在分布式服务普及的今天,分布式事务也有了自己的一席之地,虽然使用的场景比较少,但是技术可以不用,却不能不会用。今天来讲一讲分布式解决方案中的佼佼者:Seata
分布式事务的概念就不过多赘述了,其实就是为了解决分布式服务中如何保证事务的一致性。常见的分布式事务的解决方案TCC、Saga、XA等Seata都进行了支持,但是接下来我们还是主要讲一下Seata中的AT模式(毕竟官网中篇幅最多的就是这个模式,整个博客的内容都可以在seata官网找到更具体的描述,建议有兴趣的同学去官网学习一下:https://seata.io/zh-cn/docs/overview/what-is-seata.html)
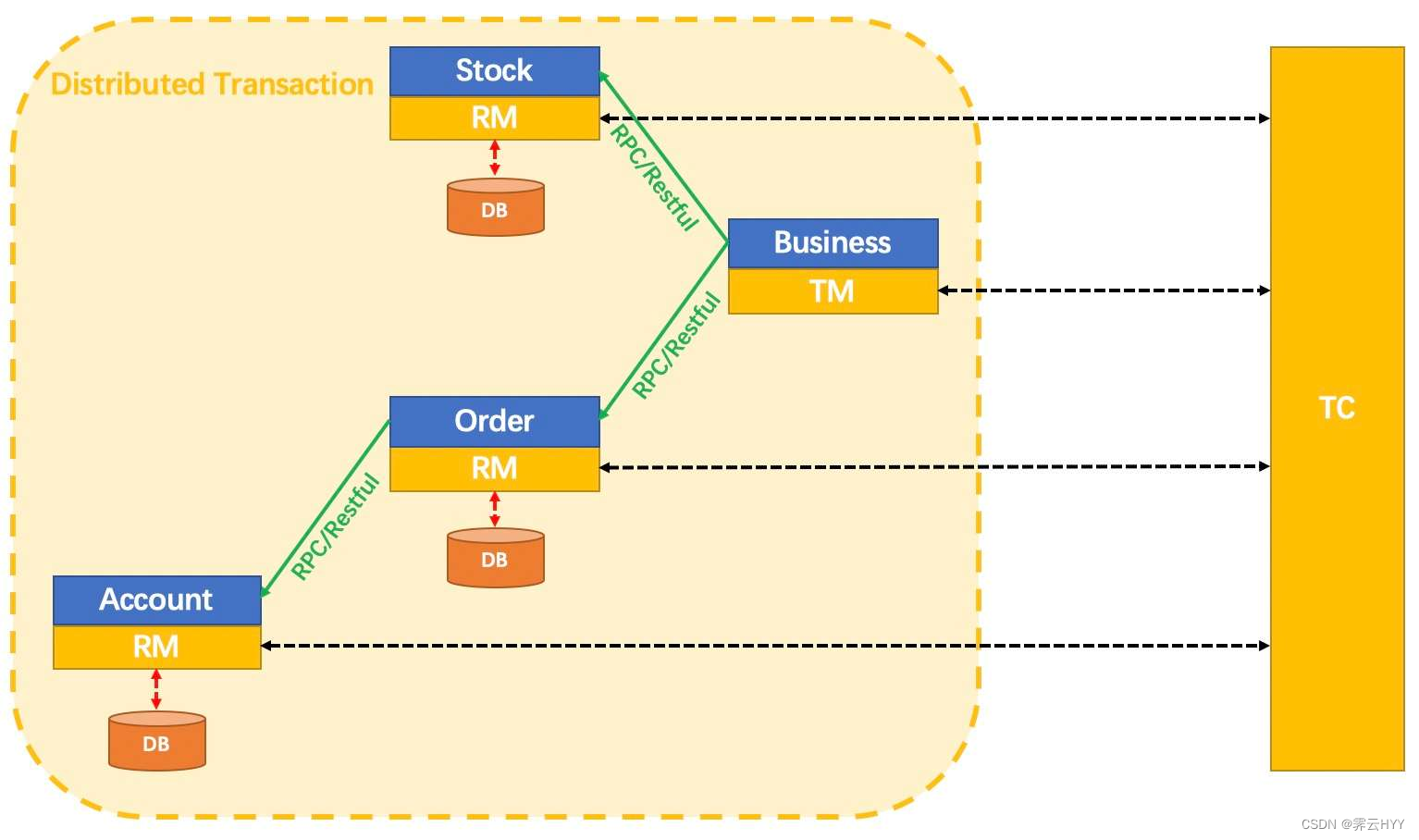
首先看一下官网的示例图,图中有三个不同的角色,分别是TC、TM和RM,官网的术语解释是:
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
如果以示例图中的流程来描述一个完整的seata分布式事务的话,大概分为下面几步:
- 首先Business服务向TC注册一个全局事务,然后TC会生成一个XID,返回给TM
- Business会分别调用Stock和Order服务,XID会分别传递给两个服务
- Stock和Order服务得到XID后,访问TC注册分支事务,并从TC获得事务ID,通过XID将分支事务与全局事务关联
- 服务执行SQL的时候,会将当前的数据保存一份回滚快照落入数据库中,同时执行后的数据也会保存一份。如果SQL执行没有问题的话,执行后的数据将会提交事务,并通知TC分支事务成功,如果失败的话,会清除服务的本地事务
- Order服务调用Account服务的时候,也是一样的执行链路
- 当所有的服务都成功调用时,Business会通过TM通知TC全局事务成功,RM就清除掉之前保存的回滚快照,如果失败了的话,就会将之前的回滚快照取出进行恢复
如果上面的流程看不懂的话,我可以举个例子:
- 你的好兄弟A打算和女朋友求婚了,于是他安排了一个惊喜,打算给女朋友搞个求婚仪式;他是整个活动的组织人也就是TC这个角色
- 然后A找到了另外两个好兄弟B和C,外加女朋友的好闺蜜D一起来实施这个计划,首先B跟A说,兄弟我去给你买些鲜花吧,咱别弄那么寒酸(此时就相当于B向A注册了一个全局事务,也就是TM)
- 当B完成了采购了工作,然后B采购完了通知A说东西都买齐了(这个时候相当于RM完成了自己的工作,并通知TC当前的分支事务已经完成了),接着B又跟C说你去布置一下吧,咱们准备一个好一点环境烘托一下气氛(分布式事务之间的互相调用)
- 之后C也完成了自己的工作,并且跟B一样通知到了A(同样要通知TC自己完成了分支事务),然后C通知D说,万事俱备只欠东风了,咱们把女主角请来吧,你找个理由把她带来咱们就可以开始让A求婚了
- D于是去找A的女朋友,但是却发现她有说有笑的上了另外一个男人的车,于是D把这个不幸的消息通知到了A(通知TC事务执行失败了),于是A只能通知他的好兄弟B和C把东西都收拾干净了,求婚取消了,各回各家,各找各妈(事务回滚)
反正大概就是这么个意思了,TC负责掌管全局的事务,TM是事务的发起者,由TM调用到的链路,都会在一个全局事务中,每个分支事务又由不同的RM的管理,并且都会和TC进行交互,最后由TM通知TC到底是成功还是失败决定RM是提交事务还是进行回滚
再描述一些官网中提到的细节
- 写隔离:在seata中,不同的事务是需要获得全局锁才能执行自己的本地事务
例如服务A优先获取全局锁,然后执行本地事务,后面的服务B只有在服务A执行完成,释放全局锁之后,才能尝试去获取全局锁并执行自己的本地事务;如果B执行失败了,也需要等到B释放全局锁之后,服务A获取锁再进行回滚操作,这么做的目的就是为了防止脏写 - 读隔离:AT模式默认的隔离级别是RU(Read Uncommitted)读未提交,如果要更严格一些,实现RC(Read Committed)读已提交的话,seata通过SELECT FOR UPDATE 语句做了代理,通过这种方式获取了全局锁,保证不会读到事务未提交的数据
接下来我们讲一下seata的工作机制(这部分官网描述的更加详细,我就简略摘录一下)
一阶段:
- 通过解析SQL得到当前的数据并记录下前镜像(当前数据库的数据)
- 执行业务SQL得到执行后的数据并记录下后镜像(执行SQL后数据库的数据)
- 把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表(这种表在使用AT模式时需要我们手动创建到我们的数据库中)中
- 提交前,向 TC 注册分支,申请一个修改的表记录的主键对应的那条记录的全局锁
- 业务数据的更新和前面步骤中生成的 UNDO LOG 一并提交,这一步是提交本地事务
- 将本地事务提交的结果上报给 TC
二阶段(回滚):
- 收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作
- 通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录
- 拿 UNDO LOG 中的后镜像与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理,请参考官方文档
- 根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息生成并执行回滚的语句
- 提交本地事务,并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC
二阶段(提交):
- 收到 TC 的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC
- 异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录
最后稍微提一下TCC和Saga事务
一般场景下AT模式就能覆盖到我们使用的场景了,而且简单易用,非常方便,但是如果在一个比较复杂的异构数据库场景下,比如你的数据库存储存储涉及到了多种不同的数据库MySQL、Oracle、HBASE、Redis等多个存储的话,AT模式可能就无能为力了,这种时候想要精准控制分布式事务的话就需要用到TCC,同样TCC的缺点也比较明显,就是工作量较大,逻辑较多,要分别写Try、Confirm、Cancel三套逻辑来进行处理
Saga模式的话主要是应对长事务,服务流程链路比较长的应用,或者是涉及到其他无法提供TCC三个接口的旧服务