目录
简介
- 什么是Hadoop?
- 1.Hadoop是apache旗下的一套开源软件平台
- 2.Hadoop提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- 3.Hadoop的核心组件有
- A.HDFS(分布式文件系统)
- 对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。
- 元数据:又称中介数据、中继数据,为描述数据的数据,主要是描述数据属性的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
- B.YARN(运算资源调度系统)
- 是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
- C.MAPREDUCE(分布式运算编程框架)
- 最简单的 MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。main 函数将作业控制和文件输入/输出结合起来。
- MapReduce 本身就是用于并行处理大数据集的软件框架。MapReduce 的根源是函数性编程中的 map 和 reduce 函数。它由两个可能包含有许多实例(许多 Map 和 Reduce)的操作组成。Map 函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce 函数接受 Map 函数生成的列表,然后根据它们的键(为每个键生成一个键/值对)缩小键/值对列表。
- 例如:假设输入域是 one small step for man,one giant leap for mankind。在这个域上运行 Map 函数将得出以下的键/值对列表:(one,1)(small,1) (step,1) (for,1) (man,1)(one,1) (giant,1) (leap,1) (for,1) (mankind,1)
- 如果对这个键/值对列表应用 Reduce 函数,将得到以下一组键/值对:
- (one,2) (small,1) (step,1) (for,2) (man,1)(giant,1) (leap,1) (mankind,1)
- A.HDFS(分布式文件系统)
- 4.广义上来说,Hadoop通常是指一个更广泛的概念――Hadoop生态圈
- Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
- 1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 。
- 2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 5.低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,Hadoop是开源的,项目的软件成本因此会大大降低。
- Hadoop产生背景
- 1.Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题――如何解决数十亿网页的存储和索引问题。
- 2.2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
- 分布式文件系统(GFS),可用于处理海量网页的存储
- 分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- 3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目Hadoop,到2008年1月,Hadoop成为Apache顶级项目,迎来了它的快速发展期
- Hadoop在大数据、云计算中的位置和关系
- 1.云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
- 2.现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
- 3.而Hadoop则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
- Hadoop大数据处理的意义
- Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、转换和加载方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里
- Hadoop组件
- Hive
- hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
- Spark
- Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是――Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
- Hive
Hadoop中的各个进程
- 一般如果正常启动Hadoop,我们可以在master上通过jps命令看到以下5个进程(单机):
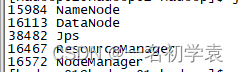
- 1.Namenode
- 它是Hadoop 中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问。
- Namenode 管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。
- Namenode容错机制
- 没有Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块(blocks)重建文件。因此,namenode的容错机制非常重要,Hadoop提供了两种机制。
- 第一种方式是将持久化存储在本地硬盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统。
- 第二种方式是运行一个辅助的Namenode(Secondary Namenode)。 事实上Secondary Namenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。
- 但是辅助Namenode总是落后于主Namenode,所以在Namenode宕机时,数据丢失是不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的Namenode的元数据文件来使用,把NFS中的Namenode元数据文件,拷贝到辅助Namenode,并把辅助Namenode作为主Namenode来运行。
- 2、SecondaryNameNode
- 它不是 namenode 的冗余守护进程,而是提供周期检查点和清理任务。出于对可扩展性和容错性等考虑,我们一般将SecondaryNameNode运行在一台非NameNode的机器上。
- Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。就想NameNode一样,每个集群都有一个SecondaryNameNode,并且部署在一个单独的服务器上。SecondaryNameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的快照。由于NameNode是单点的,通过SecondaryNameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,SecondaryNameNode可以及时地作为备用NameNode使用。

-
- 过程解释:
- 1.NameNode管理着元数据信息,元数据信息会定期的刷到磁盘中,其中的两个文件是edits即操作日志文件和fsimage即元数据镜像文件,新的操作日志不会立即与fsimage进行合并,也不会刷到NameNode的内存中,而是会先写到edits中(因为合并需要消耗大量的资源)。当edits文件的大小达到一个临界值(默认是64MB)或者间隔一段时间(默认是1小时)的时候checkpoint会触发SecondaryNameNode进行工作。
- 2.当触发一个checkpoint操作时,NameNode会生成一个新的edits即上图中的edits.new文件,同时SecondaryNameNode会将edits文件和fsimage复制到本地。
- 3.SecondaryNameNode将本地的fsimage文件加载到内存中,然后再与edits文件进行合并生成一个新的fsimage文件即上图中的Fsimage.ckpt文件。
- 4.SecondaryNameNode将新生成的Fsimage.ckpt文件复制到NameNode节点。
- 5.在NameNode结点的edits.new文件和Fsimage.ckpt文件会替换掉原来的edits文件和fsimage文件,至此,刚好是一个轮回即在NameNode中又是edits和fsimage文件了。
- 6.等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
- 过程解释:
- 3. DataNode
- 它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode 守护进程。
- Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
- 集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个 数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通 信,并且对相关的数据块进行读/写操作。
- 4.NodeManager(NM)
- 是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点包括与ResourceManger保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)
- 5.ResourceManager
- ?在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)RM与每个节点的NodeManagers (NMs)和每个应用的ApplicationMasters (AMs)一起工作。
- a.NodeManagers 遵循来自ResourceManager的指令来管理单一节点上的可用资源。
- b.ApplicationMasters负责与ResourceManager协商资源与NodeManagers合作启动容器
- ?在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)RM与每个节点的NodeManagers (NMs)和每个应用的ApplicationMasters (AMs)一起工作。