- 事务的4大特性分别由:事务日志、锁机制实现,0~4标题是事务日志,5之后是锁机制
- 每个阶段的小结放在最前面
0.事务日志:总结
- redo log保证持久性,在
innodb_flush_log_at_trx_commit=1(默认)的情况下,保证了事务的安全可靠 - undo log保证原子性、一致性,且undo log自身的持久化也依赖于redo log。undo log通过回滚指针形成链路,保证了回滚与MVCC。如果undo log被MVCC占用,则一直不会被删除。
- 刷盘持久化对于:页中数据(脏页)持久化、redo log持久化都有着相似的策略:(另外的线程)
- delete和对主键update,实际上进行的软删除(修改deletemark隐藏字段),由purge线程来进行真实的删除。
1.事务的4种特性
- 事务有4种特性:原子性、一致性、持久性、隔离性
隔离性:由锁机制 or MVCC实现原子性、一致性、持久性:由事务的redo日志和undo日志保证

2.事务日志概述
- redo log :
重做日志,记录物理级别上的修改(在页上的修改)的日志,提供再写入操作,恢复提交事务修改页的操作,保证事务持久性;主要保证数据可靠性 - undo log:
回滚日志,记录逻辑操作的日志(每个改动操作的逆过程),回滚到某一个特定版本,保证事务的原子性、一致性;主要用于回滚和MVCC - 二者都是一种恢复操作,只是场景不同
- 都是存储引擎生成的日志(而bin log则是数据层产生的)
3.redo log与持久性(D)
3.1Buffer Pool
- 在InnoDB中数据是存储在16k的页中的,在访问页中数据之前,会先将数据从磁盘读到内存中的Buffer Pool中
- 每次变更都需要先修改Buffer Pool,然后master线程以一定频率刷入磁盘。从而优化整体性能
3.2刷盘频率
- 如果每次事务提交都进行刷盘,那么效率就很低下(因为每次刷盘都是对一整个页进行刷盘,每次IO都是16kb)
- 当一个事务影响了多个页,刷盘时可能进行很多的随机IO(页可能不连续,而随机IO比顺序IO更慢,尤其对于传统机械硬盘)
3.3redo日志解决刷盘频率问题
- redo log也是写在磁盘中的,但占用的空间很小,也减少了刷盘的频率(16kb带来的性能开销远高于写一条日志)
- redo log是顺序写入磁盘的,比随机IO速度更快
- 此刷盘(redo log)非彼刷盘(页中数据)
3.4redo log buffer和redo log file
buffer:在内存中,默认16M,内部的block块是512kb
file:在磁盘中
只要保证redo log从buffer持久化到file不出错,那么MySQL宕机也能恢复数据

3.4.1刷盘策略innodb_flush_log_at_trx_commit=
- innodb_flush_log_at_trx_commit=1:每次commit就刷盘,redo log 一定在磁盘中,安全,不存在数据丢失问题,效率最差
- innodb_flush_log_at_trx_commit=2:每次commit只写入文件系统缓存(page cache),由后台线程进行刷盘,效率高,但不安全
- innodb_flush_log_at_trx_commit=0:1、2的折中做法,后台线程刷盘频率为1s
3.4.2建议使用默认
默认值为1,虽然效率差,但安全。使用事务本来考虑的就是安全性优先
4.undo log与原子性(A)
- 第3点的redo log保证的是持久性,事务过程中每次操作
之后都会产生一条redo log - 而undo log保证的是原子性,要保留之前的数据则需要在每次操作
之前
4.1undo log应用场景
- 服务器出错、断电需要回滚
- 事务手动roll back回滚
- MVCC
- 注:SELECT不产生undo log,但在MVCC机制中会用到undo log
- undo log产生的同时也会产生保护自身的redo log,而redo log默认刷盘策略innodb_flush_log_at_trx_commit=1又能保证回滚日志的安全(持久化)
4.2undo log回滚的理解
- undo log是逻辑日志,回滚只是表面上恢复之前的物理状态,但实际上是反向操作
- InnoDB支持的并发事务数量是由
回滚段roll back segment决定的,默认是128*1024
4.3每一行数据的结构
对于InnoDB来说,每一行都有3个隐藏列
- DB_ROW_ID: 没有指定主键时的隐藏主键
- DB_TRX_ID:事务ID
- DB_ROLL_PTR:回滚指针,指向undo log,相当于记录了修改该行之前的值,而undo log本身的数据结构也有一个undo log指针,指向上一个undo log(通过序号链式指向,在回滚和MVCC中用处很大)

4.3.1undo log序号
这个序号是按顺序写入日志的,因此在回滚的时候直接倒叙回滚就好
4.4更新主键:deletemark
4.3这种更新非主键是通过直接修改undo log指针指向来实现的。而如果修改主键id则需要利用deletemark(一个软删除标志,=1则软删,真实的删除由purge线程删除线程实现)
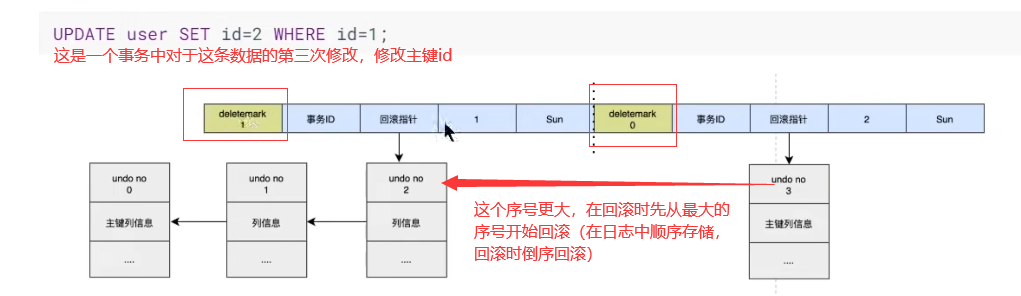
4.5undo log何时删除
4.5.1对于insert操作
在RR(可重复读)的隔离级别下,insert操作只对本事务可见(RR级别的MVCC解决了幻读),因此insert操作的 undo log可以在commit之后直接删除
4.5.2对于update操作
由于MVCC机制中的日志数组可能仍持有这条undo log记录,因此update操作commit后不能直接删除,而是存入undo log的一个链表中
5.事务的隔离级别与解决的问题
问题一般是:脏读、不可重复读、幻读
- 脏读:B读取了A回滚前的数据
- 不可重复读:B两次读取,分别读了A修改前和修改后的数据
- 幻读:一般是B事务SELECT一个WHERE范围,在这个范围中读到了A没提交的insert数据
SELECT @@transaction_isolation;查看隔离级别
5.1RU级别
RU:Read Uncommitted 读未提交,最低的隔离级别,任何情况都不加锁,在这个隔离级别下可能出现所有的问题
5.2RC级别
RC:Read Committed 读已提交,MVCC支持的最低隔离级别
- 如果有InnoDB的MVCC机制,则解决了:脏读、不可重复读
- 如果没有MVCC机制,则只解决了:脏读
5.3RR级别
RR:Read Repeatable 可重复读,在MVCC机制下可避免幻读
5.4Serializable
Serializable:串行化,最高的隔离级别,由加锁实现,最安全,性能最差
如果每条crud都加x锁,那么即便是不设置隔离级别为串行化,也是串行的
6.锁:总结
- 事务的
隔离性是由锁实现的 (也可由MVCC) - 锁的互斥性需要相同类型的锁,比如间隙锁与插入意向锁同为gap锁,同类型的冲突保证了间隙不出现幻读;而真正表级的意向锁互相都是兼容的,不会相互阻塞,他仅作为一个提示
7.锁的概述
锁机制用于多个线程or进程并发访问某一个资源,保证数据的一致性和完整性。
锁机制保证了各个事务的隔离级别
锁机制一般不针对读-读,只针对读-写 、写-读 、写-写
8.补:InnoDB的内存结构


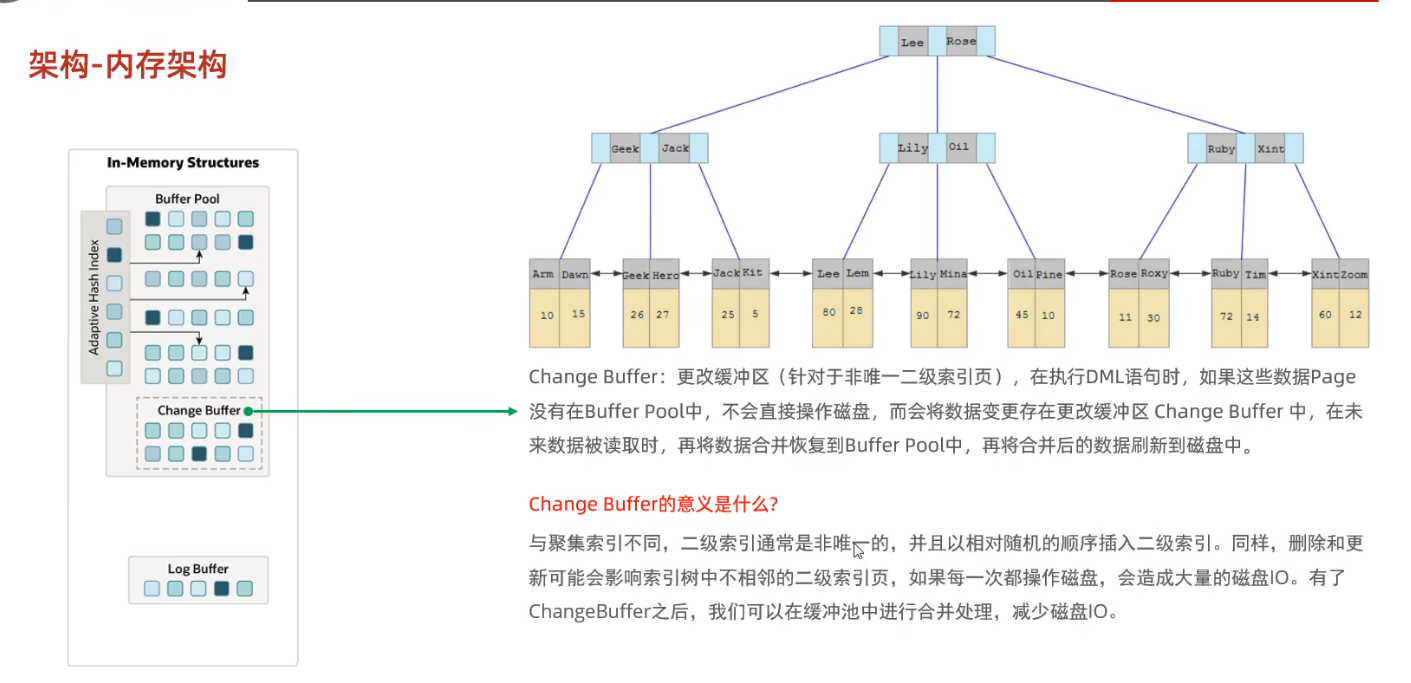


9.按操作类型(兼容性)划分
共享锁(读锁)(S锁):SELECT ... LOCK IN SHARE MODE或SELECT .. FOR SHARE
排他锁(写锁)(X锁):SELECT .. FOR UPDATE
- 锁可以手动加,也可以自动加
- 这两种锁主要体现在兼容性(是否会相互阻塞)上,无论是行锁表锁、意向锁等等都存在兼容性问题

- 兼容性不是一成不变的,表锁的兼容性与行锁的就不同。
同一个事务中
行锁:不会互相影响,即同一事务可以同时SELECT 又 UPDATE
表锁:独占的,本事务加S表锁,则不能在本事务中UPDATE
9.1读
读没什么好说的
9.2写
9.2.1 insert
由隐式锁保护,保证新数据在commit之前不会被其他事务访问
9.2.2 delete
从B+树找到该条记录的位置,获取这条记录的X锁,执行delete mark软删。真正的删除是purge线程删除
9.2.3 update
分为3种情况
- 情况1:未修改主键,且更新后存储空间不变:定位――获取X锁――在原记录的位置上修改
- 情况2:未修改主键,但更新后存储空间改变:定位――获取X锁――删除原数据,再insert(隐式锁)
- 情况3:修改了主键:类似情况2,先delete再insert
10.按粒度划分
- 锁粒度越小(锁定的少),并发性越好,但资源消耗更大
10.1表锁
10.1.1表级S锁与X锁
-
没有死锁问题
-
表锁也有S锁和X锁,但是兼容性与行锁不同:具体体现在如下两点

-
语法演示:
begin; lock tables xxx read; #也可以加write锁 show open tables where in_use > 0; #查看加锁的表 SELECT * FROM xxx ; # 正常可以查 UPDATE xxx SET s1 = 111 WHERE ... ;#阻塞,因为加了S表锁,所以同一事务也不能写当前表 unlock tables;#也可以直接commit; 都是释放表锁
10.1.2意向锁intention lock(多粒度锁支持)(加行锁时自动添加表级意向锁)
- InnoDB支持多粒度锁(允许行锁表锁共存)。而意向锁就是一种表锁
- 意向锁由存储引擎自己维护,用户无法操作。当添加行锁的时候,自动生成这个表级别的意向锁
- 意向锁不会锁住这个表,他只是告诉其他表“有其他事务锁住了表中的某些记录”
如果事务想要获得数据表中某些记录的共享S锁,就需要在数据表上添加意向共享S锁。
如果事务想要获得数据表中某些记录的排他X锁,就需要在数据表上添加意向排他X锁。
- 意向锁互相兼容(也可以看作意向锁与行锁相互兼容)

- 意向锁与表锁存在不兼容情况


10.1.3自增锁AUTO-INC
如果主键设置的是auto_increment,那么就有这个自增锁,**当一个事务持有自增锁的时候,其他事务的insert语句都会被阻塞。**如果innoDB知道要插入多少条数据则不会上自增锁
- 能明确知道插入的行数:例如insert into xx …value(),(),()
- 不能明确知道插入的行数:例如从其他表查
insert...select或replace...select或load data或混合模式
10.1.4元数据锁meta data lock
- 这个锁是表级别的,是为了防止crud DML的途中其他事务修改表结构
- crud DML的时候加MDL读锁,修改表结构DDL的时候加MDL写锁。读-读不互斥
- 对用户透明,自动添加
10.2行锁
行锁在存储引擎层实现,粒度小,开销大,更容易出现死锁,并发度高
对于行锁的监控方法如下



10.2.1记录锁record locks
这个就是可以自行添加,或在非RU级别下自动添加的锁,是狭义上的行锁
10.2.2间隙锁gap lock
- gap lock的提出仅仅是为了防止幻读,防止在间隙写入数据
- gap lock可能是由next_key locks退化而来
- 我个人更倾向于:间隙锁是临键锁的组成成分,而保证间隙锁的必要条件是
索引,因为只有索引才能保证确定这个间隙锁的范围 - 如何触发间隙锁?:有索引,
范围查询or查不存在的值
10.2.3临键锁next_key locks
- 默认情况下,InnoDB在REPEATABLE READ事务隔离级别运行,InnoDB使用next-key锁进行搜索和索引扫描,以防止幻读。
临键锁 = gap锁 + 记录锁- 例如 SELCT * FROM xxx WHERE age <= 10 and age > 5 (for update)这样加S锁(或X锁),因为有索引存在,(5,10]上的数据是不允许被其他事务插入的,从而防止了幻读
10.2.4插入意向锁insert intention locks
- 这个锁是一个gap锁,而不是意向锁。
- 因为其他事务需要保证间隙锁生效,因此需要一个同类型的锁来进行判断,所以引出了插入意向锁用于判断是否冲突
10.3页锁
- 行锁与表锁的折中粒度锁,并发度一般,也会出现死锁
- InnoDB一般用不到页锁
- 锁空间占满了,自动进行了锁升级,比如delete太多数据会导致锁表
11.按态度划分
11.1乐观锁
- 通过程序代码实现,而不采用数据库的锁机制
- 例如CAS机制、版本号机制(如where xxx = #{xxx}比如对update_time的时间戳进行校验)
11.2悲观锁
- 像Java中的
synchronized和ReentantLock等等独占锁都是悲观锁实现 - 在MySQL中使用悲观锁一定需要索引,否则会导致锁表(全表扫描)
- 如果事务太长(锁开销过高),推荐使用乐观锁
12.加锁方式
12.1隐式锁
隐式锁是没有指令可以查看的,当且仅当产生锁等待的时候转为显示锁

12.2显示锁
上面能查看的锁都是显示锁
13.其他
13.1全局锁
- 对整个数据加锁:例如在全库逻辑备份的时候,整个数据库都是只读状态
- 粒度最大的锁
13.2死锁
13.2.1产生条件
- 两个or以上的事务
- 每个事务都已经持有锁,并且正在申请新的锁
- 锁在不同的事务间不兼容
- 关键在于:加锁的顺序不一致
13.2.2如何处理死锁
存储引擎层面:
- 等待,直到超时:默认的innodb_lock_wait_timeout=50s,这个时间可以自己设置,如果太短也会误伤正常锁等待
- 死锁检测:存储引擎自动检查事务是否产生回路(死锁),回滚undo量最小的事务。但是这个方法每次遇到阻塞都去检测,并发量高的情况下检测回路的开销特别大,也可以自行关闭
业务设计层面:
- 控制并发量:例如使用MQ
- 调整SQL业务顺序,避免update和delete在事务的开头占据太长时间
- 将大事务拆分为小事务
数据库设计层面:
- 合理设计索引,减少锁竞争
- 降低隔离级别,且尽量不要显示加锁。(例如有MVCC的存在,可以将RR调整为RC,避免gap lock造成的死锁)
14.MVCC
- MVCC:多版本并发控制,与锁机制共同保证了事务的隔离性
- 依赖于数据库每行记录中的
三个隐藏字段、undo log、readView - 在MySQL的InnoDB中,依赖于MVCC,
RR(REPEATABLE READ)隔离级别下解决了幻读问题(如果没有MVCC机制则需要串行化or全加X锁才能解决幻读) - MVCC在RR级别和RC级别都是有效的,区别在于
ReadView对于undo log的判断规则。只是后者不能解决幻读问题。MVCC保证的是读,锁保证的是写,因为写永远是针对最新的版本。

14.1当前读、快照读
快照读的前提是不能是串行化,串行化下快照读退化为当前读

14.2MVCC实现原理
14.2.1undo log版本链
每次事务修改这条记录,都会产生一个版本,版本中的隐藏列DB_ROLL_PTR指针又形成了undo log版本链

14.2.2readView
这里面包含的四个字段,都是事务id相关的,他们共同决定了在读取undo log版本链的时候究竟是读哪个版本的数据。并且跟隔离级别也有关系


