����
��������
- ��������,redis��������?
- ����д����,redis��η�̯?
- ����ģʽ,н���ഫģʽ,����崻�,����ip��ַ���ͱ仯,Ӧ�ó�����������Ҫ�Ķ�Ӧ��������ַ���˿ڵ���Ϣ��
֮ǰͨ���������������,����redis3.0���ṩ�˽������,���������Ļ���Ⱥ���á�
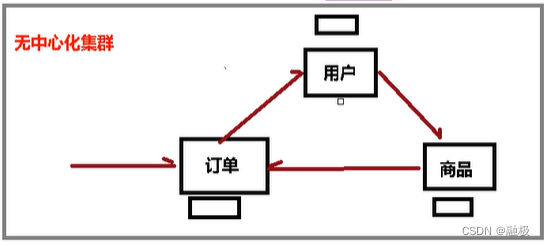
ʲô�Ǽ�Ⱥ
Redis��Ⱥʵ���˶�Redis��ˮƽ����,��������N��redis�ڵ�,���������ݿ�ֲ��洢����N���ڵ���,ÿ���ڵ�洢�����ݵ�1/N��
Redis��Ⱥͨ������(partition)���ṩһ���̶ȵĿ�����(availablitity):��ʹ��Ⱥ����һ���ֽڵ�ʧЧ����������ͨѶ,��ȺҲ���Լ���������������
��Ⱥ�
����6��redisʵ��,6379��6380��6381��6389��6390��6391
���û�����Ϣ
- ����daemonize yes;
- ��pid�ļ�����;
- �Ķ˿�;
- ��log�ļ�����(���Բ���);
- ��dbfilename
�Ķ�����������:
daemonize yes
pidfile "/var/run/redis_6379.pid"
port 6379
dbfilename "dump6379.rdb"
redis cluster������
- cluster-enabled yes ��Ⱥģʽ
- cluster-config-file nodes-6379.conf �趨�ڵ������ļ���
- cluster-node-timeout 1500 �趨�ڵ�ʧ��ʱ��,������ʱ��(����),��Ⱥ�Զ����������л���
daemonize yes
pidfile "/var/run/redis_6379.pid"
port 6379
dbfilename "dump6379.rdb"
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
����redis��Ⱥʵ��
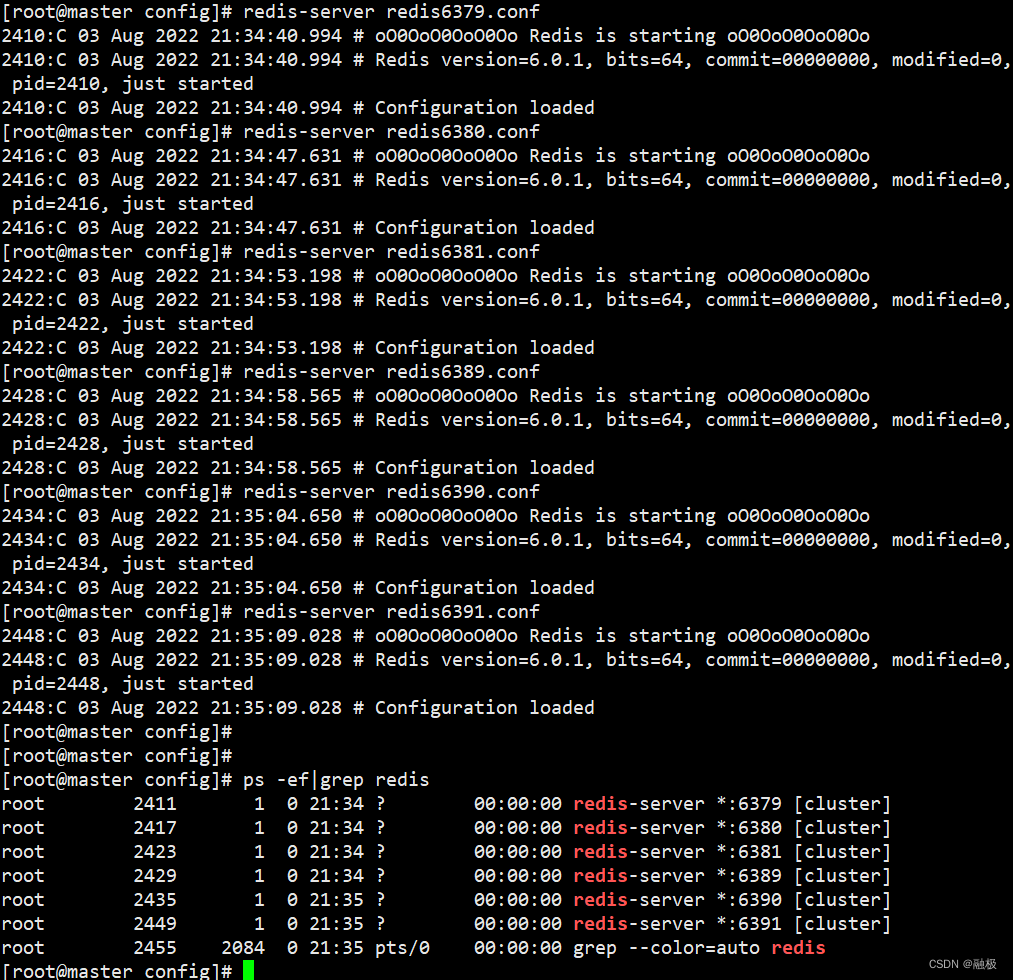
��Ⱥ�����õ�cluster-config-file�ļ��Զ����ɡ�
��6���ڵ�ϳ�һ����Ⱥ
���֮ǰ,��ȷ�����е�redisʵ������,nodes-xxx.conf�ļ�������������
����redisԴ�ļ�Ŀ¼��(redis�Ͱ汾��Ҫ��װrb����)��
�ص����ý���
# �˴���Ҫ��127.0.0.1,������ʵip��ַ
# --cluster-replicas 1 ��ʾ������ķ�ʽ���ü�Ⱥ,һ̨����,һ̨�ӻ�,�������顣
[root@master src]# redis-cli --cluster create --cluster-replicas 1 192.168.230.128:6379 192.168.230.128:6380 192.168.230.128:6381 192.168.230.128:6389 192.168.230.128:6390 192.168.230.128:6391
�������ý������:
[root@master src]# pwd
/usr/local/bin/redis/src
# �˴���Ҫ��127.0.0.1,������ʵip��ַ
[root@master src]# redis-cli --cluster create --cluster-replicas 1 192.168.230.128:6379 192.168.230.128:6380 192.168.230.128:6381 192.168.230.128:6389 192.168.230.128:6390 192.168.230.128:6391
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.230.128:6390 to 192.168.230.128:6379
Adding replica 192.168.230.128:6391 to 192.168.230.128:6380
Adding replica 192.168.230.128:6389 to 192.168.230.128:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 7613a39531e47a6ff6fd56983cdae88e5d9df94a 192.168.230.128:6379
slots:[0-5460] (5461 slots) master
M: 70c1e43570d7bc31e90e47e4220d428ac7f4816c 192.168.230.128:6380
slots:[5461-10922] (5462 slots) master
M: b34b9c9224c937d8078395ceb5448fe6ebd23273 192.168.230.128:6381
slots:[10923-16383] (5461 slots) master
S: fb8df6c560b021bf7d1aa883791888d59d8fed01 192.168.230.128:6389
replicates b34b9c9224c937d8078395ceb5448fe6ebd23273
S: a89052128eec0c4b1aab900255ae60047ceafb8f 192.168.230.128:6390
replicates 7613a39531e47a6ff6fd56983cdae88e5d9df94a
S: 11097faa158e438842c12cbcd71d498abec61783 192.168.230.128:6391
replicates 70c1e43570d7bc31e90e47e4220d428ac7f4816c
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
....
>>> Performing Cluster Check (using node 192.168.230.128:6379)
M: 7613a39531e47a6ff6fd56983cdae88e5d9df94a 192.168.230.128:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 70c1e43570d7bc31e90e47e4220d428ac7f4816c 192.168.230.128:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: a89052128eec0c4b1aab900255ae60047ceafb8f 192.168.230.128:6390
slots: (0 slots) slave
replicates 7613a39531e47a6ff6fd56983cdae88e5d9df94a
M: b34b9c9224c937d8078395ceb5448fe6ebd23273 192.168.230.128:6381
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 11097faa158e438842c12cbcd71d498abec61783 192.168.230.128:6391
slots: (0 slots) slave
replicates 70c1e43570d7bc31e90e47e4220d428ac7f4816c
S: fb8df6c560b021bf7d1aa883791888d59d8fed01 192.168.230.128:6389
slots: (0 slots) slave
replicates b34b9c9224c937d8078395ceb5448fe6ebd23273
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
[root@master src]#
�ͻ�������
- ͨ����ͨ��ʽ����
ֻ�ܿ�����ʵ�������ݡ�
[root@master src]# redis-cli -p 6379
127.0.0.1:6379> get a
(error) MOVED 15495 192.168.230.128:6381
127.0.0.1:6379> get b
"11"
127.0.0.1:6379>
- ���ü�Ⱥ��������,�������ݻ��Զ��л�����Ӧ��д����
[root@master src]# redis-cli -c -p 6379
127.0.0.1:6379> get a
-> Redirected to slot [15495] located at 192.168.230.128:6381
"10"
192.168.230.128:6381> get b
-> Redirected to slot [3300] located at 192.168.230.128:6379
"11"
192.168.230.128:6379> keys *
1) "b"
192.168.230.128:6379>
# �鿴��Ⱥ�ڵ���Ϣ
192.168.230.128:6379> cluster nodes
70c1e43570d7bc31e90e47e4220d428ac7f4816c 192.168.230.128:6380@16380 master - 0 1659536510264 2 connected 5461-10922
a89052128eec0c4b1aab900255ae60047ceafb8f 192.168.230.128:6390@16390 slave 7613a39531e47a6ff6fd56983cdae88e5d9df94a 0 1659536508000 5 connected
b34b9c9224c937d8078395ceb5448fe6ebd23273 192.168.230.128:6381@16381 master - 0 1659536508249 3 connected 10923-16383
11097faa158e438842c12cbcd71d498abec61783 192.168.230.128:6391@16391 slave 70c1e43570d7bc31e90e47e4220d428ac7f4816c 0 1659536507241 6 connected
7613a39531e47a6ff6fd56983cdae88e5d9df94a 192.168.230.128:6379@16379 myself,master - 0 1659536506000 1 connected 0-5460
fb8df6c560b021bf7d1aa883791888d59d8fed01 192.168.230.128:6389@16389 slave b34b9c9224c937d8078395ceb5448fe6ebd23273 0 1659536509257 4 connected
- ʹ��ͼ�λ��ͻ�������
��Ⱥ��η���ڵ�
һ����Ⱥ����Ҫ���������ڵ㡣
ѡ��Ccluster-replicas 1 ��ʾ����ϣ��Ϊ��Ⱥ�е�ÿ�����ڵ㴴��һ���ӽڵ㡣
����ԭ������֤ÿ�������ݿ������ڲ�ͬ��IP��ַ��,ÿ���ӿ�����ⲻ��һ��IP��ַ�ϡ�
ʲô��slots
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
һ��Redis��Ⱥ����16384�����(hash slot),���ݿ��е�ÿ������������16384����۵����е�һ����
��Ⱥʹ�ù�ʽCRC16(key)%16384�������key�����ĸ���,����CRC16(key)������ڼ����key��CRC16У��͡�
��Ⱥ�е�ÿ���ڵ㸺����һ���ֲ�ۡ��ٸ�����,���һ����Ⱥ���������ڵ�,����:
�ڵ�A������0����5460�Ų�ۡ�
�ڵ�B������5461����10922�Ų�ۡ�
�ڵ�C������10923����16383�Ų�ۡ�

ÿ����ۿ��Դ�Ŷ��key-value��ֵ�ԡ�
���ϻָ�
- ������ڵ�����,�ӽڵ�15s��ʱ���Զ���Ϊ���ڵ㡣
- ԭ�����ߵ����ڵ�ָ���,���ڵ����˴ӽڵ㡣
- ���ijһ�β�۵����ӽڵ㶼崻�,redis�����Ƿ��ܼ���?
��:���ijһ�β�۵����ӽڵ㶼�ҵ�,��cluster-require-full-coverageΪyes,��ô������Ⱥ���ҵ���
���ijһ�β�۵����Ӷ��ҵ�,��cluster-require-full-coverageΪno,��ô,�öβ�۵�����ȫ������ʹ��,Ҳ���洢;�����ڵ�IJ�ۿ�������ʹ�á�