Ϊʲôѡ��Flume
flume����Ҫ�����þ���,ʵʱ��ȡ���������ش�������,������д�뵽HDFS��(������)
Flume�ܹ�
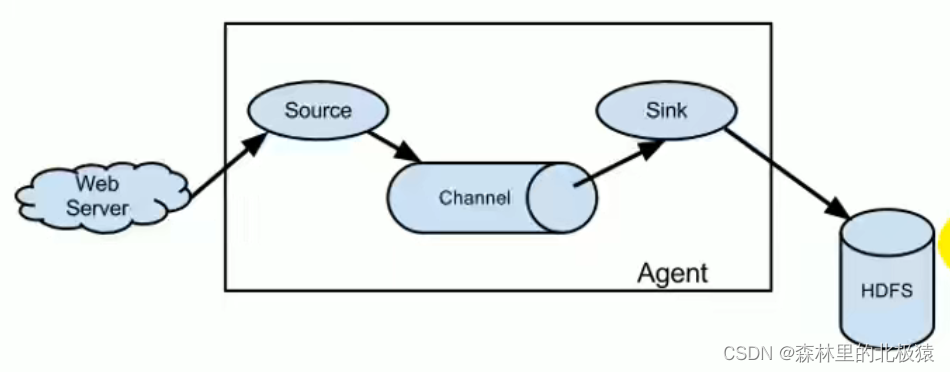
����1
��flume�½���һ���ļ�(�ļ�����һ�㶼��source-flume-sink,��������)
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000 //1000��������1000���¼�
a1.channels.c1.transactionCapacity = 100 //һ����ഫ100��ʱ��,����Ҫ���������
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
Ҫע������:
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
�����д�����������˼
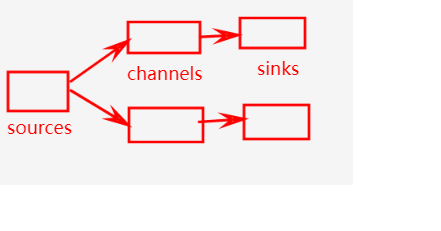
һ��source�ܹ��������channel,����һ��channelֻ�ܷ���һ��sink

shell��������
//������������,��ʾ
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template -Dflume.root.logger=INFO,console
//�ҵ�����
bin/flume-ng agent -n a1 -c conf/ -f job/net-flume-logger.co -Dflume.root.logger=INFO,console
�Cconf/-c:��ʾ�����ļ��洢�� conf/Ŀ¼
�Cname/-n:��ʾ�� agent ����Ϊ a1
�Cconf-file/-f:flume ����������ȡ�������ļ����� job �ļ����µ� flume-telnet.conf
�ļ���
-Dflume.root.logger=INFO,console :-D ��ʾ flume ����ʱ��̬�� flume.root.logger
��������ֵ,��������̨��־��ӡ��������Ϊ INFO ������־�������:log��info��warn��
error��

�����ɹ�
ʹ�� netcat �������� 44444 �˿ڷ�������

�� Flume ����ҳ��۲�����������

������(ʵʱ��ص������ļ�)
��������:ʵʱ��� Hive ��־,���ϴ��� HDFS ��
ʵʱ��ȡ�����ļ���HDFS
��������

ʵʩ����
��flume�µ�jobĿ¼�´���һ���ļ�
vim flume-file-hdfs.conf
��Ҫע�����:
Ҫ���ȡLinux���ļ�,�͵�Linux����Ĺ���ִ�����
����Hive����־����Linuxϵͳ��,���Զ�ȡ�ļ�������ѡ��Ϊexec(Ҳ����executor ִ���� ����˼)��
��ʾִ��Linux��������ȡ�ļ�
������Ϣ����
�鿴flume����
ѡ���û�ָ��
��Ϊ����Ҫ�ϴ��ļ���HDFS��,Ҳ����sink��ΪHDFS,���ǿ�����hdfs sink �鿴��Ҫʲô���ò���

# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
# ִ���ļ�������,execִ��Linux����,�鿴�ļ�
a2.sources.r2.type = exec
# �ļ���ִ������(����hive.log���û���ر�����Ĭ���� /tmp/root/hive.log)
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
# ���ﴴ��Ŀ¼(�����ļ�)
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H
#�ϴ��ļ���ǰ
a2.sinks.k2.hdfs.filePrefix = logs-
#�Ƿ���ʱ������ļ���
a2.sinks.k2.hdfs.round = true
#����ʱ�䵥λ����һ���µ��ļ���
a2.sinks.k2.hdfs.roundValue = 1
#���¶���ʱ�䵥λ
a2.sinks.k2.hdfs.roundUnit = hour
#�Ƿ�ʹ�ñ���ʱ���,����һ��Ҫtrue,��Ϊ���������õ���ʱ��
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#���ܶ��ٸ� Event �� flush �� HDFS һ��
a2.sinks.k2.hdfs.batchSize = 100
#�����ļ�����,��֧��ѹ��
a2.sinks.k2.hdfs.fileType = DataStream
#�������һ���µ��ļ�
a2.sinks.k2.hdfs.rollInterval = 30
#����ÿ���ļ��Ĺ�����С
a2.sinks.k2.hdfs.rollSize = 134217700
#�ļ��Ĺ����� Event ������
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2

��ʼ����
����flume����
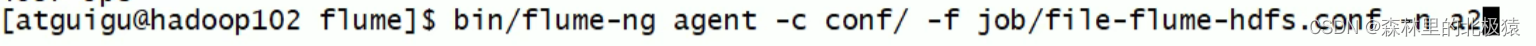
����hive,��hive�������,�鿴hdfs
�ļ�û��ˢ��ǰ����tmp,ֻҪ�ﵽ���趨�������ͻ����ļ�,����30s,128M,�ȵ�


ʵʱ���Ŀ¼�¶�����ļ�
ʹ�� Flume ��������Ŀ¼���ļ�,���ϴ��� HDFS,�˽�ϵ�����
�������
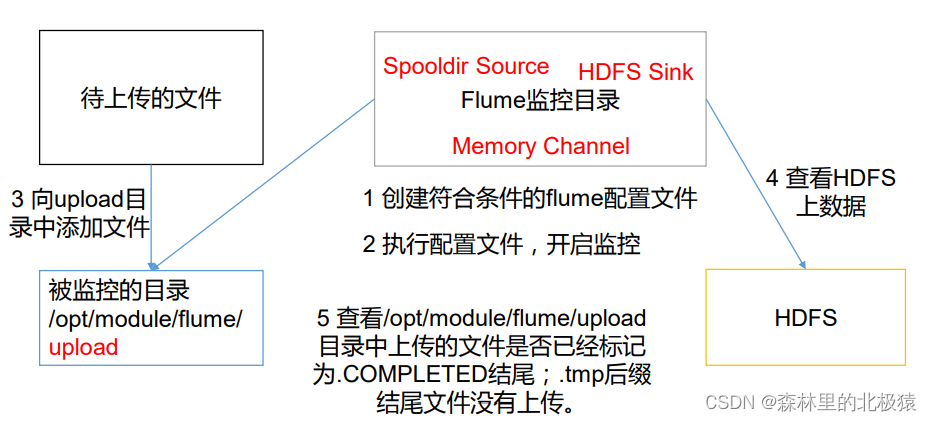
ʵ�ֲ���
- �����ļ���
[root@hadoop01 apache-flume-1.9.0-bin]# mkdir upload
- ��jobĿ¼�´����ļ�flume-dir-hdfs.conf
��������(�����ļ�)
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#����������.tmp ��β���ļ�,���ϴ�
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =
hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H
#�ϴ��ļ���ǰ
a3.sinks.k3.hdfs.filePrefix = upload-
#�Ƿ���ʱ������ļ���
a3.sinks.k3.hdfs.round = true
#����ʱ�䵥λ����һ���µ��ļ���
a3.sinks.k3.hdfs.roundValue = 1
#���¶���ʱ�䵥λ
a3.sinks.k3.hdfs.roundUnit = hour
#�Ƿ�ʹ�ñ���ʱ���
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#���ܶ��ٸ� Event �� flush �� HDFS һ��
a3.sinks.k3.hdfs.batchSize = 100
a3.sinks.k3.hdfs.fileType = DataStream
#�������һ���µ��ļ�
a3.sinks.k3.hdfs.rollInterval = 60
#����ÿ���ļ��Ĺ�����С����� 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#�ļ��Ĺ����� Event ������
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3

- �����ļ�
[root@hadoop01 apache-flume-1.9.0-bin]# bin/flume-ng agent -n a3 -c conf -f job/flume-dir-hdfs.conf
- �� upload �ļ����������ļ�
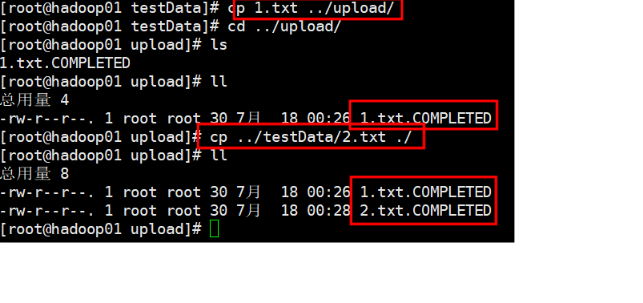
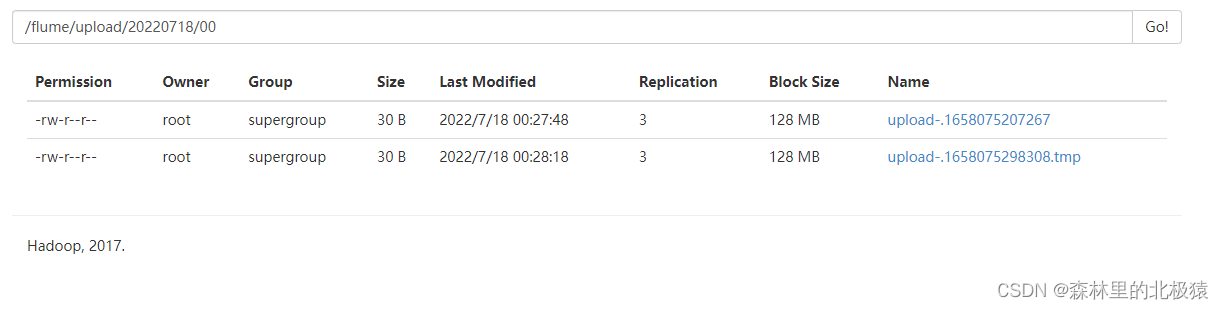
�ϴ��ɹ���������
.COMPLETED��β���ļ���,˵��flume�Ѿ������ļ��ϴ���,�Ժ��ټ�ء�
����,
��Ҫ�ڼ�ص�Ŀ¼�д��������ļ���
��ص��ļ���500����ɨ��һ�Ρ�
ʵʱ���Ŀ¼�µĶ�����ļ�
��������
ʹ�� Flume ��������Ŀ¼��ʵʱ���ļ�,���ϴ��� HDFS

ʵ�ֲ���
- ����
�������Ǵ�ӡ������̨��,ȥhdfsҲ��ͬ����һ��
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /export/servers/apache-flume-1.9.0-bin/testData/.*.txt
a1.sources.r1.positionFile = /export/servers/apache-flume-1.9.0-bin/position/position.json
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

2. �����������
[root@hadoop01 apache-flume-1.9.0-bin]# bin/flume-ng agent -n a1 -c conf/ -f ./job/flume-taildir-hdfs.conf -Dflume.root.logger=INFO,console
- ���ļ�����������
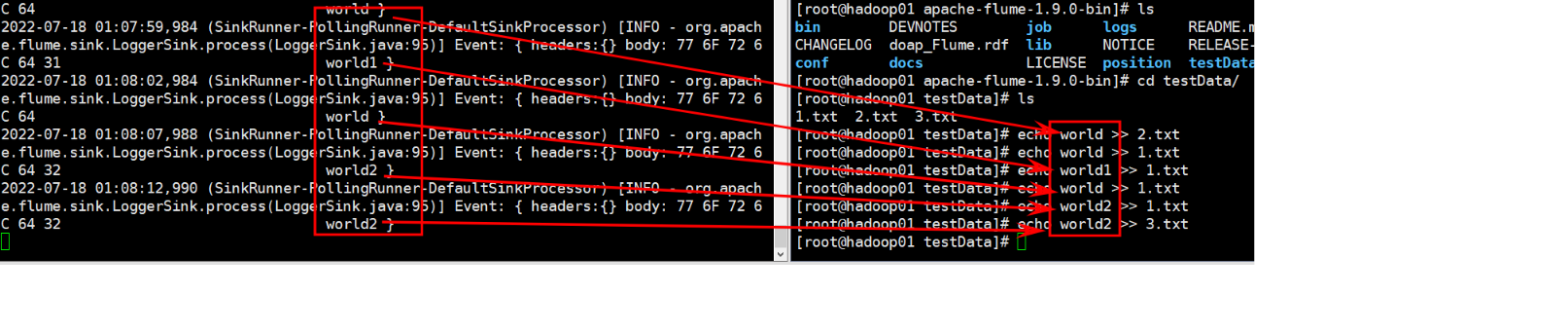
Taildir Source ά����һ�� json ��ʽ�� position File,��ᶨ�ڵ��� position File
�и���ÿ���ļ���ȡ�������µ�λ��,����ܹ�ʵ�ֶϵ�������Position File �ĸ�ʽ����:
{��inode��:2496272,��pos��:12,��file��:��/opt/module/flume/files/file1.txt��}
{��inode��:2496275,��pos��:12,��file��:��/opt/module/flume/files/file2.txt��}
flume����
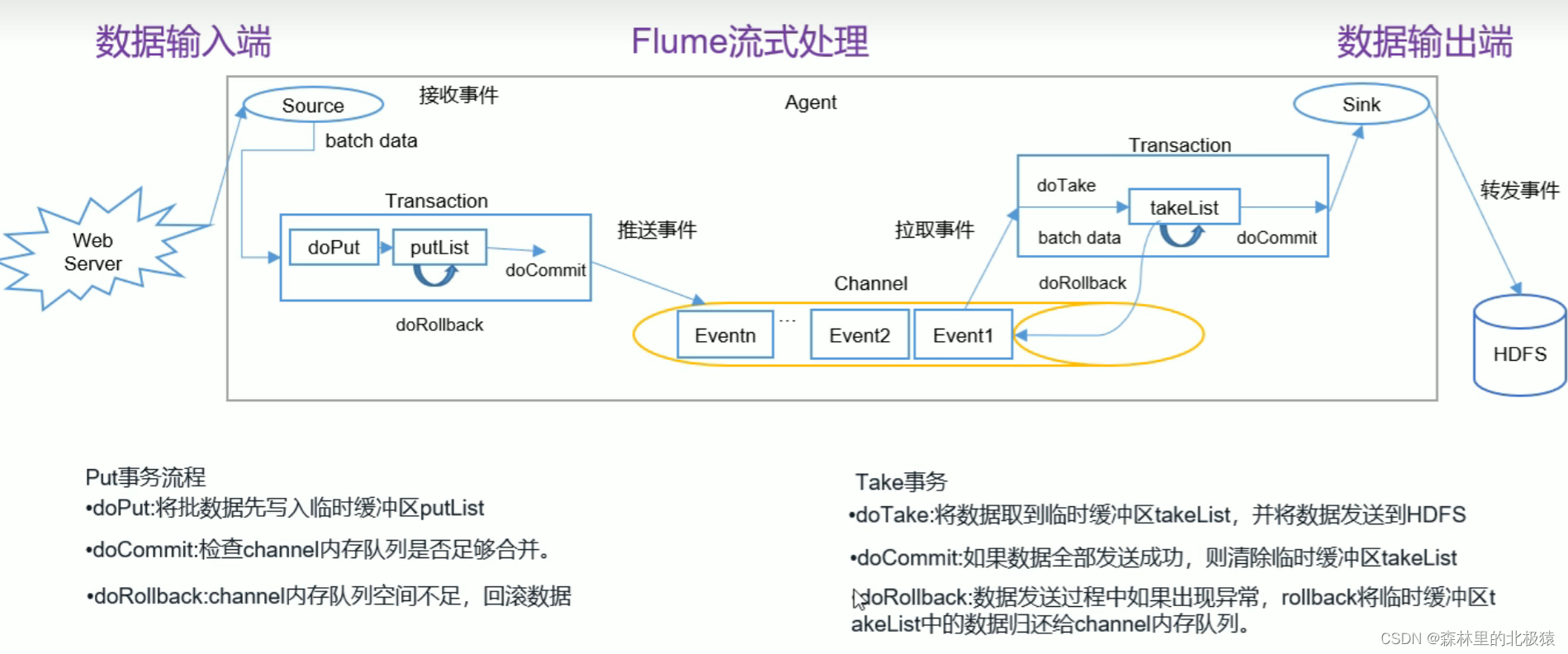
Flume Agent�ڲ�ԭ��
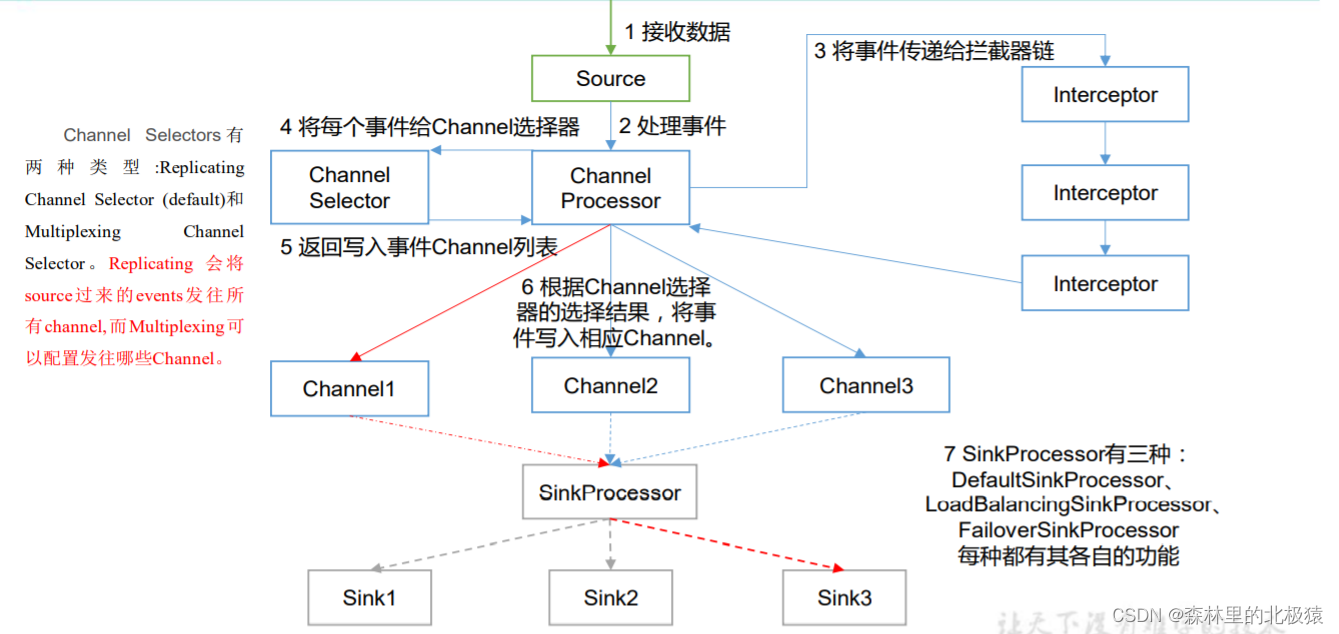
1)ChannelSelector
ChannelSelector �����þ���ѡ�� Event ��Ҫ�������ĸ� Channel���乲����������,
�ֱ��� Replicating(����)�� Multiplexing(��·����)��
ReplicatingSelector �Ὣͬһ�� Event �������е� Channel,Multiplexing �������
Ӧ��ԭ��,����ͬ�� Event ������ͬ�� Channel��
2)SinkProcessor
SinkProcessor �� �� �� �� �� �� , �� �� �� DefaultSinkProcessor ��
LoadBalancingSinkProcessor �� FailoverSinkProcessor
DefaultSinkProcessor �� Ӧ �� �� �� �� �� Sink , LoadBalancingSinkProcessor ��
FailoverSinkProcessor ��Ӧ���� Sink Group,LoadBalancingSinkProcessor ����ʵ�ָ�
�ؾ���Ĺ���,FailoverSinkProcessor ����ʵ�ֹ���ת�ƵĹ��ܡ�
���úͶ�·����
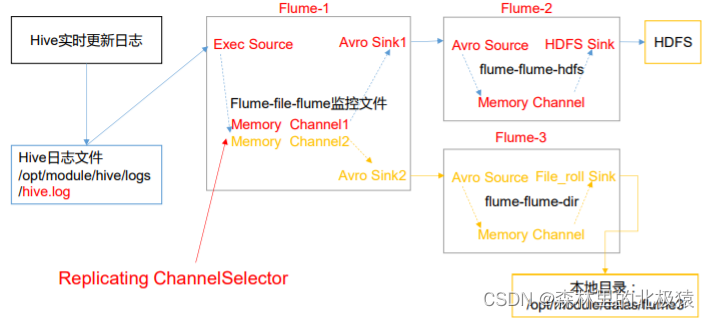
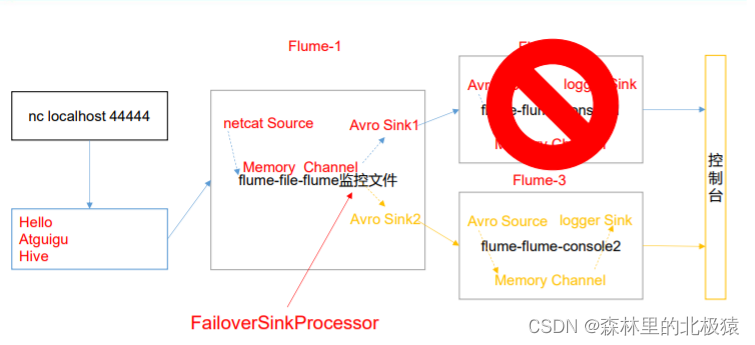
����
-
��flume/job/�´����ļ���group1
��flume/testData�´����ļ���flume3��hive.log
��flume/position�´����ļ�position2.json -
����flume-1,��flume/job/group1�´����ļ�flume-file-flume.conf,��������:
#name
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
#source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /export/servers/apache-flume-1.9.0-bin/testData/hive.log
a1.sources.r1.positionFile = /export/servers/apache-flume-1.9.0-bin/position/position1.json
#sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop01
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop01
a1.sinks.k2.port = 4142
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
#bind
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
- ����flume-2,��flume/job/group1�´����ļ�flume-flume-hdfs.conf,��������:
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
#source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop01
a2.sources.r1.port = 4141
#sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop01:9000/flume2/%Y%m%d/%H
#�ϴ��ļ���ǰ
a2.sinks.k1.hdfs.filePrefix = flume2-
#�Ƿ���ʱ������ļ���
a2.sinks.k1.hdfs.round = true
#����ʱ�䵥λ����һ���µ��ļ���
a2.sinks.k1.hdfs.roundValue = 1
#���¶���ʱ�䵥λ
a2.sinks.k1.hdfs.roundUnit = hour
#�Ƿ�ʹ�ñ���ʱ���
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#���ܶ��ٸ� Event �� flush �� HDFS һ��
a2.sinks.k1.hdfs.batchSize = 100
#�����ļ�����,��֧��ѹ��
a2.sinks.k1.hdfs.fileType = DataStream
#�������һ���µ��ļ�
a2.sinks.k1.hdfs.rollInterval = 30
#����ÿ���ļ��Ĺ�����С����� 128M
a2.sinks.k1.hdfs.rollSize = 134217700
#�ļ��Ĺ����� Event ������
a2.sinks.k1.hdfs.rollCount = 0
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 100
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
- ����flume-2,��flume/job/group1�´����ļ�flume-flume-file.conf,��������:
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop01
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /export/servers/apache-flume-1.9.0-bin/testData/flume3/
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
��ʾ:����ı���Ŀ¼�������Ѿ����ڵ�Ŀ¼,�����Ŀ¼������,�����ᴴ���µ�Ŀ¼��
5. ִ���ļ�
bin/flume-ng agent -n a1 -c conf/ -f job/group1/flume-file-flume.conf
bin/flume-ng agent -n a2 -c conf/ -f job/group1/flume-flume-hdfs.conf
bin/flume-ng agent -n a3 -c conf/ -f job/group1/flume-flume-file.conf
- ����
hdfs�����ļ���
��������Ϊ
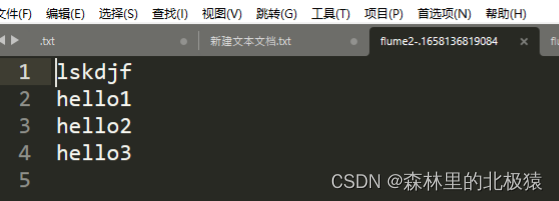
�ڴ�����,�ļ�����

����ת��
�����ļ�
- ��Linux�д������ļ�
- flume1.conf����������
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop01
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop01
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
- flume2.conf����������
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop01
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
- flume3.conf����������
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop01
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
- �ֱ�����
bin/flume-ng agent -n a1 -c conf/ -f job/group2/flume1.conf
bin/flume-ng agent -n a2 -c conf/ -f job/group2/flume2.conf -Dflume.root.loogger=INFO,console
bin/flume-ng agent -n a3 -c conf/ -f job/group2/flume3.conf -Dflume.root.loogger=INFO,console
- ��netcat�з�����Ϣ,flume3���յ�,��������ô������flume3�յ�

7. ��flume3ͣ��(ģ��ҵ��ij���)
ʹ��netcat������Ϣ,���Կ�����flume2����
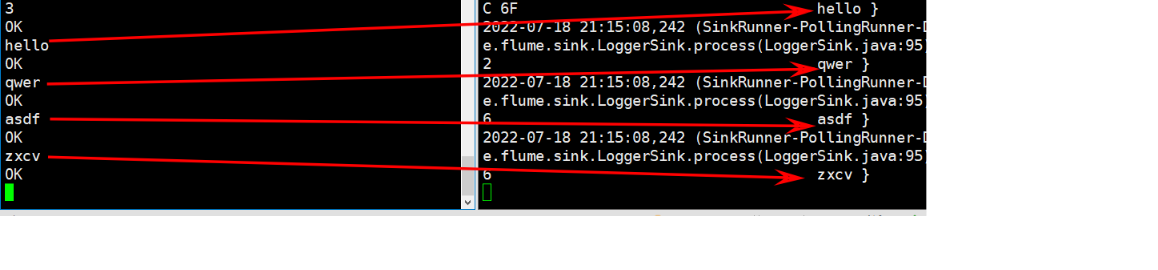
���ؾ���
- ���������������ʵ,����,����ֻ��Ҫ����һ��flume1�ļ���ok
- �����ļ�����
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop01
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop01
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
����,�����flume2��flume3�������
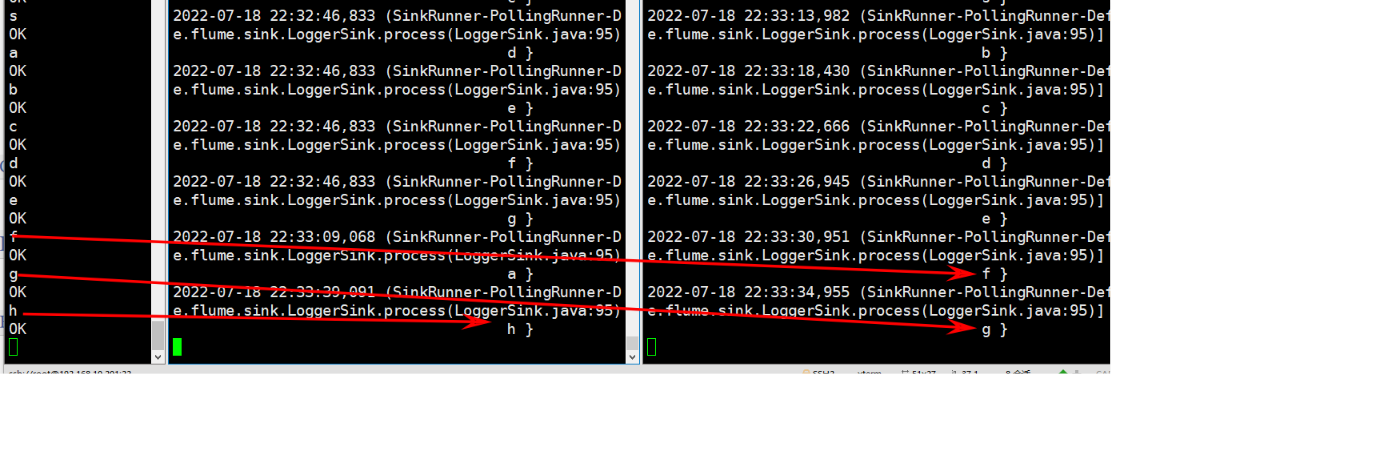
�ۺ�
���й���ĵ�,����˼��һ����