一、大数据、Hadoop、Hbase介绍
1.1. 数据与信息
1.1.1. 数据
数据(data)是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的的原始素材。可以是符号、文字、数字、语音、图像、视频等
1.1.2. 信息
信息,指音讯、消息、通讯系统传输和处理的对象,泛指人类社会传播的一切内容。人通过获得、识别自然界和社会的不同信息来区别不同事物,得以认识和改造世界。
1.1.3. 两者的关系
数据经过处理后变成信息。
1.1.4.数据库
相关数据有组织的集合
1.2. 数据模型
1.2.1. 分层模型
树形结构存储
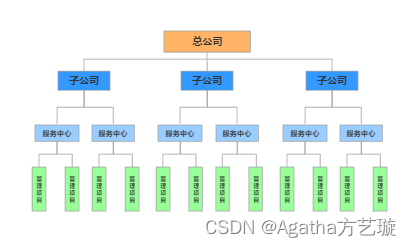
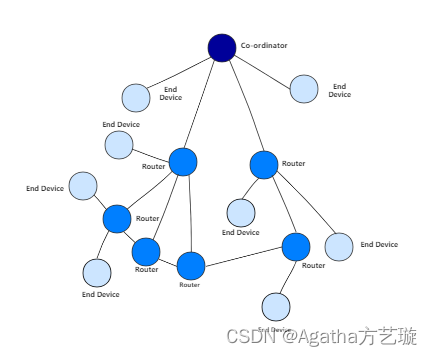
1.2.2. 网络模型
网络结构存储
1.2.3. 关系模型
表格形式存储

1.3. 数据结构
1.3.1. 结构化数据
可定义,有类型、格式、结构约束,如:RDBMS
1.3.2. 半结构化数据
有一定的格式约束但是不全,如: csv,xml,json,html文件,拥有开标签闭标签
1.3.3. 准结构化数据
如: 运行日志,流数据
1.3.4. 非结构化数据
没有规律可言很复杂,如:视频,音频,PDF文件,ppt文件,图片,邮件等;
1.4. 大数据5v特征
大量,多样,高速,价值密度低,准确不高
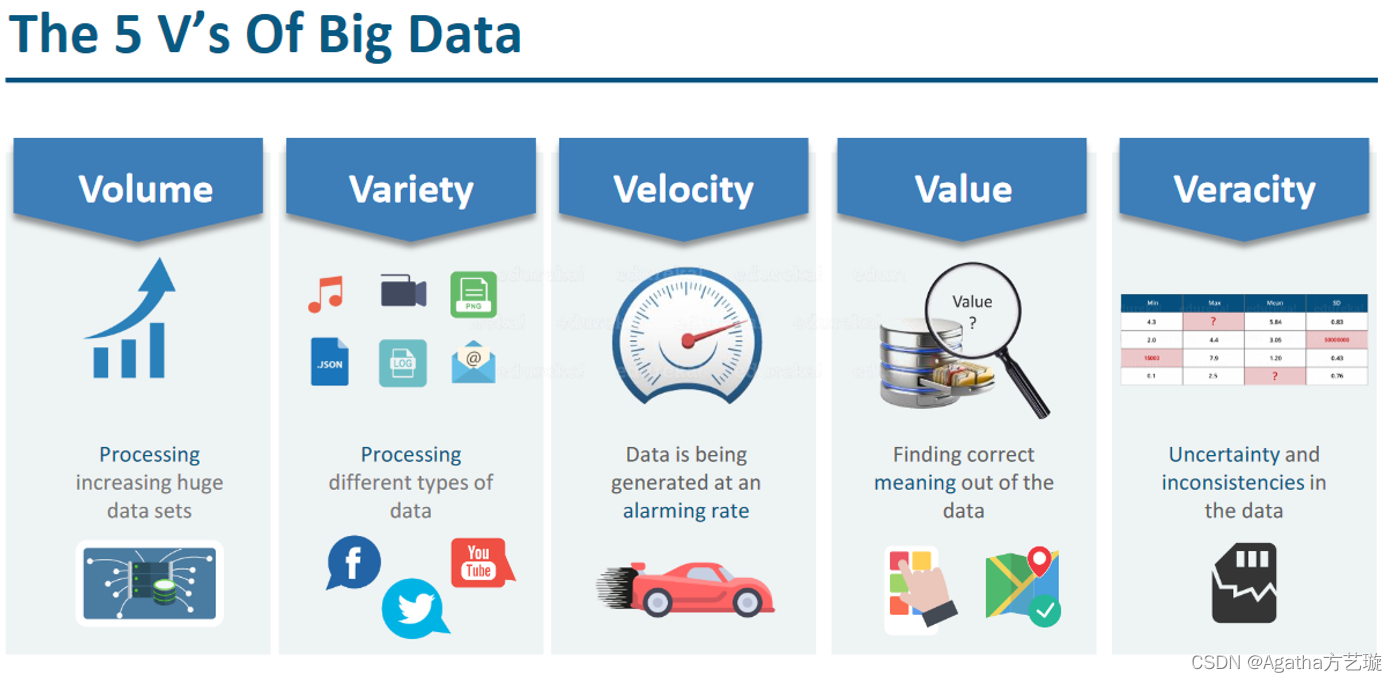
1.4.1. Volume 大量:
数据量大,包括采集、存储和计算的量都非常大。
1.4.2. Variety 多样:
种类和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
1.4.3. Value 价值密度低:
数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵。随着互联网以及物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题。
1.4.4. Velocity 速度快:
数据增长速度快,处理速度也快,时效性要求高。比如搜索引擎要求几分钟前的新闻能够被用户查询到,个性化推荐算法尽可能要求实时完成推荐。这是大数据区别于传统数据挖掘的显著特征。
1.4.5. Veracity 准确率不高:
数据的准确性和可信赖度,即数据的质量。数据不一定完整,有一定缺陷
1.5. RDBMS的数据处理限制
1.5.1. RDBMS限制
一台计算机不可能无限制提高配置,只能有限的进行垂直扩展提升配置,当数据量超过最高配置承受能力之后,此时传统数据库如Mysql,Oracle,等无法进行数据管理和处理,数据就成为大数据。大数据没有规定起点和终点具体是多大,只要超过传统数据库的处理范围就是大数据。此时只能使用大数据的处理方法。
1.5.2. RDBMS限制解决方法
1.5.2.1
当一台机器处理能力饱和后我们可以根据数据量大小和处理需求加入一定数量的计算机进行水平扩展能力,此时所有的计算机组合在一起共同工作就叫做分布式文件系统。
1.5.2.2
使用大数据工具,比如说Hadoop,Hbase,Spark,Hive…
1.6. Hadoop介绍
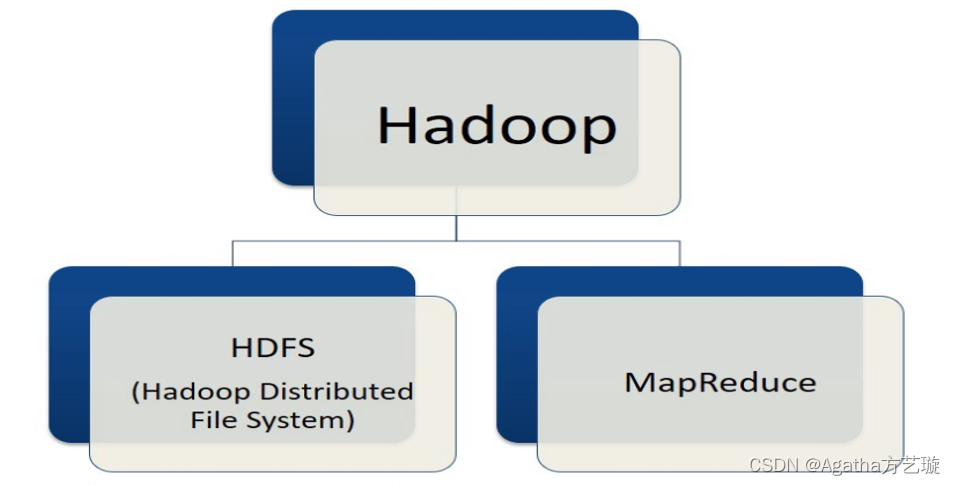
1.6.1.框架
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
HDFS:分布式文件系统,用于存储数据
MapReduce:用于处理数据
Yarn:用于资源管理
1.7. Hbase介绍
1.7.1. Hbase特点
?HBase是建立在Hadoop文件系统之上的面向列的分布式数据库。
?这是一个开源项目。
?它是水平可伸缩的。
?HBase是一种数据模型,类似于Google的大表,旨在提供对大量结构化数据的快速随机访问。
?非关系型的。
?它是分布式数据库。
?是稀疏矩阵
1.7.2. Nosql类型
?基于键值对存储: Apache Cassandra, Redis,
?基于文件存储: MongoDB, Couchbase Server
?基于列存储:MariaDB,Apache HBase
?基于图像存储:ArangoDB,Neo4j