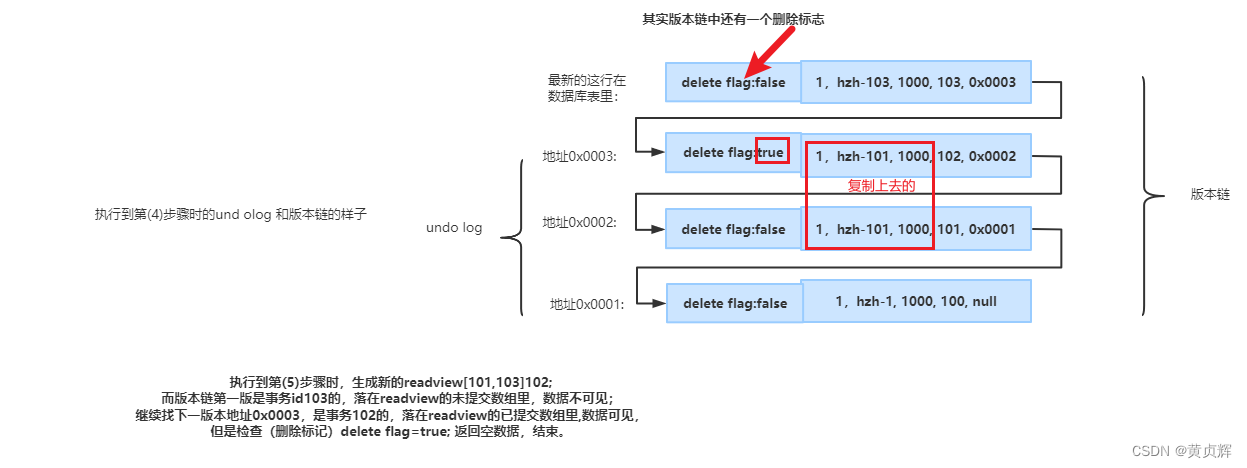
������뼶��
1����δ�ύ(Read Uncommitted) �ܶ�����������δ�ύ������
2�������ύ(Read Committed) �ܶ��������������ύ������
3�����ظ���(Repeatable Read) �����������������ύ������,ֻҪ���ڱ�������,��ζ�ȡ,����һ���Ľ��,�����DZ������Լ�����,���ǻ�������ݿ����µ�����ȥ�ĵ�,�ٲ�ѯʱ,Ҳ�����µ��Ľ��
4�����л�(Serializable) ÿ������˳��ִ��
4�ָ��뼶����ڵ�����:
���:����a��ȡ����bδ�ύ������,����b�ع���֮��,����a��֪����������һ���ԡ�
�����ظ���:����a�ڲ���ζ�ȡʱ,����b�����ύ��,����a��;��ȡ��������b�ύ������,ǰ��һ�¡������ϸ����ԡ�
�ö�:����a����ͬ������ȥ��ѯ֮ǰ���������,ȴ��������b����������ݡ������ϸ����ԡ�
����ִ������
����ͨ������sql ����ij�λỰ��������뼶��
��δ�ύ
set session TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
�����ύ
set session TRANSACTION ISOLATION LEVEL READ COMMITTED;
���ظ���(���ݿ�Ĭ�ϼ���)
set session TRANSACTION ISOLATION LEVEL REPEATABLE READ;
������Ҫ�о��������ظ���(Repeatable Read)
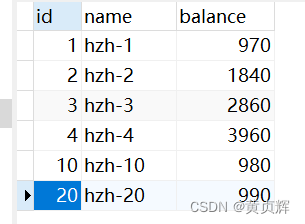
�½�һ��account������
��������������϶������������֤
ģ�������Ự
(1)��֤����: һ��session����������²��ύ,��һ��session����ͬһ����¼������,���²�ͬ��¼��������
����where �������� id,����������,Ĭ�ϼ�����
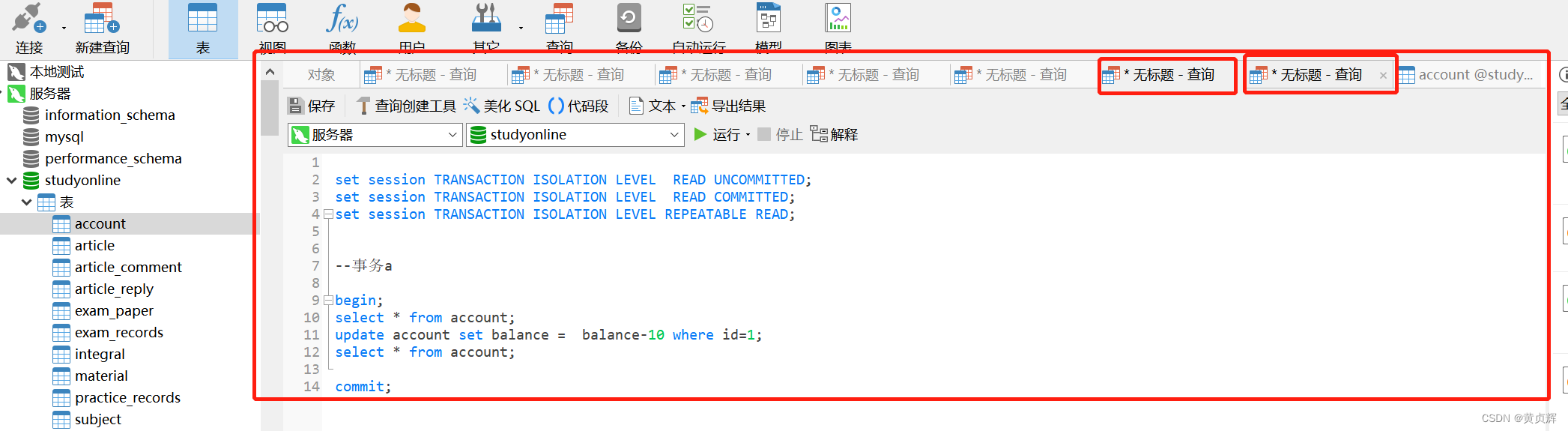
(2)��֤��������������Ϊ����:
��һ���Ǽ��������ֶ��ϵ�,���Ǽ���һ���������ϵ�,
����where ������name,����û�н���name������,����������Ϊ�Ǽ�����,������������Ϊ����,����aִ������sql
begin;
update account set balance = balance-10 where name='hzh-2' ;
��ô����סһ������,����bִ���κ�һ��д���ᱻ����,���Ǹ�name����������
(3)��֤��϶��:
����aִ��
begin;
select * from account;
update account set balance = balance-10 where id>=1 and id<=10;
�ײ�����id��Χ����,�ڱ�����commitǰ,������������,ɾ��,����idΪ1-10ʱ,����
����b��ִ����,ɾ��,����ʱ,id=1��10 �ᱻ����
begin;
insert into account values(5,'hzh-5',5000);
ע��1:������������id=1,2,3,4,10,20��6������; ������where id>=7 and id<=17;
��Ϊ7��4-10֮��,�����漰����4-10���������䶼�ǻᱻ����,����4,ͬ��10-20Ҳ�ᱻ����������ֻ��7-17�ᱻ��,����4-20��
ע��2:������������id=1,2,3,4,10,20��6������; ������where id=15;15��10-20֮��,���Լ�϶��������10-20,
��������ʹ���ɵļ�϶���ķ�Χ��һ����,Ҳ���ᷢ����ͻ,��Ϊ��϶��Ŀ����Ϊ�˷�ֹ���������������,��˼�϶�����϶��֮��������ݵġ�
�����������ݽ�ȥ
(4)��֤����1:
1������a
begin;
update account set balance = balance-10 where id=1 ;
2������b
begin;
update account set balance = balance-10 where id=2 ;
3������a
update account set balance = balance-10 where id=2 ;
4������b
update account set balance = balance-10 where id=1 ;
��������
> 1213 - Deadlock found when trying to get lock; try restarting transaction
> �Զ��ع�����һ������,��һ��������������ִ�С�
��֤��ͬ�����ȡ��϶������,������������:
����time 1,2,3,4ִ��
����a
begin;
update account set name='hzh-15' where id=15;--time1,��϶����ס��10-20
insert into account values(15,'hzh-15',1000);--time3,������b����,�ȴ�����b�ͷż�϶��
����b
begin;
update account set name='hzh-16' where id=16;--time2,��϶����ס��10-20������a�ļ�϶������,����������
insert into account values(16,'hzh-16',1000);--time4,��ȴ�����a�ͷż�϶��,��ʱ�γ�ѭ���ȴ�,������
���ظ�����1:
a �����Ȳ�ѯ����,b�����ٲ�ѯ,a������commit, b�����ٲ�ѯ��
b�����ѯ������ȫ�̲���a����Ӱ��
����1��a ����
begin;
select * from account;
update account set balance = balance-10 where id=1;
select * from account;
��ʱ��û��commit
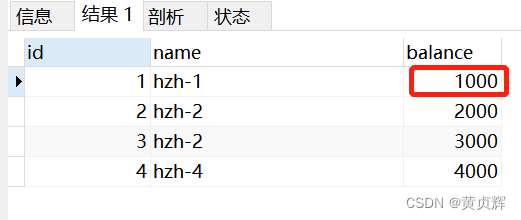
a�����ѯ���Լ��ĵ� ��һ�����ݵ� balance���990
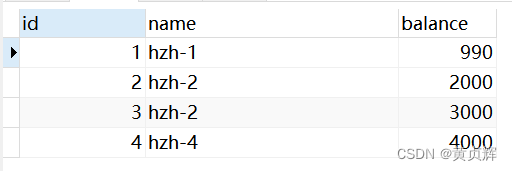
����2��b����
begin;
select * from account;
��ʱ��û��commit
b�����ѯ���ĵ�һ�����ݵ� balance����1000
��Ϊ�ǿ��ظ�������,a����û���ύ�Dz鲻����,����a�����ύҲ�鲻����
��Ϊ������뼶��Ҫ��֤b�����ζ�ȡ,�����һ����
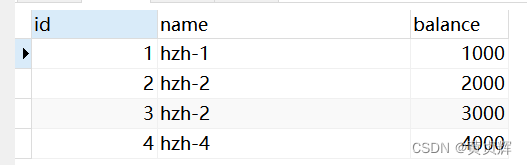
����3����������ȥ����a commit; �� select * from account;
��������ȷʵ�Ǹĺ��ˡ�
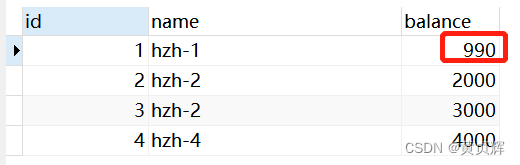
����4����ȥ����bִ�п� select * from account; ����1000;������뼶��֤��b�����ζ�ȡ,�����һ����commit֮������������ٲ�ѯ,���ܲ鵽�ˡ�
���ظ�����2:
a�����Ȳ�ѯ��,b�����ĺ��ύ,a�������IJ���ѯ���ύ
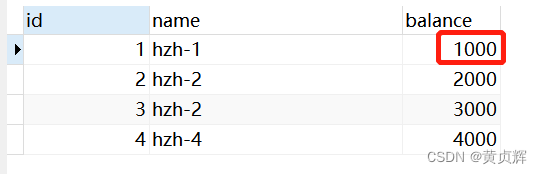
����1������a�Ȳ�ѯ
begin;
select * from account;
����2������b ִ�и��º��ύ,��ʱ���ݿ���ʵ�����Ѿ���990
begin;
select * from account;
update account set balance = balance-10 where id=1;
commit;
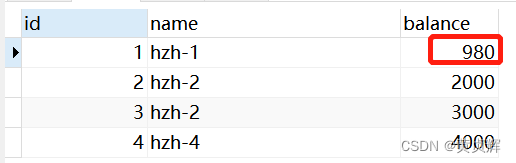
����3������a �ٲ�ѯ select * from account; ��Ȼ��1000,���Ͽ��ظ��� ��ζ�ȡ�����һ����
��������ʱִ��
update account set balance = balance-10 where id=1;
select * from account;
������?
����ȥ�������ݿ����ʵ���� 990-10=980 ����Ϊ��ʵ�����
Ҳ����˵a�����ڿ���1000ʱ��10,ֱ�ӱ��980,�����ǶԵ�,��Ϊ��ȷʵ��Ҫ������b 990�Ļ����ϼ�ȥ10=980
ֻ����ɾ��ʱ��������ݿ����ʵ����ȥ����,��ѯ�Dz���ġ�
������Ч���Ǵֿ���������Ҫ��,��ȡ����ʱ������������Ӱ��,��ɾ��ʱ��Ҫ��������������,mysql�ĵײ�����ô������������? ���� MVCC(��汾��������)������
MVCC(Multi-Version Concurrency Control ��汾��������)
���ݿ�����ص�2������ֶ� DB_TRX_ID(��������id), DB_ROLL_PTR(�ع�ָ��),ִ��beginʱ������������id,begin֮��ĵ�һ����ɾ�IJ�sql�Żᴥ��ȥ��������id,����id���������ǰ��˳���ϸ������

undo log���汾����readview������
һ��undo log(�ع���־) :����ÿ�θ���ij����¼ʱ,ԭ���ݱ�����undo log ,�������ڷ����ݿ����,������ع�ʱ,����undo log��ѯ֮ǰ�����ݡ�
�����汾��:�汾��=���ݿ����ij������+�������ݵ�undo log��
����readview:
ÿ�������ѯsqlʱ��������һ��readview,�������������:δ�ύ������id����,���ύ������id����;
��readview[101,102]103,[101,102]��δ�ύ������id����,103�����ύ������id����
ע��:��������ύ������id,��ָ�ڶ����е�,��������һ������ύ
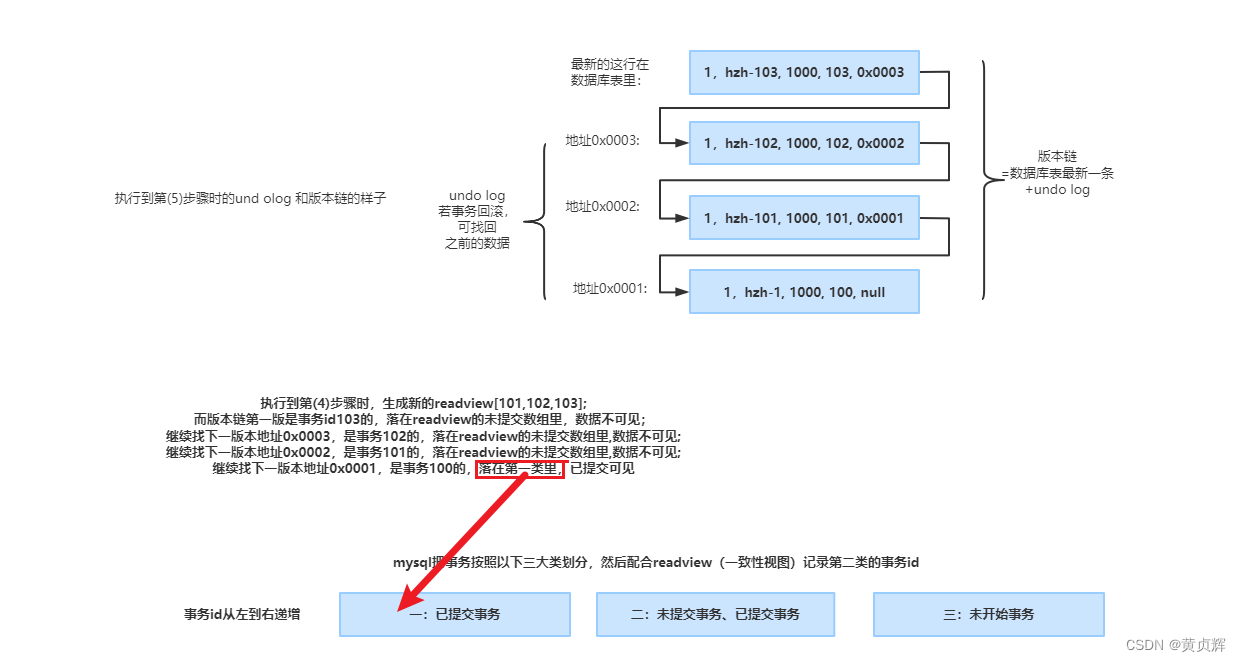
�ؼ����C�汾���ȶԹ���:���Ű汾�������������id ����readview�������ȥ�жϿɲ��ɶ�,�����ǵ�readview�Ǽ�¼�ڶ����id,���ȵڶ������Сid��С,�Ǿ����ڵ�һ�ࡣ
1�����汾����ij���汾 ����id���ڵ�һ��,���ݿɼ���
2�������ڵڶ���,���������:
(1)����id��δ�ύ����,���ݲ��ɼ�,���Լ�������ɼ�;
(2)����id�����ύ����,���ݿɼ���
3�������ڵ�����,δ��ʼ����,�϶����ɼ�;
undo log���汾����readview�����ӷ���
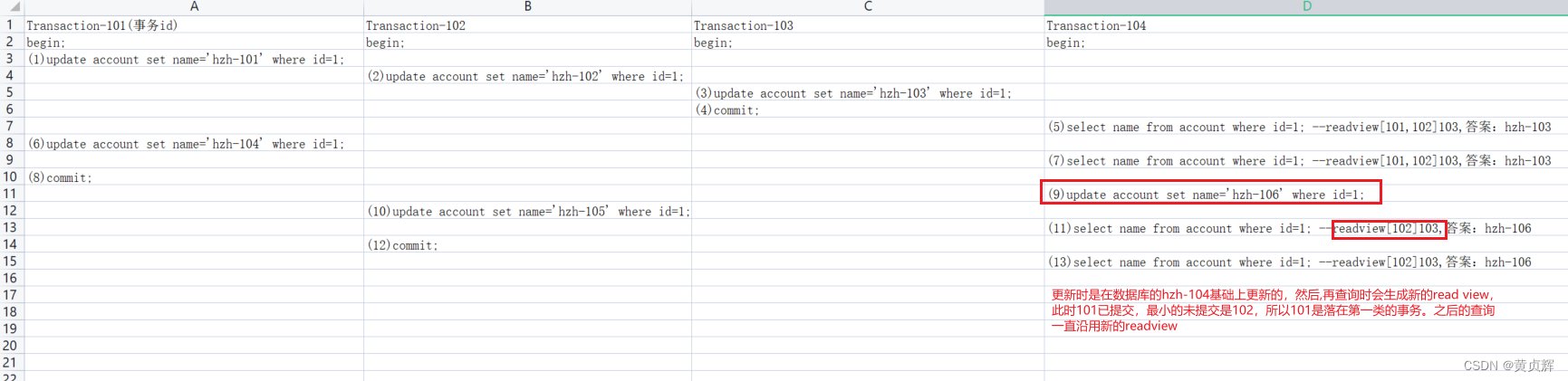
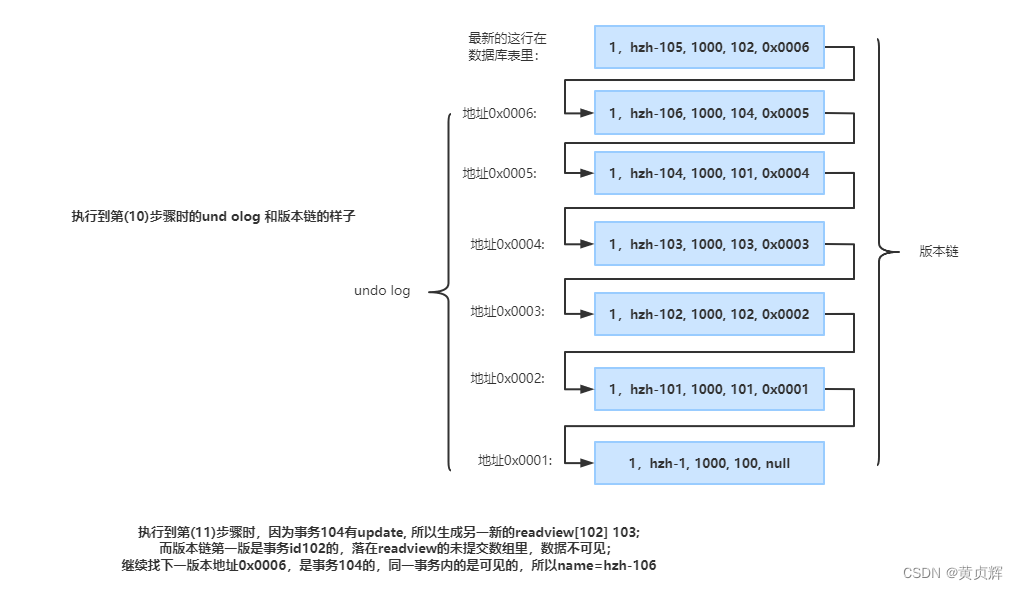
������account���ĵ�һ������Ϊ��������,�½�4������,���谴��ͼ�в���ִ�и�sql
��1:����
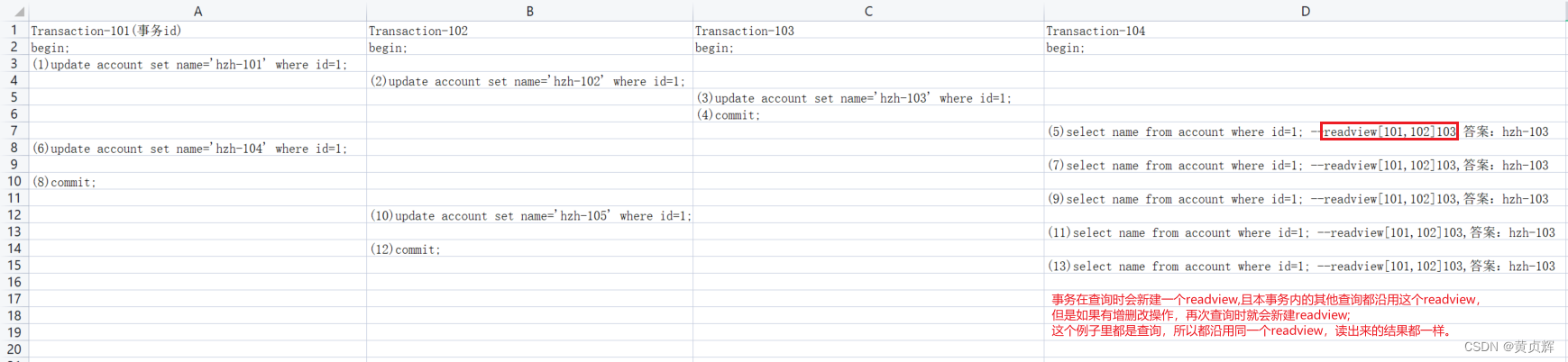
undo log�Ͱ汾���Ķ�̬�仯
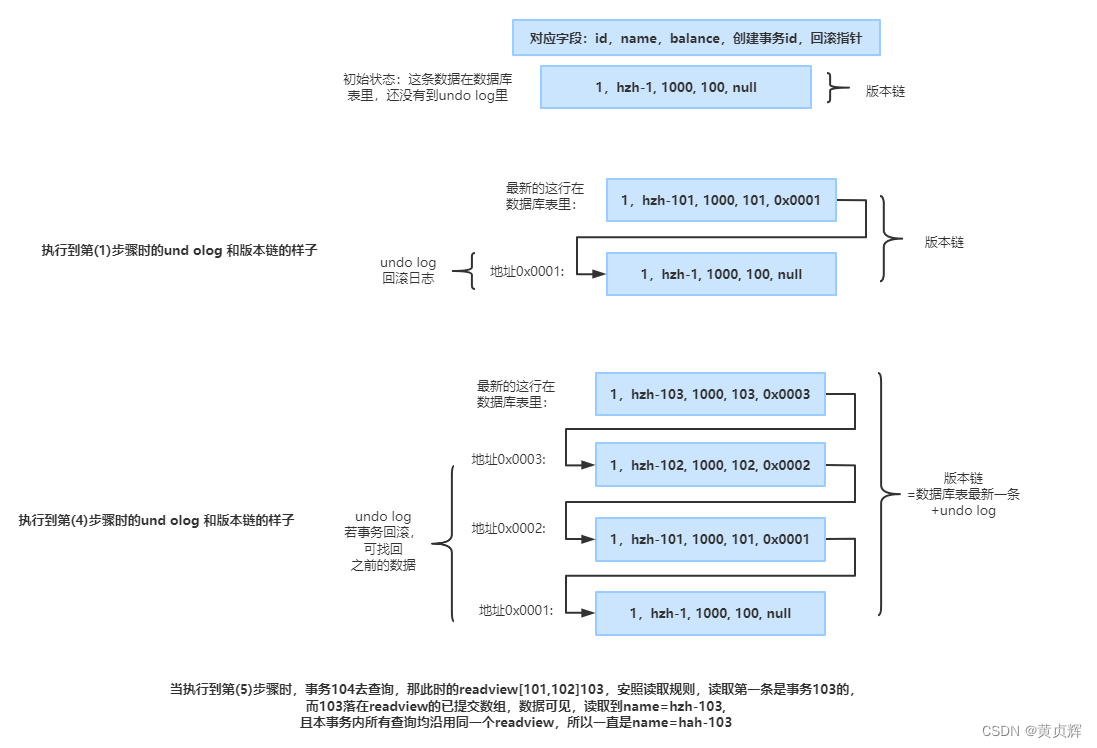
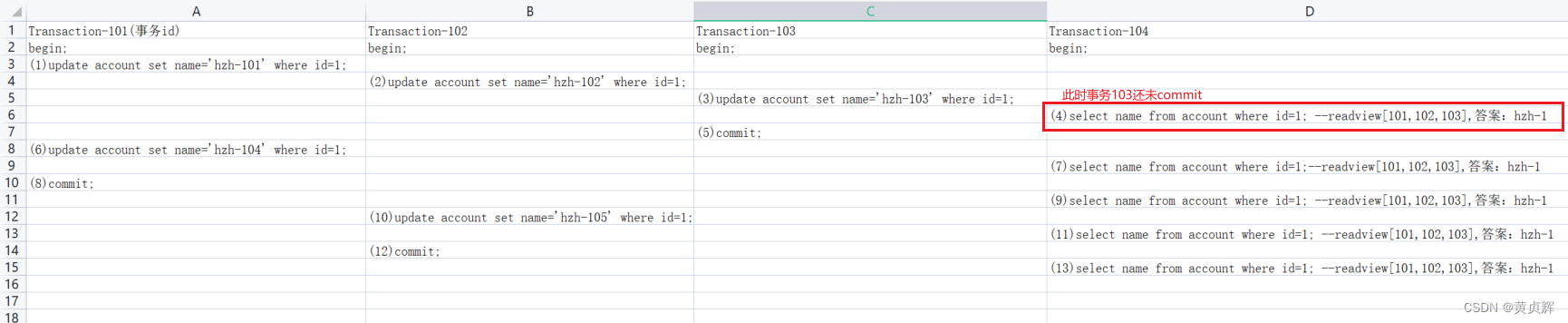
��2����:
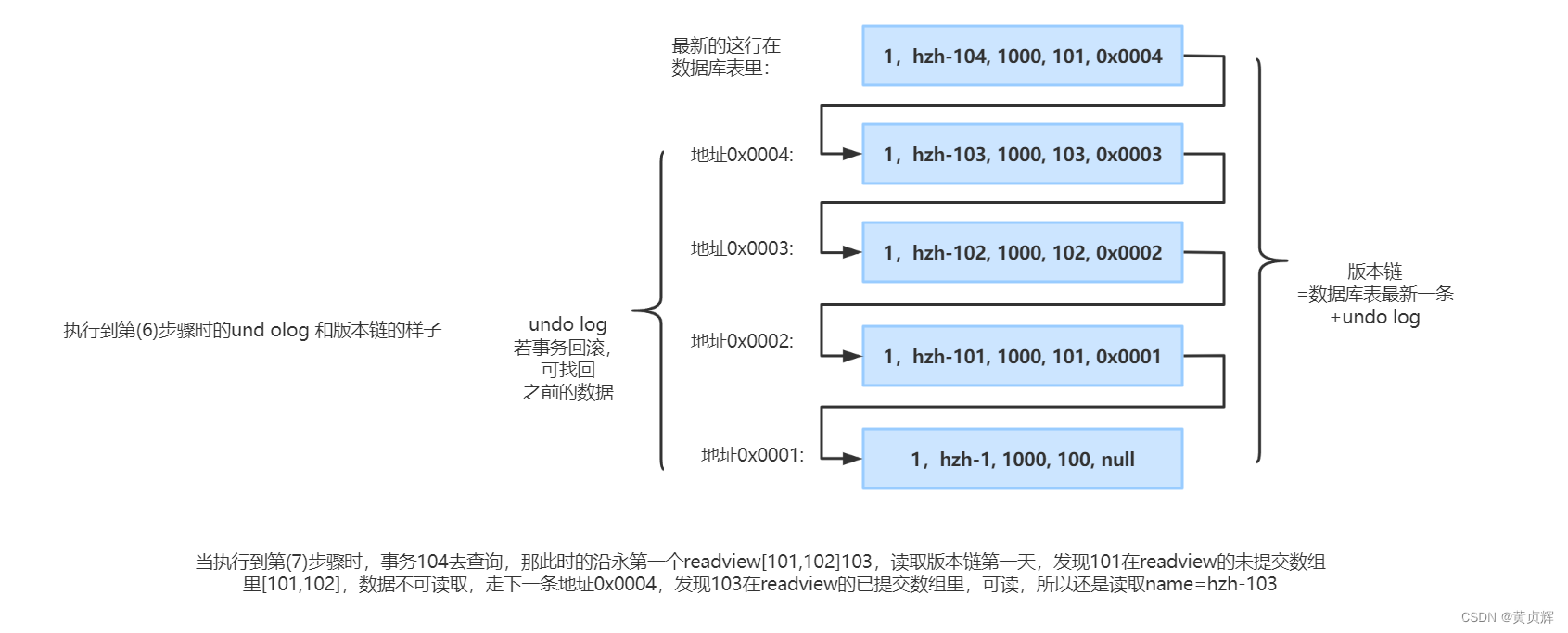
��3����:
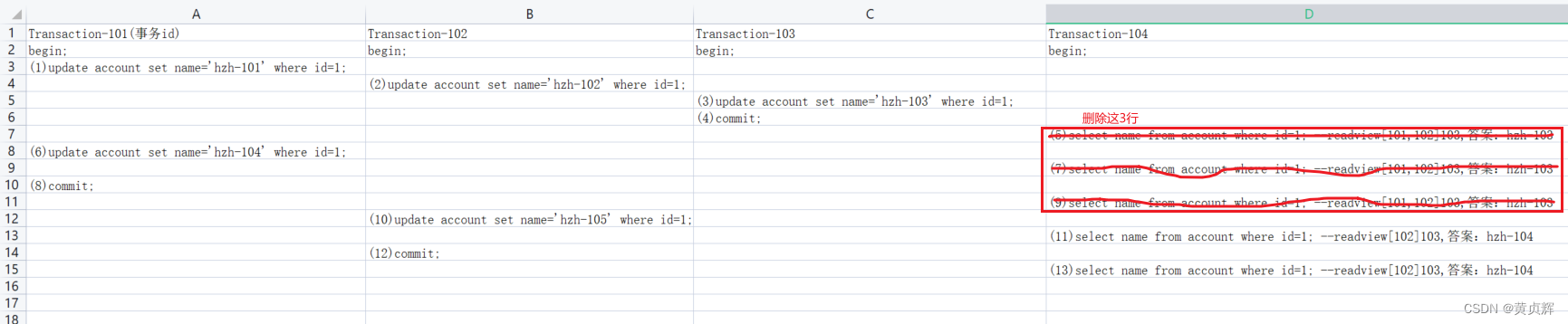
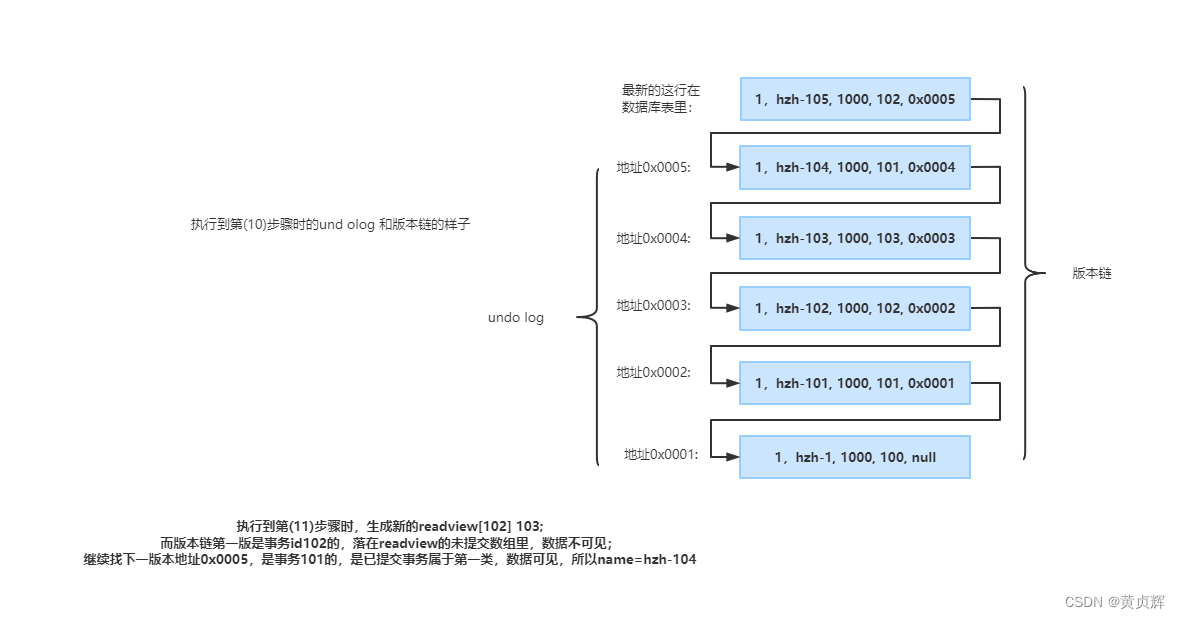
��4����:
��5����:(ɾ������)

��ʵ����ļ������Ӱ汾������deleted flag=false,ֻ��û�õ�,��ָ������
ɾ���ǰ�ԭ�ϸ��汾���ݸ���һ��,Ȼ������Լ�������id��ɾ����־Ϊtrue��
���Կ����Ǹ��µ�һ���������