����ѧϰ�ʼ�
Դ��Bվ�й�Ƚ�ʦ�κ쿵��MySQL�γ�
Bվ��ַ:https://www.bilibili.com/video/BV1iq4y1u7vj
������Щά�ȿ��Խ������ݿ����?����֮:
- ����ʧЧ��û�г�����õ������D�D��������
- ������ѯ̫��JOIN (���ȱ�ݻ��ѵ�����)��-SQL�Ż���
- ���������ż�������������(���塢�߳�����)�D�D����my.cnf
- ���ݹ���D�D�ֿ�ֱ�
�������ݿ���ŵ�֪ʶ��dz���ɢ����ͬ��DBMS,��ͬ�Ĺ�˾,��ͬ��ְλ,��ͬ����Ŀ���������ⶼ������ͬ���������Ƿ�Ϊ�����½ڽ���ϸ�½��⡣
��ȻSQL��ѯ�Ż��ļ����кܶ�,���Ǵ�������ȫ���Էֳ� ������ѯ�Ż� �� ����ѯ�Ż� ����顣
- ������ѯ�Ż���ͨ��
�����������ӷ�ʽ�ȼ����������Ż�,�����ص���Ҫ����������ʹ�á� - ����ѯ�Ż�����ͨ��SQL�ȼ۱任������ѯЧ��,ֱ��һ�����˵,��һ�ֲ�ѯд��ִ��Ч�ʿ��ܸ��ߡ�
1. ������
ѧԱ�� �� 50�� ��, �༶�� �� 1�� ��
�������ݿ�
CREATE DATABASE atguigudb2;
USE atguigudb2;
����1:����
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL , `name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
����2:����
- �����:����������������:
set global log_bin_trust_function_creators=1; # ����globalֻ�ǵ�ǰ������Ч��
����3:��������
��֤ÿ�����ݶ���ͬ��
#��������ַ���
DELIMITER //
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#����Ҫɾ��
#drop function rand_string;
��������༶���
#��������������ٵ����ٵı��
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT)
RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1));
RETURN i;
END //
DELIMITER ;
#����Ҫɾ��
#drop function rand_num;
����4:�����洢����
#������stu���в������ݵĴ洢����
DELIMITER //
CREATE PROCEDURE insert_stu( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #�����ֶ��ύ����
REPEAT #ѭ��
SET i = i + 1; #��ֵ
INSERT INTO student (stuno, name ,age ,classId ) VALUES ((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num END REPEAT;
COMMIT; #�ύ����
END //
DELIMITER ;
#����Ҫɾ��
#drop PROCEDURE insert_stu;
������class���в������ݵĴ洢����
#ִ�д洢����,��class�������������
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor) VALUES (rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#����Ҫɾ��
#drop PROCEDURE insert_class;
����5:���ô洢����
class
#ִ�д洢����,��class������1��������
CALL insert_class(10000);
stu
#ִ�д洢����,��stu������50��������
CALL insert_stu(100000,500000);
����6:ɾ��ij���ϵ�����
�����洢����
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>'PRIMARY' ;
#ÿ���α����ʹ�ò�ͬ��declare continue handler for not found set done=1�������α�Ľ���
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#��û�����ݷ���,�������,��������done��Ϊ2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
ִ�д洢����
CALL proc_drop_index("dbname","tablename");
2.1 ȫֵƥ�����
ϵͳ�о������ֵ�sql�������:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd' ;
��������ǰִ��:(��עִ��ʱ��)
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd ';
Empty set,1 warning (0.28 sec)
��������
CREATE INDEX idx_age ON student( age ) ;
CREATE INDEX idx_age_classid ON student( age , classId);
CREATE INDEX idx_age_classid_name ON student( age ,classId , name ) ;
����������ִ��:
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd ';
Empty set, 1 warning (0.01 sec)
���Կ���,��������ǰ�IJ�ѯʱ���� 0.28 ��,����������IJ�ѯʱ���� 0.01 ��,�����������Ǽ��������˲�ѯЧ�ʡ�
2.2 �����ǰ����
��MySQL������������ʱ�����������ǰƥ��ԭ��,����������,�ڼ�������ʱ����������������߿�ʼƥ�䡣
����1:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd' ;
����2:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student. name = 'abcd' ;
����3:����idx_age_classid_name���ܷ�����ʹ��?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE classid=4 AND student.age=30 AND student .name= 'abcd' ;
��������˶���,Ҫ��������ǰ����ָ���Dz�ѯ������������ǰ�п�ʼ���Ҳ����������е���;
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name =' abcd';

��Ȼ��������ʹ��,����ֻ�в��ֱ�ʹ�õ��ˡ�
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name =' abcd ' ;

��ȫû��ʹ����������
����:MySQL����Ϊ����ֶδ�������,һ������������16���ֶΡ����ڶ�������,��������Ҫʹ���������밴����������ʱ��˳��,��������,һ������ij���ֶ�,����������ֶζ�����ʹ�á� �����ѯ������û��ʹ����Щ�ֶ��е�1���ֶ�ʱ,����(������)�������ᱻʹ�á�
��չ:Alibaba��Java�����ֲᡷ
�����ļ����� B-Tree ������ǰƥ������,�����ߵ�ֵδȷ��,��ô��ʹ�ô�������
2.3 ��������˳��
����һ��ʹ��InnoDB�洢����ı���˵,������û����ʾ�Ĵ�������ʱ,���е�����ʵ���϶��Ǵ洢���۴�������Ҷ�ӽڵ�ġ�����¼�ִ洢������ҳ�е�,����ҳ�ͼ�¼���ǰ��ռ�¼����ֵ��С������˳���������,����������������ļ�¼������ֵ�����������Ļ�,������ÿ����һ������ҳ�ͻ�����һ������ҳ������,��������Dz��������ֵ��С�����Ļ�,����ܻ����ҳ���������¼��λ��
����ij������ҳ�洢�ļ�¼�Ѿ�����,���洢������ֵ�� 1~100 ֮��,
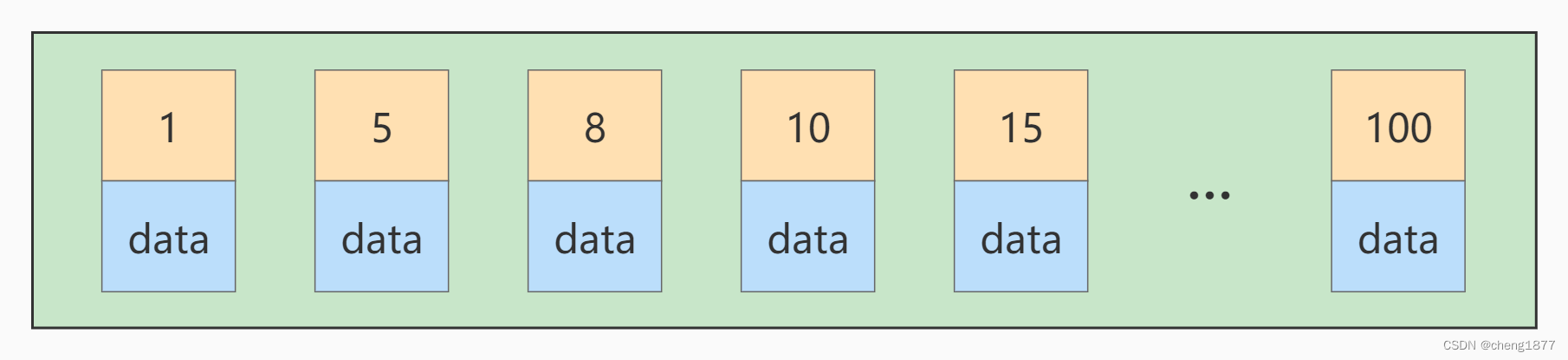
�����ʱ�ٲ���һ������ֵΪ 9 �ļ�¼,���������λ�þ�����ͼ:
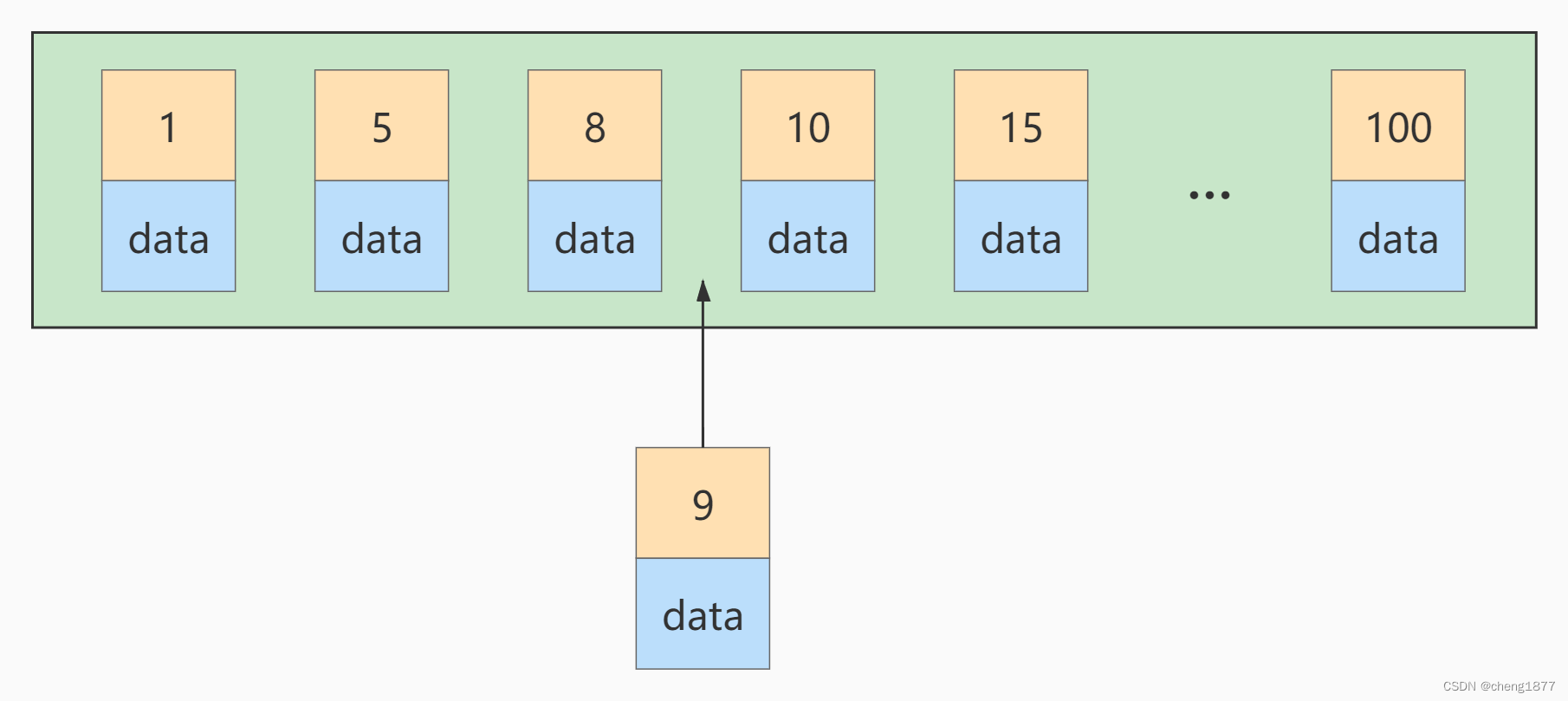
���������ҳ�Ѿ�����,�ٲ����զ����?������Ҫ�ѵ�ǰ ҳ����� ������ҳ��,�ѱ�ҳ�е�һЩ��¼�ƶ����´��������ҳ�С�ҳ����Ѻͼ�¼��λ��ζ��ʲô?��ζ��: ������� !������������뾡������������ν���������,����ò���ļ�¼�� ����ֵ���ε��� ,�����Ͳ��ᷢ����������������ˡ��������ǽ���:���������� AUTO_INCREMENT ,�ô洢�����Լ�Ϊ����������,�����������ֶ����� ��
����: person_info ��:
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);
�����Զ���������� id ӵ�� AUTO_INCREMENT ����,�ڲ����¼ʱ�洢������Զ�Ϊ������������������ֵ������������ռ�ÿռ�С,˳��д��,����ҳ���ѡ�
2.4 ���㡢����������ת��(�Զ����ֶ�)��������ʧЧ
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
��������
CREATE INDEX idx_name ON student(NAME);
��һ��:�����Ż���Ч
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';

SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
mysql> SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
+--------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+--------+--------+--------+------+---------+
| 438056 | 538056 | ABcHeB | 20 | 321 |
| 150883 | 250883 | abciJU | 21 | 388 |
| 171122 | 271122 | aBCiju | 21 | 924 |
| 237412 | 337412 | ABcIjW | 7 | 825 |
| 354085 | 454085 | aBCikB | 3 | 661 |
| 482399 | 582399 | ABcJlg | 48 | 386 |
| 488710 | 588710 | ABcJlg | 46 | 221 |
| 255517 | 355517 | aBCjmI | 33 | 190 |
| 389862 | 489862 | AbCJMI | 6 | 514 |
| 95480 | 195480 | ABcJnm | 21 | 364 |
| 474364 | 574364 | ABcJno | 30 | 141 |
| 25447 | 125447 | AbCJPW | 15 | 628 |
| 410171 | 510171 | ABcKqA | 29 | 334 |
| 440453 | 540453 | aBCkqb | 10 | 824 |
| 150817 | 250817 | AbCKQY | 23 | 326 |
| 348398 | 448398 | ABcKsK | 22 | 14 |
| 470809 | 570809 | AbCKTm | 30 | 225 |
| 248457 | 348457 | aBClvu | 37 | 490 |
| 388252 | 488252 | abclWZ | 7 | 721 |
| 162414 | 262414 | AbCLXC | 47 | 988 |
| 1158 | 101158 | abclYh | 40 | 524 |
+--------+--------+--------+------+---------+
21 rows in set, 1 warning (0.00 sec)
mysql> SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'ab%';
+--------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+--------+--------+--------+------+---------+
| 438056 | 538056 | ABcHeB | 20 | 321 |
| 150883 | 250883 | abciJU | 21 | 388 |
| 171122 | 271122 | aBCiju | 21 | 924 |
| 237412 | 337412 | ABcIjW | 7 | 825 |
| 354085 | 454085 | aBCikB | 3 | 661 |
| 482399 | 582399 | ABcJlg | 48 | 386 |
| 488710 | 588710 | ABcJlg | 46 | 221 |
| 255517 | 355517 | aBCjmI | 33 | 190 |
.......
| 351097 | 451097 | ABhfeg | 19 | 438 |
| 233473 | 333473 | ABhffj | 33 | 667 |
| 282412 | 382412 | abhFFj | 5 | 912 |
| 494189 | 594189 | aBHFfJ | 4 | 359 |
| 234145 | 334145 | AbJZgF | 35 | 668 |
| 346191 | 446191 | AbJZgH | 42 | 218 |
| 399207 | 499207 | AbJZgH | 45 | 450 |
| 63895 | 163895 | AbJZhK | 4 | 249 |
+--------+--------+--------+------+---------+
728 rows in set, 1 warning (0.01 sec)
typeΪ"range��,��ʾ��ʹ�õ�����,��ѯʱ���Ϊ0.01�롣
�ڶ���:�����Ż�ʧЧ
mysq1> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';

mysql> SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
+--------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+--------+--------+--------+------+---------+
| 1158 | 101158 | abclYh | 40 | 524 |
| 25447 | 125447 | AbCJPW | 15 | 628 |
| 95480 | 195480 | ABcJnm | 21 | 364 |
| 150817 | 250817 | AbCKQY | 23 | 326 |
| 150883 | 250883 | abciJU | 21 | 388 |
| 162414 | 262414 | AbCLXC | 47 | 988 |
| 171122 | 271122 | aBCiju | 21 | 924 |
| 237412 | 337412 | ABcIjW | 7 | 825 |
| 248457 | 348457 | aBClvu | 37 | 490 |
| 255517 | 355517 | aBCjmI | 33 | 190 |
| 348398 | 448398 | ABcKsK | 22 | 14 |
| 354085 | 454085 | aBCikB | 3 | 661 |
| 388252 | 488252 | abclWZ | 7 | 721 |
| 389862 | 489862 | AbCJMI | 6 | 514 |
| 410171 | 510171 | ABcKqA | 29 | 334 |
| 438056 | 538056 | ABcHeB | 20 | 321 |
| 440453 | 540453 | aBCkqb | 10 | 824 |
| 470809 | 570809 | AbCKTm | 30 | 225 |
| 474364 | 574364 | ABcJno | 30 | 141 |
| 482399 | 582399 | ABcJlg | 48 | 386 |
| 488710 | 588710 | ABcJlg | 46 | 221 |
+--------+--------+--------+------+---------+
21 rows in set, 1 warning (0.13 sec)
typeΪ��ALL��,��ʾû��ʹ�õ�����,��ѯʱ��Ϊ0.13��,��ѯЧ�ʽ�֮ǰ�ͺܶࡣ
�پ���:
- student�����ֶ�stuno������������
CREATE INDEX idx_sno ON student(stuno);
- �����Ż�ʧЧ:(����: student�����ֶ�stuno������������)
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 500001;
����:

EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 500000;

mysql> SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 500001;
+--------+--------+--------+
| id | stuno | NAME |
+--------+--------+--------+
| 400000 | 500000 | NohQJW |
+--------+--------+--------+
1 row in set, 1 warning (0.12 sec)
mysql> SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 500000;
+--------+--------+--------+
| id | stuno | NAME |
+--------+--------+--------+
| 400000 | 500000 | NohQJW |
+--------+--------+--------+
1 row in set, 1 warning (0.00 sec)
���ܿ�����������������˱���ʽ����,������ʧЧ�ˡ�������Ϊ������Ҫ�������ֶε�ȡֵ��ȡ����,Ȼ�����ν��б���ʽ�ļ��������������ж�,��˲��õľ��� ȫ��ɨ�� �ķ�ʽ,����ʱ��Ҳ�����ܶ�,��������ʱ��Ϊ 0.12 �롣
- �����Ż���Ч
SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 500000;
����ʱ��Ϊ 0.00 �롣
�پ���:
- student�����ֶ�name������������
CREATE INDEX idxlname ON student(NAME);
������Ҫ��name��ǰ��λΪabc�����ݽ�������ɸѡ,�����������鿴��ִ�мƻ�:
- �����Ż�ʧЧ
EXPLAIN SELECT id, stuno, name FROM student WHERE SUBSTRING( name, 1,3)='abc';

- �����Ż���Ч
EXPLAIN SELECT id, stuno, name FROM student WHERE `name` like 'abc%';

���ܿ���������ѯ��д��,����ʹ���������з�Χ����,�Ӷ�������ѯЧ�ʡ�
2.5����ת����������ʧЧ
�����ĸ�sql�������õ�������(����name�ֶ�������������)
#δʹ�õ�����
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;

#ʹ�õ�����
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';

- name=123��������ת��,����ʧЧ��
����:���ʵ��������ʱ,һ��Ҫ�����ݿ��ֶ��������Ӧ������,�ͻ��������ת���������
2.6��Χ�����ұߵ�������ʧЧ
- ���ϵͳ�������ֵ�sql����:
#ɾ������-�洢����
CALL proc_drop_index('atguigudb2', 'student')
#ɾ������-���ɾ��
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
ALTER TABLE student DROP INDEX idx_age_classid_name;
SHOW INDEX FROM student;
CREATE INDEX idx_age_classId_name oN student (age,classId,`name`);
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc';

2. ��ô���� idx_age_classid_name���������������ʹ��ô?
-
����,��Χ�ұߵ��в���ʹ�á�����:(<)(<=)(>)(>=)�� between �ȡ�
-
�������sql���ֽ϶�,Ӧ�ý���:
create index idx_age_name_classid on student(age, name, classid); -
������Χ��ѯ��������������:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abc' AND student.classId>20 ;

Ӧ�ÿ����з�Χ��ѯ,����:����ѯ,���ڲ�ѯ�������Ƿ�Χ��ѯ��Ӧ����ѯ��������where������(����������������,��ذѷ�Χ�漰�����ֶ�д�����)
2.7������(!= ����<>)����ʧЧ
- Ϊname�ֶδ�������
CREATE INDEX idx_name ON student(NAME);
- �鿴�����Ƿ�ʧЧ
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'abc' ;

����
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'abc' ;

��������:�û��������,����������,��Ʒ���������0�Ķ�ͳ�Ƴ�����
2.8 is null����ʹ������,is not null��ʹ������
- IS NULL:���Դ�������
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;

����:�����������ݱ���ʱ��ͽ�
�ֶ�����Ϊ NOT NULL Լ��,��������Խ�INT���͵��ֶ�,Ĭ��ֵ����Ϊ0�����ַ����͵�Ĭ��ֵ����Ϊ���ַ���(����)
��չ:ͬ��,�ڲ�ѯ��ʹ��
not likeҲ��ʹ������,����ȫ��ɨ��
2.9 like��ͨ���%��ͷ����ʧЧ
��ʹ��LIKE�ؼ��ֽ��в�ѯ�IJ�ѯ�����,���ƥ���ַ����ĵ�һ���ַ�Ϊ��%��,�����Ͳ��������á�ֻ�С�%�����ڵ�һ��λ��,�����Ż������á�
- ʹ�õ�����
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab%';

- δʹ�õ�����
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab%';

��չ:Alibaba��Java�����ֲᡷ
��ǿ�ơ�ҳ�������Ͻ���ģ������ȫģ��,�����Ҫ�������������������
2.10 ORǰ����ڷ���������,����ʧЧ
��WHERE�Ӿ���,�����ORǰ�������н���������,����OR���������û�н�������,��ô������ʧЧ��Ҳ����˵,ORǰ������������е��ж�������ʱ,��ѯ�в�ʹ��������
��ΪOR�ĺ����������ֻҪ����һ������,��� ֻ��һ�������н�����������û�������,ֻҪ��������û�н�������,�ͻ���� ȫ��ɨ��,���������������Ҳ��ʧЧ��
��ѯ���ʹ��OR�ؼ��ֵ����:
SHOW INDEX FROM student;
#ɾ��student����������
CALL proc_drop_index('atguigudb2','student');
#������������,������age�ֶ�
CREATE INDEX idx_age ON student(age);
#δʹ�õ�����
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

#��������,������classid�ֶ�
CREATE INDEX idx_cid ON student(classid);
#ʹ�õ�����
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

��Ϊage�ֶκ�classid�ֶ��϶�������,���Բ�ѯ��ʹ�������������ܿ�������ʹ�õ��� index_merge,����˵index_merge���Ƕ�age��classid�ֱ������ɨ��,Ȼ������������������˺ϲ����������ĺô����� ������ȫ��ɨ����
2.11 ���ݿ�ͱ����ַ���ͳһʹ��utf8mb4
ͳһʹ��utf8mb4( 5.5.3�汾����֧��)�����Ը���,ͳһ�ַ������Ա��������ַ���ת�����������롣��ͬ���ַ������бȽ�ǰ��Ҫ����ת�����������ʧЧ��
2.12��ϰ��һ���Խ���
��ϰ: ����: index(a,b,c)
| Where��� | �����Ƿ�ʹ�� |
|---|---|
| where a= 3 | Y,ʹ�õ�a |
| where a= 3 and b=5 | Y,ʹ�õ�a, b |
| where a= 3 and b=5 and c=4 | Y,ʹ�õ�a,b,c |
| where b= 3 ���� where b=3 and c= 4 ���� where c= 4 | N |
| where a= 3 and c=5 | ʹ�õ�a,����c������, b�м���� |
| where a= 3 and b>4 and c=5 | ʹ�õ�a��b,c�������ڷ�Χ֮��, b���� |
| where a is null and b is not null | is null֧����������is not null��֧�֡� ����a����ʹ������, ����b������ʹ�� |
| where a <> 3 | ����ʹ������ |
| where abs(a)=3 | ����ʹ������ |
where a=3 and b like 'kk%' and c =4 | Y,ʹ�õ�a,b,c |
| where a=3 and b like ��%kk�� and c=4 | Y,ֻ�õ�a |
| where a=3 and b like ��%kk%�� and c=4 | Y,ֻ�õ�a |
where a=3 and b like 'k%kk%' and c=4 | Y,ʹ�õ�a,b,c |
һ���Խ���:
- ���ڵ�������,����ѡ����Ե�ǰquery�����Ը��õ�������
- ��ѡ�����������ʱ��,��ǰquery�й�������õ��ֶ�������|�ֶ�˳����,λ��Խ��ǰԽ�á�
- ��ѡ�����������ʱ��,����ѡ���ܹ�������ǰquery�е�where�Ӿ��и����ֶε�������
- ��ѡ�����������ʱ��,���ij���ֶο��ܳ��ַ�Χ��ѯʱ,����������ֶη����������������档
��֮,��дSQL���ʱ,���������������ʧЧ�������