ԭ��
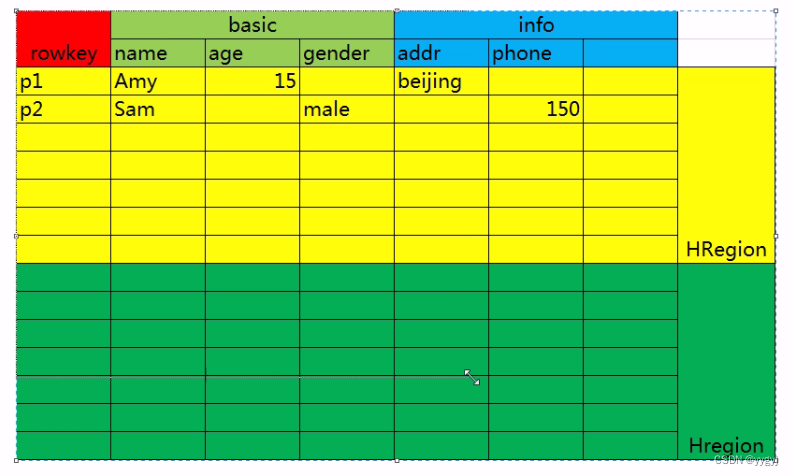
һ��HBase�����洢����
1.��HBase��,���м��ķ����Ͻ�һ��������Ϊһ�����߶��HRegion
2.ÿһ��HRegion��洢�ڲ�ͬ�Ľڵ�(HRegionServer)��
3.��ΪHBase����м������ֵ�������,����ÿһ��HRegion�������������Dz��غϵ�
4.ÿһ��HRegion��¼��ǰHRegion����ʼ�м��ͽ����м�(��Χ����),��������Ŀ����Ϊ�˽��п��ٲ���������������ѯ
5.����HRegion��Ŀ����Ϊ���������ķֲ�ʽ�洢,I�����ܹ���Ч�����HBase��������
6.��ijһ��HRegion�ﵽ������Ĭ����10G,���ֵ���Ե�,��Χ1~20G)��ʱ��,���HRegion���з���,ƽ����Ϊ2��HRegion,����һ��HRegion�����ת��,ת�Ƶ�������HregionServer��
7. HBase�ڽ��зֲ�ʽ�洢����С��λ��HRegion,����HBase�洢����С��λ����HRegion
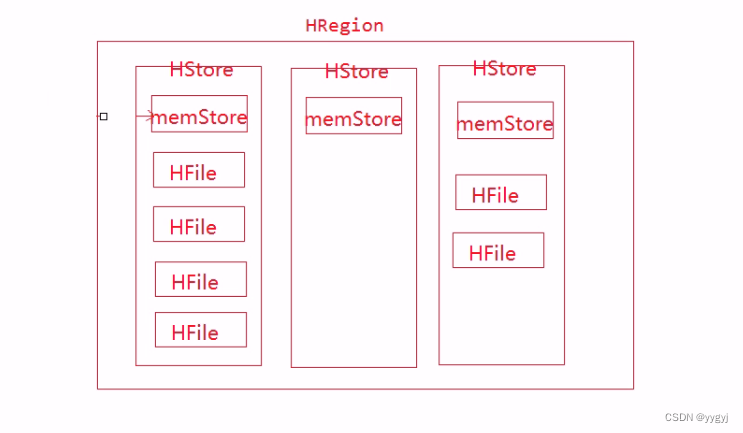
8 HRegion��Ҫ����1�������HStore,ÿһ�������Ӧһ��HStore
9. HStore����һ��memStore(д����)�Լ�0�����HFile(StoreFile)

��������hmaster
[root@hadoop02 bin]# sh hbase-daemon.sh start master
[root@hadoop02 bin]# jps
3681 Jps
3593 HMaster
1579 QuorumPeerMain
����HMaster
1.��HBase�в�����HMaster�ĵ������,��Ϊ�����������HMaster
2.HMaster����2��״̬: active(��Ծ)��backup(����)����HBase��Ⱥ��,�����ĸ��ڵ�
������HMaster,��ô����ڵ����active HMaster,��������HMaster����backup HMasterl
3.������,������HMaster�ĸ���
4.��HBase������ʱ��,����zookeeper��ע��/hbase�ڵ㡣active HMaster
����Zookeeper��ע��һ����ʱ�ڵ�/hbase/master�ڵ�,backup HMaster����/hbase/backup-masters�ڵ���ע����ʱ�ڵ�
5.Active HMaster����Zookeeper��/hbase/backup-masters�е��ӽڵ�ı仯�����/hbase/backup-masters�е��ӽڵ㷢���˱仯,��˵���нڵ�ļ�������Ƴ�
6.��Active HMaster崻�,��ôZookeeper�е���ʱ�ڵ�Ҳ����ʧ,��ô��ʱZookeeper��ֱ��Active�ڵ�ҵ�,��Ҫ��Backup HMaster��ѡһ���л�ΪActive״̬
7. Active/Backup HMaster����Zookeeper��������άϵ����ڵ�Ĵ��
8.Active HMasterĬ����ÿ��180s����һ������,ʵ�ʿ�����һ��Ὣ���ʱ������Ϊ1min
9. Active HMaster��Backup HMasterҪ�����ȱ���,���ʵ�ʹ�����,Backup HMaster�ĸ���һ�㲻����2��
10. HMaster��ְ��:
a.�Ա��ṹ���й���(���Ĵ�����ɾ������- create/drop/alter -ddl) ,�����ڱ������ݵIJ���(put/get/scan/delete - dml)������HMaster
b.����HRegionServer��ddl��(zk������dml����rs��������)
[zk: localhost:2181(CONNECTED) 2] ls /hbase
[replication, meta-region-server, rs, splitWAL, backup-masters, table-lock, region-in-transition, online-snapshot, master, running, recovering-regions, draining, namespace, hbaseid, table]
11.��һ�ζ�д����:
a.��0.96�汾��ǰ:
b.��0.96�汾��ʼ:
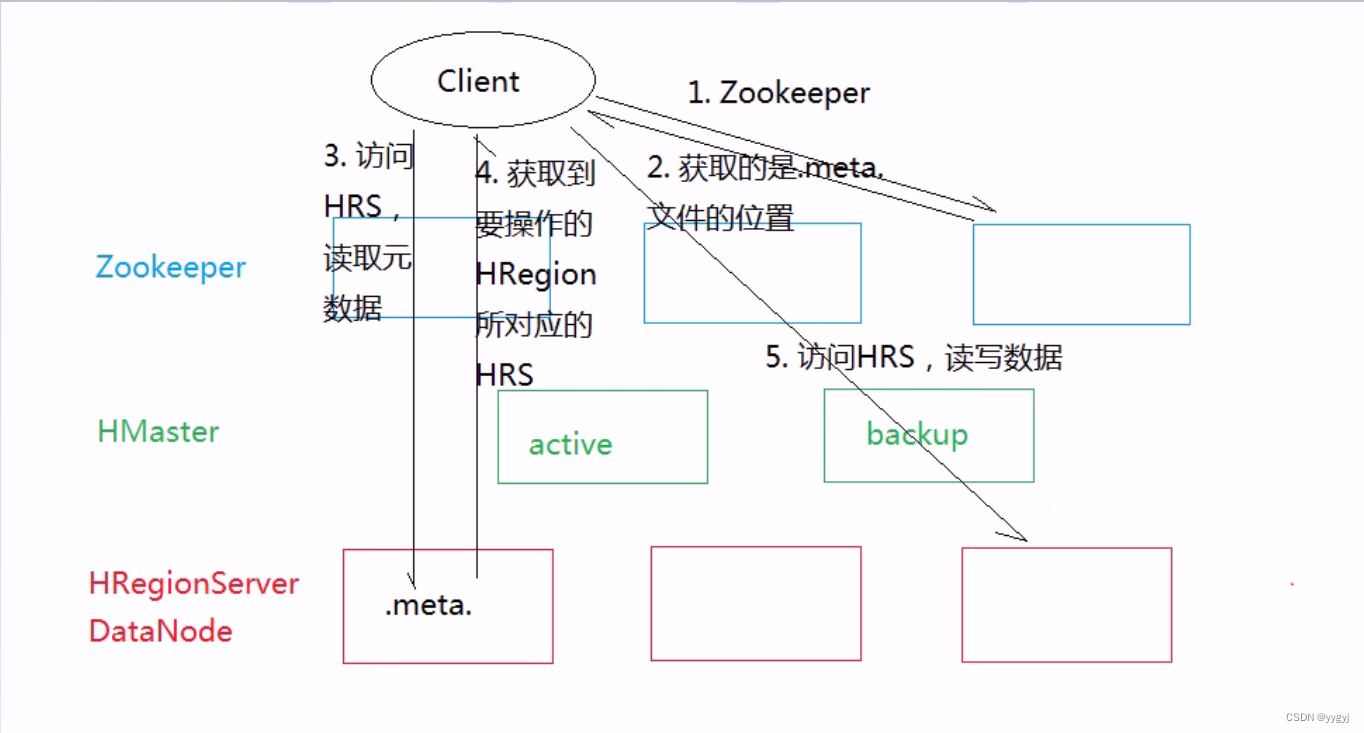
i����0.96��ʼ,Ϊ����߶�дЧ�ʼ��ٷ��ʴ���,�ڿͻ��������˻������,�洢HRegion����Ӧ��HRegionServer������ʱ����ӳ�,�ͻ��˵Ļ����Խ��Խ��,��дЧ��Ҳ��Խ��Խ��
ii������������������HRegion�ķ��ѻ����ǿͻ���崻�,��ô������ƾ���Ҫ���½���
12.Ԫ����:
a.�����������������ƿռ����Ϣ
b.ÿһ������Ӧ��HRegion
c. HRegion�����ڵ�HRegionServer
�ġ�HRegionServer
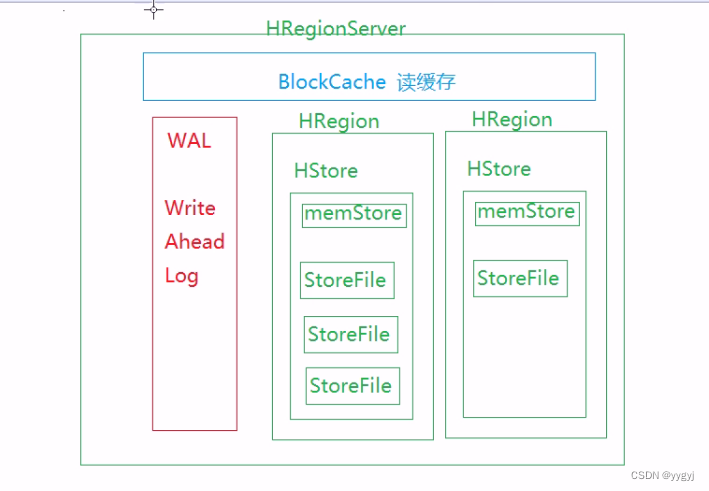
1.HRegionServer���Ǵ洢HRegion���ǹ���HRegionr
2.��HBase�ٷ��ĵ��и�������,ÿһ��HRegionServer�ܹ�����1000��HRegion
3.�ṹ:
a. WAL - Write Ahead Log-����ΪHLog
i.���ڼ�¼д��������HRegionServer�յ�д�����ʱ��,���Ƚ�������¼��WAL��,Ȼ���ٸ��µ�memStore�С����memStore����,���ˢ��HFile��
ii.��HBase0.92�汾֮ǰ,WAL�Ǵ���д,��0.92�汾��ʼ,WAL���н��в���д
b. BlockCache
i���ڶ�ȡ���ݵ�ʱ��,��Ѷ�ȡ�����ݷ����������ii. BlockCache�ڽ��л����ʱ����õ���"�ֲ���"ԭ��:
1)ʱ��ֲ���:���ijһ�����ݱ���ȡ,��ô���������ٴα�
��ȡ�ĸ��ʾͱ��������ݴ�,��ô��ʱӦ�ý��л���
2)�ռ�ֲ���:���ijһ�����ݱ���ȡ,��ô�������������ڵ����ݱ���ȡ�ĸ��ʾͱ��������ݴ�,��ô��ʱ���ڵ�����Ӧ�ý��л��档�ռ�ֲ����ڷŵ�ʱ������Data BlockΪ��λ��BlockCache�з�
iii.���þֲ���ԭ����Ŀ����Ϊ�����������
iv. BlockCache��άϵ���ڴ���,Ĭ�ϴ�С��128M
v.BlockCache��ȡ��LRU����:��BlockCache����֮��,������ʱ�䲻��/ʹ�ô������ٵ�����
c. HRegion -��HBase�д洢���ݵĻ����ṹ
i��һ��HRegion����1�������HStore,HStore����������������������,ÿһ�������Ӧһ��HStore
ii��ÿһ��HStore�а���1��memStore�Լ�0�����storeFile/HFile
iii. memStore������һ��д����,��άϵ���ڴ���,�����128M��������memStore�л��������:�м��ֵ���->�������ֵ���-�������ֵ���->ʱ�������,Ҳ����ζ����HFile�������Ǿֲ�����-ÿһ��HFileӦ���������
����
һ��д����
1.HRegionServer���յ�д�����ʱ��,�Ƚ����д�����¼��wAL��,Ȼ���ٸ��µ�memStore��,���������memStore�н�������
2.��memStore�ﵽ������ʱ�����г�ˢ,����HFile:
a.Ĭ�������,��memStore�ﵽ128M(ͨ��
hbase.hregion.memstore.flush.size����������,ע�ⵥλ���ֽ�)��ʱ��,�ὲ���ͳ�ˢ
b.��WAL�ļ��ﵽ1G��ʱ��,Ҳ����г�ˢ,���Ҵ�ʱ�����һ���µ�WAL�ļ�
c.��һ��HRegionServer�е����е�memStore���ڴ�ռ����ǰ�ڵ������ڴ��35%��ʱ��,Ҳ����г�ˢ,��ʱ��ˢ��ʱ��,���ȳ�ˢ�Ƚϴ��memStorel
3.��HBase�ṩ��2�ֺϲ�����-���HFile���кϲ�-Ĭ�ϵĺϲ���ʽ����minor compact
a. minor compact:����ǰHStore�ж��С��HFile�ϲ��ɼ������HFile
b. major compact:����ǰHStore�����е�HFile�ϲ���һ��HFile
4.�ںϲ���ʱ��,���ݻ�������������,������������л�ȥ�Ƴ��������ΪҪɾ��������
5.Update:
����������memStore�л�����HFile��,�ڽ��и��µ�ʱ��,���ǽ�����д��,�ںϲ���ʱ��,�����ָ���İ汾,��������ʱ������
Delete:
����������memStore�л�����HFile��,�ڽ���ɾ����ʱ��,���ǽ�����д��,�ڽ�����д���ʱ��,����ĩβ������ɾ����ǡ��ںϲ���ʱ��,����������ɾ�����,��������Ӧ������
a. HFilev1:
i.������6����:
-
Data Block:���ݿ顣ÿһ��DataBlock�д洢1��Magic-ħ��(ħ��������һ���������,���������ڽ���У��,��֤�������û�б��ı��)�Ͷ��KeyValue���ݡ�С��DataBlock�����ڲ�ѯ,���Data Block�����ڱ���scan
-
Meta Block:��¼��Ԫ����,���������Ϣ�ڴ������HFile�в�����
-
File Info:��¼��HFile��������Ϣ
-
Data lndex:��¼����ÿһ��Data Block����ʼ�ֽںͽ����ֽ�
-
Meta lndex:��¼����ÿһ��Meta Block����ʼ�ֽںͽ����ֽ�
-
Trailer:�̶�4���ֽڴ�С,��¼��File Info��Data lndex��Meta lndex����ʼ�ֽ�
ii.�ڶ�ȡHFile��ʱ��,��Ҫ�ȶ�ȡTrailer,��ȡ��Data Index��λ��,Ȼ���Data Index��ȥ����ÿһ��Data Block��λ��,Ȼ�����ȥ��ȡData Block
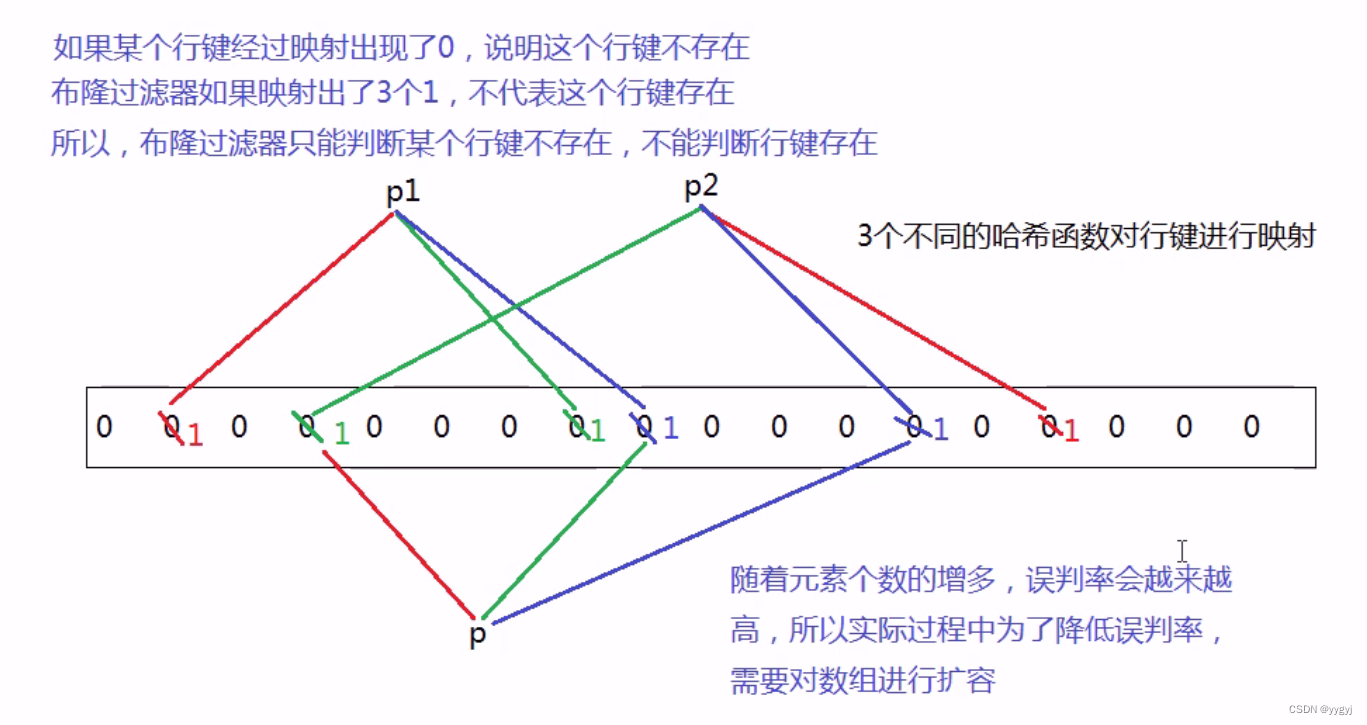
b. HFilev2�汾��������Bloom Filter-��¡������-HFile�е�ÿһ���м����ᾭ����¡����������ӳ��
����HBase������
1.����������Ӧ��HRegionServer
2.�ȴ�BlockCache�ж�ȡ,���������,���ȡmemStore�е�����,���Ҳ������,���HFile��ȡ
3.�����HFile�ж�ȡ,��Ҫ��ɸѡ(��Χ+��¡����)����������HFile4.��HFile��,������м�ɸѡ�����Ϸ�Χ��Data Block
5.����ܹ���ȡ��,��ô�����������ڵ�Data Block�����建�浽BlockCache��
ע��:HBase��һ��αʵʱ�����ݿ�C-����
Redis
cassandra ��MS ----CAP WNR
hbase����
1.����data block
2.�ʵ��ر����ݿ黺��
3.������¡������
4.��������ѹ��
5.����scan����
6.��ʾ��ָ����
7.�ر�ResultScanner
8.ʹ��������
9.�ر�wal��־
10.�����Զ���ˢ
11.��ǰ����HRegion
12.����ZooKeeper Session����Чʱ��
phoenix��װʹ��(����phoenix��sqlȥ����hbase)
1.sql�����sql
2.���ȶ�
3.�رղ�����