目录
流处理流程

Environment
getExecutionEnvironment
创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就是说,getExecutionEnvironment会根据查询运行的方法决定返回什么样的运行环境,是常用的一种创建执行环境的方式。
//创建一个执行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment如果没有设置并行度,会以 flink-conf.yaml 中的配置为准,默认是 1

?Source
从集合读取数据
测试代码
package com.atguigu.apitest
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import java.util.Properties
//
case class SensorReading( id: String, timestamp: Long, temperature: Double)
object SourceTest {
def main(args: Array[String]): Unit = {
//创建一个执行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment
//从集合中获取数据
val dataList = List(
SensorReading("sensor_1", 1547718199, 35.8),
SensorReading("sensor_6", 1547718201, 15.4),
SensorReading("sensor_7", 1547718202, 6.7),
SensorReading("sensor_10", 1547718205, 38.1)
)
val stream1=env.fromCollection(dataList)
//打印输出
stream1.print()
//执行
env.execute("source test")
}
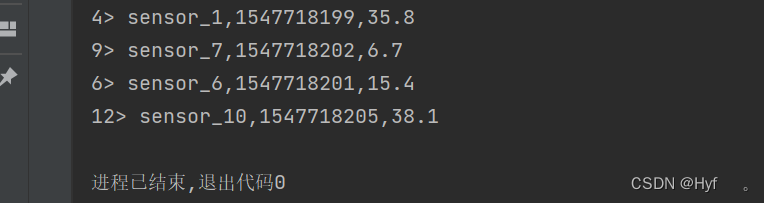
}测试结果?

从文件读取数据
测试代码
package com.atguigu.wc
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
//创建一个批处理的执行环境
val env:ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据
val inputPath = "D:\\HYF\\FlinkTutorial\\src\\main\\resources\\sensor.txt"
val stream2 = env.readTextFile(inputPath)
//打印输出
stream2.print()
//执行
env.execute("source test")
}
}
测试结果
以Kafka消息队列的数据作为来源
需要pom.xml文件中引入 kafka 连接器的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>测试环境
1、先打开zookeeper
2、再打开Kafka
3、jpsall查看是否启动成功
4、先完全关闭Kafka才能关闭zookeeper
测试代码
package com.atguigu.apitest
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import java.util.Properties
case class SensorReading( id: String, timestamp: Long, temperature: Double)
object SourceTest {
def main(args: Array[String]): Unit = {
//创建一个执行环境
val env=StreamExecutionEnvironment.getExecutionEnvironment
//从集合中获取数据
val dataList = List(
SensorReading("sensor_1", 1547718199, 35.8),
SensorReading("sensor_6", 1547718201, 15.4),
SensorReading("sensor_7", 1547718202, 6.7),
SensorReading("sensor_10", 1547718205, 38.1)
)
val stream1=env.fromCollection(dataList)
//打印输出
//stream1.print()
//从文件中读取数据
val inputPath = "D:\\HYF\\FlinkTutorial\\src\\main\\resources\\sensor.txt"
val stream2 = env.readTextFile(inputPath)
//打印输出
//stream2.print()
//从kafka读取数据
val properties = new Properties()
properties.setProperty("bootstrap.servers","hadoop102:9092")
properties.setProperty("group.id","consumer-group")
val stream3 = env.addSource( new FlinkKafkaConsumer011[String]("sensor",new
SimpleStringSchema(),properties) )
stream3.print()
//执行
env.execute("source test")
}
}
测试结果