��Һ�����һ�һ�,���Ľ�����ǰ�� 1w5����ϸ���ֲܷ�ʽϵͳ����Щ�������� ���»�����,����ʵ�ʵİ�������

�߿��ö��ڵ��µ�ϵͳ����,����˵��һ��Ӳָ��,����רע��ҵ��������,���ڸ߿�����ֱ�۵ĸо����ܾ�������Ӧ�ò�Ҫ������,��Ҫ����;����������,Ҳ��ò������ǵ�ҵ����������µ�,����Ƿ�������DB���м��(��ע�����ġ��������ĵ�)���쳣�Ǿ�����Ӧ��sre, dba;Ȼ�����ںӱ���,���в�ʪЬ,Ϊ�˱��Ϸ���ĸ߿���,���ǿ��Դ���Щ�������Ŭ����?
���Ľ���Ϊ�߿��õĿ�ƪ,ͨ������һЩ���õ�ϵͳ�ĸ߿��÷���,����ҽ���һ�����ǿ��Դ���Щ����Ŭ�������ǵ�ϵͳ�ﵽ�߿���,��Ҫ��Ƶ���ϵͳ����
- ����:Redis
- ���ݿ�:MySql
- ��Ϣ����:RabbitMQ
- ����: ElasticSearch
1 redis�߿��ò���
redis�㷺Ӧ���ڻ����ҵ��,��ȻҲ�н��䵱���־û��洢��nosql���ݿ�ʹ��,��Щ������Ҫ,�ص���redis���ṩ�����ʱ��,�����֧�ָ߿��õ���?
redis�ٷ�֧�������ֲ���:
- ���ݳ־û�
- ����ͬ��
- �ڱ�ģʽ
- ��Ⱥ
����������֮��,�����Լ���ʹ��ʱ������ѡ�����ҵ��ʹ�ò�ͬ��redisʵ��(����˵�еIJ������м�������һ��������)
�����������redis�ļ��ָ߿��ò��Խ��м���˵��
1.1 ���ݳ־û�
�ٷ��ֲ�: Redis persistence
�־û����ڸ߿��á�һ���Եij����о����ῴ����һ�ּ����ֶ�;
�ڸ߿��õij�����,���ݵij־û���Ҫ��Ϊ�˽���ڷ����������(��崻�)֮��,���Կ��ٻָ�����������ṩ��������;
redis�ٷ��ṩ�����ֳ־û�����
- AOF: �����µIJ��������¼�ڶ�Ӧ����־�ļ���,��������ʱ����á��طš�����,�����е���������ִ��һ����ʵ�ֳ����ָ�
- RDB: ��ʱ�洢redis�е����ݿ��յ������ļ���,��������ʱ��,����rdb�ļ�,�ָ����е�����
������AOF��¼���Dz�������,���ûط�ִ�еĻ��ƽ��лָ�;RDB���൱����������,���¶�ȡ���صĻ��ƽ��лָ�
ע:AOF RDB����һ����,û��������
1.2 ���ӷ�ʽ
��Ȼredis���ܱ�ը,���ǵ�����Ȼ��������ƿ��;��������������������ƿ����ʱ��,һ����ô��?
û��,�ӻ���
redisҲ֧�ֶ������,���糣����һ����Ӳ���:
- ����:�ṩ��д����
- �ӻ�:ֻ�ṩ��
��Ծ����������д�ٵij���,���ǿ�������redisʵ��,����һ������Ϊ��,�ṩ���е�д����;������ʵ��������Ϊ��,�ͻ���ͨ�����ز���·�ɵ���ͬ�Ĵ�redis,�Ӷ�ʵ��������̯;
ͬʱҲ��Ϊ�ж��ʵ��,���Ե�̨��̨ʵ������,����������Ŀ�����Ӱ�첢����̫��(��ʱժ�����ϻ���,������ʵ����Ȼ���������ṩ����;��Ȼǰ����������ʾ̫���������ʵ��Ҳ���,�Ǿ�gg��)
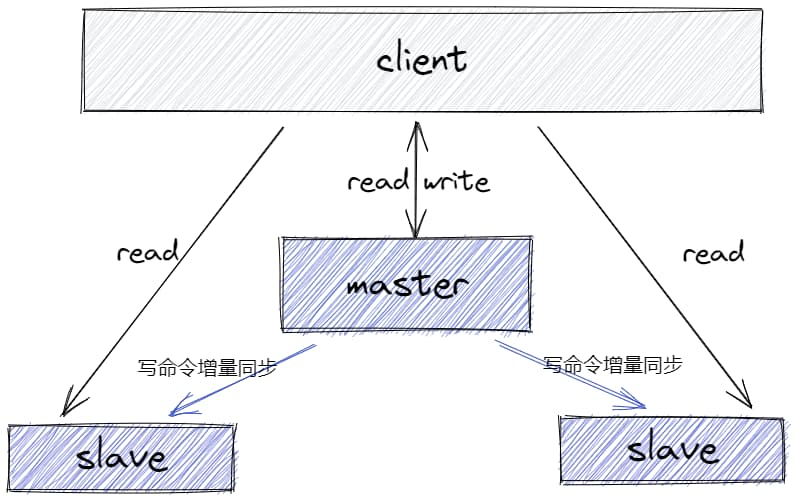
����ģʽ����һ������,�����Ӵ�ģʽ,��Ҫ��Ϊ�˽����redis��ͬ��ѹ��,�ij��� -> ��,Ȼ����һ����ͬ���������Ĵ�ʵ��,����ܹ�ͼ����
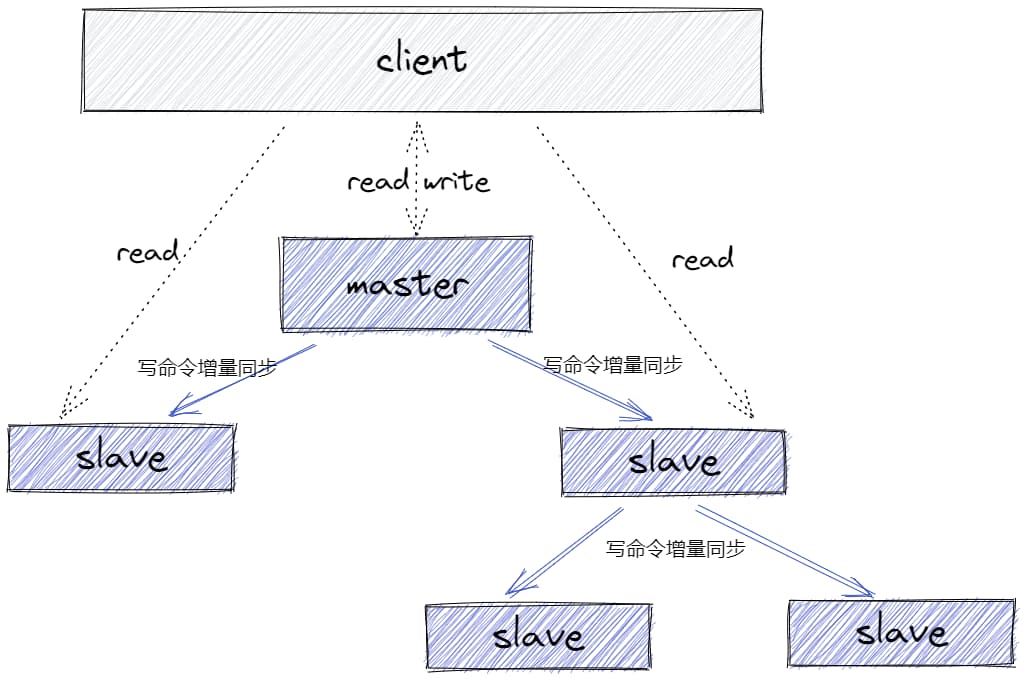
ʹ�����ӡ����Ӵ�ģʽʵ�ָ߿��ÿ����Ƿֲ�ʽϵͳ�ľ������,����Ҫ˼������:
- ��ʵ���ṩ����,ʵ�ָ��ؾ���
- ÿ��ʵ������һ��ȫ������
1.3 �ڱ�ģʽ
�ڱ�ģʽ��Ҫ��Ϊ�˽������ģʽ��,����崻��ij���,���������������ڵ���,�������ڵ�Գ��˸߿��õĹؼ�������;��ô���ʵ�����ڵ�崻�֮��,�Զ�ѡ��һ���µ����ڵ�,�������Ϳ������ϵͳ�Ŀ�������ô; redis�ٷ��ṩ�Ļ��ƾ��� - �ڱ�ģʽ
��Ҫ����ԭ��:
- �ڱ�:����redisʵ��,�ж��Ƿ���(��̫�����ṩ��������)
- ͨ�� PING ����,��������ӷ�����֮����������,��������Ӧ,����Ϊ���;������Ϊ
�������� - ��
n/2 + 1���������ڱ���Ϊ���ڵ�����,����Ϊ���ڵ�������,����ѡ�µ����ڵ� - �����дӽڵ���,ѡ����֮ǰ�������ƶ���ߵĴӽڵ���Ϊ�µ�����
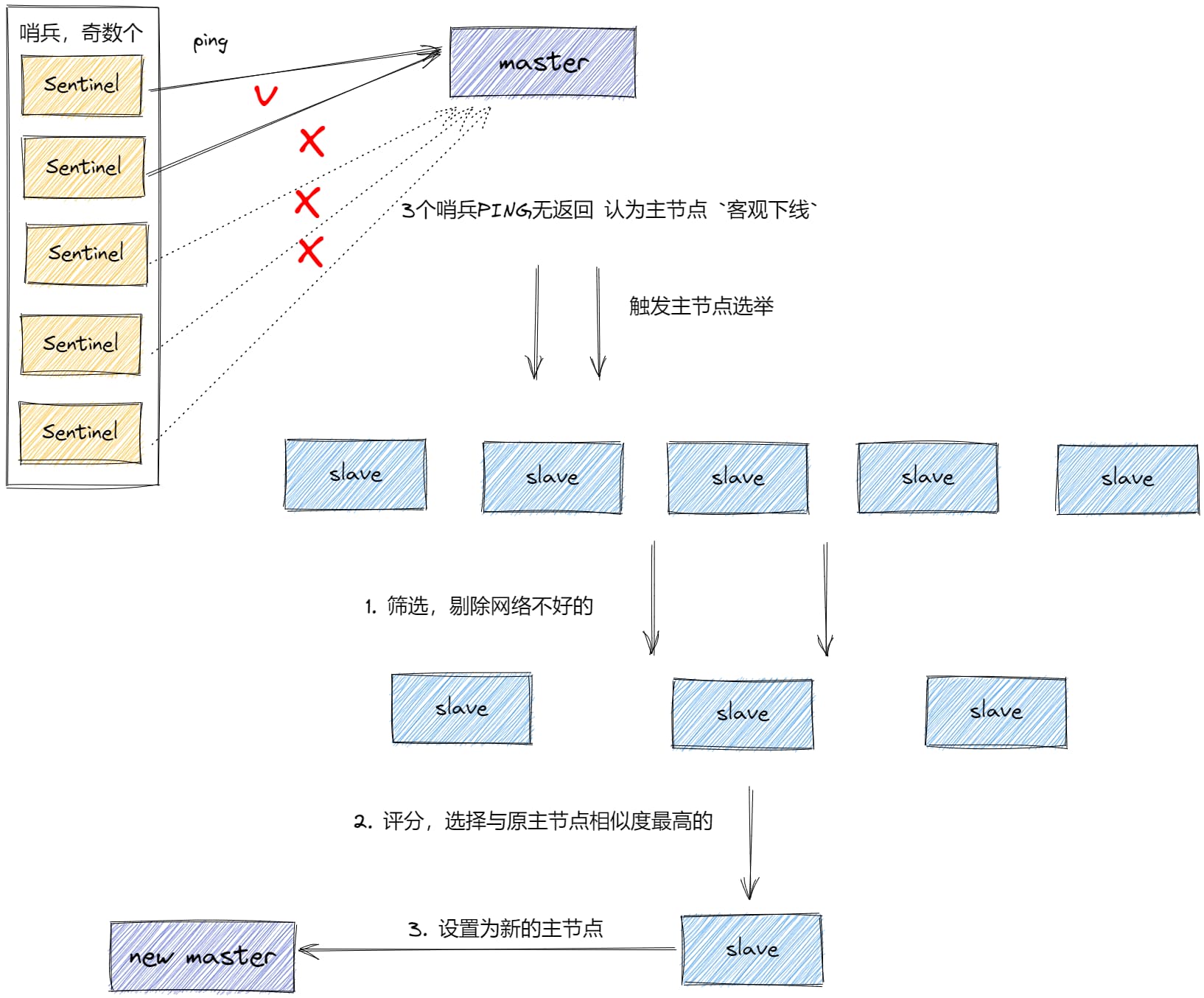
�ڱ�ģʽ,��������Ϊ̽�� + ѡ��,����Ҳ�����ڸ���ֲ�ʽϵͳ�ļ���������
1.4 ��Ⱥģʽ
�ٷ��ֲ�: Scaling with Redis Cluster
���������ģʽ��ȫ������,redis�ļ�Ⱥ�������������ݷ�Ƭ,ÿ��ʵ���ϴ洢���ֵ�����;������ȫ������,�Ӷ������������ij�����,����redis�������Լ�����ͬ����ѹ��
��Ⱥģʽ���ص����ڶ��ʵ��,������һ��ʵ��,ÿ��ʵ���ϴ洢���ֵ�����;redis��û�в���һ����hash�������ݷֲ�,����ʹ�����е�slots��ۻ���,��ʵ�����ݵ�hashӳ��
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-buMhL8yM-1659404635232)(https://hhui.top/�ֲ�ʽ/�߿���/imgs/220708/redis03.jpg)]
��Ⱥģʽ,��Ҫ�ص��������ݷ�Ƭ,ÿ��ʵ���沿������,��˼·�������
�������ͼ��Ҳ���Կ���,��Ⱥһ�������Ӵ���ʹ��,��Ⱥ�е�ÿ����Ƭ��Ӧ��������ģʽ��redis����,�Ӷ���ǿ�߿���
1.5 ��
��һ����Ҫ���ܵ���redis�ĸ߿��ò���,����Ҳ���Կ����ܶྭ��ļ�������
- �־û�:RDB�������̼��ط�ʽ + AOF��¼�����������ڻطŲ���
- ����,���Ӵ�:ȫ���������ࡢ��д�������,���ؾ����˼��;���������������ڵ�ҵ�֮����Ҫ�˹������ֶ�ָ������
- �ڱ�����:PING/PONG��̽�����,�������ڵ�,崻�֮���Զ�ѡ��,ȷ���߿���;���������������е�ʵ��������ͬ��һ������,��������ʱ���Ѻ�
- ��Ⱥ:���ݷ�Ƭ,ÿ��ʵ���ṩ���ַ�������
���������С�����Ȼ���뵽,Ϊʲôredis���ṩ��Щ��ͬ�IJ���?���Ǹ��Ե�Ӧ�ó�����ʲô,��ȱ����ɶ?��Щ���ʾͷ��ں�����redis�߿�������н���
��ز���:
2 MySql�߿��ò���
MySql���ݿ�ĸ߿��ò��ԾͱȽ϶���,ͬ��Ҳ�dz��ľ���;�������ڵ�ı�����Ծͷdz�����;�����ォ��Ҫ�����ķ���MySql�ĸ߿��üܹ����������ӡ�һ�����,���������,�������ڵ����ʱת�Ʋ�������ں�����ϸ�������н��н���
2.1 ���ݳ־û�
����ÿ�������߶���,����˵�����ݿ��ACID����,���е�D��Ӧ�ľ�������˵���ij־û�;������redis�ij־û�,��MySql��InnoDB����Ϊ��,��־û��漰�������־�ļ�(undo log,redo log,binlog),������(buffer),����(idb�ļ�)
��������һ�����������ݸ���/���������

����������һ�º���˼��:
- ���ݸ��²���:���Ǹ��»��������(����δ����,��Ӵ��̼��ص�����)
- ��дundolog��־�ļ�:��¼֮ǰ������,֧��mvcc��֧�ֻع��Ϳ���
- redolog��¼�������ύ:(����prepare,��binlogд��֮��,�ٴθ���״̬Ϊcommit)
- ����첽ˢ�»������ݵ�����
��Ȼ����������Ƚϼ�,���������֪ʶ��dz���,��
- Ϊʲô�ȸ��»���,����첽ˢ����?
- �������ڲ����ڴ���ٶ� >> ��������
- undolog������ʲô,��ô֧��mvcc,ʵ������ع���?
- ��������ԭ���ԵĹؼ�����,�����з��������ʱ,��¼��ǰ�����ݵ�undolog,��ָ����,����sql�����undolog�еĸ������ݴӶ�֧��mvcc,�ع�ʱ���Ǹ���undo log�������ָ�
- redolog������ʲô,Ϊʲô���η���?
- ��Ҫ��������ij־���,�����ݿ��쳣崻�֮��,����ͨ������ִ��redo log���ָ�δ��ʱ���̵�����;���ε���ҪĿ����Ϊ�˽��redolog��binlog��һ��������,�������redolog��һ�γɹ�,����binlogʧ�ܵ��²�һ������
- redolog����innodb����,�̶���С,���νṹ����д����;�ڲ�ͬ������д����,��ˢ���̵IJ���
������������,���浽mysql��ר��ʱ����ϸ����
2.2 �����ܹ�
��֤�߿��õ�һ������Ծ��ǡ����ࡱ,Ҳ������������˵���������ܹ�,��mysql����,��������������ʵ��;һ����������ṩ��д����,һ������,���������������������,���������ṩ����;
������gg֮��,Ȼ������,�л�Ϊ����
��˵���˼��Ŵ��Ĵ����Ʒdz�����,ƽʱ���ǻʵ����쳯��,̫�Ӿ͵�������;�ʵۼݱ�֮��,̫�Ӿͽ���Ϊ�ʵ�(�۱�̥����Ҫ��)

����������ص���Ƕ౸һ̨ʵ��,�ڳ�����ʱ����,��Ȼȱ��ͺ�������,���ص���Դ�˷�
2.3 ���Ӽܹ�
���Ӻ�ǰ��mysql��˼·���,����ģʽһ���ֽ�����д����,��д����,���ӿ�;�������������,����Ҫ��ͻ�Ƶ���������һ��mysqlʵ������ɷ���,�����������е�������

���ӵĺ���˼�����ڶ�д����
2.4 һ�����
��ǰ�����ӵĻ����϶�Ҽ����ӿ�,��Ҫ���������ڵ�ǰ�Ļ�����������,���������Ӧ�ö��Ƕ���д��,ͨ���Ҷ���ӿ�,������Ч�ṩ������������ָ��
ͬ��һ����ӵ�ģʽ,Ҳ������Ϊ���� + ���Ӵ�����,��������Ҫ��Ϊ�˼��������ͬ��ѹ��,��ͼΪ����4�ܹ�ģ��
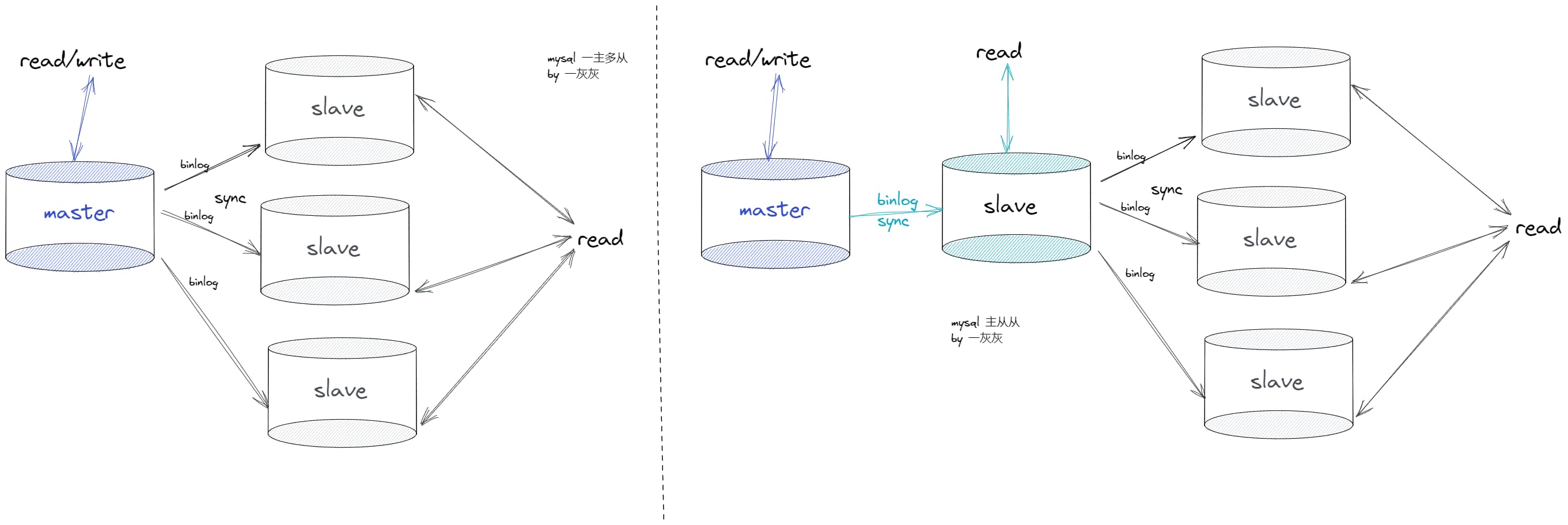
2.5 �������
һ����ӿ��Խ������д�ٵij���,���ܻ����дƿ���ij���;�ڲ����Ƿֿ�ֱ���ҵ���ֶ�֮ǰ(���ַ�ʽҲ��������Ϊ���ݷ�Ƭ,��������˵����redis��Ⱥģʽ),������mysql�ļܹ�ģʽ����,��Ȼ���뵽�IJ��Ծ��Ƕ�������ṩд����,���������˵�Ķ�����ӵļܹ���

�������,����ÿ�����ⶼ���Զ��������ṩд����;�ӿ�������ṩ������
��Ҫע���������֮�������ͬ��,��һ��д�����䵽һ������һ������֮��,���е����ⶼ��ͬ�����д����
2.6 �����л����ԡ�����ͬ������
ǰ����ܵ��Ǽ��ֲ�ͬ�����Ӽܹ��ص�,��Ҫͨ��������/��������ʵ������߿�����;���ǻ��������dz���Ҫ�ĵ�û��ϸ˵,һ���ǹ���֮��,���ȷ���µ�����;����һ����������/����֮����������ͬ��,��α�֤���ݵ�һ����;
���������ǽ��Ľ�����mysql�г�����һЩ����(����ϸ�ĵ�Ȼ���ں����ר��)
���������
VIP + KeepAlived
- vip: ��virtual ip����ip
- KeepAlived: ����ű�
����Ҫ˼·�����ⲿͨ��VIP����mysqlʵ��(����/����),��KeepAlived���ڼ�������Ƿ���,���ҵ�֮��,VIPƫ�Ƶ�����һ������(����ѡһ���ӿ���Ϊ����)��,�Ӷ�ʵ���Զ�����������
ȱ��:
- ��������(��->��->�����ָ���ģʽ������������)����һ��������л�֮��,������ʵ����Ҫ����������������
MHA
Master High Avaliable ����߿��û���,Ҳ�ǵ��ºܶ˾���õIJ���;�����һ�������Ĺ���,�ڼ����ⲻ���ú�,���Զ���ͬ������ӽ������slave����Ϊmaster,Ȼ��������slaveָ���µ�master
���ŵ�dz�����,ͨ������ʵ��ʮ���ڵ������л�,��չMySql�ڵ�Ҳ�dz�����;��ȱ����������Ҫ�������
MXC
PXC(Percona XtraDB Cluster)��һ����ȫ��Դ�� MySQL �߿��ý������������ Percona Server��Percona XtraBackup �� Galera �⼯����һ��,��ʵ�ֶ������Ƶ� MySQL ��Ⱥ
������ص�����д������Զ�ͬ���������ڵ�,Ҫ�������еĽڵ㶼��֤֮��Ż��ύ,��֤���ݵ�ǿһ����
���ȱ�������ľͰЧӦ,����ȡ���������Ǹ��ڵ�
MGR/InnoDB Cluste
MySQL 5.7 �Ƴ��� MGR(MySQL Group Replication),�� PXC ����,Ҳʵ���˶�ڵ�����д���ǿһ���Ե��ص㡣MGR ���� GCS(Group Communication System)Э��ͬ������,GCS �ɱ�֤��Ϣ��ԭ����
�ⲿ����ͨ�� MySql router��һ��mysqlʵ�����н���,�������л�ʱ,mysql router���Զ��л����µ����ڵ�
Xenon
����RaftЭ���MySql�߿��ú����Թ�������,�����Ļ�ѡ��,֧���뼶�л�
����ͬ������
���������ӿ�ʱ,��Ȼ�����ͬ������,��α���������ӿ����ݵ�һ������?
����ͬ������
����ͬ����Ҫ����Binlog��ʵ��,�����ǰ���ͼ���м�����,�����������������ͬ������
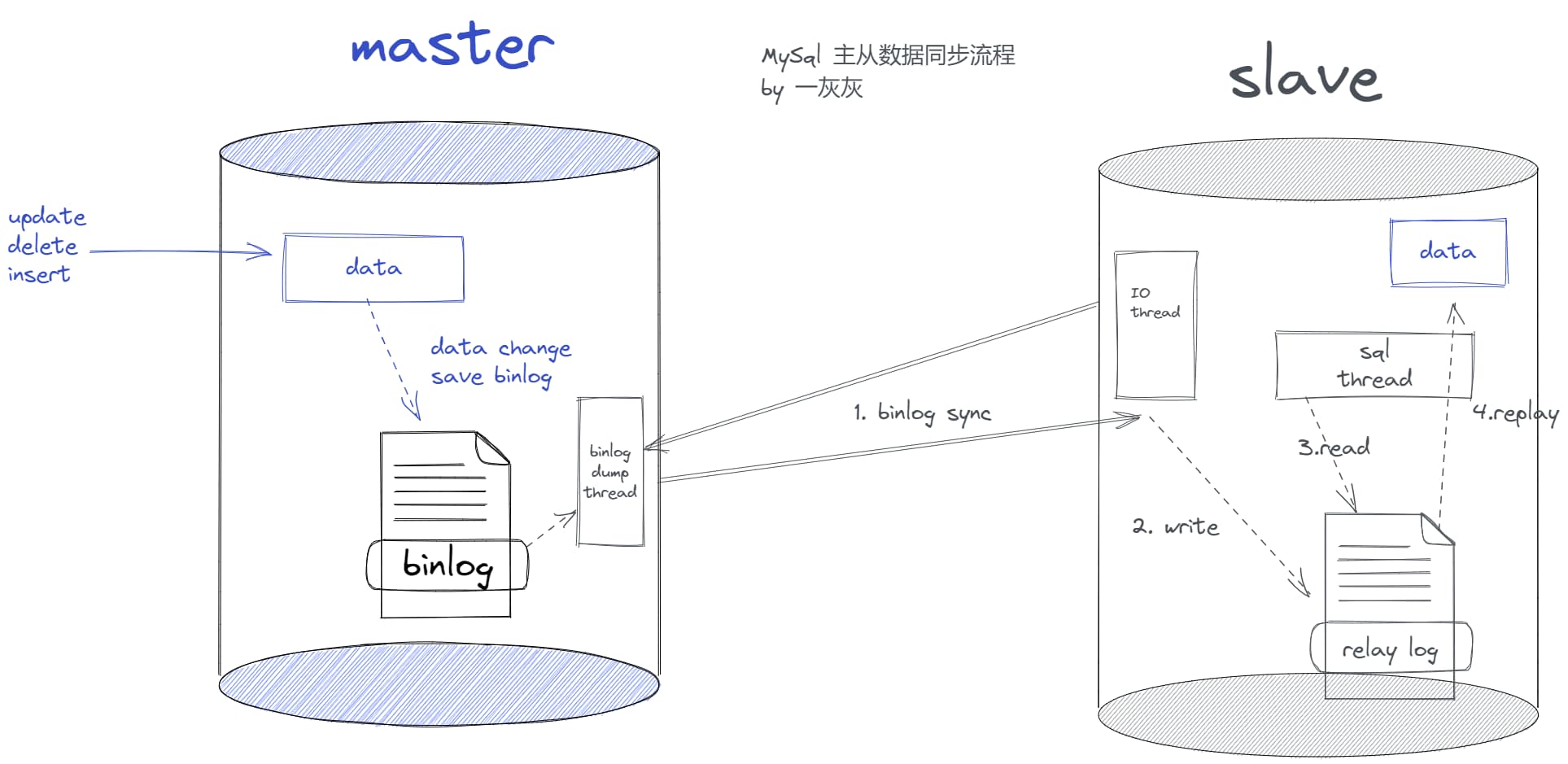
- ��������binlog��־�ļ�
- statement:��¼��������Ķ��IJ������,����insert xxxxx,ȱ����ijЩ�����ᵼ�����ݲ�һ��(��now())
- row:���������е�,ԭ����������xxֵ��Ϊ��yy ֵ,ȱ������������
- mixed: ������������
- �ӿ��io�߳��������binlog��־,д���Լ���relaylog(�м���־),Ȼ����sql�̶߳�ȡrelaylog��־���лط�,ʵ������ͬ��
����ͬ������
ʹ������֮��,��ʵ�ʵ�ҵ����,���������������������ӳ�,�����������Ѿ�д����,���Ƕ��ӿ�ȴ��������Ӧ������,������������ӳ���,��ֱ�ӵ������ݵIJ�һ��;��Ȼһ������Ӱ�컹��,���������Ϊ�����ӳ�,�����������,���еĴӿⶼû�����µļ�¼,�ⲻ�͵������ݶ�ʧ��ô,�ᵼ�����ص�����һ��������
����������ͬ���IJ�����,�����漸��
case1:�첽����
�������д����֮��,���ⷵ�ؽ��,�������Ĵӿ��Ƿ�ͬ�����մ���,��ʱ�Ϳ��ܳ�������˵��,�������֮��,���дӿ����δͬ��������,�������ݶ�ʧ
case2:��ͬ������
Ϊ�˱���������������,����Ҫ��������һ���ӿ�ͬ����֮��,����Ӧ�û�������,������������崻�֮���и�����
case3:ȫͬ������
���������һ��,Ҫ�����еĴӿⶼͬ����,����������ok,��֤ǿһ����,ȱ�����������ܻ��ܵ�Ӱ��
2.7 ��
��һС����Ҫ���ܵ���MySql�ĸ߿��ò���,�Ӽܹ��������,������,����,һ�����,�������,ͬʱҲ�Ľ����������ʵ��������Զ��л�(MHA,MXC,MGR��)����������ͬ������,ͬ������;������˽����ϸ������,���Ʋ���mysql�ĸ߿���ר��
����С��һ�±��ָ߿��õ���Ҫ˼·
- ͨ��������ʵ�ָ߿���:������
- ��д����,ʵ�ָ��ؾ���:���ӡ����Ӵ�ģʽ
- ���ݳ־û�����:�����ڴ�(buffer),�첽ˢ��,�����ύ����һ����
��ز���:
- �ٷ��ĵ� InnoDB Cluster
- ����㶮MySQL�־û��ͻع�(ͼ�����)-mysql�̳�
- MySQL ���ø߿��÷���
- MySQL�߿���֮PXC���_��ʵ���ѽ�IJ���-CSDN����_pxc
- һ�Ŀ���MySQL���첽���ơ�ȫͬ���������ͬ������
3. RabbitMq�߿��÷���
��Ϣ�м��Ҳ�Ǵ�һ����ٻ�Ӵ���һ��ϵͳ,����������RabbitMq����һ�����ĸ߿��������ʵ�ֵ�
3.1 ���ݳ־û�
��ͬ��ǰ��MySql��Ȼ��־û�,RabbitMq�����ݳ־û��ǿ�ѡ��,�����Ƕ����ݵ�������Ҫ���ʱ,��ÿ����־û�
���ȼ�һ��rabbitmq��ģ��

��������˵�ij־û���Ҫָ
- exchange�־û�: ��exchange����������Ϊrabbitmq崻�����ɾ��,��Ҫ�ֶ�ָ��durable=true
- topic�־û�:������ͨ��topic��exchange�ж�ȡ��Ϣ,��Ҫָ��durable=true,�������崻�������е���Ϣ��ʧ
- msg��Ϣ�־û�:��������Ͷ�ݵ�echange����Ϣ,��Ҫ�־û�������
ע��rabbitmq����Ϣ�־û�Ҳ����д��buffer,Ȼ���ٶ�ʱˢ�µ�����;
������Ϊ�˱������ݵ�������ʱ,һ��Ὺ����Ϣ��ȷ�ϻ���/�������,ÿ��Ͷ�ݵȵ�mq�ظ�һ��ȷ��ack֮��,�ű�ʾ������Ͷ�ݳɹ�,��mq��Ӧ����������Ϣ�ij־û�֮�����
3.2 ����ģʽ
ͬǰ���MySql������,���ڵ��ṩ��д,���ڵ�ͬ�����ڵ������,�������ṩ��������;�����ڵ����֮��,���ñ��ڵ�������,ԭ���ڵ�ָ�֮������Ϊ���ڵ����
3.3 ShovelԶ��ģʽ
�ٷ��ĵ�: * Shovel Plugin �� RabbitMQ
Զ��ģʽ����ʵ��˫���һ��ģʽ,��� shovel ģʽ,��ν�� shovel ���ǰ���Ϣ���в�ͬ�������ĵĸ��ƹ���,���Կ����������� MQ ��Ⱥ����,Զ����ͨ�ź��ơ�
- Shovel �������ǿ�����Ϣ�����������ĵĸ��ƹ���,���ǿ��Կ����������� MQ ��Ⱥ������
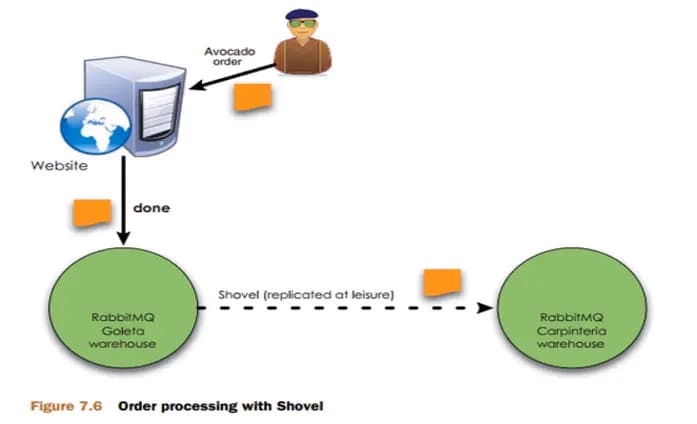
����ͼ,��������ص� MQ ��Ⱥ(�����Ǹ���ļ�Ⱥ),���û��ڵ��� 1 �����µ���,ϵͳ����Ϣ�� 1 ���� MQ ������,���� MQ �����ѳ����趨����ֵ,���ع���,������Ϣ�ͻᱻת�� ���� 2 �� MQ ��������,�� 2 ����ȥִ�к����ҵ����,�൱�ڷ�̯���ǵķ���ѹ����
3.4 ����ģʽ
����ͼ,�� KeepAlived ���� HA-Proxy �ĸ߿���,Ȼ���� 3 ���ڵ�� MQ ����,��Ϣ���͵����ڵ���,���ڵ�ͨ�� mirror ���а�����ͬ���������� MQ �ڵ�,������ʵ����߿ɿ�

����ģʽ����Ҫ�ص�����ÿ��mqʵ��������һ�����������ݾ���,�ڲ���һ��masterѡ���㷨,ͨ��VIP�����ṩ����
- consumer,��������һ���ڵ�,�����ϵIJ���master,�����ת����master,Ϊ�˱�֤��Ϣ�Ŀɿ���,consumer�ظ�ack��master��,masterɾ����Ϣ���㲥���е�slaverȥɾ����
- publisher ,��������һ���ڵ�,�����ϵIJ���master,��ת����master,��master�洢��ת����������slaver�洢��
���master�ҵ�,���slaver��ѡ����Ϣ�������Ϊmaster,
3.5 ��ͨ��Ⱥģʽ
exchange,buindling�����еĽڵ��϶��ᱣ��һ��,����queueֻ��洢�����е�һ���ڵ���,�������еĽڵ㶼��洢һ��queue��meta��Ϣ
������������ӵ�������һ���ڵ�,�������Ϣת�����洢�ö��еĽڵ��ϡ���������������˷Ǵ洢���еĽڵ�ȡ����,��Ӵ洢��Ϣ�Ľڵ���ȡ���ݡ�
������ص�����:
- ���ݲ�ִ洢,������Ϣ�Ľڵ����,��ֻ�ܵȴ����ָ�֮�������������
3.6 ���ģʽ
���ģʽ�ҵ�����Ҳ�������,������������������ժ¼,�����浽rabbitmqר��֮����к��һ������
rabbitMQ ����ܹ�����˫����ģʽ(������),��ô������(�����)�������ĸ�����һ�� rabbitMQ ��Ⱥ,�����ĵ�rabbitMQ ���������ҪΪҵ���ṩ��������Ϣ������,����֮�仹��Ҫʵ�ֲ��ֶ�����Ϣ����

federation �����һ������Ҫ���� cluster ,���� brokers ֮�䴫����Ϣ�ĸ����ܲ��,federation ��������� brokers ���� cluster ֮�䴫����Ϣ,���ӵ�˫������ʹ�ò�ͬ�� users �� virtual hosts,˫��Ҳ����ʹ�ò�ͬ�汾�� rabbitMQ �� erlang��
federation ���ʹ�� AMQP Э��ͨ��,���Խ��ܲ������Ĵ��䡣federation ���ǽ����ڼ�Ⱥ�ϵ�,���ǽ����ڵ����ڵ��ϵ�,��ͼ�ϻ�ɫ�� rabbit node 3 ��������ɫ�� node1��node2��node3 �е�����һ������ federation �����������ͬ����
3.7 ��
rabbitmq�ĸ߿��û��Ƶķ���Ҳ�ȽϺ�����
- ����ģʽ
- ����ģʽ:ȫ������һ������,�������ṩ����,����ʵ���Զ�����
- ��ͨ��Ⱥģʽ:���ݲ�ֵ���Ⱥ��ʵ����,consumer/publisher���ӵ�ʵ��֮��,��Ӿ������exchange/topic��ʵ����������
- Զ��ģʽ:�����ڶ����ĵij���,����Ϣת�����������ĵ�ʵ��
������õĸ߿���˼·Ҳ����������ļ���:�־û� + �������� + ���
��ز���:
4. ElasticSearch�߿��÷���
�����������ٿ�һ�����ڷdz����еķֲ�ʽ��������ElasticSearch����α�֤�߿��õ�
4.1 ��Ⱥ
Elasticsearch ��һ���ֲ�ʽ��RESTful �������������ݷ�������
by ��������
����es����,ͨ�����Ǽ�Ⱥ��ʽ�����ṩ����,ÿ����һ��ʵ������һ���ڵ�(Node),ÿ���ڵ�ᶨ��һ���ڵ���(Node Name),��Ⱥ��(Cluster Name),��ͬ��Ⱥ���Ľڵ�ṹ��Ϊһ����Ⱥ;

��ͼ������es��Ⱥ�ĺ���Ҫ��:
- ÿ���ڵ������Ⱥ�� + �ڵ�����������,��ͬ��Ⱥ���Ľڵ����һ����Ⱥ��
- �ڵ�����֮��,��ʼPING�����ڵ�(�����Ϻ��õ���Ӧ�ڵ����ڼ�Ⱥ��������Ϣ)
- �ڵ㷢����Ҫ��Zen Discover��ʵ��,ѡ��Ҳ�ǿ�����ʵ��
ѡ����Ҫ��������

- ѡ��ͬ��Ҳ������Zen Discover��ʵ��
- ÿ���ڵ��ϱ��Լ���������ڵ�,Ȼ��Ʊ�����ľ������ڵ�;Ʊ����ͬ�������,����ID����,ѡ��һ��
�������es��Ⱥ�Ĺ��������ڵ��ѡ�ٹ���;es֧������ڵ���Ŀ�ļ�Ⱥ(1- N),����ȫ����ͶƱ�Ļ�����ѡ��,����ͨ��һ������
ֻҪ���еĽڵ㶼��ѭͬ���Ĺ���,�õ�����Ϣ���ǶԵȵ�,ѡ���������ڵ�϶���һ�µġ�
���ֲ�ʽϵͳ������ͳ�����Ϣ���Եȵ����,��ʱ������׳�������(Split-Brain)�����⡣
��������������������һ�� Quorum ֵ,Ҫ����ýڵ������� Quorum(һ���dz��������ڵ�),���ܶ����ṩ���� Elasticsearch ��,��� Quorum �����þ��� discovery.zen.minimum_master_nodes,����ѡ���ڵ��ĸ��������������ֵʱ,��ʼѡ��,ѡ�����֮������ṩ����
ES��Ϊ�ֲ�ʽ����ʵʱ����ϵͳ,��Ȼ֧�ּ�Ⱥ�ķ�������,ͨ��Zen Discover��ʵ�ֽڵ�ͨ�š���Ⱥ������ѡ��
4.2 ��������
�����ᵽ������,��������һ��ES����ν�����������
����:�����������Ⱥ�����������,����������Ⱥ���ֶ��master�ڵ�,���������������
es�Խڵ�����˽�ɫ����
- ���ݽڵ�:�������ݵĴ洢����صIJ���(CURD,�ۺ�)��,��˶Ի�������Ҫ��ϸ�
- ��ѡ���ڵ�:ӵ��ѡ��Ȩ�ͱ�ѡ��Ȩ,���ڵ��ں�ѡ���ڵ�����ѡ����,����������ɾ��������������Щ�ڵ���Ⱥ����һ����,��������Щ��Ƭ�������Щ�Ľڵ㡢�ټ�Ⱥ�нڵ��״̬��
һ���ڵ�,���Լ������ݽڵ�,���Ǻ�ѡ���ڵ�,����ע���������ߵĶ�λ,���ڵ�Ի�������Ҫ��û�����ݽڵ��,��һ̨�����������ݽڵ��������ڵ�ʱ,���ܳ��ֳ���ʱ������Դ�����������ڵ�����쳣;
ͨ�����Ƽ��ķ�����ʹ�����ܵ�һ�����Ϊ��ѡ���ڵ�,���ܸߵ���Ϊ���ݽڵ�

�������������ѳ��ֵ����
- ��������,���·���:�����ֽڵ����Ӳ������ڵ�,��Ϊ������,Ȼ��ѡ�ٳ��ֵ����ڵ�
- ���ڵ㸺�ء���Ӧ�ӳ�:���ڵ����ڸ��ع��ߡ�������Ӧ��ʱ,��������ѡ���µ����ڵ�
�������:
- �ʵ�����ping timeout��Ӧʱ��,������Ϊ���硢���ڵ���������µ�ѡ��
- ��������ѡ�ٽڵ������ں�ѡ���ڵ�İ���,����ֻҪ�а������ϵĺ�ѡ�ڵ���,�����ѡ�ٳ�һ�����ڵ�;�������ýڵ���С�ڰ���ʱ,������ѡ��,��Ⱥ��ʹ��,Ҳ�������״̬�쳣�����
- ��ɫ����:���ݽڵ� + ��ѡ���ڵ㲻����һ̨������;
�������ڵ��ϵͳ��,һ�㶼��Ҫ������������,�����IJ�������:
- �����ڵ����ϵ�ͶƱ������Ч
- es�����ṩ�˽ڵ�Ľ�ɫ��λ,���ݽڵ�ͺ�ѡ���ڵ�,����ֻ�к�ѡ���ڵ����ѡ��Ȩ�ͱ�ѡ��Ȩ,�ṩһ�ֽ�ɫ����Ŀ�ѡ����,���������ڵ㱻�������ݷ���Ӱ��
4.3 ���ݷ�Ƭ
������������ʱ,es֧���Զ����,��һ��������������ˮƽ��ֵ���ͬ�����ݿ�C��Ƭ(Shards),Ϊ���ṩ������,ÿ�������ڶ���ʱ���˷�Ƭ֮��,���ᶨ�帱������,����ĸ�����������Ϊ��������,���и����ͷ�Ƭ��Ȼ����һ���ڵ���,�����ڵ��쳣ʱ,���������ṩ���ݲ�ѯ����
esĬ���ڴ�������ʱ,��Ƭ��Ϊ5,ÿ����Ƭ��Ӧһ������

ESͨ����Ƭ,����������ˮƽ���,��Ƭ��Խ��,ÿ����Ƭ�ϵ���������Խ��;���������Ƕ�Ӧ��ÿ����Ƭ������,��������Ϊ����,����Խ��,������Խ��
����С˵��
- ��Ӧ�����ĸ���,����ķ�ƬҲ��������Ƭ
- ��һ������д��/���µ���Ƭʱ,ֻ�����еĸ������������֮��,�������(����MySql��ȫͬ��)
4.4 ���ݳ־û�
�����˵һ��es�ij־û�����,��ǰ����˵�־û���ͬ,es��������Ҫ���˽�����Ļ�������,����������Ҫ���浽����Ƭ��,��������,��������һ������������
����Ƭ���ݸ�������

����һ�����������
- �������������һ��es�ڵ�(����ڵ����Э���ڵ�),Ȼ��ͨ��·���㷨,ȷ�����ݶ�Ӧ������Ƭ
- д���ݵ�����Ƭ,Ȼ��ͬ��������(�������ʱ���ò���ͬ��,�ֹ�������)
- ���и���ͬ�����֮��,����Ƭ�ڵ����Э���ڵ����ս��,Ȼ��Э���ڵ���ߵ�������Ӧ
������д�뵽����Ƭ��֮��,�������ٿ�һ���������ʱ���ˢ�µ������ϵ�
�ֶδ洢
�����ĵ��Զε���ʽ�洢����,��һ�������ļ��Ữ��Ϊ�ܶ�����ļ�,��������ļ����Ƕ�
ÿһ���α�������һ����������,���Ҷξ��в�����,һ�����������ݱ�д��Ӳ��,�Ͳ�������;�α�д�뵽���̺������һ���ύ��,�ύ����һ��������¼�����ύ�����Ϣ���ļ�
�ε�����,�����漸���е�
- �ֶδ洢,������Ч�����дʱ����������
- ������,����ֻ�����Ը�Ч����,���迼�Ǹ���
- һ����һ��ӵ�����ύ��,��˵�������ֻ�ж���Ȩ��,ʧȥ��д��Ȩ�ޡ��෴,�������ڴ���ʱ,��ֻ��д��Ȩ��,�����߱������ݵ�Ȩ��,��ζ�Ų��ܱ�����
���ڶβ��ɱ�,�����ڸ���ʱ��Ҫ�����
- ����:��ǰ�ĵ�����һ����
- ɾ��:����һ��.del�ļ�,��¼��ɾ�����ĵ���Ϣ;�����ɾ�����ĵ���Ȼ���Ա�������,ֻ�����շ���ʱ���Ƴ�
- ����:ɾ���ļ��б�Ǿɵ��ĵ�ɾ��,�����µĶ�
�ӳ�д
ES������ʵʱ���ڴ��е�����д���,���Dz����ӳ�д�IJ���(����ǰ���дbuffer,Ȼ���첽��ʱˢ��)
es�Ƚ��ڴ�����,д���ļ�����ϵͳ(����ϵͳ�ڴ�),
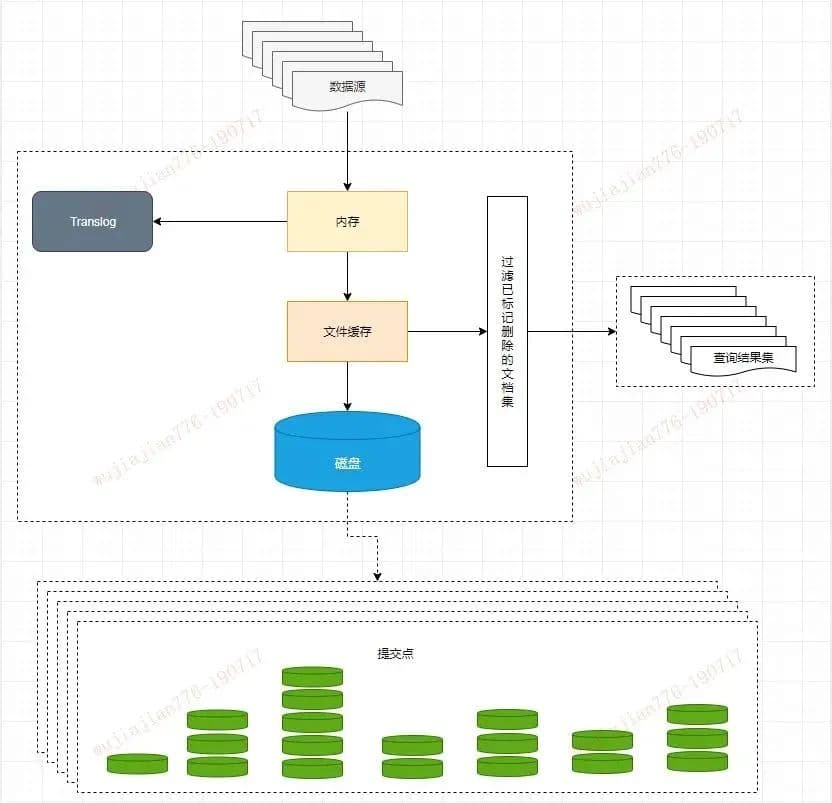
��ͼ���� * �����ֽ̳�,��������ElasticSearch
ע�⼸������
- д���ļ�����ϵͳ,֮���첽����,���ܵ��¶�����,es����������־�ķ�ʽ�������ָ�����(��mysql����д��־,����֮�����طŻָ�)
- es�������ʱ,�����ļ�����ϵͳ + ���е��ĵ�,���ڴ��е����ݲ��ᱻ������(������es�ǽ�ʵʱ��������,��Ϊ����д������ݻ����ڴ���,û���ύ,������Ͳ鲻��)
- Ϊ�˱���ι���,es�ᶨʱ���ϲ�,���ܶ�С�Ķκϲ��ɴ�Ķ�(�ϲ������л��Զ��Ƴ������ɾ�����ĵ�)
���С��һ��es�ij־û�
- �����ֶδ洢,������checkpoint֮��,��ֻ��,��˿���ȫ������,���ÿ��Ǹ�����
- �ӳ�д����:�ȸ����ڴ�����,�첽�ύ�ļ�����ϵͳ,������ɲ���ϵͳˢ��
- �ڴ��е����ݲ��ܱ�����;�ļ����� + ���е������ṩ��ѯ�ۺ�,���յĽ��������ѱ��ɾ�����ĵ�
4.5 ��
��һС����Ҫ���ܵ���ES�ĸ߿��û���,����ES�ļ�Ⱥ����ԭ��,ѡ�ٲ���;�������ݷ�Ƭ֧�ִ����ݳ�����֧��,������������߿�����;
ESԭ��֧�ּ�Ⱥ
- ��ɫ����:��ѡ���ڵ� + ���ݽڵ�
- ���ݽڵ�:�������ݵĴ洢����صIJ���(CURD,�ۺ�)��,��˶Ի�������Ҫ��ϸ�
- ��ѡ���ڵ�:ӵ��ѡ��Ȩ�ͱ�ѡ��Ȩ,���ڵ��ں�ѡ���ڵ�����ѡ����,����������ɾ��������������Щ�ڵ���Ⱥ����һ����,��������Щ��Ƭ�������Щ�Ľڵ㡢�ټ�Ⱥ�нڵ��״̬��
ES���ݳ־û�����
- �����ֶδ洢,������checkpoint֮��,��ֻ��,��˿���ȫ������,���ÿ��Ǹ�����;��������ʱ,���ԭ�������ĵ�ɾ��,���µĶ�д������
- �ӳ�д����:�ȸ����ڴ�����,�첽�ύ�ļ�����ϵͳ,������ɲ���ϵͳˢ��
- �ڴ��е����ݲ��ܱ�����;�ļ����� + ���е������ṩ��ѯ�ۺ�,���յĽ��������ѱ��ɾ�����ĵ�
�����
5.һ�һҵ��ܽ�
5.1 ����
��Ƭ������Ҫ�Ƿ������²�ͬӦ�ó����µļ�������ϵͳ�ĸ߿��ò���,����һ����������ϵ�ϵͳ�ĸ߿���
�����ĸ߿���˼·
- ���� (�����ݸ��������������)
- ��� (���ݲ�֡�����������ֵ�)
- �־û�
redis
- �־û�:RDB�������̼��ط�ʽ + AOF��¼�����������ڻطŲ���
- ����,���Ӵ�:ȫ���������ࡢ��д�������,���ؾ����˼��;���������������ڵ�ҵ�֮����Ҫ�˹������ֶ�ָ������
- �ڱ�����:PING/PONG��̽�����,�������ڵ�,崻�֮���Զ�ѡ��,ȷ���߿���;���������������е�ʵ��������ͬ��һ������,��������ʱ���Ѻ�
- ��Ⱥ:���ݷ�Ƭ,ÿ��ʵ���ṩ���ַ�������
mysql
- ͨ��������ʵ�ָ߿���:������
- ��д����,ʵ�ָ��ؾ���:���ӡ����Ӵ�ģʽ
- ���ݳ־û�����:�����ڴ�(buffer),�첽ˢ��,�����ύ����һ����
rabbitmq
- ����ģʽ
- ����ģʽ:ȫ������һ������,�������ṩ����,����ʵ���Զ�����
- ��ͨ��Ⱥģʽ:���ݲ�ֵ���Ⱥ��ʵ����,consumer/publisher���ӵ�ʵ��֮��,��Ӿ������exchange/topic��ʵ����������
- Զ��ģʽ:�����ڶ����ĵij���,����Ϣת�����������ĵ�ʵ��
ElasticSearch
- ES��Ⱥ:���ݽڵ� + ��ѡ���ڵ�
- ES�־û�:
- �ӳ�д����,�ȸ����ڴ�,Ȼ���ύ����ϵͳ����,����첽ˢ�µ�����;
- �����ֶδ洢:������checkpoint֮��,��ֻ��,��˿���ȫ������,���ÿ��Ǹ�����;��������ʱ,���ԭ�������ĵ�ɾ��,���µĶ�д������
5.2 ������
����д����ʱ,ԭ�ƻ���Բ�ͬҵ������һ�������ϵͳ�������¸��Եĸ߿��÷���,ʵ��д�������ֹ������е��;�Ͱ�����һ���ֲ�ʽ�ļ�ϵͳhdfs���ݻ���(���ڴ����ҵ������,�Ӵ��Ļ���Ҳ����̫��),�������ڡ��ֲ�ʽϵͳ-�����������н��н���
����Ứ������ʱ�侫��,����һ���������ġ��ֲ�ʽר����,��ӭ����Ȥ�ղع�ע һ�һҵ���վ
- ר����ַ:* �ֲ�ʽר�� | https://hhui.top/�ֲ�ʽ
- ��ѡ: * �ֲ�ʽ���ģʽ���� | һ�һ�Learning
* �����������ò��ĵ�ַ,����ԭ�IJ鿴
��ӭ����Ȥ��С����ע�ҵĹ��ں�:��һ�һ�blog��