kafka.conf -Dflume.root.logger=INFO,console数据生产完后,控制台会有successful的字样,且原始数据文件的末尾也加上了?.COMPLETED这样的标识,这样,数据就生产好了,Kafka的控制台也会打印数据一些关于分区呀,偏移量什么什么的东西。至此生产过程顺利执行成功
5. 然后我们就可以启动消费者主程序,消费完成后idea的控制台会重复打印输出“结束”,这样就消费完成了,打开消费后生成的文件,发现文件中的日期已经全部转换成了8位数字表达的格式。
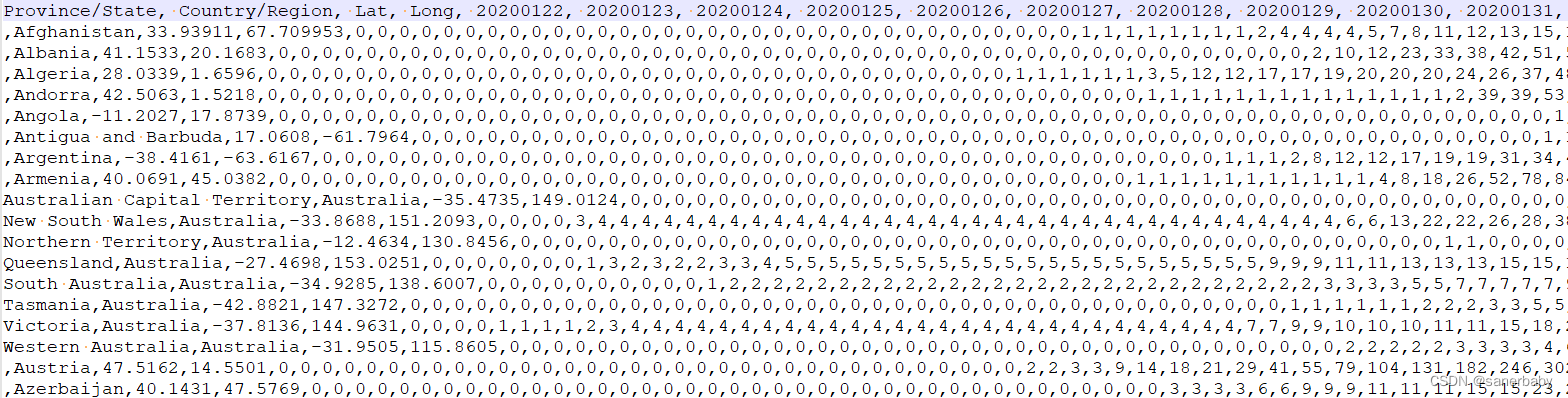
本人属实懒🐕,有一类的日期数据我少补了一个0,但是我也不想补了^^,反正大概的实现过程就是这样了
ending?
感谢各位大哥大姐分享的文章,受益匪浅,只要别人做的够牛,我就永远不会有瓶颈^^。