一、背景
最近遇到了一个问题,我们的项目启动非常慢,其他团队发个服务,几分钟全部搞定,我们发个服务至少要半个小时,效率极其低下。
经过排查,发现是慢在了sharding-jdbc加载表元数据这个环节,我们的项目有大几千张表,整个元数据加载过程就非常缓慢。
分析源代码发现,元数据的加载可以是单线程串行加载,也可以是多线程并行加载,而使用哪种策略,最终基于sharding-jdbc的一个配置:max.connections.size.per.query
max.connections.size.per.query默认值是1,此时元数据加载是单线程串行加载。
而配置大于1时,会根据该配置的值,采用多线程并行加载。
显然,对于我们大几千张表,多线程并行加载可以极大的提高加载效率。
好了,事情似乎完美解决,将max.connections.size.per.query设置大点,再大点,就能完美解决我们项目启动慢的问题。
但,秉着小心谨慎的原则,我们必须思考接下来的问题:
1、该配置到底是什么意思?
2、该配置的改动是否会影响到其他的逻辑?
3、我们是否能接受该配置变动带来的影响?
为此,在真正弄清楚这个配置的意义之前,我们并不能无脑的随意变更其值,我们需要真正了解这个配置对于整个项目的影响。
二、调研分析
1、服务启动阶段
影响我们项目启动慢的关键源代码如下:
org.apache.shardingsphere.sql.parser.binder.metadata.schema.SchemaMetaDataLoader#load
List<List<String>> tableGroups = Lists.partition(
tableNames,
Math.max(tableNames.size() / maxConnectionCount, 1)
);
Map<String, TableMetaData> tableMetaDataMap =
1 == tableGroups.size() ?
load(dataSource.getConnection(), (Collection)tableGroups.get(0), databaseType) :
asyncLoad(dataSource, maxConnectionCount, tableNames, tableGroups, databaseType);其中,maxConnectionCount对应的就是我们今天说的max.connections.size.per.query,也对应了源码中的枚举:
org.apache.shardingsphere.underlying.common.config.properties.ConfigurationPropertyKey
MAX_CONNECTIONS_SIZE_PER_QUERY("max.connections.size.per.query", String.valueOf(1), Integer.TYPE),可以看到,它的默认值是1。
而对应的加载方法有load和asyncLoad两种,也就是前面说过的单线程加载和多线程加载。
load方法源码如下:
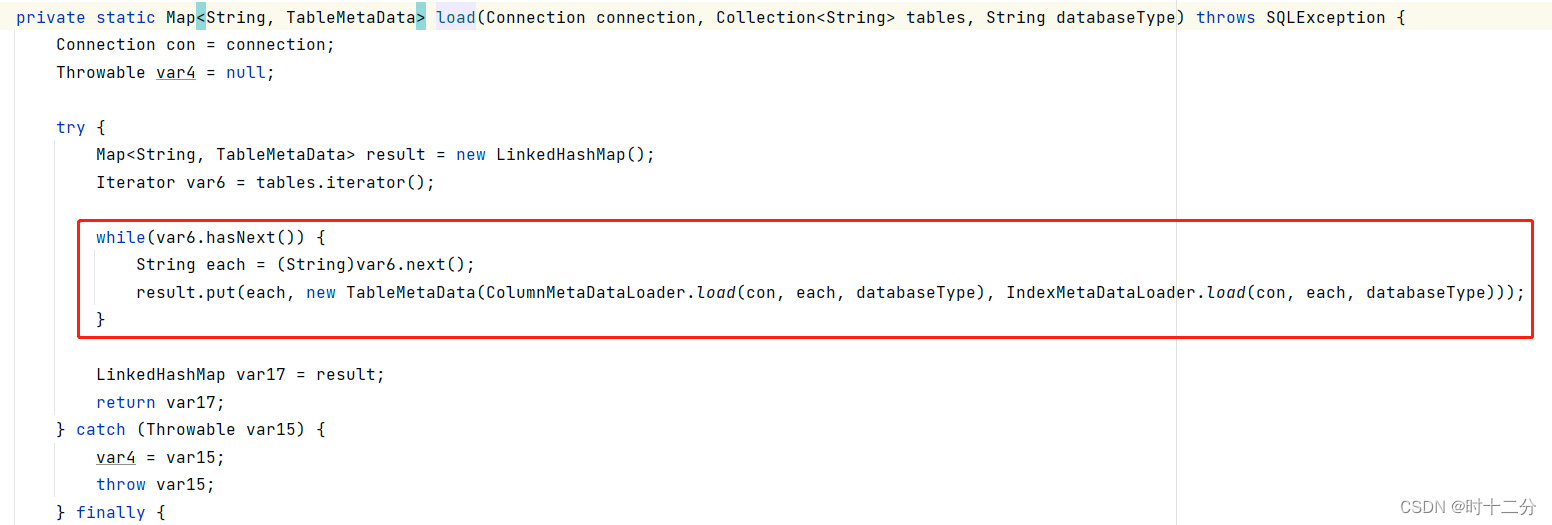
?asyncLoad源码如下: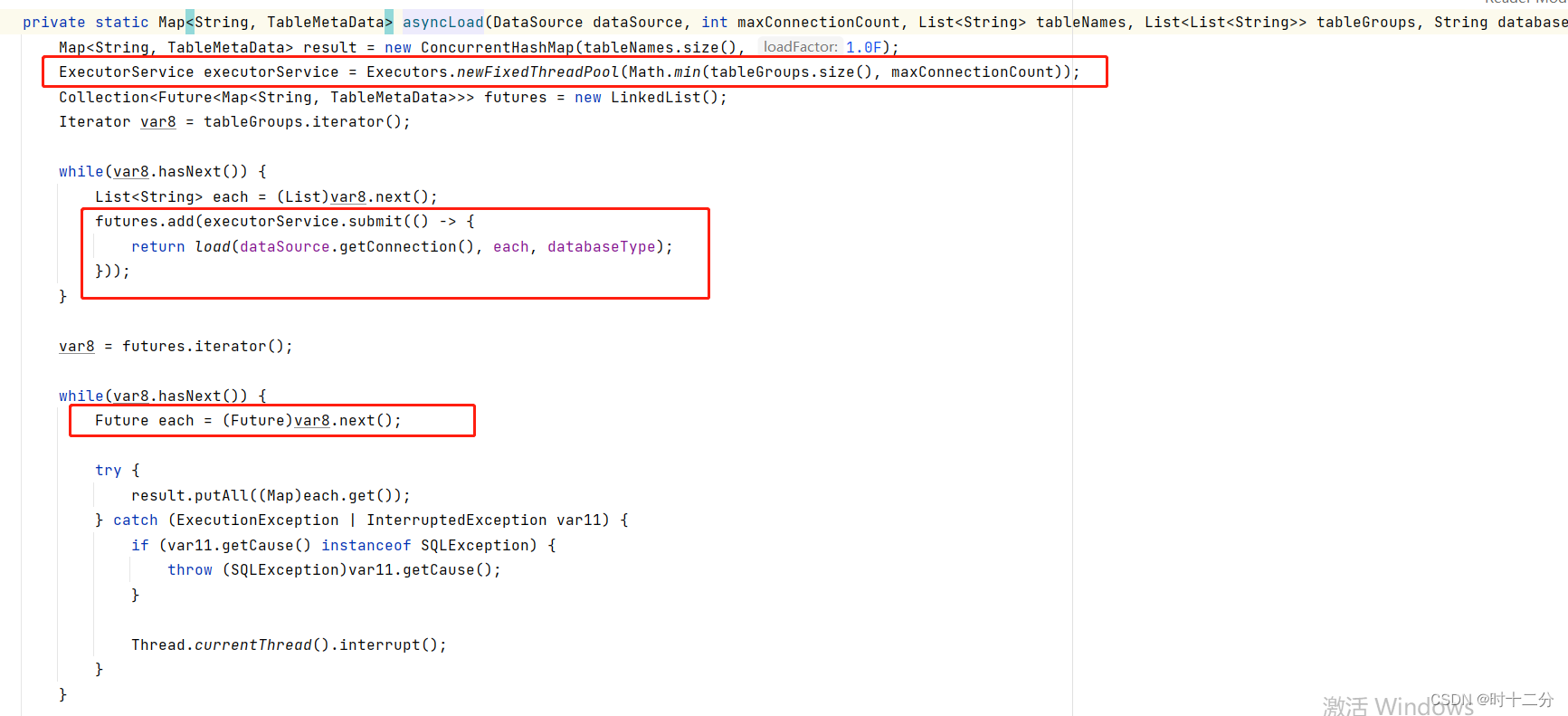
上述,便是启动过程中加载表元数据的逻辑,归纳如下:
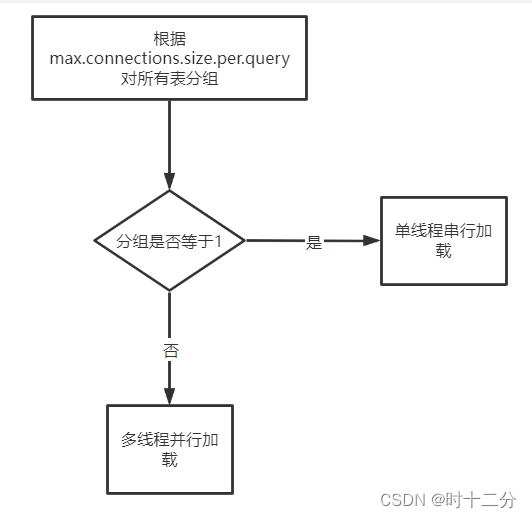
?为了更直观的表达代码逻辑,举几个例子:
| 表数量 | max.connections.size.per.query | 分组数 | 线程数 | 每组数量 | 加载方式 |
|---|---|---|---|---|---|
| 100 | 1 | 1 | 1 | 100 | 1个线程跑一组数据 |
| 100 | 2 | 2 | 2 | 50 | 2个线程跑2组数据 |
| 100 | 3 | 4 | 3 | 33或1 | 3个线程跑4组数据 |
| 100 | 101 | 100 | 100 | 1 | 100个线程跑100组数据 |
加载元数据的线程池中线程数量取决于max.connections.size.per.query和分组数的最小值。
2、服务运行阶段
先说下两个概念:
逻辑sql和真实sql
直接举例:
假设我们的用户很多,进行了分表,分表数量32,对应的表为:t_user_0,t_user_1...t_user_31
当我们在查询用户,如select * from t_user where name='张三',这个就是逻辑sql
sharding-jdbc会将逻辑sql改写成真实sql,也就是这样:
select * from t_user_0 where name='张三'
select * from t_user_1 where name='张三'
......
select * from t_user_31 where name='张三'
一个逻辑sql的执行,涉及底层32个真实sql的执行。
那这32个真实sql是怎么执行的呢?是一个一个跑出来的吗?
这里,就又涉及到了max.connections.size.per.query这个配置。
原理同前面的分组加载元数据相似,也是把真实sql分组去执行。
分组的源码逻辑如下:
org.apache.shardingsphere.sharding.execute.sql.prepare.SQLExecutePrepareTemplate#getSQLExecuteGroups
private List<InputGroup<StatementExecuteUnit>> getSQLExecuteGroups(String dataSourceName, List<SQLUnit> sqlUnits, SQLExecutePrepareCallback callback) throws SQLException {
List<InputGroup<StatementExecuteUnit>> result = new LinkedList();
int desiredPartitionSize = Math.max(0 == sqlUnits.size() % this.maxConnectionsSizePerQuery ? sqlUnits.size() / this.maxConnectionsSizePerQuery : sqlUnits.size() / this.maxConnectionsSizePerQuery + 1, 1);
List<List<SQLUnit>> sqlUnitPartitions = Lists.partition(sqlUnits, desiredPartitionSize);
ConnectionMode connectionMode = this.maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
List<Connection> connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitPartitions.size());
int count = 0;
Iterator var10 = sqlUnitPartitions.iterator();
while(var10.hasNext()) {
List<SQLUnit> each = (List)var10.next();
result.add(this.getSQLExecuteGroup(connectionMode, (Connection)connections.get(count++), dataSourceName, each, callback));
}
return result;
}分组后,便需要根据分组数量获取对应数量的连接,源码如下:
org.apache.shardingsphere.shardingjdbc.jdbc.adapter.AbstractConnectionAdapter?
private List<Connection> createConnections(String dataSourceName, ConnectionMode connectionMode, DataSource dataSource, int connectionSize) throws SQLException {
if (1 == connectionSize) {
Connection connection = this.createConnection(dataSourceName, dataSource);
this.replayMethodsInvocation(connection);
return Collections.singletonList(connection);
} else if (ConnectionMode.CONNECTION_STRICTLY == connectionMode) {
return this.createConnections(dataSourceName, dataSource, connectionSize);
} else {
synchronized(dataSource) {
return this.createConnections(dataSourceName, dataSource, connectionSize);
}
}
}
private List<Connection> createConnections(String dataSourceName, DataSource dataSource, int connectionSize) throws SQLException {
List<Connection> result = new ArrayList(connectionSize);
for(int i = 0; i < connectionSize; ++i) {
try {
Connection connection = this.createConnection(dataSourceName, dataSource);
this.replayMethodsInvocation(connection);
result.add(connection);
} catch (SQLException var9) {
Iterator var7 = result.iterator();
while(var7.hasNext()) {
Connection each = (Connection)var7.next();
each.close();
}
throw new SQLException(String.format("Could't get %d connections one time, partition succeed connection(%d) have released!", connectionSize, result.size()), var9);
}
}
return result;
}这两处源码涉及的max.connections.size.per.query包括两点:
1、计算需要一次性获取多少个连接去执行所有的真实sql;
2、归并方式,也就是源码中的ConnectionMode,它分为两种,一种叫内存限制模式,一种叫连接限制模式,当max.connections.size.per.query小于真实sql数量时,走的是连接限制模式(通俗理解:因为连接不够用,需要把sql执行完后,将查询结果先放到内存,然后释放连接用于查询其他sql),反之走的是内存限制模式(连接足够用,每个sql占据一个连接,查询结果不需要一次性放到内存,而是分批次拉取数据,在内存中做归并聚合)。
三、结论
1、max.connections.size.per.query配置的变更影响有三点:
1)启动时加载元数据的逻辑;
2)sql执行时的逻辑;
3)查询结果归并的逻辑;
2、max.connections.size.per.query的配置不能大于datasource的最大线程数,否则一旦分表数量大,就会因为无法一次获取足够的连接而报错;
3、如果代码中有很多不带分片参数的分表查询,而max.connections.size.per.query又设置的比较大,会极大的消耗数据库连接,可能导致其他业务逻辑无法获取连接而报错;
4、如果代码中有不带分片参数的分表查询,而max.connections.size.per.query又设置的比较小,会走连接限制模式,所有数据会放到内存后再做聚合,如果查询结果较大,可能爆掉内存;
5、只要代码中避免掉不带分片参数的查询更新操作,适当加大max.connections.size.per.query的值,可以提升启动速度而不会对项目的运行造成任何影响。