HA概述
1)所谓HA,即高可用(7*24小时不中断服务)
2)实现高可用最关键的策略是消除单点故障。
3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障。
4)NameNode主要在一下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,知道管理员重启。
NameNode机器需要升级,包括软件升级,硬件升级,此时集群也无法使用
HDFS HA功能通过配置Active/StandBy两NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可以通过此方法将NameNode很快切换到另一台机器。
HA的namenode主要分为共享editLog机制,和ZKFC对namenode状态控制。
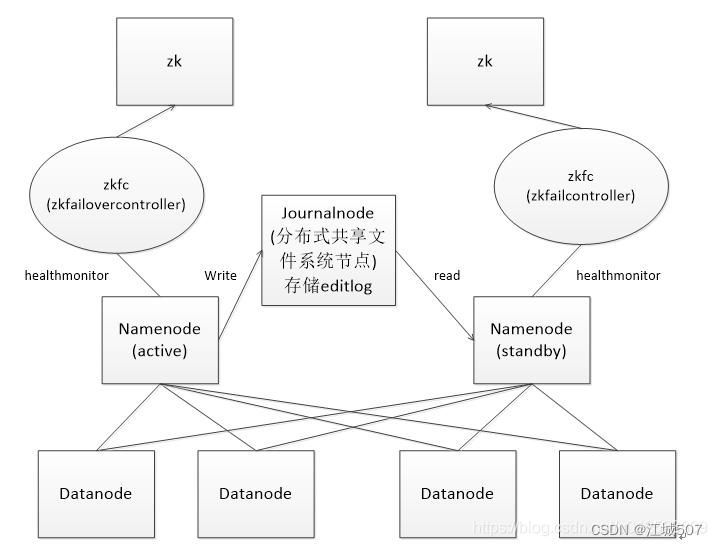
1)状态为active的namenode向分布式共享文件系统journalnode写入编辑日志editlog,状态为standby为了与active状态的namenode保持一致,在分布式共享文件系统中读入文件。
2)每个datanode会向所有namenode报告自身状态。
3)zkfc最为轻量级故障转移器,基于zookeeper实现,是由namenode运行的独立线程。在启动zkfc时,他会注册healthmonitor和activestandbyelector服务组件,同时会向注册的服务组件注册响应的回调方法。
healthmonitor负责监控namenode状态变化,当namenode状态改变时,会调用zkfc进行主备选举。
activestandbyelector负责主备选举,内部调用zk选举逻辑。当选举结束时,调用zkfc相应方法,切换主namenode状态,或者备namenode状态。
主备切换逻辑
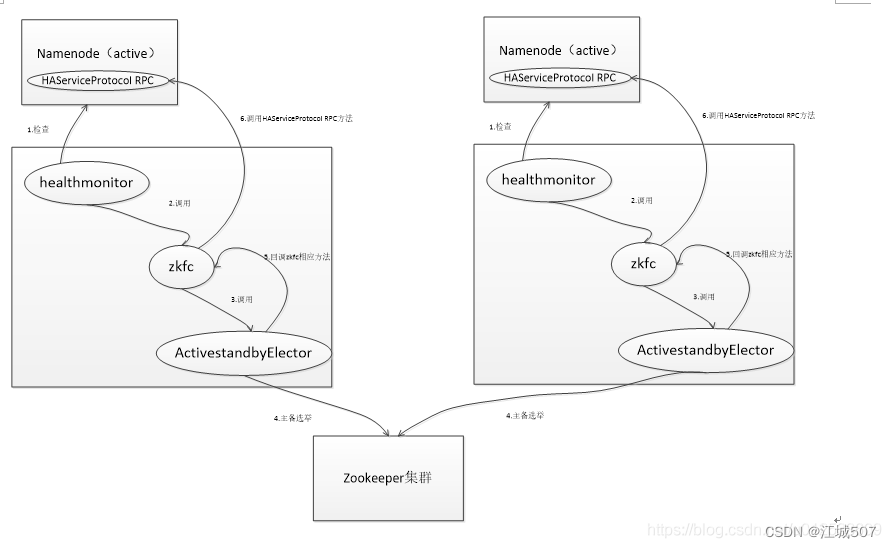
1)heathmoiniter监控namenode状态
2)当namenode状态改变,调用zkfc进行主备选举
3)zkfc判断是否需要进行主备选举
4)当需要进行选举时,调用activestandbyelector组件
5)activestandbyelector组件负责与zk进行交互,尝试在zk上创建临时节点。由于zk的最终一致性,只会有一个activestandbyelector创建节点成功,成功创建节点的activestandbyelector对应的namenode成为主namenode。
6)activestandbyelector进行回调zkfc,通知切换namenode状态
7)zkfc会调用HAservicePool RPC接口的方法来切换namenode状态。
防止脑裂
脑裂产生的情况有以下几种:
1)由于zookeeper的假死
2)长时间的垃圾回收或者网络异常等
脑裂的情况下,会出现两个active状态的namenode对外提供服务,无法保证数据一致性。
防止脑裂的步骤如下:
1)在创建临时节点的同时,创建持久节点。
2)正常关闭时,临时节点和持久节点都会被删除。
3)异常关闭时,还会存在持久节点。此时可以采用hadoop自带的隔离机制sshfence(直接通过端口查找进程id,kill进程)或shellfence方式(执行已有的shell脚本),执行fencing过程。