Postgresql中的并发控制
一、 事务隔离级别
sql标准定义了四种隔离级别:读未提交、读已提交、读可重复、可序列化。四种关系层层递进,越来越严格。
1、读未提交 Read uncommitted
解释就是一个事务读到了另一个事务未提交的数据,一旦另一个事务回滚了,那么读到的数据就是有问题的。这种现象就是脏读了。
2、读已提交 Read committed
读已经提交的数据能够解决脏读的问题,因为这个事务需要等待另一个事务提交后才能读取数据。但是该级别有一个问题,重复读的时候可能会产生不同的数据,这是因为该事务读取的两次过程中,这些数据并没有锁住 ,还是可以处于能够修改(update和delete)的。该级别是postgresql默认的级别。
3、可重复读 Repeatable read
该级别解决了读已提交的不可重复读的问题,在事务开启的时候,不能再修改操作了,直到该事务提交。该级别是mysql,Oracle,sql server默认的级别。但是在该级别,还是会出现幻读的问题,幻读和可重复读非常类似,都是两次查询的结果不一致,可以这么理解,一个事务在插入一个检查过不存在的记录时,发现数据已经存在了,之前检查的结果就像幻觉一样,这是因为已经插入了新的数据导致的。区别需要从机制来看,读某一行数据,会给行加行排他锁,事务无法修改数据,重复读就不会出现数据不一致的问题,但是并没有加表锁,还是可以insert数据的。这就导致了后面查询数据变多了。mysql会出现幻读,pg不会。
幻读举例说明如下:
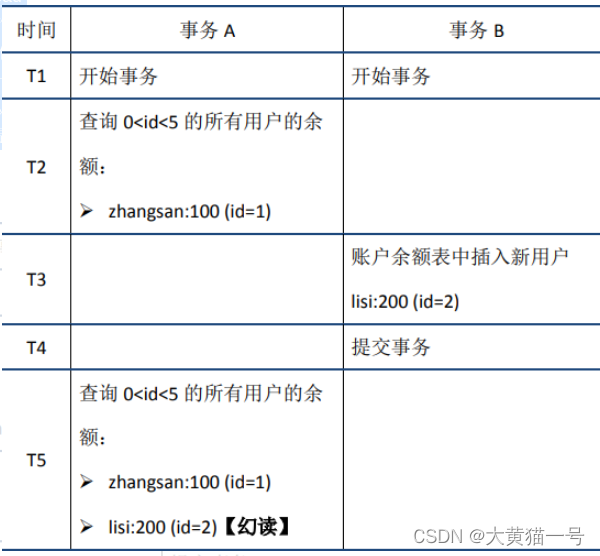
4.序列化 Serializable
序列化是最高的事务隔离级别,在该级别下,事务是按照串行化的顺序执行,可以避免脏读,重复读,幻读。但是可想而知,所有事务都是按照串行化顺序执行,那怎么保证高并发呢?这种数据库必然性能非常低下,几乎没有数据库会达到这种级别。
二、 锁
2.1锁的分类
PG中的锁从不同维度的划分:
- 从锁对象种类上:分为表锁、行锁等
- 从锁的访问类型上:分为共享锁、独占锁、读锁、写锁等
- 从实现机制上:分为SpinLock、LWLock和RegularLock。PG中又定义了另外两种锁advisorylock和SIReadLock锁。
1、SpinLocK锁
SpinLock锁是最底层的锁,使用互斥信号量实现,与操作系统和硬件环境联系紧密。
特点:封锁时间很短,没有等待队列和死锁检测机制,事务结束时不能自动释放。
2、LWLock锁
LWLock(轻量级锁)是由SpinLock实现,主要提供对共享存储器的数据结构的互斥访问。LWLock有三种锁模式,一种为排他模式,另一种是共享模式,以及一种特殊模式。
特点:有等待队列、无死锁检测、在elog期间自动释放锁。
3、RegularLock锁(常规锁或者事务锁)
RegularLock就是一般数据库事务中所指的锁,可以分为表级别锁和行级别锁两种。
RegularLock锁由LWLock实现,特点是:有等待队列,有死锁检测,能自动释放锁。
4、Advisory Lock锁
建议锁,主要用于实现用户级的封锁控制,粒度可粗可细,完全由用户控制。
5、SIReadLock
谓词锁,是专门用于实现“可串行化”隔离级别的。
不同锁的对比:

2.2 ?常规锁
2.2.1 RegularLock(常规锁)的划分
- regularLock锁的方法类型
PG中使用两种加regularLock锁的方法:DEFAULT_LOCKMETHOD(默认)和USER_LOCKMETHOD.
- RegularLock支持的锁模式(表锁,实际上有一部分是行锁,一部分是表锁)
共有8种,按排他级别从低到高:
AccessShareLock(访问共享锁):进行SELECT 查询操作时,自动施加在被查询的表上。使用场景:SELECT。(弱锁)
RowShareLock(行共享锁):语句使用SELECT....FOR UPDATE 和FOR SHARE时,使用该锁对表加锁。使用场景:SELECT FOR UPDATE/ FOR SHARE。(弱锁)
RowExclusiveLock(行排他锁):使用UPDATE、DELETE、INSERT语句时使用该锁对表加锁。使用场景:INSERT/UPDATE/DELETE。(弱锁)
ShareUpdateExclusiveLock(共享更新排他锁):使用VACUUM(不带FULL选项)ANALYZE或CREATE INDEX CONCURRENTLY语句时使用共享更新排他锁。使用场景:VACUUM。
ShareLock(共享锁):使用不带CONCURRENTLY选项的CREATE INDEX语句时,使用共享锁对表加锁。使用场景:主要用于创建索引。使用场景:CREATE INDEX.(强锁)
ShareRowExclusiveLock(共享行排他锁):类似于排他锁,但是允许行共享。使用场景:create triggeer。(强锁)
ExclusiveLock(排他锁):阻塞行共享,使用场景:refresh materialized view。(强锁)
AccessExclusiveLock(访问排他锁):最强级别的锁,任何锁都被排斥。被ALTER TABLE、DROP TABLE以及VACUUM FULL操作要求。应用场景:DROP、TRUNCATE、REINDEX、VACUUM FULL。(强锁)
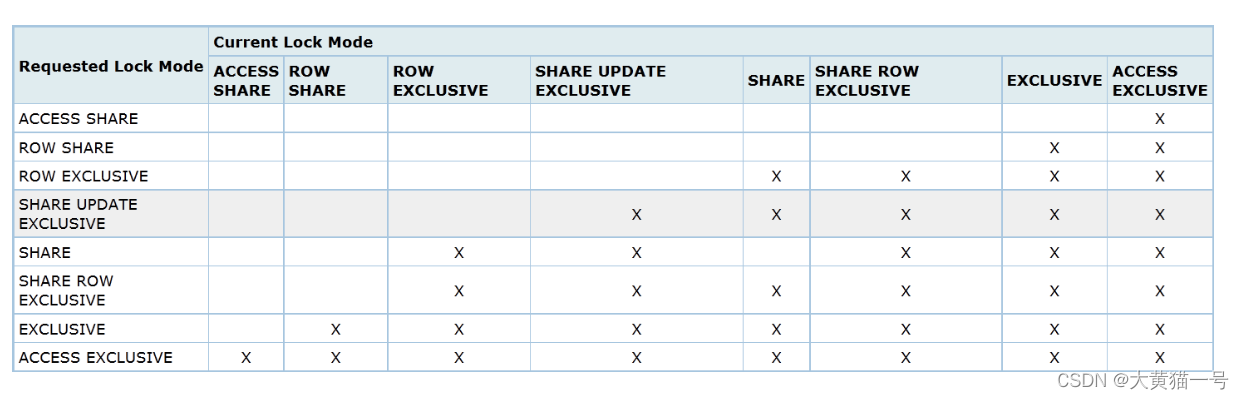
表锁的不同锁模式之间加锁请求冲突情况,如下图所示:
2.2.2 常规锁的加锁步骤
??在pg中,锁获取最重要的函数是LockAcquire(核心是调用LockAcquireExtended),这是非常高频的操作,性能相当重要。因此在LockAcquire中,对封锁的性能做了大量优化。
常规锁主要保存在以下4个位置:
1.主锁表(LOCK结构体):保存一个锁对象所有相关信息
2.本地锁表(LOCALLOCK结构体):对于重复申请的锁进行计数,避免频繁访问主锁表和进程锁表,相当于一层缓存
3.快速路径(fast path):对弱锁的访问保存到本进程,避免频繁访问主锁表和进程锁表(快速路径的申请和释放需要调用进程锁表)
4.进程锁表(PROCLOCK结构体):保存一个锁对象中与当前会话(进程)相关的信息.
a.本地锁表
? ?每个会话都保存了一个本地锁表 ―― 当一个事务(不同事务还是需要检测)重复在同一个对象上申请同类型锁时,无须做冲突检测,只要将这个锁记录在本地即可,避免频繁访问主锁表和进程锁表。--一个本地锁表只对应一个事务,不同的事务的本地锁表不通用。
a.1.本地锁表的获取
本地锁表的判断和获取在LockAcquireExtended函数。
本地锁表的结构体:
(1)
typedef struct LOCALLOCK
{
/* tag */
LOCALLOCKTAG tag; /* 本地锁唯一id:LOCKTAG + LOCKMODE */
/* data */
uint32 hashcode; /* LOCKTAG的hash值 */
LOCK *lock; /* 关联主锁表对象 */
PROCLOCK *proclock; /* 关联进程锁表对象 */
int64 nLocks; /* total number of times lock is held */ /* 获得同类型锁的次数 */
int numLockOwners; /* # of relevant ResourceOwners */
int maxLockOwners; /* allocated size of array */
LOCALLOCKOWNER *lockOwners; /* dynamically resizable array */
bool holdsStrongLockCount; /* bumped FastPathStrongRelationLocks fast path需要的标记,是否持有了强锁*/
bool lockCleared; /* we read all sinval msgs for lock */
} LOCALLOCK;?????????对应该哈希表来说,其键是LOCALLOCKTAG,其值是LOCALLOCK。本地锁表的查询标签是LockTag+请求的锁模式。如果没有从本地锁表中检查到对应的锁,说明这是本事务第一次申请该锁。如果没有持有过该锁,其LOCALLOCK结构体中的nLocks为0,如果能够在本地锁表中找到对应的锁(nLocks不大于零)就说明这个锁对象和锁模式已经授予给本事务,只需要给本地锁表的这个锁增加引用计数就可以,首先增加nLocks计数,增加ResourceOwner中锁的计数。
(2)
typedef struct LOCALLOCKTAG
{
LOCKTAG lock; /* identifies the lockable object */
LOCKMODE mode; /* lock mode for this table entry */
} LOCALLOCKTAG;LOCKTAG:加锁的对象,使用不同的字符位标记不同的加锁对象。
typedef struct LOCKTAG
{
uint32 locktag_field1; /* a 32-bit ID field */
uint32 locktag_field2; /* a 32-bit ID field */
uint32 locktag_field3; /* a 32-bit ID field */
uint16 locktag_field4; /* a 16-bit ID field */
uint8 locktag_type; /* see enum LockTagType */
uint8 locktag_lockmethodid; /* lockmethod indicator */ /* 加锁的类型,默认锁类型或者用户自定义的锁类型 */
} LOCKTAG;加锁对象与标记位的对应关系在代码中申请的结构体下方,例子如下:
/* ID info for a relation is DB OID + REL OID; DB OID = 0 if shared */
#define SET_LOCKTAG_RELATION(locktag,dboid,reloid) \
((locktag).locktag_field1 = (dboid), \
(locktag).locktag_field2 = (reloid), \
(locktag).locktag_field3 = 0, \
(locktag).locktag_field4 = 0, \
(locktag).locktag_type = LOCKTAG_RELATION, \
(locktag).locktag_lockmethodid = DEFAULT_LOCKMETHOD)?LOCKMODE:锁的模式
常规锁加锁流程:
- 本地锁表查找该锁,如果没有查找到该锁,是一个新锁,将该锁插入到本地锁hash表中,初始化。如果找到该锁,查看是否有足够的空间存储该锁,如果没有的话扩展空间,得到该锁的hash值。
- 如果是本地锁表中已经存在该类型锁,更新LOCALLOCK结构体信息,将对应的进程的锁个数+1,总锁数量(nlock)+1,返回LockAcquire()的结果。
- 如果是新锁,检查锁是强锁还是弱锁。
- 弱锁:使用hashcode 计算得到fasthashcode,得到该锁,检测分区有没有强锁,没有强锁并且fast-path有槽位就可以将该锁放入fast-path,同时清除locallock标志位。如果以上没有执行成功,执行第四步。
- 强锁:获得强锁,将fast-path锁转移到主锁表。
- 初始化主锁表和进程锁表用来申请新锁,一般强锁才申请主锁表和进程锁表冲突检测。冲突检测。
?代码如下:
/*
* 执行一次数据库操作该函数需要循环多次,因为要对多个数据对象加锁,例如系统表等等
*/
LockAcquireResult
LockAcquireExtended(const LOCKTAG *locktag,
LOCKMODE lockmode,
bool sessionLock,
bool dontWait,
bool reportMemoryError,
LOCALLOCK **locallockp)
{
LOCKMETHODID lockmethodid = locktag->locktag_lockmethodid;
LockMethod lockMethodTable; //里面有锁的模式数量,标志冲突位
LOCALLOCKTAG localtag; //本地锁表信息,存储着本地锁表的类型,加锁的对象
LOCALLOCK *locallock; //本地锁
LOCK *lock; //主锁表
PROCLOCK *proclock; //进程锁
bool found; //当前会话的是否已经有同类型的锁
ResourceOwner owner;
uint32 hashcode;
LWLock *partitionLock;
int status;
bool log_lock = false;
if (lockmethodid <= 0 || lockmethodid >= lengthof(LockMethods)) // lock method判断,必须>0且< LockMethods数组长度。 默认锁或者用户自定义的锁?
elog(ERROR, "unrecognized lock method: %d", lockmethodid);
lockMethodTable = LockMethods[lockmethodid];
if (lockmode <= 0 || lockmode > lockMethodTable->numLockModes) // 锁模式(弱锁or强锁)判断,必须小于8 因为一共就8级锁
elog(ERROR, "unrecognized lock mode: %d", lockmode);
//是否为恢复模式,恢复模式不能获取RowExclusiveLock以上的锁
if (RecoveryInProgress() && !InRecovery &&
(locktag->locktag_type == LOCKTAG_OBJECT ||
locktag->locktag_type == LOCKTAG_RELATION) &&
lockmode > RowExclusiveLock)
ereport(ERROR,
(errcode(ERRCODE_OBJECT_NOT_IN_PREREQUISITE_STATE),
errmsg("cannot acquire lock mode %s on database objects while recovery is in progress",
lockMethodTable->lockModeNames[lockmode]),
errhint("Only RowExclusiveLock or less can be acquired on database objects during recovery.")));
#ifdef LOCK_DEBUG
if (LOCK_DEBUG_ENABLED(locktag))
elog(LOG, "LockAcquire: lock [%u,%u] %s",
locktag->locktag_field1, locktag->locktag_field2,
lockMethodTable->lockModeNames[lockmode]);
#endif
/* Identify owner for lock */
if (sessionLock) /* 如果是会话级别的锁 ALTER DATABASE SET TABLESPACE,owner 是 NULL。如果是事务级别的,设置当前的owner,该owner是后期判断是否在本地加锁的条件 */
owner = NULL;
else
owner = CurrentResourceOwner;
/*
* Find or create a LOCALLOCK entry for this lock and lockmode
*/
MemSet(&localtag, 0, sizeof(localtag)); /* must clear padding */
localtag.lock = *locktag; /*加锁的对象*/
localtag.mode = lockmode; /*锁的模式(级别)*/
locallock = (LOCALLOCK *) hash_search(LockMethodLocalHash,
(void *) &localtag,
HASH_ENTER, &found); /* 查找本地锁表 */
/*
* if it's a new locallock object, initialize it
*/
if (!found) /*(一)、 如果是一个新锁,先在本地化初始该锁,查找本地有没有该级别的锁*/
{
locallock->lock = NULL;
locallock->proclock = NULL;
locallock->hashcode = LockTagHashCode(&(localtag.lock));
locallock->nLocks = 0;
locallock->holdsStrongLockCount = false;
locallock->lockCleared = false;
locallock->numLockOwners = 0;
locallock->maxLockOwners = 8;
locallock->lockOwners = NULL; /* in case next line fails */
locallock->lockOwners = (LOCALLOCKOWNER *)
MemoryContextAlloc(TopMemoryContext,
locallock->maxLockOwners * sizeof(LOCALLOCKOWNER));
}
else /*(二)、 如果在本地找对应的锁*/
{
/* Make sure there will be room to remember the lock */
if (locallock->numLockOwners >= locallock->maxLockOwners)
{
int newsize = locallock->maxLockOwners * 2;
locallock->lockOwners = (LOCALLOCKOWNER *)
repalloc(locallock->lockOwners,
newsize * sizeof(LOCALLOCKOWNER));
locallock->maxLockOwners = newsize;
}
}
hashcode = locallock->hashcode; /*得到该锁的hash值 */
if (locallockp)
*locallockp = locallock;
/*
* If we already hold the lock, we can just increase the count locally.
*
* If lockCleared is already set, caller need not worry about absorbing
* sinval messages related to the lock's object.
*/
/*
* 如果已经持有该锁,需要增加计数
*/
if (locallock->nLocks > 0) /* 如果检查到了对应锁(locallock->nLocks一定大于0),说明这个锁对象和模式已经授予了本事务,给本地锁表对应锁增加引用计数即可,这个工作由GrantLockLocal函数完成。 */
{
GrantLockLocal(locallock, owner);
if (locallock->lockCleared)
return LOCKACQUIRE_ALREADY_CLEAR;
else
return LOCKACQUIRE_ALREADY_HELD;
}
/*
* Prepare to emit a WAL record if acquisition of this lock needs to be
* replayed in a standby server.
*
* Here we prepare to log; after lock is acquired we'll issue log record.
* This arrangement simplifies error recovery in case the preparation step
* fails.
*
* Only AccessExclusiveLocks can conflict with lock types that read-only
* transactions can acquire in a standby server. Make sure this definition
* matches the one in GetRunningTransactionLocks().
*/
/*
* 如果 锁级别>=8 && 需要加锁 && 不是在恢复模式 && 是在流复制模式中,则直接加最大级别的锁
*/
if (lockmode >= AccessExclusiveLock &&
locktag->locktag_type == LOCKTAG_RELATION &&
!RecoveryInProgress() &&
XLogStandbyInfoActive())
{
LogAccessExclusiveLockPrepare();
log_lock = true;
}
/*
* Attempt to take lock via fast path, if eligible. But if we remember
* having filled up the fast path array, we don't attempt to make any
* further use of it until we release some locks. It's possible that some
* other backend has transferred some of those locks to the shared hash
* table, leaving space free, but it's not worth acquiring the LWLock just
* to check. It's also possible that we're acquiring a second or third
* lock type on a relation we have already locked using the fast-path, but
* for now we don't worry about that case either.
*/
/* 如果申请的锁是弱锁,并且有空间存储Fast-Path锁*/
if (EligibleForRelationFastPath(locktag, lockmode) &&
FastPathLocalUseCount < FP_LOCK_SLOTS_PER_BACKEND) /* FastPathLocalUseCount:本地快路径使用的个数,最大是16 */
{
uint32 fasthashcode = FastPathStrongLockHashPartition(hashcode); /* 使用hashcode 计算得到fasthashcode */
bool acquired;
/*
* LWLockAcquire acts as a memory sequencing point, so it's safe to
* assume that any strong locker whose increment to
* FastPathStrongRelationLocks->counts becomes visible after we test
* it has yet to begin to transfer fast-path locks.
*/
LWLockAcquire(&MyProc->backendLock, LW_EXCLUSIVE);
if (FastPathStrongRelationLocks->count[fasthashcode] != 0) /*FastPathStrongRelationLocks->count[fasthashcode] 记录对应分区的strong锁的个数,当计数器非0时,不会使用fast-path机制在对应分区获取新的关系锁。*/
acquired = false;
else /* 分区没有强关系锁才能获得 fast-path 锁 */
acquired = FastPathGrantRelationLock(locktag->locktag_field2,
lockmode);
LWLockRelease(&MyProc->backendLock); /* 释放以前获得的进程锁 */
if (acquired)
{
/*
* The locallock might contain stale pointers to some old shared
* objects; we MUST reset these to null before considering the
* lock to be acquired via fast-path.
*/
/*
* locallock 可能包含指向一些旧共享对象的过时指针;在考虑通过快速路径获取锁之前,我们必须将其重置为 null 。
*/
locallock->lock = NULL;
locallock->proclock = NULL;
GrantLockLocal(locallock, owner);
return LOCKACQUIRE_OK;
}
}
/*
* If this lock could potentially have been taken via the fast-path by
* some other backend, we must (temporarily) disable further use of the
* fast-path for this lock tag, and migrate any locks already taken via
* this method to the main lock table.
*/
/* 如果快锁表中的锁已经被其他的backend占用,需要迁移到主表中 */
/* 如果申请的锁模式为强锁 */
if (ConflictsWithRelationFastPath(locktag, lockmode))
{
uint32 fasthashcode = FastPathStrongLockHashPartition(hashcode);
/* 获取强锁 */
BeginStrongLockAcquire(locallock, fasthashcode);
/* 弱锁转移主锁表,如果不能转移就报错 */
if (!FastPathTransferRelationLocks(lockMethodTable, locktag,
hashcode))
{
AbortStrongLockAcquire();
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
if (reportMemoryError)
ereport(ERROR,
(errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("out of shared memory"),
errhint("You might need to increase max_locks_per_transaction.")));
else
return LOCKACQUIRE_NOT_AVAIL;
}
}
/*
* We didn't find the lock in our LOCALLOCK table, and we didn't manage to
* take it via the fast-path, either, so we've got to mess with the shared
* lock table.
*/
/* 如果获得强锁,或者fast-path没有空间了 */
partitionLock = LockHashPartitionLock(hashcode);
LWLockAcquire(partitionLock, LW_EXCLUSIVE);
/*
* Find or create lock and proclock entries with this tag
*
* Note: if the locallock object already existed, it might have a pointer
* to the lock already ... but we should not assume that that pointer is
* valid, since a lock object with zero hold and request counts can go
* away anytime. So we have to use SetupLockInTable() to recompute the
* lock and proclock pointers, even if they're already set.
*/
/* 初始化主锁表和进程锁表用来申请新锁,一般强锁才申请主锁表和进程锁表 */
proclock = SetupLockInTable(lockMethodTable, MyProc, locktag,
hashcode, lockmode);
if (!proclock)
{
AbortStrongLockAcquire();
LWLockRelease(partitionLock);
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
if (reportMemoryError)
ereport(ERROR,
(errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("out of shared memory"),
errhint("You might need to increase max_locks_per_transaction.")));
else
return LOCKACQUIRE_NOT_AVAIL;
}
locallock->proclock = proclock;
lock = proclock->tag.myLock;
locallock->lock = lock;
/*
* If lock requested conflicts with locks requested by waiters, must join
* wait queue. Otherwise, check for conflict with already-held locks.
* (That's last because most complex check.)
*/
/*做锁的冲突检测*/
if (lockMethodTable->conflictTab[lockmode] & lock->waitMask)
status = STATUS_FOUND;
else
status = LockCheckConflicts(lockMethodTable, lockmode,
lock, proclock);
if (status == STATUS_OK)
{
/* No conflict with held or previously requested locks */
GrantLock(lock, proclock, lockmode);
GrantLockLocal(locallock, owner);
}
else
{
Assert(status == STATUS_FOUND);
/*
* We can't acquire the lock immediately. If caller specified no
* blocking, remove useless table entries and return NOT_AVAIL without
* waiting.
*/
if (dontWait)
{
AbortStrongLockAcquire();
if (proclock->holdMask == 0)
{
uint32 proclock_hashcode;
proclock_hashcode = ProcLockHashCode(&proclock->tag, hashcode);
SHMQueueDelete(&proclock->lockLink);
SHMQueueDelete(&proclock->procLink);
if (!hash_search_with_hash_value(LockMethodProcLockHash,
(void *) &(proclock->tag),
proclock_hashcode,
HASH_REMOVE,
NULL))
elog(PANIC, "proclock table corrupted");
}
else
PROCLOCK_PRINT("LockAcquire: NOWAIT", proclock);
lock->nRequested--;
lock->requested[lockmode]--;
LOCK_PRINT("LockAcquire: conditional lock failed", lock, lockmode);
Assert((lock->nRequested > 0) && (lock->requested[lockmode] >= 0));
Assert(lock->nGranted <= lock->nRequested);
LWLockRelease(partitionLock);
if (locallock->nLocks == 0)
RemoveLocalLock(locallock);
if (locallockp)
*locallockp = NULL;
return LOCKACQUIRE_NOT_AVAIL;
}
/*
* Set bitmask of locks this process already holds on this object.
*/
MyProc->heldLocks = proclock->holdMask;
/*
* Sleep till someone wakes me up.
*/
TRACE_POSTGRESQL_LOCK_WAIT_START(locktag->locktag_field1,
locktag->locktag_field2,
locktag->locktag_field3,
locktag->locktag_field4,
locktag->locktag_type,
lockmode);
WaitOnLock(locallock, owner);
TRACE_POSTGRESQL_LOCK_WAIT_DONE(locktag->locktag_field1,
locktag->locktag_field2,
locktag->locktag_field3,
locktag->locktag_field4,
locktag->locktag_type,
lockmode);
/*
* NOTE: do not do any material change of state between here and
* return. All required changes in locktable state must have been
* done when the lock was granted to us --- see notes in WaitOnLock.
*/
/*
* Check the proclock entry status, in case something in the ipc
* communication doesn't work correctly.
*/
if (!(proclock->holdMask & LOCKBIT_ON(lockmode)))
{
AbortStrongLockAcquire();
PROCLOCK_PRINT("LockAcquire: INCONSISTENT", proclock);
LOCK_PRINT("LockAcquire: INCONSISTENT", lock, lockmode);
/* Should we retry ? */
LWLockRelease(partitionLock);
elog(ERROR, "LockAcquire failed");
}
PROCLOCK_PRINT("LockAcquire: granted", proclock);
LOCK_PRINT("LockAcquire: granted", lock, lockmode);
}
/*
* Lock state is fully up-to-date now; if we error out after this, no
* special error cleanup is required.
*/
FinishStrongLockAcquire();
LWLockRelease(partitionLock);
/*
* Emit a WAL record if acquisition of this lock needs to be replayed in a
* standby server.
*/
if (log_lock)
{
/*
* Decode the locktag back to the original values, to avoid sending
* lots of empty bytes with every message. See lock.h to check how a
* locktag is defined for LOCKTAG_RELATION
*/
LogAccessExclusiveLock(locktag->locktag_field1,
locktag->locktag_field2);
}
return LOCKACQUIRE_OK;
}
?