MYSQL调优(六)之查询优化
在编写快速的查询之前,需要清楚一点,真正重要的是响应时间,而且要知道在整个SQL语句的执行过程中每个步骤都花费了多长时间,要知道哪些步骤是拖垮执行效率的关键步骤,想要做到这点,必须要知道查询的生命周期,然后进行优化,不同的应用场景有不同的优化方式,不要一概而论,具体情况具体分析,。
0、查询慢的原因
网络
CPU
IO
上下文切换
系统调用
生成统计信息
锁等待时间
1、优化数据访问(select*)
1. 数据量少一些,太多了,比如10000多条,那么有可能不会用到索引排序。
2. Limit前面的数字不能太大,造成了全表扫描的过程,太大limit不行。可以用子查询。
3. 优化数据访问,尽量不要写,速度太慢了。*
1.查询性能低下的主要原因是访问的数据太多,某些查询不可避免的需要筛选大量的数据,我们可以通过减少访问数据量的方式进行优化
确认应用程序是否在检索大量超过需要的数据
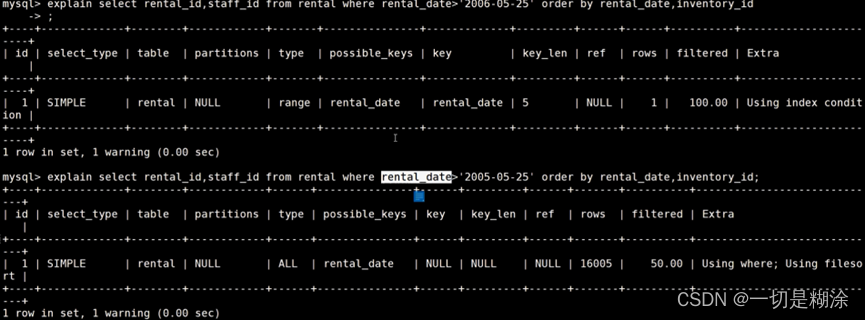
上面检索了大量的数据,所以不用索引。
 需要5条,但是explain中rows却为16005条,因为用limit时,前面一个数字过大则会触发全表扫描。
需要5条,但是explain中rows却为16005条,因为用limit时,前面一个数字过大则会触发全表扫描。
确认mysql服务器层是否在分析大量超过需要的数据行
2.是否向数据库请求了不需要的数据,查询不需要的记录

多表关联时返回全部列,尽量少用select *
总是取出全部列 尽量少用select *
重复查询相同的数据,但是再高版本删除了查询缓存。

2、执行过程优化
执行过程中:查询优化器,会选择错误的执行计划。
优化器的优化策略。包含了静态优化(通过解析树进行分析)与动态优化(与上下文有关、索引等)
优化类型。
1.决定关联表的优化顺序,
2。尽量用内连接,因为使用的数据量会少。
3.使用等价变换规则,比如a!=4或者a>4 && a <4。4.用min,max时,尽量用分组条件,使用索引效率比较高。
5.尽量用等值查询。让ref为const、
6.on的后面最好使用索引,使用index-neste-loop算法。
7.尽量不要用子查询,会产生临时表。换成join
8.尽量使用union all 而不是union,因为后者需要消除重复行,这种操作影响了性能。
一个是查询缓存,一个是查询优化处理。
对于查询缓存,在解析一个查询语句之前,如果查询缓存是打开的,那么mysql会优先检查这个查询是否命中查询缓存中的数据,如果查询恰好命中了查询缓存,那么会在返回结果之前会检查用户权限,如果权限没有问题,那么mysql会跳过所有的阶段,就直接从缓存中拿到结果并返回给客户端。
重要的是查询优化处理。
mysql查询完缓存之后会经过以下几个步骤:解析SQL、预处理、优化SQL执行计划,这几个步骤出现任何的错误,都可能会终止查询。
1.语法解析器与预处理
mysql通过关键字将SQL语句进行解析,并生成一颗解析树,mysql解析器将使用mysql语法规则验证和解析查询,例如验证使用使用了错误的关键字或者顺序是否正确等等,预处理器会进一步检查解析树是否合法,例如表名和列名是否存在,是否有歧义,还会验证权限等等
2.查询优化器
当语法树没有问题之后,相应的要由优化器将其转成执行计划,一条查询语句可以使用非常多的执行方式,最后都可以得到对应的结果,但是不同的执行方式带来的效率是不同的,优化器的最主要目的就是要选择最有效的执行计划
mysql使用的是基于成本的优化器,在优化的时候会尝试预测一个查询使用某种查询计划时候的成本,并选择其中成本最小的一个。show status like ‘last_query_cost’;
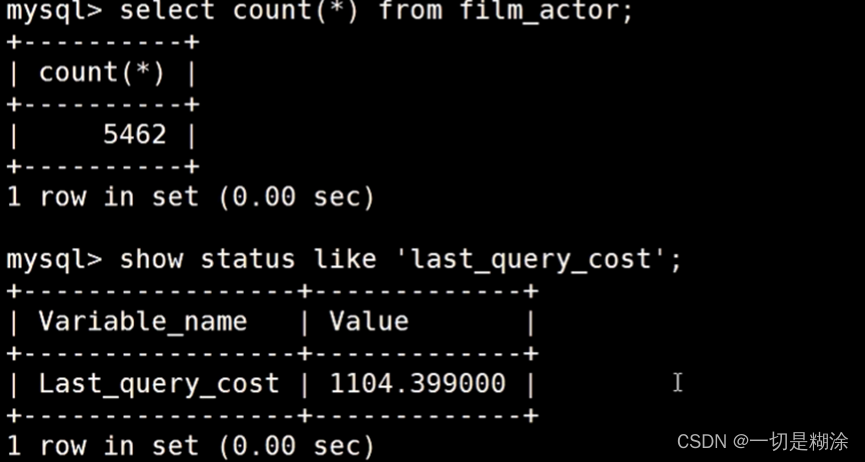 可以看到这条查询语句大概需要做1104个数据页才能找到对应的数据,这是经过一系列的统计信息计算来的
可以看到这条查询语句大概需要做1104个数据页才能找到对应的数据,这是经过一系列的统计信息计算来的
每个表或者索引的页面个数
索引的基数
索引和数据行的长度
索引的分布情况
在很多情况下mysql会选择错误的执行计划,原因如下:
统计信息不准确(InnoDB因为其mvcc的架构,并不能维护一个数据表的行数的精确统计信息,成本并不一定是准确的)
执行计划的成本估算不等同于实际执行的成本(有时候某个执行计划虽然需要读取更多的页面,但是他的成本却更小,因为如果这些页面都是顺序读或者这些页面都已经在内存中的话,那么它的访问成本将很小,mysql层面并不知道哪些页面在内存中,哪些在磁盘,所以查询之际执行过程中到底需要多少次IO是无法得知的)
mysql的最优可能跟你想的不一样(mysql的优化是基于成本模型的优化,但是有可能不是最快的优化)
mysql不考虑其他并发执行的查询() mysql不会考虑不受其控制的操作成本(执行存储过程或者用户自定义函数的成本)
优化器的优化策略 静态优化 直接对解析树进行分析,并完成优化
动态优化(比如用2005年5月5日做范围查询,与大于2006年5月5日用的索引不一样)
动态优化与查询的上下文有关,也可能跟取值、索引对应的行数有关
mysql对查询的静态优化只需要一次,但对动态优化在每次执行时都需要重新评估
优化器的优化类型
重新定义关联表的顺序(数据表的关联并不总是按照在查询中指定的顺序进行,决定关联顺序时优化器很重要的功能)比如Ajoinbjoinc
并不是先a在b后c,有可能不同组合。 将外连接转化成内连接,内连接的效率要高于外连接
使用等价变换规则,mysql可以使用一些等价变化来简化并规划表达式(尽量一个语句完成,比如a !=4 与a > 4 && a < 40)
优化count(),min(),max()聚合函数 (索引和列是否可以为空通常可以帮助mysql优化这类表达式:例如,要找到某一列的最小值,只需要查询索引的最左端的记录即可,不需要全文扫描比较)
预估并转化为常数表达式,当mysql检测到一个表达式可以转化为常数的时候,就会一直把该表达式作为常数进行处理(explain select
film.film_id,film_actor.actor_id from film inner join film_actor
using(film_id) where film.film_id = 1)能不用范围查询就不用范围查询。
索引覆盖扫描,当索引中的列包含所有查询中需要使用的列的时候,可以使用覆盖索引
子查询优化(mysql在某些情况下可以将子查询转换一种效率更高的形式,从而减少多个查询多次对数据进行访问,例如将经常查询的数据放入到缓存中)
等值传播(如果两个列的值通过等式关联,那么mysql能够把其中一个列的where条件传递到另一个上: explain select
film.film_id from film inner join film_actor using(film_id ) where
film.film_id >
500;这里使用film_id字段进行等值关联,film_id这个列不仅适用于film表而且适用于film_actor表explain
select film.film_id from film inner join film_actor using(film_id)
where film.film_id > 500 and film_actor.film_id > 500; 3)
里使用了film_id字段进行等值关联,MySQL会知道这里的WHERE子句不仅适用于film表,同样也适用于film_actor表。
关联查询
join的实现方式原理
Simple Nested-Loop Join
Index Nested-Loop Join
Block Nested-Loop Join
(1)Join Buffer会缓存所有参与查询的列而不是只有Join的列。
(2)可以通过调整join_buffer_size缓存大小
(3)join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL
5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。 (4)使用Block Nested-Loop
Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。
show variables like ‘%optimizer_switch%’
排序优化 排序的算法 两次传输排序(老版本)
第一次数据读取是将需要排序的字段读取出来,然后进行排序,第二次是将排好序的结果按照需要去读取数据行。
这种方式效率比较低,原因是第二次读取数据的时候因为已经排好序,需要去读取所有记录而此时更多的是随机IO,读取数据成本会比较高
两次传输的优势,在排序的时候存储尽可能少的数据,让排序缓冲区可以尽可能多的容纳行数来进行排序操作遍历排序好的 id 和字段 age ,按照 id 的值回到原表中取出 所有字段的值返回给客户端
单次传输排序(新版本)先读取查询所需要的所有列,然后再根据给定列进行排序,最后直接返回排序结果,此方式只需要一次顺序IO读取所有的数据,而无须任何的随机IO,问题在于查询的列特别多的时候,会占用大量的存储空间,无法存储大量的数据
当需要排序的列的总大小超过max_length_for_sort_data定义的字节(默认1024),mysql会选择双次排序,反之使用单次排序,当然,用户可以设置此参数的值来选择排序的方式对比: ? 其实对比两个排序模式,单路排序会把所有需要查询的字段都放到 sort buffer 中,而双路排序只会把主键
和需要排序的字段放到 sort buffer 中进行排序,然后再通过主键回到原表查询需要的字段。
总结
在优化数据访问过程中:
1. 数据量少一些,太多了,比如10000多条,那么有可能不会用到索引排序。
2. Limit前面的数字不能太大,造成了全表扫描的过程,太大limit不行。可以用子查询。
3. 优化数据访问,尽量不要写,速度太慢了。*
在执行过程优化过程中:
执行过程中:查询优化器,会选择错误的执行计划。
优化器的优化策略。包含了静态优化(通过解析树进行分析)与动态优化(与上下文有关、索引等) 优化类型。
1.决定关联表的优化顺序, 2。尽量用内连接,因为使用的数据量会少。
3.使用等价变换规则,比如a!=4或者a>4 && a <4。4.用min,max时,尽量用分组条件,使用索引效率比较高。
5.尽量用等值查询。让ref为const、
6.on的后面最好使用索引,使用index-neste-loop算法。
7.尽量不要用子查询,会产生临时表。换成join
8.尽量使用union all 而不是union,因为后者需要消除重复行,这种操作影响了性能。