昨天碰到一个客户的测试环境HBase启动异常,表面的现象是从CDH界面里面看不到HMaster的主备状态,显示Master一直处于初始化的状态,通过hbcheck命令执行返回错误信息为:org.apache.haoop.hbase.PleaseHoldException: Master is initializing…
由于是HMaster异常,所以先到/var/log/hbase目录下查看Master的日志,报错如下所示:
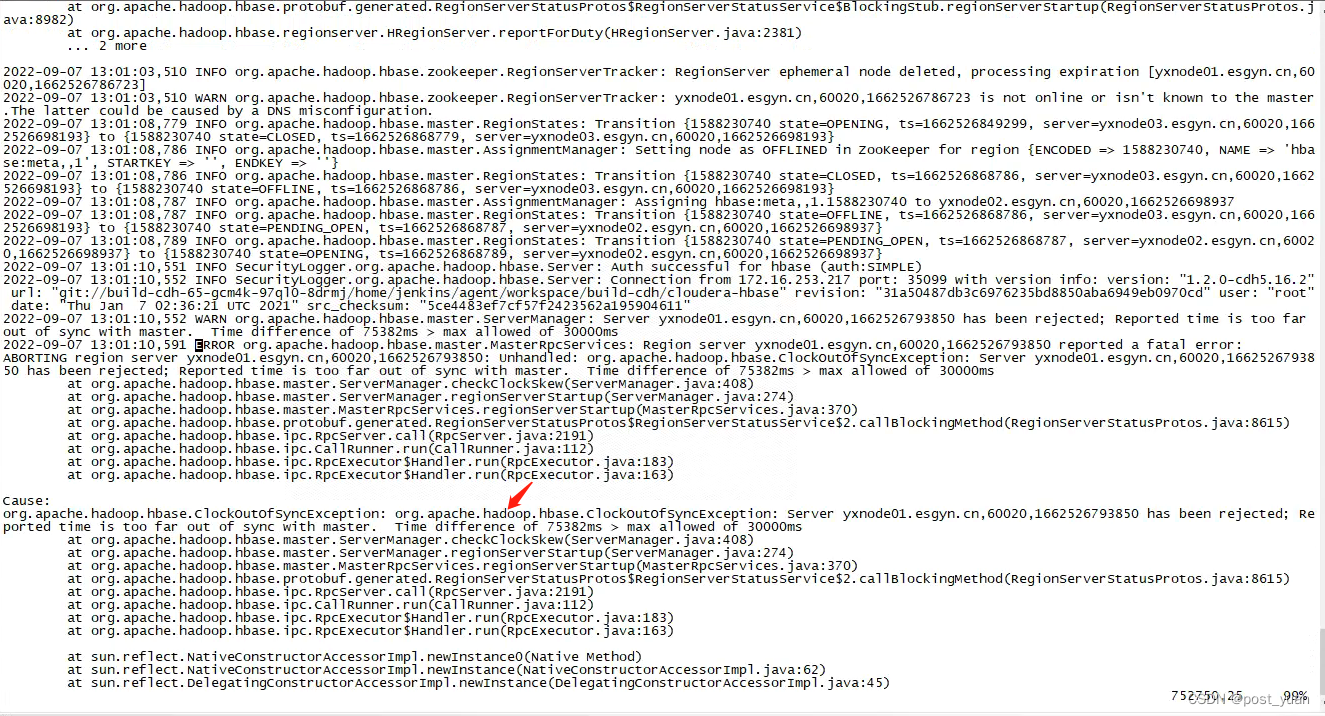
错误信息:Reported time is too far out of sync with master,说明时钟同步出现问题,于是检查每个节点的时钟同步情况,发现当前的时钟同步是正常的。怀疑是这个环境之前是不是发生过比较严重的时钟问题,比如突然修改了系统时钟或时区,导致节点上突然发生了很大的时间更改。
但不管怎么样,我们还是先看看如何解决这个问题吧~

于是又继续查看日志(如上图),发现日志中报大量WARN信息:Found a log (hdfs://nameservice1/hbase/oldWALs/xxx) new than current time, probably a clock skew。通过"Found a log"此关键搜索了一下所有Master日志文件,日志都指向是oldWALs下面的文件。
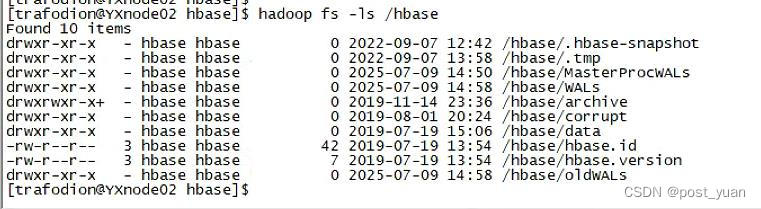
于是去检查hbase下面的oldWALs这个路径,发现这个目录的时间确实相差很大。从以下截图可以看到,/hbase/oldWALs目录的时间居然是2025-07-09,还有/hbase/MasterProcWALs和/hbase/WALs目录。这说明这个环境确实在时钟上发生了巨大的变化。
hadoop fs -ls /hbase
由于oldWAL文件是可以被删除的,因为当时决定删除oldWALs下面的所有日志并尝试重启HBase。(当时没有仔细看每个目录的时间,只是根据日志提示认为oldWALs目录有问题,所以没有想起来删除/hbase/MasterProcWALs和/hbase/WALs目录下面的东西)
hadoop fs -rmr hdfs://nameservice1/hbase/oldWALs

删除oldWALs之后重启HBase,发现HBase仍然启动异常。查看HBase日志,发现有如下报错:org.apache.hadoop.hbase.io.hfile.CorruptHFileException: Problem reading HFile Trailer from hdfs://nameservice1/hbase/meta/xxx/info/xxx
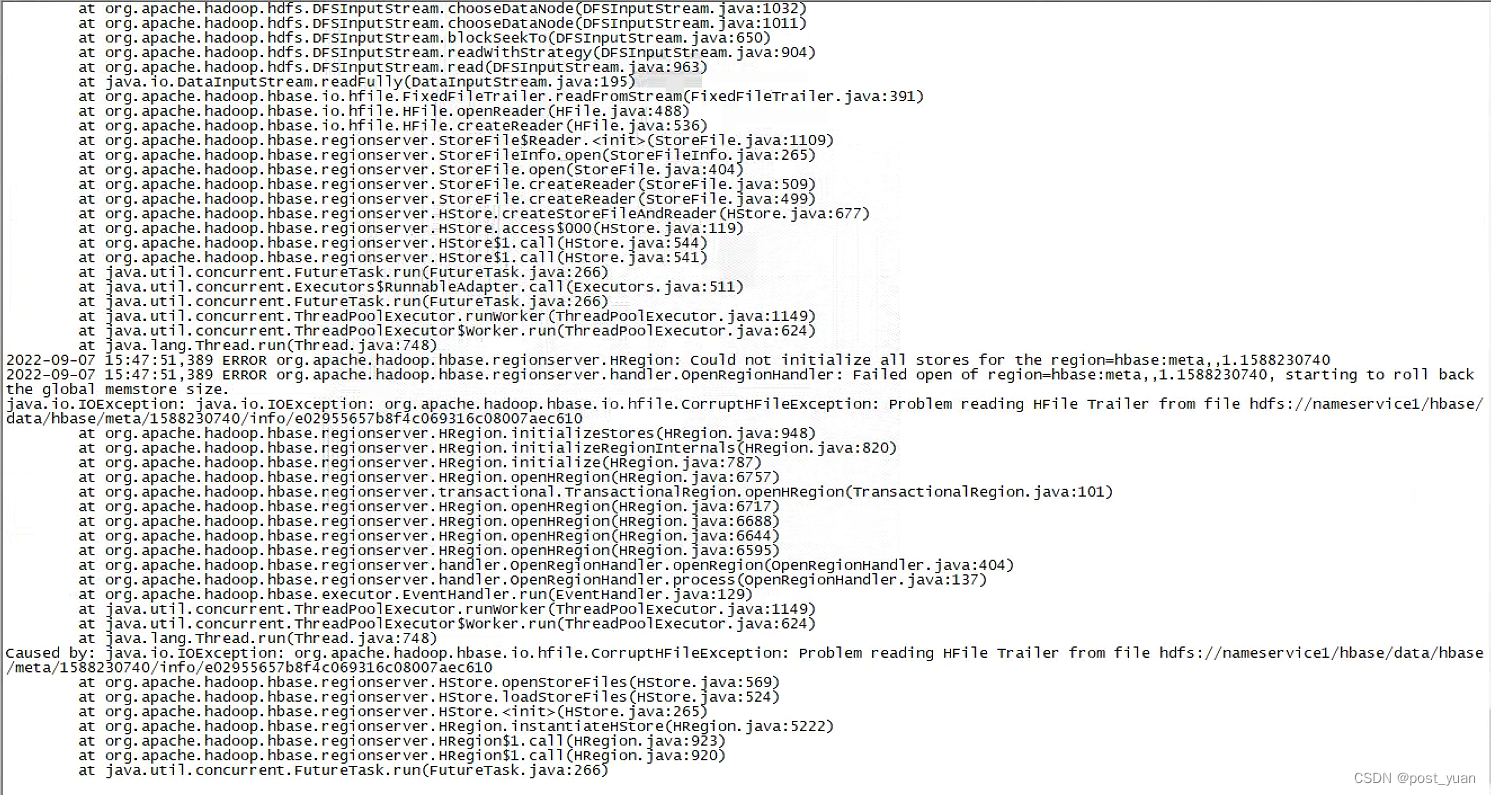
根据以上报错信息,怀疑可能是HBase meta表的数据文件发生了损坏,我们使用以下命令也单独验证了这一点:
hdfs fsck /hbase/data/hbase/meta/1588230740/info/e029xxx
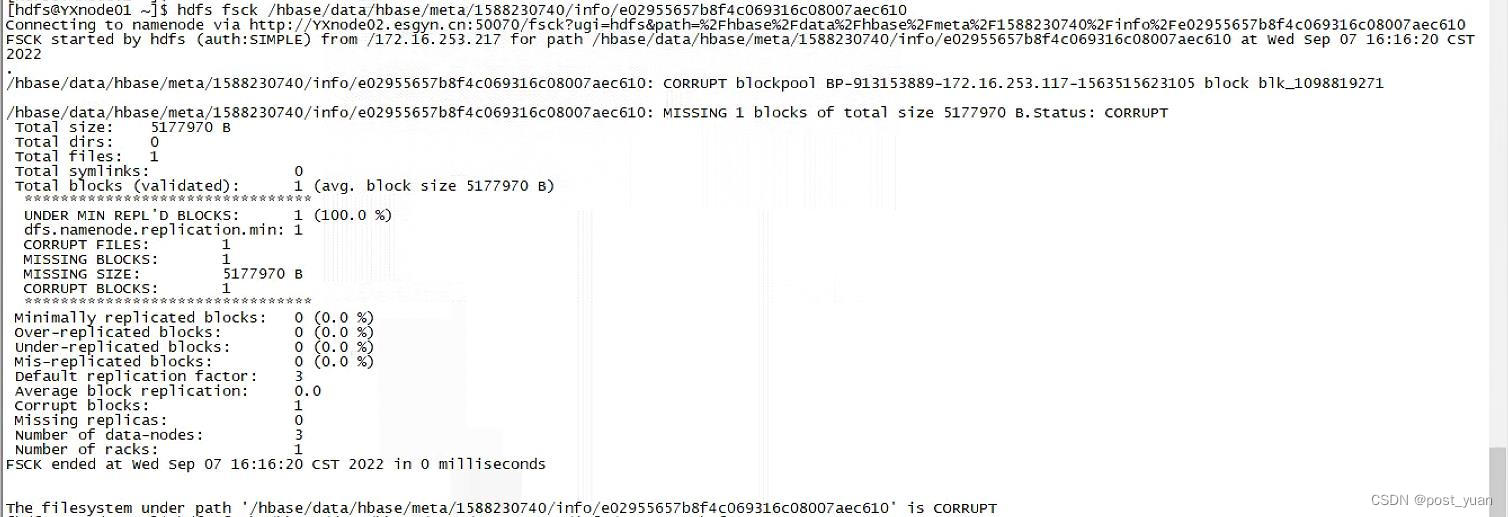
根据此报错现象,找到一篇类似问题的解决方案,见https://forum.huawei.com/enterprise/zh/thread-870917.html,文中描述的方法大概思路就是把meta表的相关文件备份移走,然后通过hbase hbck -repair的方式来重新生成meta数据。关键的步骤如下:
1. 停止HBase
2. 备份meta目录
hdfs dfs -mv /user/hbase /user/hbase_bak
hdfs dfs -mkdir /user/hbase
hdfs dfs -mv /hbase/data/hbase/namespace /user/hbase/namespace
hdfs dfs -mv /hbase/data/hbase/meta /user/hbase/meta
3. 启动HBase
4. 修复meta数据
hbase hbck -repair
以操作完上述步骤后,我发现HBase现在可以启动成功了,但是HBase中的部分表依然存在问题,比如我发现有一个TRAFODION的元数据表使用list可以看到表,但scan又查看不到。

这一现象表明某些HBase表的元数据信息仍然存在不一致的问题。于是我使用hbck做了一遍整体的检查。
sudo -u hbase hbase hbck
以下命令返回出现有25个不一致的对象,上面看到TRAFODION._MD_.TEXT就是其中一个。
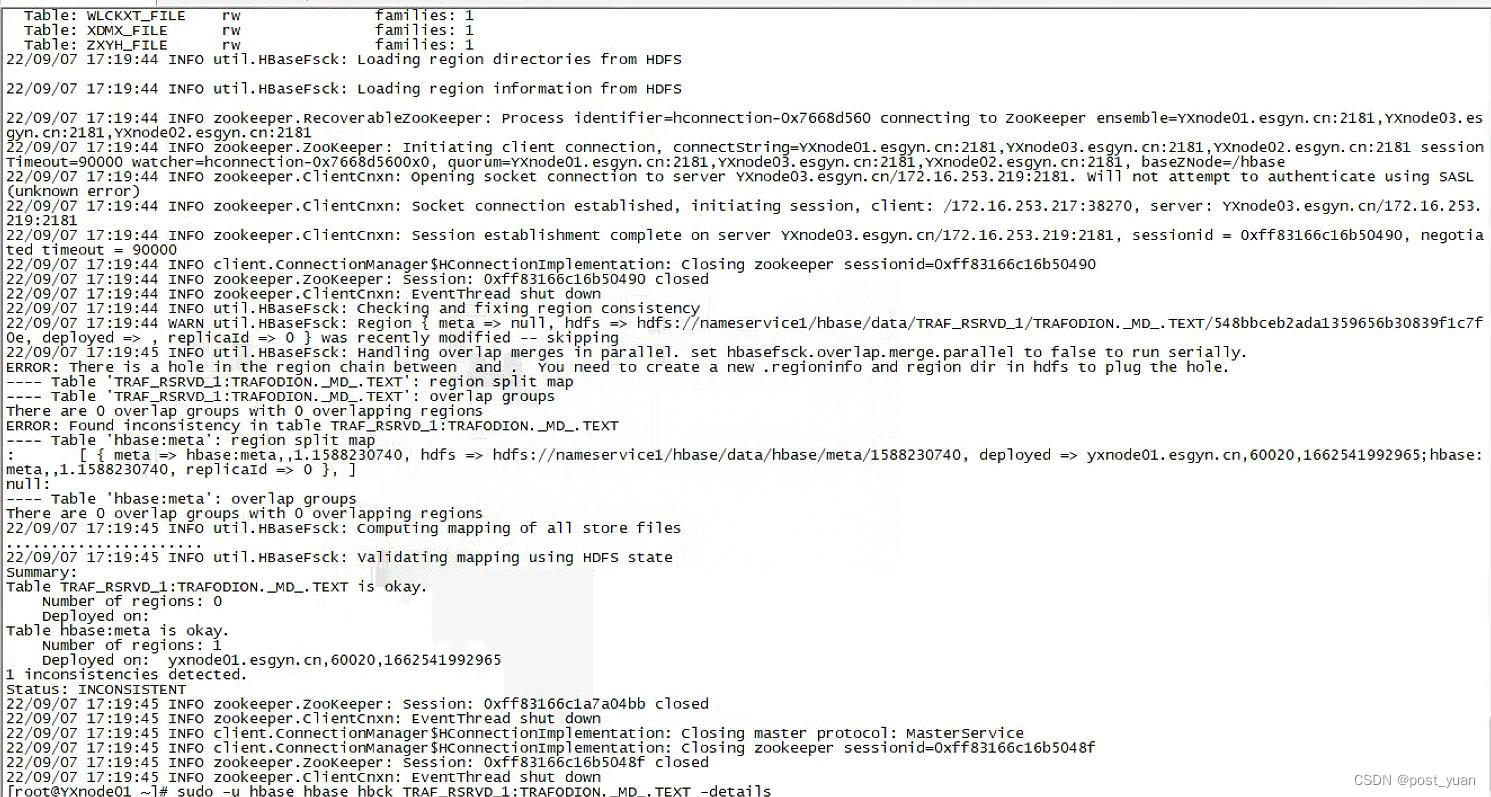
那么针对这种hbck出来有不一致的问题应该怎么解决呢?想到的方法自然是使用hbck的修复命令。 hbck提供了不同的参数用来解决HBase region处于RIT或无法正常上线的情况,网上关于hbck的贴子也有很多,比如https://bbs.huaweicloud.com/blogs/353332。
针对我这里遇到的问题,我几乎把hbase hbck的相关修复参数都用了一遍,包括-repair、-fixMeta、-fixAssignments,都没有起效果。
于是又仔细看了一下hbck的报错信息:Region {Meta => null, hdfs => hdfs://nameservice1/hbase/data/TRAF_RSRVD_1/TRAFODION._MD_.TEXT/xxx, deployed => , replicaId => 0} was recently modified
ERROR: There is a hole in the region chain between and . You need to create a new .regioninfo and region dir in hdfs to plug the hole.
网上查了不少文章,说这个报错要么是缺少.regioninfo,要么是缺少meta信息。我去hdfs这个表对应的目录下面查看发现.regioninfo文件是存在的,但meta表中确实没有相关信息,既然是这样情况,那理论上通过-fixMeta应该就可以修复Meta数据,但是实际上执行-fixMeta后并没有实际的效果。
于是我试图利用路径中的Region名称,即548bbceb2ada1359656b30939f1c7f0e尝试去assign使其上线,但assign命令提示此region不存在。
因此我怀疑可能是.regioninfo信息不对了,索性我就把.regioninfo文件移走,然后重新使用hbck -repair来修复生成.regioninfo文件。
hadoop fs -mkdir /user/hbase/548bbceb2ada1359656b30939f1c7f0e
hadoop fs -mv /hbase/data/TRAF_RSRVD_1/TRAFODION.\_MD\_.TEXT/548bbceb2ada1359656b30939f1c7f0e/.regioninfo /user/hbase/548bbceb2ada1359656b30939f1c7f0e
sudo -u hbase hbase hbck -repair TRAF_RSRVD_1:TRAFODION.\_MD\_.TEXT
经过上述一波操作之后,这个表对应的不一致问题居然解决了。使用同样的方法,依次对其余的24个对象使用-repair方式也修复了问题。
至些,这个HBase启动的问题算是彻底修复了,虽然,但是,关于最后的.regioninfo为什么会有问题以及是什么问题,为什么不删除.regioninfo后再-repair就可以修复,这里面的一些细节问题我还没有研究清楚。不管怎样,先记录下来这次的恢复历程吧,后面有时间再来细究。