������������ݼ���(Hadoopƪ)
һ.Hadoop���
1.Hadoop����
Hadoop����Apache���µĿ�Դ���ֲ�ʽ����ƽ̨,�������������������Ⱥ֮��,�ṩ�ɿ��ġ�����չ�ķֲ����㹦�ܡ�
Hadoop�ĺ����Ƿֲ�ʽ�ļ�ϵͳ(HDFS)�Ͳ��б�̿��MapReduce��
2.Hadoop�����Ĺؼ�����
�ȸ����ƪ���Ĵٽ���Hadoop��ؼ����ķ�չ,���Doug Cutting������Hadoop,����Ϊ��Hadoop֮������
- ��The Google File System��
Hadoop��HDFS���ǻ��ڹȸ��GFS
- ��MapReduce:Simplified Data Process on Large Clusters��
MapReduce��һ���ֲ�ʽ����ģ��,�ǵ��͵ġ�����˼�롱��
- ��Bigtable:A Distributed Storage System for Structured Data��
Bigtable��һ������ ���ģ�ṹ������ ����Ƶķֲ�ʽ�洢ϵͳ,������չ��PB�����ݺ���ǧ̨��������
ֵ��ע�����,Bigtable���ǹ�ϵ�����ݿ�,����ȴ�����˺ܶ��ϵ�����ݿ�����
��.Hadoop��չʷ
- 2002��-2004��,���������ĵķ������������������Ƽ���ĺ�����ɲ���GFS��MapReduce�Լ�Bigtable��
- 2006��1��,Doug Cutting ����Yahoo,�쵼Hadoop�Ŀ�����Doug�������ӵ���߷�����Ϊ��Hadoop��ͼ��,���¡�

��.Hadoop�ص�
��ơ��ĸ�һ�͡�
- ���ݴ���
Hadoop�ļ�ϵͳ�����ݽ����˱���,�Ҿ��о����ͻָ����ơ������������ϵ������ݳ������Իָ�,���������С� - ����չ��
�����˼������Ⱥ�洢�ͼ���,�������Ⱥ�����������Ӽ����,���������������� - ��Ч��
- �߿ɿ���
- �ͳɱ�
�������������۵����÷�������
��.Hadoop�ṹ���
1.HDFS
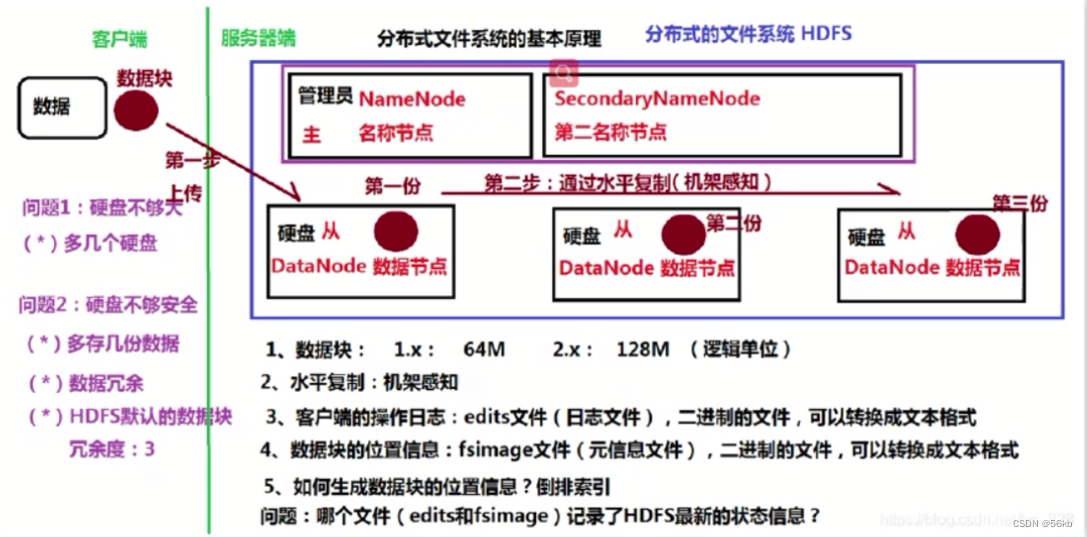
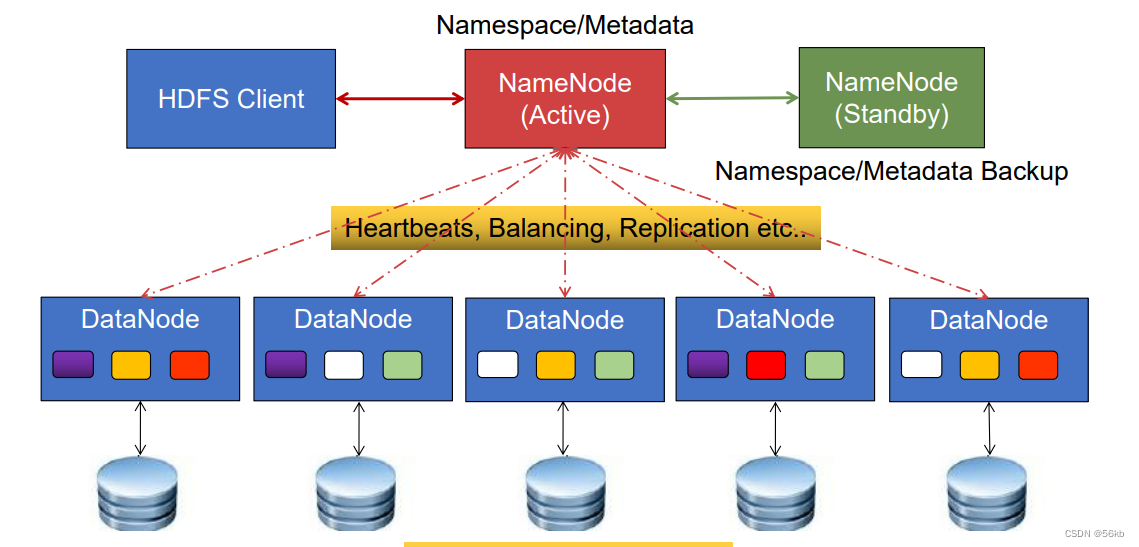
- HDFS(Hadoop Distributed File System �ֲ�ʽ�ļ�ϵͳ)���ⲿ�ͻ�������,����һ����ͳ�ķּ��ļ�ϵͳ,���Դ�����ɾ�����ƶ����������ļ�
�ȡ� - HDFS��ϵ�ṹ
�����Client��NameNode(Active��Stanby״̬)��DataNode
- HDFSд�����ݵ�����
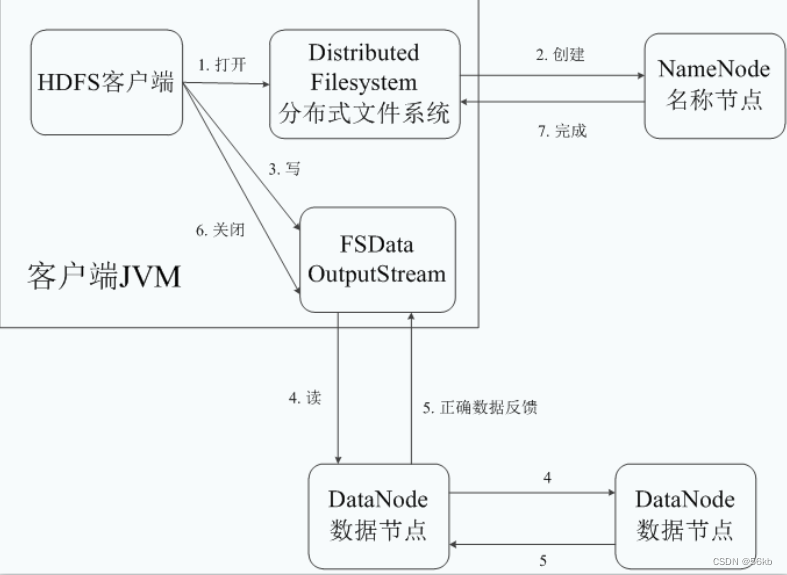
- HDFS��ȡ���ݵ�����
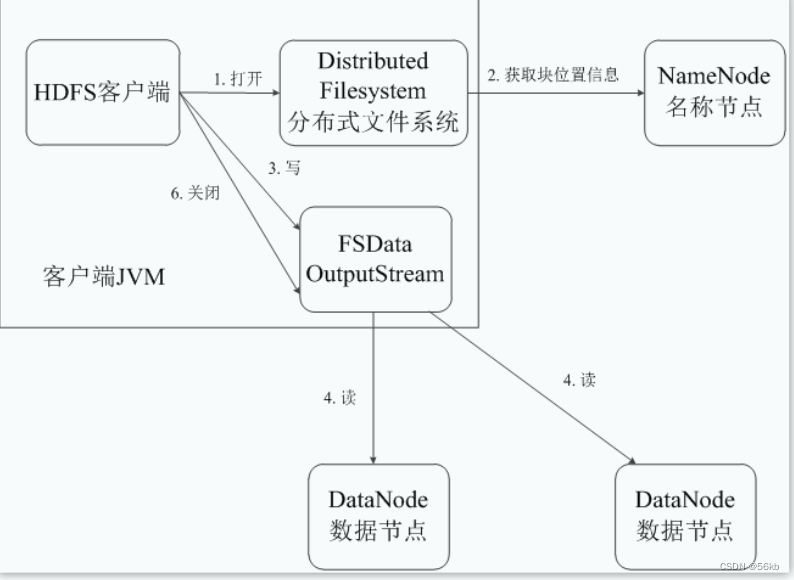
- HDFS���������������:
- ���ֽڵ����
- ���ݽڵ����
- ����Ͽ�
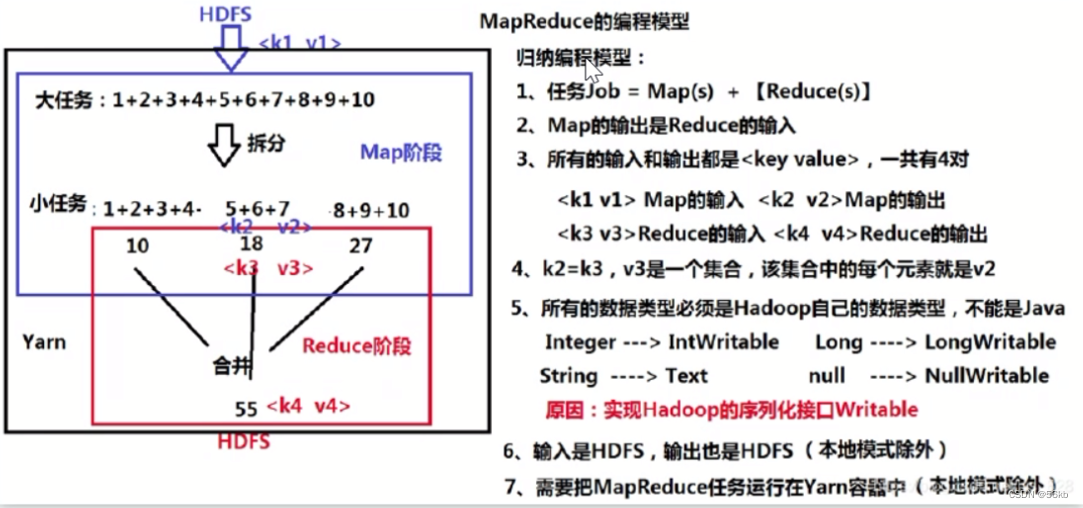
2.MapReduce
- MapReduce����MapReduce��Hadoopϵͳ�ĺ������,��Google��MapReduceϵͳ�����ݱ����,��Ҫ������������ݼ����,Ҳ���ڶ�ֲ�ʽ����ģ���бȽ����е�һ��,���Ե���ʹ��,һ�����HDFSһ��ʹ�á�MapReduce��һ�ֱ��ģ��,���ڴ��ģ���ݼ�(����1TB)�IJ������㡣
- ��ϵ�ṹ
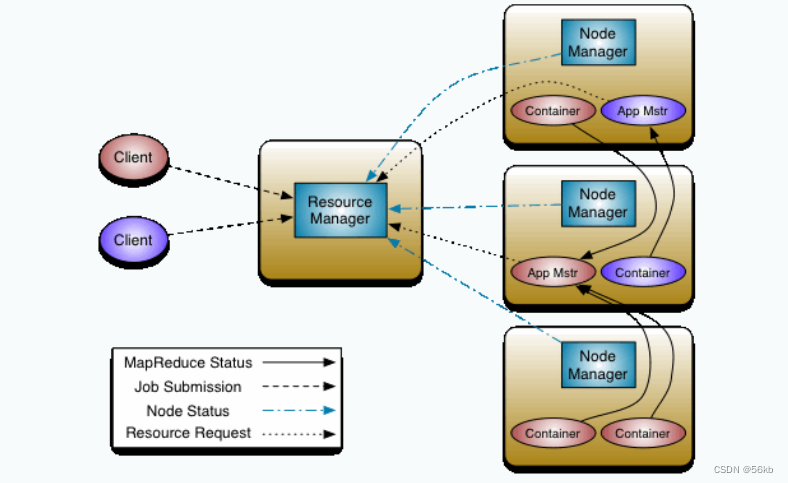
- ��ϵ�ṹ�����
- MapReduce��Ҫ�����ĸ���ɲ���,�ֱ�ΪClient��ResourceManager(JobTracker)��NodeManager(TaskTracker), MRAppMaster��
- Client:�û���ͨ��Client�ṩһЩ�ӿڲ鿴��ҵ������״̬
- ResourceManager:��Workers�ַ�Ӧ�ú�����,����
��Դ�������ҵ����,��Client�ṩ״̬�������Ϣ�� - NodeManager:��
��������ͨ��Heartbeat�����ڵ�����Դ(CPU, �ڴ�,����,����)��ʹ���������������н����㱨��ResourceManager,ͬʱ����ResourceManager�����������ִ����Ӧ�IJ���(������������ɱ�������)�� - MRAppMaster: ��Ӧ�÷���,���ں�ResourceManagerЭ����Դ,��NodeManagerִ�в��ල����
3.Taskִ�й���
- Map Task�Ƚ���Ӧ��split ����������һ����key/value ��,���ε����û��Զ����map() �������д���,���ս���ʱ�����ŵ����ش�����, ������ʱ���ݱ��ֳ����ɸ�partition,ÿ��partition��һ��Reduce Task ������
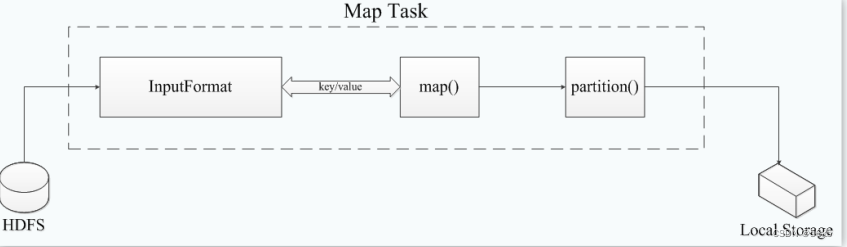
- Reduce Taskִ�й��̷�Ϊ������
- Shuffle��:��Զ�̽ڵ��϶�ȡMap Task�м��
���� - Sort��:����key��key/value �Խ�������
- Reduce��:���ζ�ȡ< key,value list>,������
���Զ����reduce() ��������,�������ս���浽
HDFS�ϡ�
- Shuffle��:��Զ�̽ڵ��϶�ȡMap Task�м��
��.Hadoop�����
1.����Linux����
- ����,��װVMware�����
- ��������а�װLinux����(CentOs 7)
linux��������:

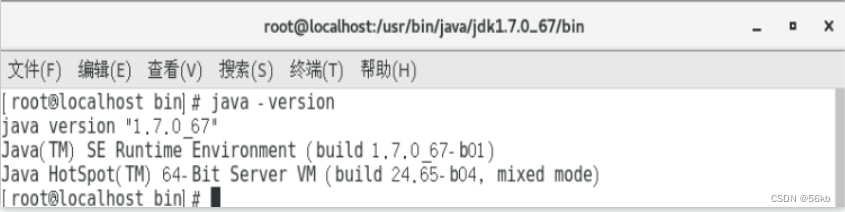
2.JDK��װ�Ͳ���
- ִ�С�java �Cversion������JDK����,�������:
3.Hadoop��װ������
----��������:----
- ��ѹhadoopѹ����
- ����Hadoop��������
- ����Yarn��������
- ���ú�������ļ�
- �����ļ�ϵͳ 6.
- ����yarn-site.xml
- ����MapReduce�������ļ�
- ����Master��slaves�ļ�
��.Hadoop�ؼ����
1.Hadoop��̬
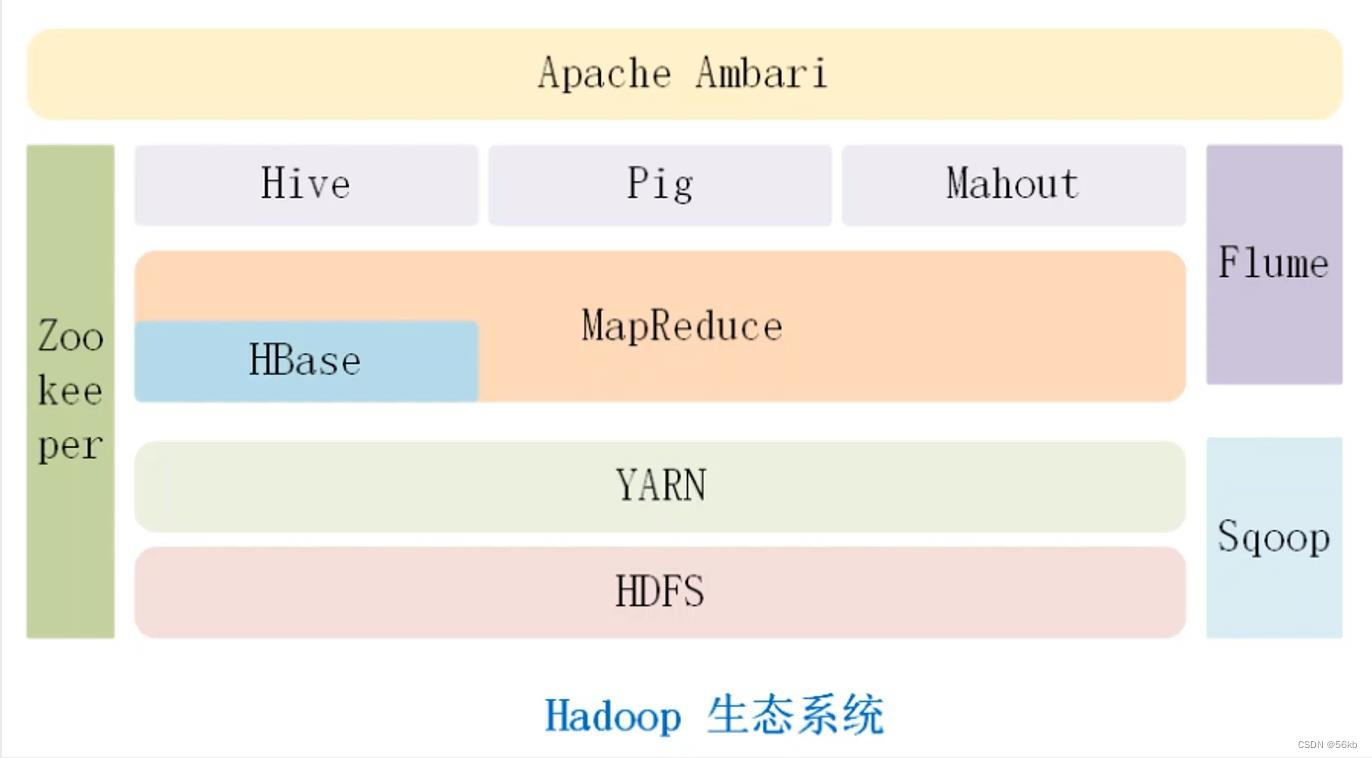
Hadoop��ϵ�ṹ��ײ����HDFS,���洢��Hadoop ��Ⱥ�����д洢�ڵ��ϵ��ļ���HDFS����һ����MapReduce����(����ģ��),�� JobTrackers TaskTrackers ��ɡ�����֮��,Hadoop��ϵ�ṹ���������ݲֿ�Hive������������Pig�������ھ��Mahout��ʵʱ�ֲ�ʽ���ݿ�Hbase�ȡ�
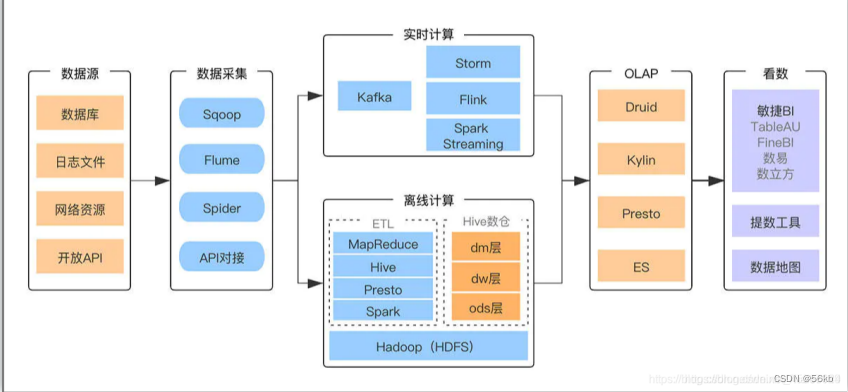
2.�������
-
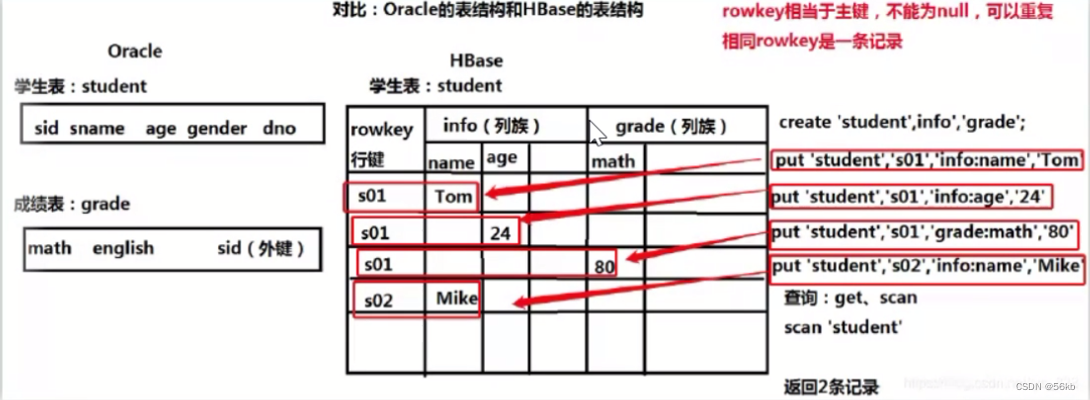
HBase
- HBase ��Hadoop Database�ļ��,��һ���߿ɿ��ԡ������ܡ��������ķֲ�ʽ�洢ϵͳ,����HBase������������PC Server�ϴ����ģ�ṹ���洢��Ⱥ��
- Hbase����Hadoop�е�HDFS��Ϊ���ļ��洢ϵͳ,����Hadoop��MapReduce������Hbase�еĺ�������,����ZooKeeper��ΪЭ�����ߡ�

-
Hive
- Hive�ǻ���Hadoop��һ��
���ݲֿ��,���Խ��ṹ���������ļ�ӳ��Ϊһ�����ݿ��,���ṩ��sql��ѯ����,���Խ�sql���ת��ΪMapReduce�����������,Hive��Hadoop֮���ṩ�����ݲ�ѯ����,��Ҫ����ǹ�ϵ�����ݲ�ѯ���⡣
- Hive�ǻ���Hadoop��һ��
-
Redis
- Redis��һ���ٶȷdz���ķǹ�ϵ���ݿ�,֧�ִ�
���� value ������Ը���,����֧�ָ��ֲ�ͬ��ʽ
������,Ϊ�˱���Ч��,���ݶ��ǻ������ڴ��С�
- Redis��һ���ٶȷdz���ķǹ�ϵ���ݿ�,֧�ִ�
-
Pig
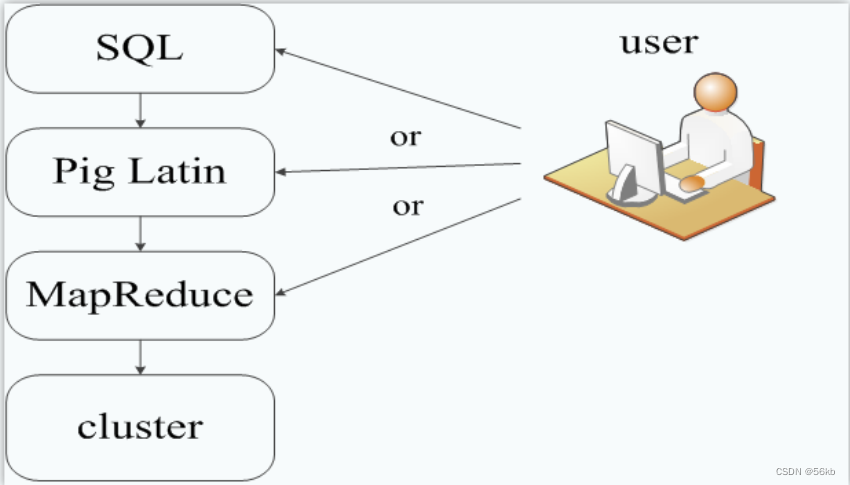
- Apache Pig��һ������������,�ʺ���ʹ��Hadoop��MapReduceƽ̨����ѯ���Ͱ�ṹ�����ݼ���ͨ���Էֲ�ʽ���ݼ���������SQL�IJ�ѯ,Pig���Լ�Hadoop��ʹ��
- Pig�����ݴ����е�λ������
-
Mahout
- Mahout����˵����һ���ṩ����չ��
����ѧϰ������㷨��,ּ�ڰ���������Ա���ӷ����ݵش�������Ӧ�ó��� - Mahoutʵ���˾��ࡢ���ࡢƵ����ھ����Ŀ��ͨ��ʹ��Apache Hadoop��,Mahout������Ч����չ��Hadoop��Ⱥ������չ�����С�
- Mahout����˵����һ���ṩ����չ��
-
ZooKeeper
- ZooKeeper��һ��Ϊ�ֲ�ʽӦ������Ƶĸ����ܵ�
�ֲ�ʽЭ���������,���ṩ����ͬ������,���������������Ŀͻ��˾Ϳ��Եõ�һ�µ����ݡ� - ����Ӧ�ó��������ݷ���/���ġ��ֲ�ʽЭ��/֪ͨ����Ⱥ�����ȡ�
- ��Ҫ�����ù��������ַ��ֲ�ʽ����
��Ⱥ���������ù���ָ������һ���ط���������,��ô������ط������ø���Ȥ�����еĶ����Ի�ñ��,ʡȥ���ֶ��������õķ���,���ܺõı�֤�����ݵĿɿ���һ����,ͬʱ������ͨ����������ȡ��Դ���߷���ĵ�ַ����Ϣ,���Լ�ؼ�Ⱥ�л����ı仯,ʵ�����������������ƵĹ��ܡ� - Zookeeper�Ĺ����ܹ�
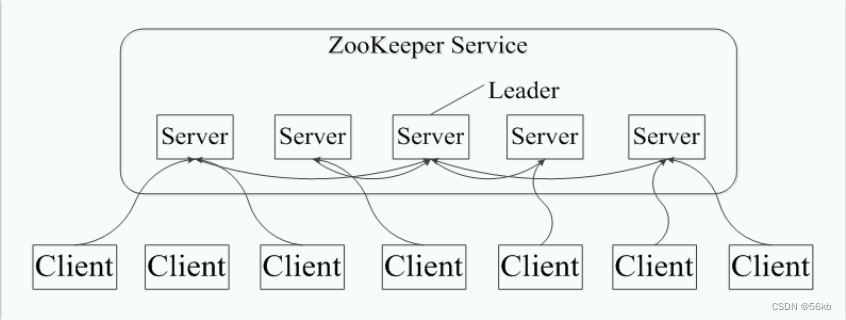
- ZooKeeper��һ��Ϊ�ֲ�ʽӦ������Ƶĸ����ܵ�
-
Kafka
- Kafka��һ�����������ķֲ�ʽ��
���ڷ���/���ĵ���Ϣϵͳ,���Դ��������߹�ģ����վ�����ж��������ݡ� - Kafka���������֮һ����ͬʱ�ṩ���ߴ�����ʵʱ����, �Լ�������ʵʱ���ݵ���һ���������ġ�
- Kafka����������������ߺ������߷����������,����Ϣ��topicΪ��λ���й���;Kafka������Ϣ�ij����producer,Ҳ��������,Ԥ��topics��������Ϣ�ij����Ϊconsumer,Ҳ��������;��Kafka�Լ�Ⱥ�ķ�ʽ����ʱ,������һ��������߶���������,ÿ���������һ��broker,���й�����producerͨ�����罫��Ϣ���͵�Kafka��Ⱥ,��Ⱥ���������ṩ��Ϣ��
- Kafka��һ�����������ķֲ�ʽ��
-
Flume
- Flume��Cloudera�ṩ��һ���߿��õ�,�߿ɿ���,�ֲ�ʽ��
������־�ɼ����ۺϺʹ����ϵͳ,Flume֧������־ϵͳ�ж��Ƹ������ݷ��ͷ�,�����ռ�����;ͬʱ,Flume�ṩ�����ݽ��м���,��д���������ݽ��ܷ���������
- Flume��Cloudera�ṩ��һ���߿��õ�,�߿ɿ���,�ֲ�ʽ��
-
Sqoop
- Sqoop��һ��������Hadoop��ϵ�����ݿ��е������ת�ƵĹ���,���Խ�һ����ϵ�����ݿ�(����MySQL ��Oracle ��Postgres��)�е����ݵ�����Hadoop��HDFS��,Ҳ���Խ�HDFS�����ݵ�������ϵ�����ݿ��С�SqoopרΪ�����������������,�ܹ��ָ����ݼ�������Hadoop����������ÿ�����顣
- Sqoop��һ��������Hadoop��ϵ�����ݿ��е������ת�ƵĹ���,���Խ�һ����ϵ�����ݿ�(����MySQL ��Oracle ��Postgres��)�е����ݵ�����Hadoop��HDFS��,Ҳ���Խ�HDFS�����ݵ�������ϵ�����ݿ��С�SqoopרΪ�����������������,�ܹ��ָ����ݼ�������Hadoop����������ÿ�����顣
-
Ambari
- Ambari��Hortonworks��Դ��Hadoopƽ̨��
��������,�߱�Hadoop����İ�װ����������ά�Ȼ�������,�ṩWeb UI���п��ӻ��ļ�Ⱥ����,���˴�����ƽ̨�İ�װ��ʹ���Ѷȡ�Ambariͨ��HDP��Hadoop��������м���,ͨ��ջ����ʽ�ṩService�����ʹ�á�
- Ambari��Hortonworks��Դ��Hadoopƽ̨��