1、概述
官网:https://hudi.apache.org
gitee:https://gitee.com/apache/Hudi
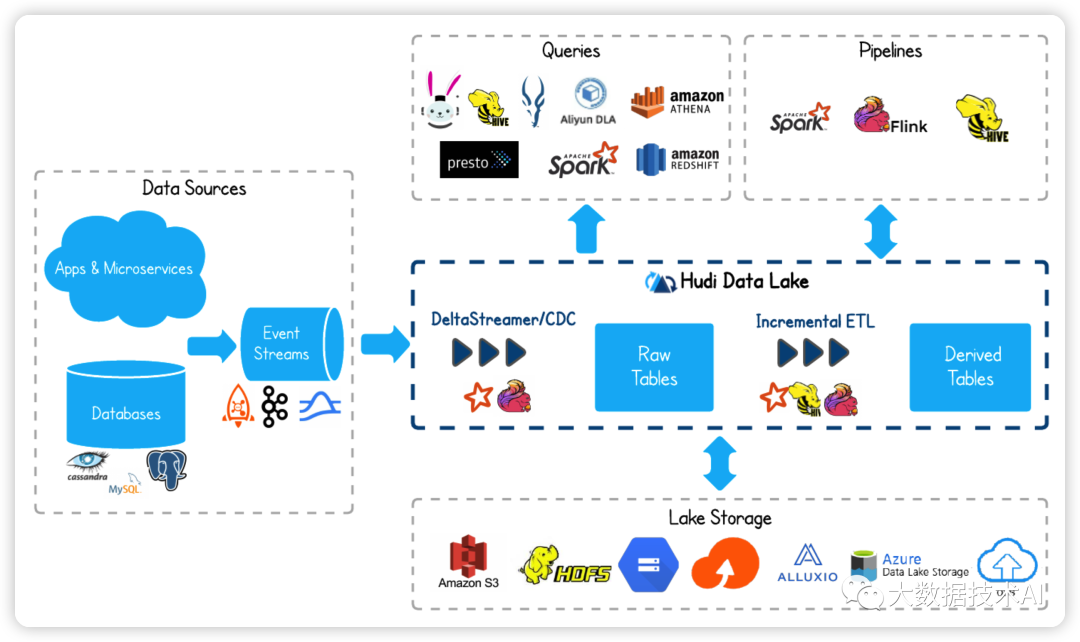
1.1 架构
1.2 特点
-
Upserts, Deletes with fast, pluggable indexing.
-
Incremental queries, Record level change streams
-
Transactions, Rollbacks, Concurrency Control.
-
SQL Read/Writes from Spark, Presto, Trino, Hive & more
-
Automatic file sizing, data clustering, compactions, cleaning.
-
Streaming ingestion, Built-in CDC sources & tools.
-
Built-in metadata tracking for scalable storage access.
-
Backwards compatible schema evolution and enforcement

2、启动flink
修改配置
taskmanager.numberOfTaskSlots: 4
配置HADOOP的环境变量
export HADOOP_CLASSPATH=`hadoop classpath`
2.1 启动本地集群(Standalone)
duo@bigdata100:/flink-1.14.4$?./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host bigdata100.
Starting taskexecutor daemon on host bigdata100.
duo@bigdata100:/flink-1.14.4$ jps
18226 Jps
15333 NameNode
16038 ResourceManager
16649 JobHistoryServer
17900 StandaloneSessionClusterEntrypoint
15756 SecondaryNameNode
16381 NodeManager
15534 DataNode
启动sql-client
duo@bigdata100:/bigdata/module/flink-1.14.4$ ./bin/sql-client.sh embedded -j /home/duo/hudi-flink-bundle_2.11-0.10.1.jar
2.2 启动yarn-session集群
依赖于hadoop存储,所以只能以yarn模式启动集群
duo@bigdata100:/bigdata/module/flink-1.14.4$ ./bin/yarn-session.sh -nm duo -d
duo@bigdata100:/bigdata/module/flink-1.14.4$ jps
15333 NameNode
16038 ResourceManager
25191 YarnSessionClusterEntrypoint
16649 JobHistoryServer
25290 Jps
15756 SecondaryNameNode
16381 NodeManager
15534 DataNode
duo@bigdata100:/bigdata/module/flink-1.14.4$ ./bin/sql-client.sh embedded -s yarn-session -j /home/duo/hudi-flink-bundle_2.11-0.10.1.jar
3、测试
3.1 sql执行语句
-- 创建表CREATE TABLE student( uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED, name VARCHAR(10), age INT, ts TIMESTAMP(3), `partition` VARCHAR(20))PARTITIONED BY (`partition`)WITH ( 'connector' = 'hudi', 'path' = 'hdfs:///flink/hudi/student', 'table.type' = 'MERGE_ON_READ');-- 插入数据INSERT INTO student VALUES ('id1','Danny',23,TIMESTAMP '2022-07-01 12:12:12','par1'), ('id2','Stephen',33,TIMESTAMP '2022-07-01 12:12:02','par1'), ('id3','Julian',53,TIMESTAMP '2022-07-01 12:12:03','par2'), ('id4','Fabian',31,TIMESTAMP '2022-07-01 12:12:04','par2'), ('id5','Sophia',18,TIMESTAMP '2022-07-01 12:12:05','par3'), ('id6','Emma',20,TIMESTAMP '2022-07-01 12:12:06','par3'), ('id7','Bob',44,TIMESTAMP '2022-07-01 12:12:07','par4'), ('id8','Han',56,TIMESTAMP '2022-07-01 12:12:08','par4');-- 更新key='id1' 的数据insert into t1 values ('id1','Danny',27,TIMESTAMP '1970-01-01 00:00:01','par1');SELECT * FROM student;
3.2 创建表并插入数据
Flink SQL> set execution.result-mode=tableau;[INFO] Session property has been set.Flink SQL> CREATE TABLE student(> uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,> name VARCHAR(10),> age INT,> ts TIMESTAMP(3),> `partition` VARCHAR(20)> )> PARTITIONED BY (`partition`)> WITH (> 'connector' = 'hudi',> 'path' = 'hdfs:///flink/hudi/student',> 'table.type' = 'MERGE_ON_READ'> );[INFO] Execute statement succeed.Flink SQL> INSERT INTO student VALUES> ('id1','Danny',23,TIMESTAMP '2022-07-01 12:12:12','par1'),> ('id2','Stephen',33,TIMESTAMP '2022-07-01 12:12:02','par1'),> ('id3','Julian',53,TIMESTAMP '2022-07-01 12:12:03','par2'),> ('id4','Fabian',31,TIMESTAMP '2022-07-01 12:12:04','par2'),> ('id5','Sophia',18,TIMESTAMP '2022-07-01 12:12:05','par3'),> ('id6','Emma',20,TIMESTAMP '2022-07-01 12:12:06','par3'),> ('id7','Bob',44,TIMESTAMP '2022-07-01 12:12:07','par4'),> ('id8','Han',56,TIMESTAMP '2022-07-01 12:12:08','par4');[INFO] Submitting SQL update statement to the cluster...[INFO] SQL update statement has been successfully submitted to the cluster:Job ID: 2b4962486c1fbcff9e6354ab17801ae1Flink SQL> SELECT * FROM student;
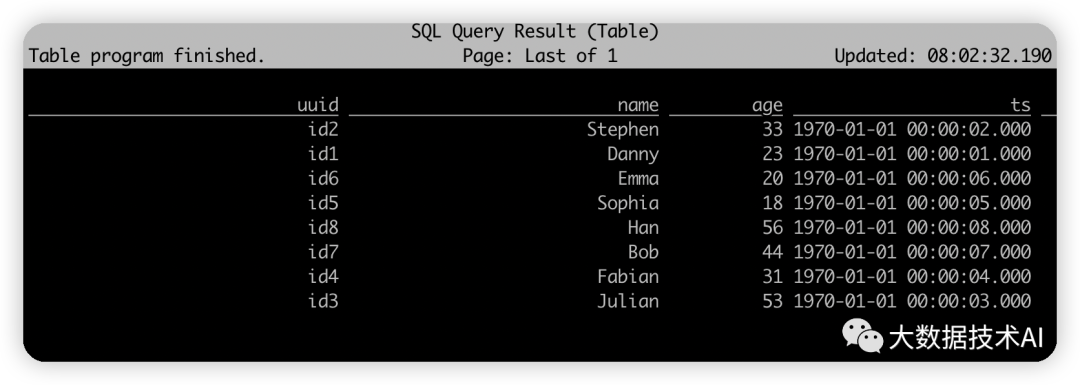
3.3 查询数据
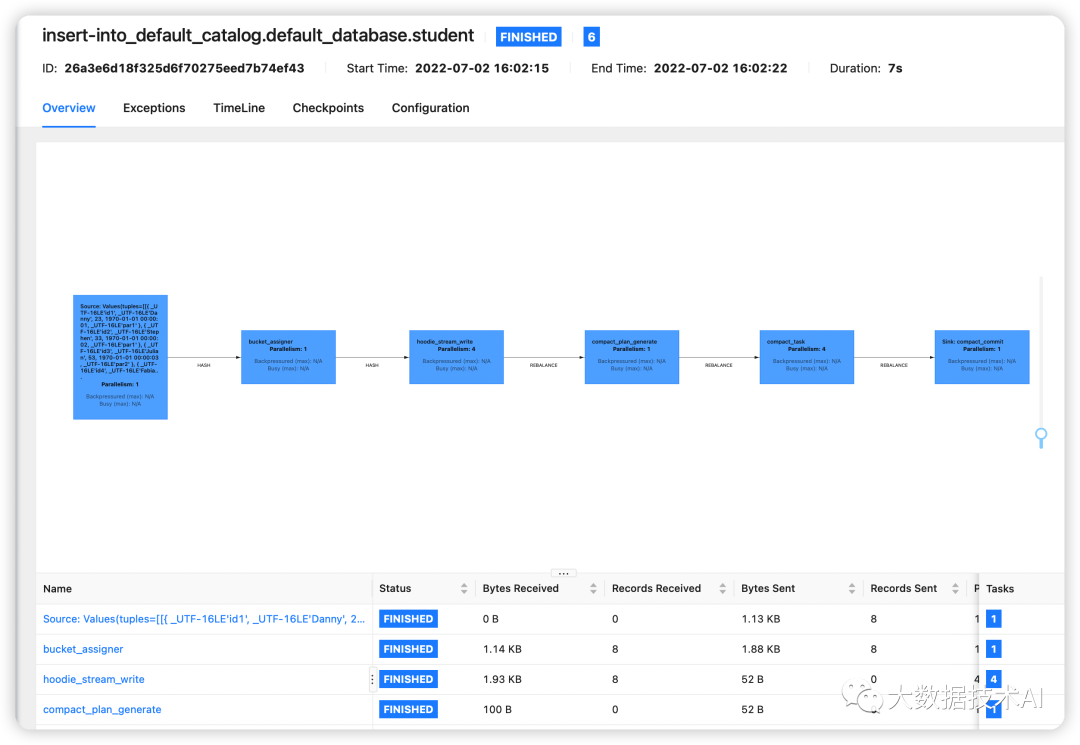
3.4 查看yarn任务

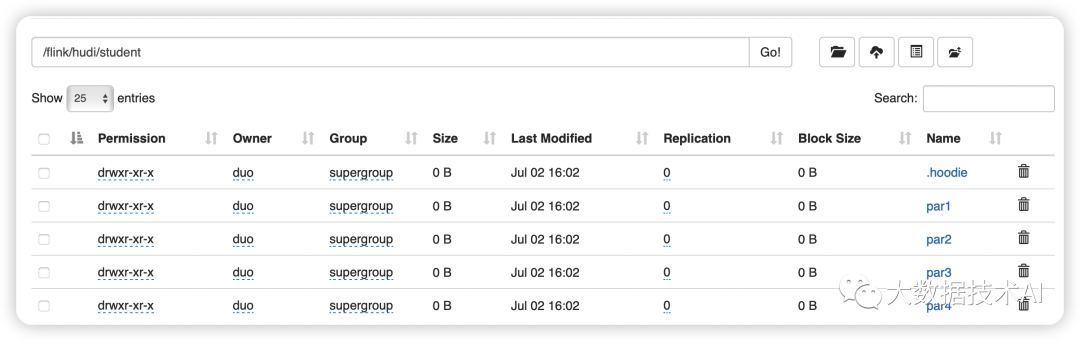
3.5 查看HDFS文件
3.6 Flink WebUI 查看任务