
**�⺣��,**10g / 11g / 12c OCM,Oracle Exadata / Golden Gateר��,����Amazon��Oracle��˾����ȫ��ҵ������DBA,Ŀǰ��ְ���й�ũҵ����,�������ݿ�ǰ�ؼ����о���֧�֡�
����
����MySQL 8.0�ķ���,MySQL�Ĺ��ܺ��������˽ϴ����ǿ,Խ��Խ�����ҵ��ѡ����ʹ�óɱ����Ҳ�������MySQL���ݿ⡣��ô,�����ݴӵ�ǰ���ݿ�Ǩ�Ƶ�MySQLʱ,��Ӧ�ò㡢���ݿ�㶼��Ҫע����Щ����?Ϊ��˳����ɸ��ӵ�Ǩ�ƹ�������Ҫ���Ǻͽ����Щ���������?
������OracleǨ�Ƶ�MySQLΪ��,�ص����Oracle��MySQL�������Ͳ��졢ҵ��ʵ�ֲ��졢Ǩ�Ʒ�ʽ�Լ�Ǩ�ƹ����е�һЩ���յ�,����Ҳο�,����������©֮��,����������ָ����
���칹���ݿ�Ǩ�ƹ�����,���Ǵ����¼����������˼��:
1��Ǩ������
OracleǨ�Ƶ�MySQL��Ҫ�漰���ݽṹǨ�ơ�����Ǩ�ơ�ҵ��Ǩ��������,������Ҫ�������¼����ѵ�:
- �������Ͳ��쵼�����ݽṹǨ�ƹ�������Ҫ���и���ʹ���;
- ����Ǩ���� Oracle LOB�ֶΡ�nullֵ�͡���ֵ�Լ�Ǩ�Ʒ�ʽΪǨ���ѵ㡣
- ҵ��Ǩ��������MySQL��֧�ֲ��С���֧���ﻯ��ͼ,���漰���洢���̸���,ͬ��ʸ���,DBlink��sequence���������Լ�����sql���ĸ��졣
2��Ǩ������
������Ҫ����һ��������Ǩ������:1��ȷ��Ǩ�Ʒ�Χ;2��Ǩ������;3��ѡ��Ǩ�Ʒ�ʽ;4��Ǩ����֤,�Դ���ȷ��Ǩ�ƹ����Ľ�չ��˳����ɡ�
1)ȷ��Ǩ�Ʒ�Χ
��OracleǨ�Ƶ�MySQL��һ����Һ�ʱ������,��Ҫ����Ҫ�˽�ҪǨ�Ƶķ�Χ,��Ҫ�˷�ʱ����Ǩ�Ʋ�����Ҫ�Ķ�������,����Ƿ���ҪǨ�����е���ʷ����,��Ҫ�˷�ʱ�������Ʋ���Ҫ������,�����ȥά���еı������ݺ���ʱ����
2)Ǩ������
������������,Ǩ�Ƶĵ�һ���Ƿ���Ӧ�ó�������ݿ����,�ҳ��������ݿ�֮�䲻���ݵ�����,������Ǩ�������ʱ��ͳɱ�����������Oracle��MySQL֮�����ݽṹ���ڲ���,��MySQL��֧�ֲ��С���֧���ﻯ��ͼ��8.0���ϲ�֧�ֺ�������,�����漰���洢���̸���,ͬ��ʸ���,DBlink��sequence���������Լ�����sql���ĸ���ȹ�����
3)Ǩ�Ʒ�ʽ
ͨ����Ǩ������ʱ��ͳɱ�ѡ��ͬ��Ǩ�Ʒ������߹��߽���Ǩ��,���Է�Ϊʵʱ����(��������GoldenGateʵʱͬ������ʹҵ��Ӱ��ʱ����С),����һ���Լ���(������� Oracle�����ݱ�������csv�ļ���,ͨ��load����mysqlsh���ߵ��뵽MySQL��)��
4)��֤����
��������Ӧ�ó����Ǩ�Ƶ����ݿ�dz���Ҫ,��Ϊ�������ݿ��е�ijЩ������ͬ,����ʵ�ַ�ʽ�ͻ���ȴ�Dz�ͬ�ġ�������Ҫ����ֵ���֤����:
- ����Ƿ���ȷת�������ж���;
- �������DML�Ƿ���������;
- ���������ݿ��м����������ݲ������,���������������ݿ��SQL���Ӧ����ͬ;
- ���DML����ѯSQL������,���ڱ�Ҫʱ����SQL���졣
����,�����ȴ����Ԫ���ݡ��������������͡������ȷ����˽�һ��Oracle��MySQL�IJ��������
һ��MySQL��Oracle����
1.1 MySQL��Oracle�������

1.2 MySQL��Oracle�����û�����

1.3 MySQL��Oracle�Ա������Ʋ���
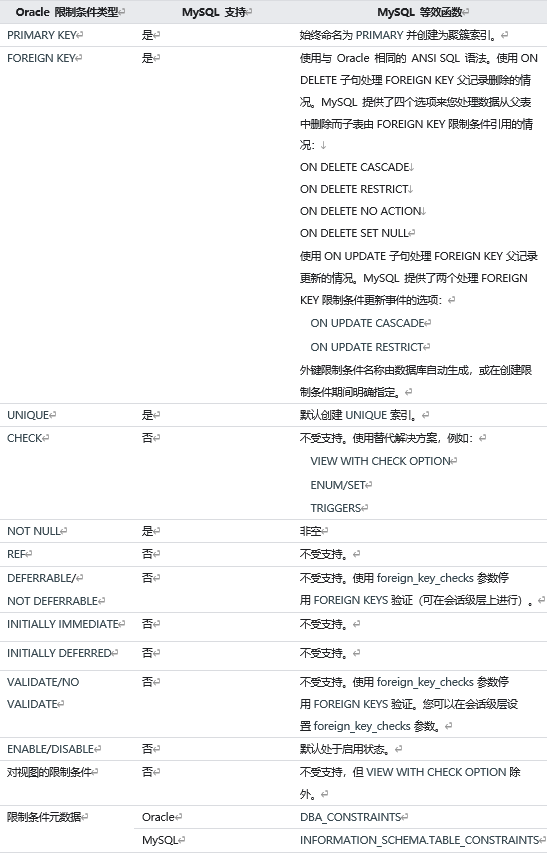
1.4 MySQL��Oracle�����кͼ����в���
Oracle��MySQL��������(��MySQL��Ҳ��Ϊ���ɵ���)���������еļ�������������ʾΪ������,�����ǵ�ֵ�Ǽ�������,������ǵ�ֵ����洢�����ݿ��С������п������������������������������һ��ʹ��,����ͨ�� DML �������ݡ�
��Oracle���������෴MySQL���ɵ��б���ָ�������е��������͡�����ָ��GENERATED ALWAYSֵ,������ʾ������ʾ:
Oracle������:
SQL> CREATE TABLE PRODUCTS (
PRODUCT_ID INT PRIMARY KEY,
PRODUCT_TYPE VARCHAR2(100) NOT NULL,
PRODUCT_PRICE NUMBER(6,2) NOT NULL,
PRICE_WITH_TAX AS (ROUND(PRODUCT_PRICE * 1.01, 2))
);
SQL> INSERT INTO PRODUCTS(PRODUCT_ID, PRODUCT_TYPE, PRODUCT_PRICE)
VALUES(1, 'A', 99.99);
SQL> SELECT * FROM PRODUCTS;
PRODUCT_ID PRODUCT_TYPE PRODUCT_PRICE PRICE_WITH_TAX
---------- -------------------- ------------- --------------
1 A 99.99 100.99
MySQL������:
MySQL> CREATE TABLE PRODUCTS (
PRODUCT_ID INT PRIMARY KEY,
PRODUCT_TYPE VARCHAR(100) NOT NULL,
PRODUCT_PRICE NUMERIC(6,2) NOT NULL,
PRICE_WITH_TAX NUMERIC(6,2) GENERATED ALWAYS AS
(ROUND(PRODUCT_PRICE * 1.01, 2))
);
MySQL> INSERT INTO PRODUCTS(PRODUCT_ID, PRODUCT_TYPE, PRODUCT_PRICE)
VALUES(1, 'A', 99.99);
MySQL> SELECT * FROM PRODUCTS;
+------------+--------------+---------------+----------------+
| PRODUCT_ID | PRODUCT_TYPE | PRODUCT_PRICE | PRICE_WITH_TAX |
+------------+--------------+---------------+----------------+
| 1 | A | 99.99 | 100.99 |
+------------+--------------+---------------+----------------+
1.5 MySQL��Oracle�������Ͳ���
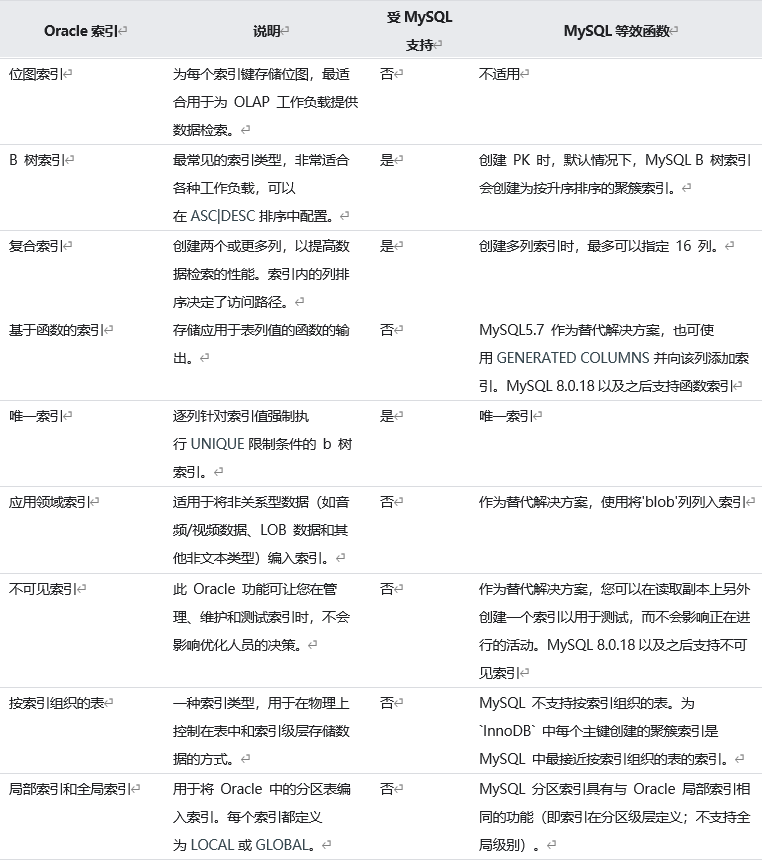
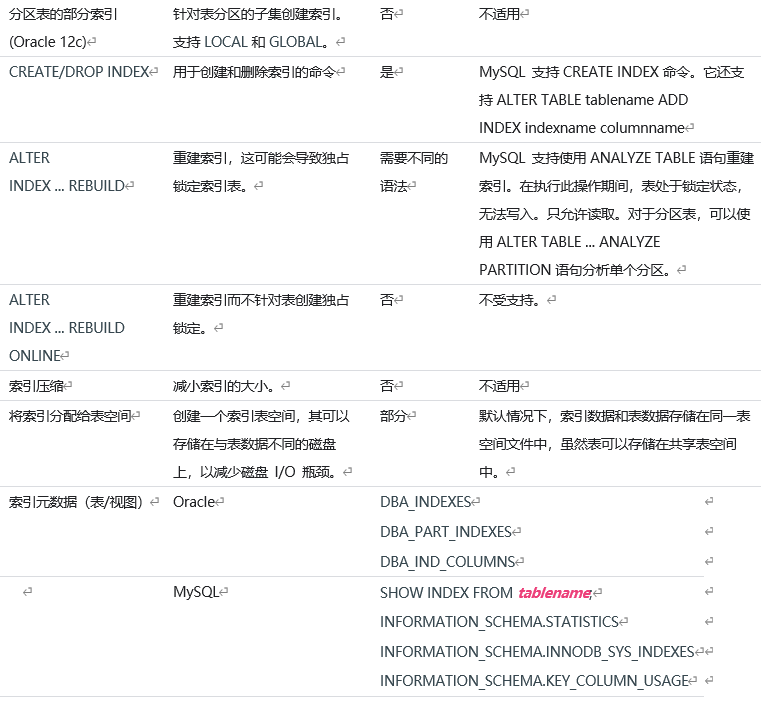
1.6 MySQL��Oracle��������

1.7 MySQL��Oracle��ʱ������
�� Oracle ��,��ʱ����ȫ����ʱ����session�������ʱ��֮�֡���MySQL ��,���Ǽ��Ϊ��ʱ������������ƽ̨��,��ʱ���Ļ�����������ͬ�ġ�����,����֮�����һЩ��������:
��ʹ�����ݿ�����֮��,Oracle Ҳ��洢��ʱ���ṹ���ظ�ʹ��,��MySQL ���ڻỰ�ڼ�洢��ʱ����
������ӦȨ�������û����Է��� Oracle �е���ʱ�������֮��,MySQL �е���ʱ��ֻ���ڴ�����ʱ���� SQL �Ự�ڼ���ʡ�
����ڴ�����ʱ��ʱʡ���� ON COMMIT �Ӿ�,�� Oracle �е�Ĭ����Ϊ�� ON COMMIT DELETE ROWS,����ζ�� Oracle ����ÿ���ύ��ض���ʱ�������֮��,��MySQL ��,Ĭ����Ϊ����ÿ���ύ������ʱ���е��С�

1.8 MySQL��Oracleδʹ���в���
MySQL ��֧�ֽ��ض��б��Ϊ UNUSED �� Oracle ���ܡ���MySQL ��,����ӱ���ɾ�������в�����ִ�д˲���ʱ�ij��ȴ�ʱ��,�����ԭʼ��ʹ���ĺ�ļܹ������±�,Ȼ������������������
��ע��,�˹�����Ҫͣ��ʱ�䡣
1.9 MySQL��Oracle�ַ�������
Oracle �� MySQL ���ṩ�˶����ַ������������� Unicode ����,����֧�ֵ��ֽںͶ��ֽ����ԡ�����,ÿ��MySQL ���ݿⶼ����ʹ���Լ����ַ����������á�MySQL �е���������������ַ������ƿ�ͷ,���һ��������ʾ����������������Ľ�β�������ַ��������ٰ���һ���������(Ĭ���������),�����ַ��������ж��֧�ֵ����������ע��,������ͬ���ַ������ܾ�����ͬ���������
�� Oracle �� MySQL ��,�ַ����������ݿ⼶��ָ���ġ��� Oracle ���,MySQL ��֧���Ա�������м�������ָ���ַ�����
1.10 MySQL��Oracle��ͼ����
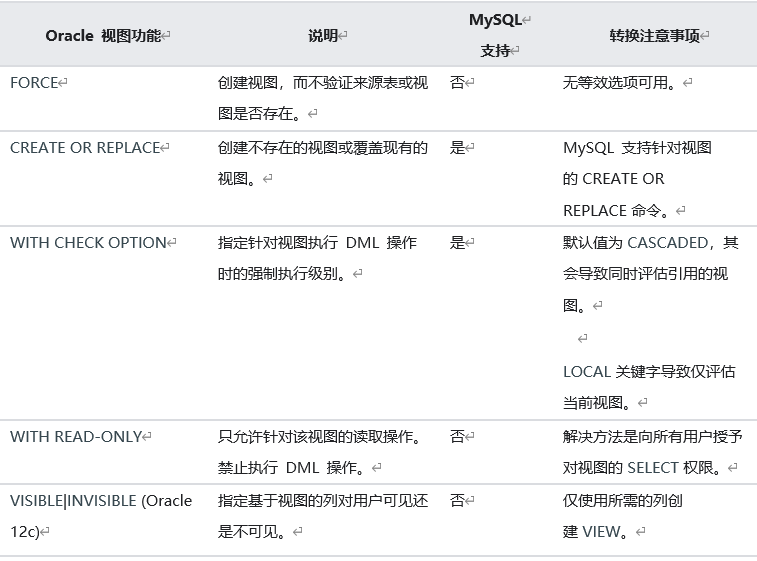
MySQL��֧�ּ���ͼ,��֧�ָ�����ͼ���ڶ���ͼִ�� DML ����ʱ,������ΪҲ�� Oracle ��ͬ��������ͼ����ѡ��,Oracle ��MySQL ֮�����һЩ���졣�±�����˵������Щ���졣
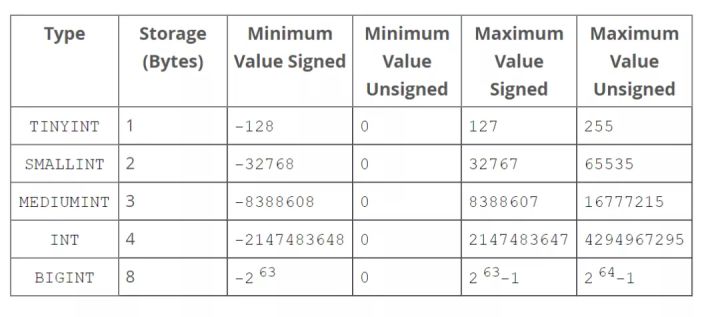
1.11 MySQL��Oracle�������Ͳ���
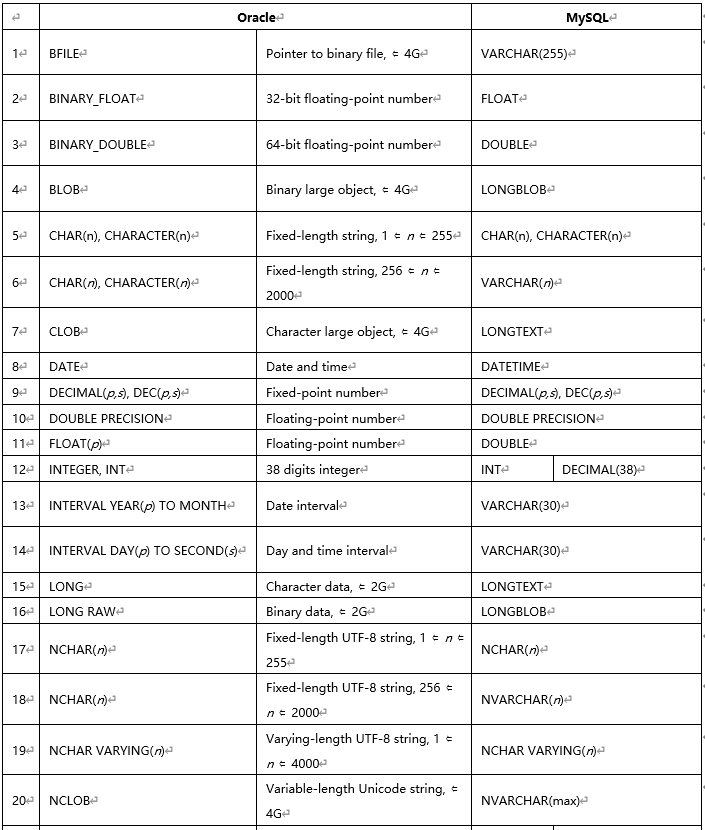
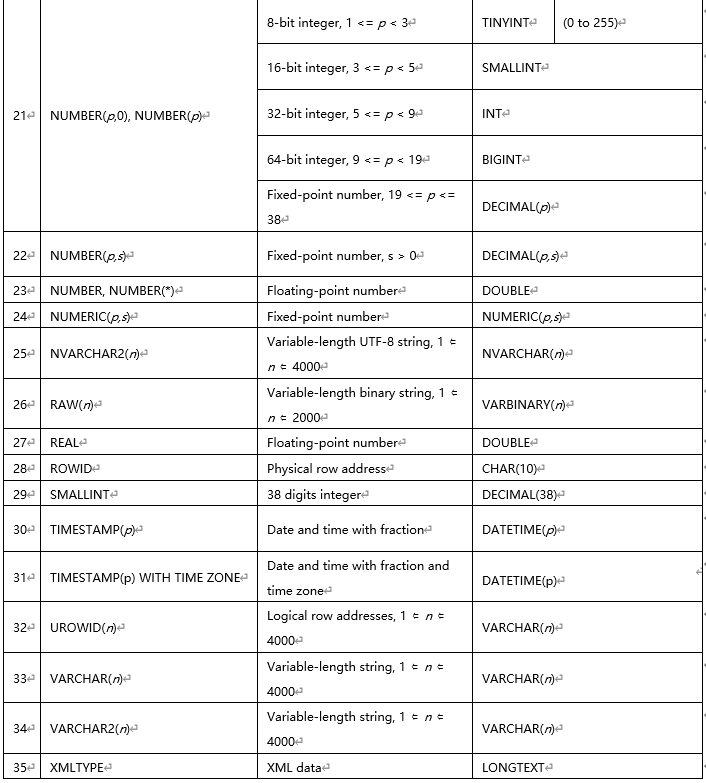
(�ɲο��ٷ��ĵ�https://dev.MySQL.com/doc/refman/8.0/en/integer-types.html)
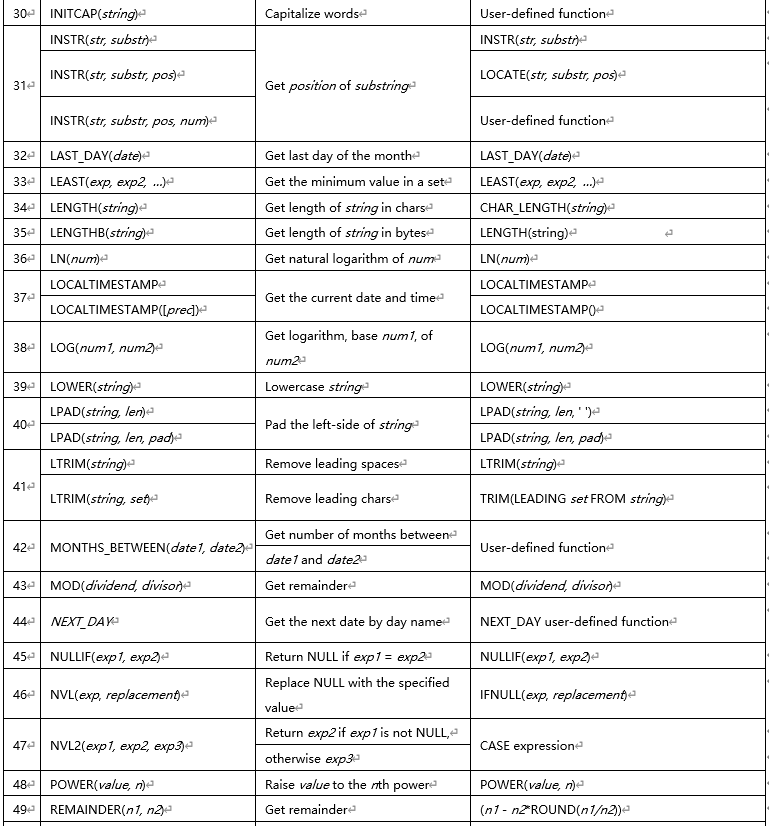
1.12 MySQL��Oracle���ú�������

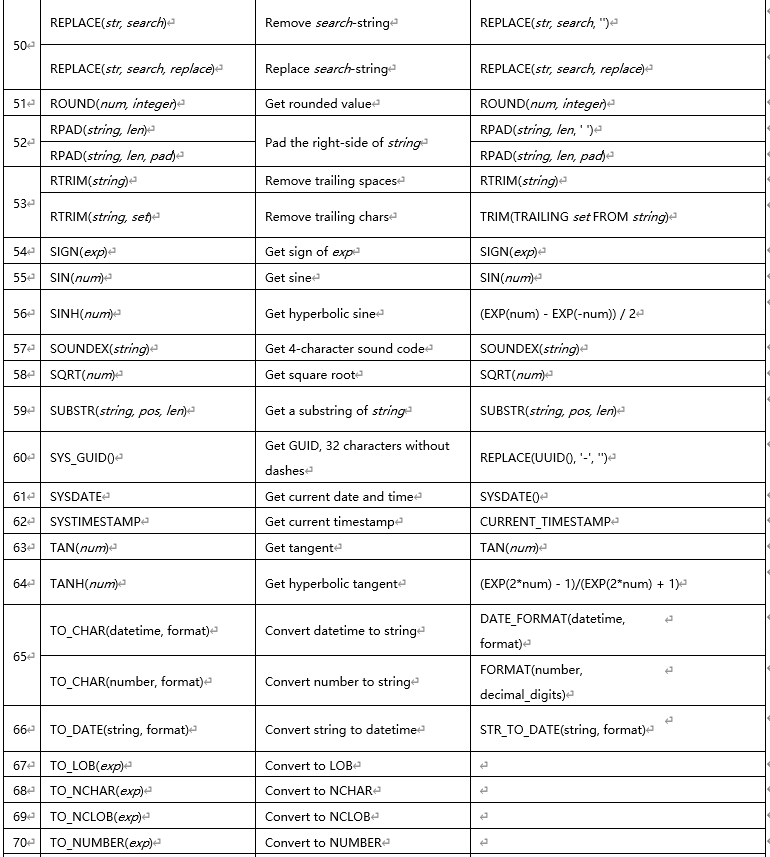

1.13 MySQL��Oracle�������������еIJ���

Oracle��MySQL�����������ݿ⼶��IJ�����,���������ݿ���Ӧ�ó���ʵ�ֶ�Ҳ�нϴ�IJ���,����洢���̡������ʹ������ȹ��ܵ�ʹ�á��� Oracle ��,�洢���̡������ʹ��������û����С���MySQL ��,���ǹ����ݿ����С���MySQL ��,�����洢��������ݿ��û����Զ���� CREATE DEFINER Ȩ��,�����Գ䵱�������ݿ��û�����Ȩ�ߡ�
1.14 MySQL��Oracle���������
PL/SQL����������������������,����ζ���û����Խ�����PL/SQL��������Ӳ����д����,�����贴���洢����MySQL û�е�Ч�Ĺ��졣��MySQL��,�����ڴ洢���̻����д�������顣

1.15 MySQL��Oracle�洢���̲���
���ڴ����洢���̺ͺ����� Oracle PL/SQL���������ѡ��OR REPLACE�Ӿ�,��dz��ʺ����ڸ��Ĺ��̡�MySQL��֧�ִ˹��졣�������MySQL�еĹ���,����ʹ��DROP PROCEDURE��ʹ��CREATE PROCEDURE��䡣
����MySQL�洢���̻���ʱ,���Ĵ������ָ����Ĭ�Ϸָ�����;��(�ֺ�)�������ָ�������ΪMySQL�Ὣ�� ��;�� ��β��ÿһ����Ϊһ������,�������ǽ�����ʹ�ò�ͬ�ķָ���(�� )���������д洢���̡� E N D )���������д洢���̡�END )���������д洢���̡�END �ؼ��ֽ���ʹ�ô˷ָ�����
��һ����������,MySQL�洢���̵ı�������������BEGIN�ؼ��ֺ�����С���Oracle��,�˲�����BEGIN�ؼ���ǰ����С�

1.16 MySQL��Oracle����������
Oracle�ṩ�������͵Ĵ�����:DML��������instead of��������system event������������MySQLԭ����֧��DML��������������ʹ��FOLLOWS��PRECEDES�Ӿ����ĺ�����MySQL��������

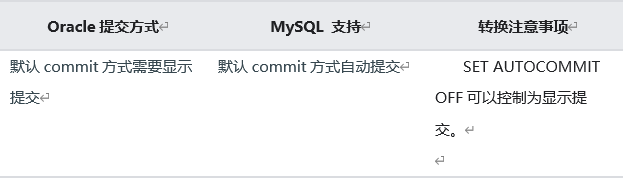
1.17 MySQL��OracleĬ���ύ��ʽ
1.18 MySQL��Oracle������뷽ʽ
����ĸ��뼶����Է�Ϊ�ĸ�����
- Serializable (���л�):�ɱ�������������ظ������ö��ķ���;
- Repeatable read (���ظ���):�ɱ�������������ظ����ķ���;
- Read committed (�����ύ):�ɱ�������ķ���;
- Read uncommitted (��δ�ύ):��ͼ���,�κ����������֤��
��MySQL���ݿ���,֧�����ָ��뼶��,Ĭ�ϵ�ΪRepeatable read (���ظ���) ;���� Oracle���ݿ� ��,ֻ֧��Serializable (���л�) ����� Read committed (�����ύ) �����ּ���,����Ĭ�ϵ�Ϊ Read committed(�����ύ) ����,MySQL �������õ�ǰϵͳ�ĸ��뼶��,���뼶���ɵ͵�����������Ϊ
- set global transaction isolation level read uncommitted;
- set global transaction isolation level read committed;
- set global transaction isolation level repeatable read;
- set global transaction isolation level serializable;
MySQL ��ʹ�����������ϵͳ,�Ự�ĸ��뼶��
select @@global.transaction_isolation, @@session.transaction_isolation, @@transaction_isolation;
MySQLΪ��ʵ�ֿ��ظ����ĸ��뼶��,InnoDB����ʹ�ó�Ϊ��next-key locking�����㷨,���㷨���������������϶���������һ��,����뼶���й�,ֻ��REPEATABLE READ�����ϵĸ��뼶���µ��ض������Ż���gap lock��nextkey lock��
1.19 MySQL��֧�ֵĹ�����
- MySQLû�в��еĸ���,��֧�ֲ���;
- MySQL�Ż�������,����SQL�����ּ�SQL;
- MySQL�����Ӳ�ѯ�Ż����Ǻܺ�;
- MySQL��֧���ﻯ��ͼ���洢���̸��졢ͬ��ʸ��졢dblink��Ҫ���졣
����MySQL��Oracle������Ǩ�Ʒ�ʽ
һ�����ǿ���ͨ���������ֻ�������Ǩ������:һ���Լ��غ�ʵʱ���ơ�һ���Լ��ط�����ָ�� Oracle �ֵ����������ݲ����䵼�뵽 MySQL �С�ʵʱ���Ʒ�����ָ��������֮�������� Oracle ���Ƶ� MySQL��
2.1 һ���Լ��ط���
����һ���Լ��ط���,Դ���ݿ������ڸù����ڼ����д�롣���,�˷���Ҳ��Ϊ��������Ǩ�ơ�Oracle SQL DEVELOPER���û��� Oracle �������ݵ���ù���֮һ���˹���֧�ִӲ��ø��ָ�ʽ(���� CSV �� SQL �������)�� Oracle ���е������ݡ�����,������ʹ�� SQL*Plus ѡ�����ݲ��������ʽ,Ȼ������ѻ����ļ��С������ݴ� Oracle ������ƽ���ļ���,������ʹ�� LOAD DATA INFILE ������ݼ��ص� MySQL �С��÷���ͨ����һ������˵�Ǩ�Ʒ���,����������Ҫ������ֶ�����,���ұ�ʹ��Ǩ�ƹ���Ҫ����������Ҫ��Ǩ�ƹ����н�Ӧ��ͣ����
2.2 ʵʱ���Ʒ���
ʵʱ���Ʒ���(Ҳ��Ϊ�������ݲ���)��һ����������Ǩ�Ʒ������ڳ�ʼ���ݸ����ڼ�,Դ���ݿⱣ�ִ�״̬�����Ʋ�Ʒ�Ჶ��Դ���ݿ��Ϸ��������ݸ���,������Щ���Ĵ��䲢Ӧ�õ�Ŀ�����ݿ⡣�����Ǩ����������,������ʹ�ô˷���������ȵؼ��������ͣ��ʱ��,��ȷ���ڽ����л�֮ǰͣ��ʱ��ӽ��㡣�˷����漰ʹ�ø������ݲ��� (CDC) ��Ʒ,���� GoldenGate��Striim �� Informatica �����ݸ��ơ�
2.3 ��ѭԭ��
Ǩ������ʱ,����ѭ������,���д���ͬʱ������һ���Լ��ط�����ʵʱ���Ʒ���:
- �ַ���:ȷ��Դ Oracle ���ݿ���Ŀ�� MySQL ���ݿ�֮����ַ�������;
- ���:Ҫ������ȡ�ٶ�,����ʱͣ��Ŀ�� MySQL ���ݿ��ϵ��������������������ɺ������������������;
- ����:���������,Ŀ�� MySQL ���ݿ��ϵ��������ܻ��������ͳ�ʼ���ص��ٶȡ�ȷ���ڳ�ʼ�������֮ǰ,��Ŀ�����ݿ���δ��������;
- Oracle ����:MySQL ֧�� AUTO_INCREMENT ���������С�ȷ���ڳ�ʼ�����ڼ�ͣ�� AUTO_INCREMENT ����,�Ա��⸲�� Oracle ���������ɵ�ֵ���ڳ�ʼ������ɺ�,�� AUTO_INCREMENT �������ӵ�������;
- ��������:�����ʹ�õ���GoldenGate TDM,��ȷ����Դ������Ŀ�껷����������GoldenGate TDM��Ʒ������������,�������� Oracle �˲������ݲ���MySQL �˼������ݡ�
��Ǩ�ƹ�����,�ַ������ռ���㡢NULLֵ�Ĵ�����LOBǨ�Ƶ�,����Ǩ�ƹ����е��ѵ�,������Ҫ����Щ�ѵ���з����������Ӧ�Ĵ����취,������Ǩ�ƹ����вȿӡ�
�����ѵ�����ʹ���
3.1 �ַ���
�����ַ���,��Ҫ���ǵ�����ΪǨ�ƹ����ֶγ���ƥ�����,Ǩ�ƺ������Ƿ�����,�Լ�Ǩ�ƺ��ַ���ת����ռ�����⡣
3.1.1 Oracle
Oracle�������ݿ�ʱָ���ַ���,һ�㲻����,�������ݿⶼ��һ���ַ�������֧��ָ�������ַ���,����nvarchar2����,���õ��ַ���:AL32UTF8��ZHS16GBK,����AL32UTF8��UTF8�����ǵȼ۵ġ�һ��������AL32UTF8��ռ�����ֽ�,����ZHS16GBK��ռ�������ֽڡ�
3.1.2 MySQL
MySQL���ַ����Ƚ����,����ָ�����ݿ⡢�����е��ַ���,���Һ����������ݿ���ַ���,�������ַ���ʱ���е����ݲ�����¡�
(1)֧�ֵ��ַ���:��ѯ֧�ֵ��ַ���:show character set;����,default collation��ʾĬ���������,��_ci������������ʾ�ַ���Сд�����С�(2)�鿴���ݿ��Ĭ���ַ���:show variables like ��character_set_server��;��ѯ��ǰ���ݿ���ַ���:show variables like ��character_set_database��;
3.1.3 ����Ǩ�Ʊ�������
�ͻ����ַ�������Ҫ,��������ʱ,�����ı��������Ļ�����,�ͻ��˻�������ַ���������������ı�,���ʵ��������ַ�����ͻ����ַ�����һ��,��ô�Ϳ��ܵ���¼�����ݿ�����ݳ�������;�������ʱ,����ͻ����ַ������õIJ�����,�ͻᵼ��չʾ�������������롣
Oracle ͨ����������NLS_LANG���ÿͻ����ַ�����
- Linux�»Ự�����÷���:export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
- Windows�»Ự�����÷���:set NLS_LANG=AMERICAN_AMERICA.AL32UTF8
�ر�Ҫע��һ��,��SQLPLUSִ�нű�ʱ,NLS_LANG��Ҫ���ű��ļ����ַ�������һ�¡������UTF8,�ű���Ҫ����ΪUTF8��BOM��ʽ��
��ѯoracle server�˵��ַ���: select userenv(��language��) from dual;
��ѯoracle client�˵��ַ���:
��windowsƽ̨��,����ע���������ӦOracleHome��NLS_LANG��������dos���������Լ�����,����: set nls_lang=AMERICAN_AMERICA.ZHS16GBK������ֻӰ�������������Ļ�����������unixƽ̨��,�鿴��������NLS_LANG:echo $NLS_LANG
MySQL����ͨ�������ַ���������ȷ���ַ�������:
- character_set_client:�ͻ�����Դ����ʹ�õ��ַ���;
- character_set_connection:���Ӳ��ַ���;
- character_set_results:��ѯ����ַ�����
������Ľ������server����client���ַ�����һ��,��ͳһ��Ϊͬserver����ͬ���ַ�����
3.2 Ǩ�ƹ������ֶγ���ƥ��Ϳռ����
MySQL��char(n)��varchar(n)���������ַ�������,��Oracle��char(n)��varchar(n)���������ֽڳ���,����Ǩ�ƹ����п����ʵ������ֶγ��ȼ��ٴ���ռ䡣
3.3 �մ���Nullֵ�Ĵ���
Oracle��MySQL������null������:
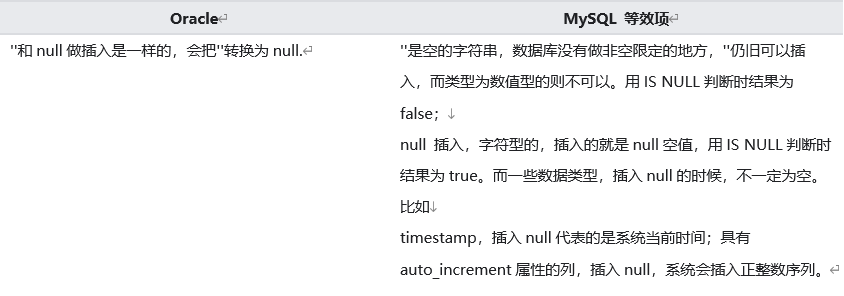
��Oracle�е������ļ����ǵ���nullֵ�ᱻ�ɡ���,�������뵽MySQL��null�͡����ͻ����,�Ҳ��뵽MySQL�ġ�������ݲ�ͬ���ֶ�����ת���ɲ�ͬ�ķ�ʽ��
ʹ���ļ����뵽MySQLʱ�ֶ��еĿ�ֵnull��Ҫʹ��N��ʾ,����ÿ��ַ�����ʾ,��ô���ݲ�ͬ����������,MySQL����Ҳ���졣
���ݿ��ֶ�������ַ�������,�����ʱ,load data Ĭ�ϵ��� ���ַ������ݿ��ֶ��������������,�����ʱ,load data Ĭ�ϵ��� 0.00000000���ݿ��ֶ���������ں�ʱ������,�����ʱ,load data Ĭ�ϵ��� 0000-00-00 00:00:00
Oracle�������ı��ļ�,null���Ϊ���ַ���,���뵽MySQL��ᱻ��Ϊ�ǿ��ַ�������,�ƻ�������һ����,�����ṩ�����ַ�ʽ���й��:
1��������OracleǨ��֮ǰ������ҵ�����nullֵ���Ϊ�������ֵ,�ȵ�Ǩ�Ƶ�MySQL��ͳһ��������������,����:
UPDATE SUPPLIERS_TBL SET SUPPLIER_ID=NVL(null,��N/A��) where SUPPLIER_ID isnull;
2��ʹ��spool������ʱ���nullֵ����ת��,��Ҫ��Ա����н�����
Select
NVL(TO_CHAR(id),'N/A')||','||NVL(name,'N/A')||','||NVL(SEX,'N/A')||','||NVL(ADDRESS,'N/A')||','||NVL(TO_CHAR(BIRTHDAY),'N/A') from user1;
3��ʹ��python�ű����г�ȡ����,�����˵������ı��ļ�������,��Ҫ���жԽű����п���,��������Ч����Ҫ���в��ԡ�
3.4 �������ʹ���
Oracleȱʡ��ʱ�����ݵ���ʾ��ʽ,����ʹ�õ��ַ����йء�һ����ʾ������,������ʾʱ���롣����,ʹ��us7ascii�ַ���(������������Ӣ���ַ���)ʱ,ȱʡ��ʱ���ʽ��ʾΪ:28-Jan-2003,ʹ��zhs16gbk�ַ���(�����������ַ���)��ʱ���ʽȱʡ��ʾΪ:2003-1��-28��
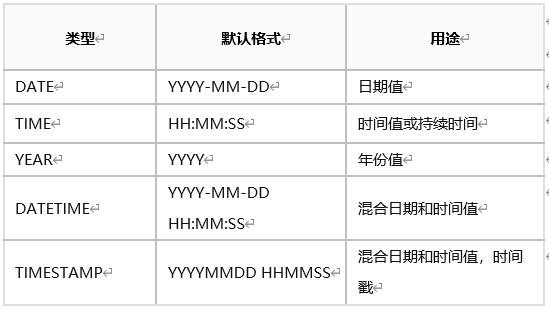
MySQL���ݿ�Ĭ��ʱ���ֶθ�ʽ
�����ڵ������ı��ļ�ʱ��Ҫע��,����Oracle��Ĭ��ʱ���ʽ,����������ļ���ֱ������
export NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'
��Ҫע��ĵ�:
�ֶ����������datetime,Ӧ���ϸ�ѿ���Ӧ�ı����ݵĸ�ʽ,���������������yyyy-MM-dd HH:mm:ssͬʱ�����ڡ�ʱ��ĸ�ʽ,�������Ա�֤���ݵ������ȷ�ԡ�
���ݿ��ֶ������datetime,����yyyy-MM-ddʱ,load data Ĭ�ϵ��� yyyy-MM-dd 00:00:00,������ȷ���ܹ���֤���ݿ��ֶ������datetime,����HH:mm:ssʱ,load data Ĭ�ϵ��� 0000-00-00 00:00:00,������ȷ�Բ��ܹ���֤
�ֶ����������timestamp��explicit_defaults_for_timestamp=on,�����и���ʱ,timestamp�����ֶβ�����Ϊ��ǰʱ�䡣
3.5 LOB�ֶ�Ǩ��
Lob�ֶο��Է�Ϊclob��blob����clob�ֶεı����Բ���UTL_FILE������csv��,�ٵ���MySQL�С�
�ο�:How to Export The Table with a CLOB Column Into a CSV File using UTL_FILE (Doc ID 1967617.1)
3.6 ��Сд���в���
Oracle���Ĭ��ͳһ���մ�д������,MySQL����Ĭ���Ǵ�Сд���еġ�
���ǽ�Ϊ�˽���DZ��ṹ��Сд���в���lower_case_table_names,���������������ִ�Сд���в���(collate)����ʹ�ÿ��ܽ���,����OracleĬ�����������ݴ�Сд��,Ϊ�ﵽǨ��ǰ��һ����,����������Ҫ�������������ʽ�ġ�
3.7 �ⲿ��������ʽ
MySQL���ṩCSV����,����ʵ��Oracle���ⲿ���Ĺ���,����CSV��ʱ,������������һ�����ı������ļ�,���ļ��������Ա�����ͷ������.CSV��չ���������ݴ洢������ʱ,�洢����Ὣ���Զ��ŷָ���ֵ��ʽ���浽�����ļ��С����Խ��ⲿ�ļ��滻.CSV��flush tableʵ��Oracle�ⲿ�����ܡ�
CSV��������:
- CSV�洢���治֧������;
- CSV�洢���治֧�ַ�����
ʹ��CSV�洢���洴�������б��������������Ͼ���NOT NULL���ԡ�
3.8 MySQL sql_mode
MySQL�������ܹ������ڲ�ͬ��SQLģʽ��,��Բ�ͬ�Ŀͻ���,�Բ�ͬ�ķ�ʽӦ����Щģʽ������Ӧ�ó�����ܶԷ���������������������,�������Լ�����������ģʽ������MySQLӦ֧�ֵ�SQL�,�Լ�Ӧ����������ִ�к���ȷ�ϼ�顣MySQL 8.0Ĭ��Ϊ�ϸ�ģʽ��sql_mode
sql_mode=ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONONLY_FULL_GROUP_BY:sql��select������ֶα��������group by����,���߱��ۺϺ���������STRICT_TRANS_TABLES:������ܰ��ո���ֵ�����������,����ֹ����䡣���ڷ������,�����ֵ�����ڵ�������������ĵ�һ����,����ֹ����䡣NO_ZERO_IN_DATE:Ӱ��������Ƿ�������ݲ��ַ��㵫�·ݻ����ڲ���Ϊ0�����ڡ�NO_ZERO_DATE:Ӱ��������Ƿ��������� '0000-00-00����Ϊ��Ч���ڡ���Ч����ȡ�����Ƿ��������ϸ��SQLģʽ��ERROR_FOR_DIVISION_BY_ZERO:Ӱ�������Ĵ���no_engine_subtitution:create table ��engine�Ӿ�ָ���Ĵ洢���治��֧��ʱ,mysql��ѱ��������Ϊinnodb��
����:�ڵ�������ж��ڲ�ƥ��ĸ�ʽ,�����ȹر��ϸ�ģʽ���е���set global sql_mode=����,����֮���ٴ��ϸ�ģʽ��
�ġ�Ǩ�����ܵĿ���
���������Ƚϴ�ʱ,������Ҫ���ؿ���Ǩ�Ƶ����ܺ��ٶ�,�Ӷ��������ݿ�Ǩ��ʱ��ʱ�䴰�ڡ�
4.1 ���ݵ�����
���ݿ��Դ�һ���Լ��ط�ʽ��ж�����ݷ�ʽ:
- ʹ��sql developer���е���,Ӧ�ó���ֻ��windows��,����������ı�����hang;
- Utl_file ж�ط�ʽ �����ı�������������ʱ�Ͽ�;
- Sqlplus spoolж�ط�ʽ �����ı�������������ʱ�Ͽ� �������Ӳ�����ߵ����ٶȡ�
һ���Լ��صķ�ʽ��Ҫ���в��Բ���ȷ��ͣ��ʱ��
�������͵���ʱ��Ա�:

����,ʹ��Orato8a���߽�Oracle���ݿ�ı�������CSV�ļ�,Ȼ��ʹ��load������ݵ���MySQL���ݿ�,�ù�����ҪԤ�Ȱ�װ��Oracle�ͻ���,�����ú����Ӵ���
Orato8a��һ�����Կ��١���Ч�ش�Oracle���ݿ�ϵͳ�г�ȡ����,�������ݱ��浽ָ���ļ��е�ר�ù��ߡ�����Orato8a���ṩ��ѯ��䵼����ȫ���������ַ�ʽ,����ȫ�������ĵ�¼�û���Ҫ��dba_extents��dba_objects��dba_tables�����ű���selectȨ��,ʹ�ò�������:
Ǩ��������Oracle���ݿ��������,���������ַ���:1��ͨ��tnsnames.ora�����Ӵ���������1)��tnsnames.ora�������ļ�vi KaTeX parse error: Undefined control sequence: \[ at position 310: ���ú�,ִ�������������������:\?[?oracle@NODE167 �� sqlplus username/password@testdb_p 2��ͨ��IP,�˿ںźͷ�����ֱ�Ӳ���������[oracle@NODE167 output]$ sqlplus username/password@server_IP_address:1521/testdb ʹ��orato8a��������ִ�������������ݵ���:./orato8a --user=��username/password@testdb���Cquery=��SELECT CUSTNO, TIME FROM TEST�� --file=��/user/output/test.csv�� --field=��,�� --format=3 ��parallel=4����˵��:�Cuser:�������ݿ���û���,����,���Ӵ��Cquery:ָ������������ʹ�õ�sql��ѯ���Cfile:ָ������csv�ļ���·�����ļ����Cfield:��Ϊ������csv�ļ�,����ʹ�ð���Ķ�����Ϊ�ָ����Cformat:����Ϊ3ʱ,��ʾ�����ݵ���Ϊ��ת����ı���ʽ��parallel:���ж�Ϊ4�ڵ���֮ǰ,�����nullֵ����һЩ�����,������Խ�nullֵ����Ϊ��ҵ�����������ص��ض�����,Ǩ����Ϻ��ٸ��³�nullֵ����дMySQL������䲢���������������ͺ��ֶγ���,��Oracle���ݿ��õĽ�������д��MySQL���ݿ��õĽ������;֮���¼MySQL���ݿ�,ʹ�ø�д�Ľ�����佨������д�����е�ע������:1.���뵼������ʱ,����/�����ͻ�����Ҫ������Ŀ��mysql���ݿ���ͬ���ַ�����2.�ڵ���֮ǰ,������ǰ��nullֵ����һЩ�����,������Խ�nullֵ����Ϊ��ҵ�����������ص��ض�����,Ǩ����Ϻ��ٸ��³�nullֵ,�����ķ����Ƚϰ�ȫ,��Ϊ��ͬ�����ݿ��nullֵ�Ĵ���������һ�����ְ���ʾ�����ı��ṹ,�ٳ�ʾ���������,���ο�:CREATE TABLE TEST_TAB (CUSTNO VARCHAR(10),TIME VARCHAR(20));���ݵ���MySQLMGR�ܹ���ִ����������:mysqlsh --uri root@server28:3306 ��ssl-mode=DISABLED �C util import-table/data/raid/data/190513newdata/data03/pdcrFile --schema=PDS --table=PDCR�CfieldsTerminatedBy=��,�� --bytes-per-chunk=10M
���߿���ʹ��python�������еİ�����Ǩ����ͨ��,���Բο�,������Ҫ���в��ԡ�
#Import libraries
import cx_Oracle
import mysql.connector
import pandas as pd
from sqlalchemy import create_engine
#Set Oralce Connection
conn = cx_Oracle.connect('test/test@192.168.19.111/orcl')
#Open cursor
cursor = conn.cursor()
#buidling sql statement to select records from Oracle
sql = "SELECT * FROM T"
#read data into dataframe directly
data=pd.read_sql(sql,conn)
print("Total records form Oracle : ", data.shape[0])
#Create sqlalchemy engine
engine = create_engine("mysql+mysqlconnector://test:root@192.168.19.111:3312/test")
data.to_sql("t", con = engine, if_exists = 'append', index = False, chunksize =10000)
print("Data pushed success")
#close connection
conn.close()
4.2 ���ݵ����
���ݵ������ǿ��Բ���mysqlsh����load data���е���,�ڵ������ݵ�ʱ��Ԥ�ȵ���һЩ����,����ȡ������ܵĴ���,�����������Ӧhash�ص�,Doublewrite�ص�,Ȼ�����������,log�ļ��Ĵ�С,���ܱ��Ķ����,���ܹصĶ��ص�����ȡ��������,���ǽ�����˵�������õ�:
innodb_flush_log_at_trx_commit���innodb_flush_log_at_trx_commit����Ϊ0,log buffer��ÿ��һ�ε�д��log file��,����log file��flush(ˢ������)����ͬʱ���С���ģʽ��,�������ύʱ,������������д����̵IJ��������innodb_flush_log_at_trx_commit����Ϊ1,ÿ�������ύʱMySQL�����log buffer������д��log file,����flush(ˢ������)��ȥ�����innodb_flush_log_at_trx_commit����Ϊ2,ÿ�������ύʱMySQL�����log buffer������д��log file������flush(ˢ������)�IJ���������ͬʱ���С���ģʽ��,MySQL��ÿ��ִ��һ�� flush(ˢ������)������ע��:���ڽ��̵��Ȳ�������,�����ÿ��ִ��һ�� flush(ˢ������)�����������DZ�֤100%�ġ�ÿ�롱��sync_binlogsync_binlog ��Ĭ��ֵ��0,�����ϵͳˢ�����ļ��Ļ���һ��,MySQL����ͬ����������ȥ,������������ϵͳ��ˢ��binary log����sync_binlog =N (N>0) ,MySQL ��ÿдN�� ��������־binary logʱ,��ʹ��fdatasync()����������д��������־binary logͬ����������ȥ��ע:���������autocommit,��ôÿһ�����statement�ͻ���һ��д����;����ÿ�������Ӧһ��д������max_allowed_packet�ڵ������������ر���CLOB����ʱ,���ܻ�����쳣:��Packets larger than max_allowed_packet are not allowed������������MySQL���ݿ���һ��ϵͳ����max_allowed_packet,��Ĭ��ֵΪ1048576(1M),����ͨ��������������ݿ��в�ѯ��ֵ:show VARIABLES like ��%max_allowed_packet%��; �Ĵ˲����ķ�������MySQL�ļ����ҵ�my.cnf�ļ�,��my.cnf�ļ�[MySQLd]������һ��:max_allowed_packet=16777216innodb_log_file_sizeInnoDB��־�ļ�̫��,��Ӱ��MySQL�����ָ���ʱ��,̫С������IO����,��������Ҫ�������ʵ���־��С�������ݵ���ʱ�Ȱ����ֵ����һ�㡣������ν��buffer pool��flush��������Ҳ���ܰ� innodb_log_file_size����̫��,���������� InnoDB��logд�����,���һ���ɲ���ϵͳ��Ҫ�����Disk Cache������innodb_log_buffer_sizeInnoDB���ڽ���־�ļ�д�����ʱ�Ļ�������С�ֽ�����Ϊ��ʵ�ֽϸ�д��������,������ò�����Ĭ��ֵ��һ�����log buffer��һ�������������,����Ҫ�������ύǰд��־������,���,��������������update��insert����delete �ܶ�ļ�¼,��log buffer �㹻������Լ����I/O��innodb_buffer_pool_size���������Ҫ����InnoDB�������������ݡ���������ʱ�Ļ��塣ΪInnoDB�����Ż���Ҫ������һ���������������е�innodb_log_buffer_size�Ĵ�С�Ϳ���,�ٵ����innodb_log_file_sizeԽ��Խ�á�innodb_buffer_pool_instancesInnoDB����ز�ֳɵ�����������������GB��ģ����ص�ϵͳ,ͨ�����ٲ�ͬ�̶߳�д����ҳ�������,������ز��Ϊ��ͬʵ�������ڸ��Ʋ����ԡ�
4.3 Ǩ�ƺ���֤���ݵ�������
������Ǩ����Ϻ�,������Ҫ�ҳ�Ŀ�� MySQL����ڵ���������ݲ�һ�µĵط�,�Ա���ٽ������֮������в��졣���Կ��Ǵ����¼������������֤:
- �Ƚ�Դ���ݿ����Ŀ�����ݿ�����������ҳ����в��,��������count֮��,��Ҫ��ͬһ�������sum��avg��min��max;
- ���Ŀ��MySQL�������г��õ�SQL���,��ȷ��������ԴOracle���ݿ�ƥ��;
- ��Ӧ�����ӵ�Դ���ݿ��Ŀ�����ݿ�,����֤����Ƿ�ƥ�䡣
�塢Ǩ���ܽ�
1����ȷ���ݽṹ����,Ӧ��ʵ�ֵIJ��첢��ȷ�����DZ���Ǩ�ƺ�ȷ�ԵĹؼ���
2�����ʵ�Ǩ�Ʒ�ʽ��Ҫ�ٶ�β��������н����������������ȷ��ʱ�������Ǩ��,һ��Ҫѡ��Ϻ��ʵ�Ǩ�Ʒ�����
3���Ƚ��Ƽ�ʹ��mysqlsh��csv���뵽MySQL����,�÷������Բ��е����ҿ��Խ���������ļ�������Ƭ��
4�����ݿ�Ǩ����Ϻ�,��������ȷ�ļ���dz���Ҫ,Ǩ��ǰ��Ҫ�ƶ�������������У�鲽��ͷ�����
�����ҽ���һ��,С��13����ʦ�����ҵ,������С��˾����,ȥ����ΪOPPO�ȴ�,18����밢��,ֱ�����ڡ���֪��������м�java����ʦ,��Ҫ������,��������Ҫ�Լ������ɳ����DZ���ѧϰ,��������ѵ�����������Ԫ��ѧ��,��ʵѹ����С���Լ�������ϵ����ѧЧ�ʺܵ�������,�������������컨�弼��ֹͣ��ǰ��������ռ���һ�ݡ�java����ȫ��ѧϰ���ϡ������,����Ҳ�ܼ�,����ϣ������������ѧ�ֲ�֪���ôӺ�ѧ�������,ͬʱ�����ҵĸ����������·���Ƭ,���ɻ�ȡȫ��ѧϰ����Ŷ