记录遇到的SQL问题
1、 hive sql中 ‘’ 和 null 之间区别?
- 概念区别
null 表示没有有任何值
‘’ 表示没有一个空的字符串 - 使用区别
在数据表中,如果一个字段没有值,通常默认为 null ,而 ‘’ 是需要自行设置。
如果字段类型为字符串,null 和 ‘’ 显示出来一样。我们插入数据时,null 在数值型和字符串型存储形式都是默认 /N,而 ‘’ 在字符串型中保持 ‘’ ,而在数值型则为 /N。
查询表中 null 和 ‘’ 的数据:
select col from tablename where col is null or col is not null
select col from tablename where col = '' or col <> ''
2、Hive中order by、sort by、distribute by、cluster by用法
- order by :全局排序,所有的数据经过一个reduce处理,对于大批量数据执行时间较长,还会面临运行失败的情况。如果set hive.mapred.mode=strict,将MR模式设置为严格模式,order by后面必须有limit才能避免报错,成功运行。
- sort by :局部排序,在每个reduce中数据有序,对输出的数据进行归并排序即可得到全局排序。sort by 优点是为全局排序提高效率。
- distrrbute by :控制map端输出划分到不同的reducer中,distribute by根据后面的列,reduce个数进行分发,默认采用的是hash算法。
注意:distribute by保证相同的key值划分在同一个reduce中,但由于划分规则需要考虑hash码和reduce个数,意味着同一个分区中的分区字段不一定相同。
例如,下图年份的key有四个不同的值,但reduce只有三个,自然会出现不同的key在一个reduce中。
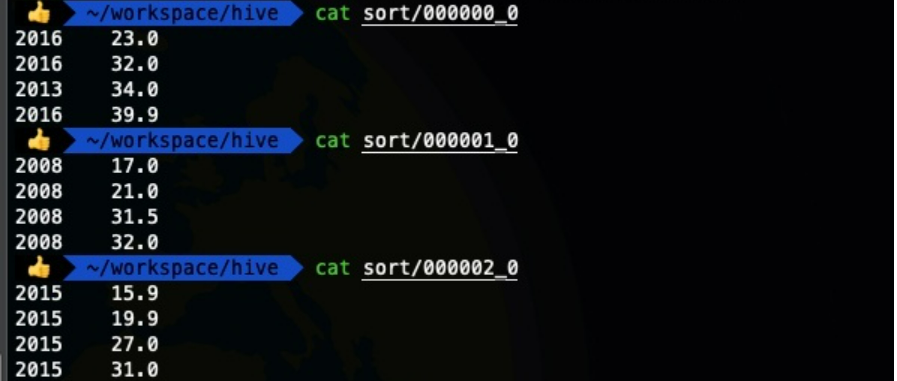
- cluster by :其功能就是distribute by和sort by相结合,但是排序只能是升序排序,不能指定排序规则为 asc 或者 desc。
注意:distribute by和sort by字段相同时,可以使用cluster by 代替distribute by和sort by。
例如,
select mid, money, name from store distribute by mid sort by mid
等价于
select mid, money, name from store cluster by mid
3、连接查询中,on和where条件含义
- 对于left join,无论on后面接什么条件,左表的记录都会查询出来,因此想要过滤则需要where条件。
- 对于inner join,则可以通过on后面加上一些条件达到过滤目的。同样也可以通过where条件。
对于上述说法,通过例子具体说明:
现有两张表,tab1和tab2


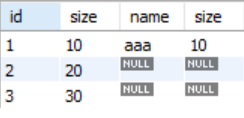
1、select * from tab1 left join tab2 on tab1.size = tab2.size and tab1.id = 1
结果如下
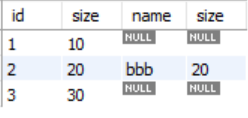
2、select * from tab1 left join tab2 on tab1.size = tab2.size and tab2.name = 'bbb'
结果如下
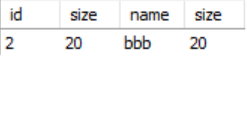
3、select * from tab1 left join tab2 on tab1.size = tab2.size where tab2.name = 'bbb'
结果如下
4、select * from tab1 inner join tab2 on tab1.size = tab2.size and tab2.name = 'ccc'
相当于
select * from tab1 inner join tab2 on tab1.size = tab2.size where tab2.name = 'ccc'
结果如下
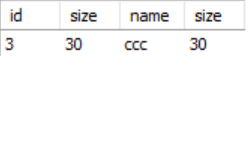
从以上的查询结果可以看出,对于left join,on的条件是否为真都会返回左表全部记录,而把条件放在where后,则会过滤掉不符合条件的记录。而对于inner join来说,条件放在on和where结果一致。