?一、大数据处理框架
? ? ? ?主流的大数据处理框架包括以下三类五种:
1、仅批处理框架:Apache Hadoop
2、仅流处理框架:Apache Storm、Apache Samza
3、混合框架:Apache Spark、Apache Flink
? ? ? 处理框架相比处理引擎,处理引擎为实际处理数据操作的组件,而处理框架为承担类似作用的一系列组件。如Apache Hadoop可以看作一种以MapReduce作为默认处理引擎的处理框架,另一个框架Apache Spark可以纳入Hadoop并取代MapReduce。组件之间的这种互操作性是大数据系统灵活性如此之高的原因之一。
1、批处理框架
? ? ?批处理主要操作大容量静态数据集,并在计算过程完成后返回结果。批处理模式中使用的数据集通常符合下列特征:
・?有界:批处理数据集代表数据的有限集合
・?持久:数据通常始终存储在某种类型的持久存储位置中
・?大量:批处理操作通常是处理极为海量数据集的唯一方法
? ? ?批处理非常适合需要访问全套记录才能完成的计算工作。需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。大量数据的处理需要付出大量时间,因此批处理不适合对处理时间要求较高的场合。
? ? ? ?Hadoop的处理功能来自MapReduce引擎。MapReduce的处理技术符合使用键值对的map、shuffle、reduce算法要求。基本处理过程包括:
・?从HDFS文件系统读取数据集
・?将数据集拆分成小块并分配给所有可用节点
・?针对每个节点上的数据子集进行计算(计算的中间态结果会重新写入HDFS)
・?重新分配中间态结果并按照键进行分组
・?通过对每个节点计算的结果进行汇总和组合对每个键的值进行“Reducing”
・?将计算而来的最终结果重新写入 HDFS
? ? ? ?由于这种方法严重依赖持久存储,每个任务需要多次执行读取和写入操作,因此速度相对较慢。但另一方面由于磁盘空间通常是服务器上最丰富的资源,这意味着MapReduce可以处理非常海量的数据集。同时也意味着相比其他类似技术,Hadoop的MapReduce通常可以在廉价硬件上运行,因为该技术并不需要将一切都存储在内存中。MapReduce具备极高的缩放潜力,生产环境中曾经出现过包含数万个节点的应用。MapReduce的学习曲线较为陡峭,虽然Hadoop生态系统的其他周边技术可以大幅降低这一问题的影响,但通过Hadoop集群快速实现某些应用时依然需要注意这个问题。围绕Hadoop已经形成了辽阔的生态系统,Hadoop集群本身也经常被用作其他软件的组成部件。很多其他处理框架和引擎通过与Hadoop集成也可以使用HDFS和YARN资源管理器。
2、流处理框架
? ? ? 流处理系统会对随时进入系统的数据进行计算。流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作。流处理中的数据集是“无边界”的,这就产生了几个重要的影响:
・?完整数据集只能代表截至目前已经进入到系统中的数据总量。
・?工作数据集也许更相关,在特定时间只能代表某个单一数据项。
? ? ? ?处理工作是基于事件的,除非明确停止否则没有“尽头”。处理结果立刻可用,并会随着新数据的抵达继续更新。流处理系统可以处理几乎无限量的数据,但同一时间只能处理一条(真正的流处理)或很少量(微批处理,Micro-batch Processing)数据,不同记录间只维持最少量的状态。虽然大部分系统提供了用于维持某些状态的方法,但流处理主要针对副作用更少,更加功能性的处理(Functional processing)进行优化。
? ? ? ?Apache Storm是一种侧重于极低延迟的流处理框架,也许是要求近实时处理的工作负载的最佳选择。该技术可处理非常大量的数据,通过比其他解决方案更低的延迟提供结果。Storm的流处理可对框架中名为Topology(拓扑)的DAG(Directed Acyclic Graph,有向无环图)进行编排。这些拓扑描述了当数据片段进入系统后,需要对每个传入的片段执行的不同转换或步骤。Storm可与Hadoop的YARN资源管理器进行集成,因此可以很方便地融入现有Hadoop部署。除了支持大部分处理框架,Storm还可支持多种语言,为用户的拓扑定义提供了更多选择。
? ? ? ?Apache Samza是一种与Apache Kafka消息系统紧密绑定的流处理框架。虽然Kafka可用于很多流处理系统,但按照设计,Samza可以更好地发挥Kafka独特的架构优势和保障。该技术可通过Kafka提供容错、缓冲,以及状态存储。Samza可使用YARN作为资源管理器。这意味着默认情况下需要具备Hadoop集群(至少具备HDFS和YARN),但同时也意味着Samza可以直接使用YARN丰富的内建功能。
3、混合处理框架
? ? ??可同时处理批处理和流处理工作负载。这些框架可以用相同或相关的组件和API处理两种类型的数据,借此让不同的处理需求得以简化。混合框架意在提供一种数据处理的通用解决方案。这种框架不仅可以提供处理数据所需的方法,而且提供了自己的集成项、库、工具,可胜任图形分析、机器学习、交互式查询等多种任务。? ? ? ?
? ? ? ? Apache Spark是一种包含流处理能力的下一代批处理框架。与Hadoop的MapReduce引擎基于各种相同原则开发而来的,Spark主要侧重于通过完善的内存计算和处理优化机制加快批处理工作负载的运行速度。Spark可作为独立集群部署(需要相应存储层的配合),或可与Hadoop集成并取代MapReduce引擎。与MapReduce不同,Spark的数据处理工作全部在内存中进行,只在一开始将数据读入内存,以及将最终结果持久存储时需要与存储层交互。所有中间态的处理结果均存储在内存中。虽然内存中处理方式可大幅改善性能,Spark在处理与磁盘有关的任务时速度也有很大提升,因为通过提前对整个任务集进行分析可以实现更完善的整体式优化。为此Spark可创建代表所需执行的全部操作,需要操作的数据,以及操作和数据之间关系的Directed Acyclic Graph(有向无环图),即DAG,借此处理器可以对任务进行更智能的协调。为了实现内存中批计算,Spark会使用一种名为Resilient Distributed Dataset(弹性分布式数据集),即RDD的模型来处理数据。这是一种代表数据集,只位于内存中,永恒不变的结构。针对RDD执行的操作可生成新的RDD。每个RDD可通过世系(Lineage)回溯至父级RDD,并最终回溯至磁盘上的数据。Spark可通过RDD在无需将每个操作的结果写回磁盘的前提下实现容错。流处理能力是由Spark Streaming实现的。Spark本身在设计上主要面向批处理工作负载,为了弥补引擎设计和流处理工作负载特征方面的差异,Spark实现了一种叫做微批(Micro-batch)*的概念。在具体策略方面该技术可以将数据流视作一系列非常小的“批”,借此即可通过批处理引擎的原生语义进行处理。Spark Streaming会以亚秒级增量对流进行缓冲,随后这些缓冲会作为小规模的固定数据集进行批处理。这种方式的实际效果非常好,但相比真正的流处理框架在性能方面依然存在不足。
? ? ? ?Apache Flink是一种可以处理批处理任务的流处理框架。该技术可将批处理数据视作具备有限边界的数据流,借此将批处理任务作为流处理的子集加以处理。为所有处理任务采取流处理为先的方法会产生一系列有趣的副作用。这种流处理为先的方法也叫做Kappa架构,与之相对的是更加被广为人知的Lambda架构(该架构中使用批处理作为主要处理方法,使用流作为补充并提供早期未经提炼的结果)。Kappa架构中会对一切进行流处理,借此对模型进行简化,而这一切是在最近流处理引擎逐渐成熟后才可行的。Flink的流处理模型在处理传入数据时会将每一项视作真正的数据流。Flink提供的DataStream API可用于处理无尽的数据流。Flink的批处理模型在很大程度上仅仅是对流处理模型的扩展。此时模型不再从持续流中读取数据,而是从持久存储中以流的形式读取有边界的数据集。Flink会对这些处理模型使用完全相同的运行时。Flink可以对批处理工作负载实现一定的优化。例如由于批处理操作可通过持久存储加以支持,Flink可以不对批处理工作负载创建快照。数据依然可以恢复,但常规处理操作可以执行得更快。另一个优化是对批处理任务进行分解,这样即可在需要的时候调用不同阶段和组件。借此Flink可以与集群的其他用户更好地共存。对任务提前进行分析使得Flink可以查看需要执行的所有操作、数据集的大小,以及下游需要执行的操作步骤,借此实现进一步的优化。
二、大数据计算引擎
? ? ? ?计算引擎就是一种计算规则的高度抽象聚合体,使用者按照指定的方式编写对应接口代码,然后执行就能得到需要的结果(前提没有bug)。大数据计算场景分为两种:批处理(历史文件)和流处理(实时数据)处理:
1、批处理-Hadoop承载的MapReduce
? ? ? ?它将计算分为两个阶段,分别为 Map(映射) 和 Reduce(归约)。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
2、支持DAG计算的计算引擎
? ? ? 如Tez 和 Oozie,大多还是批处理的任务。hadoop2新增计算引擎,MapReduce是第二代,优化原有MapReduce框架结构,合并非必要计算过程,减少数据存储次数,执行时间大幅提升。
? ? ? ?1个Tez = MR(1) + MR(2) + ... + MR(n),Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。总结起来,Tez有以下特点:
(1)Apache二级开源项目
(2)运行在YARN之上
(3)适用于DAG(有向图)应用(同Impala、Dremel和Drill一样,可用于替换Hive/Pig等)
3、内置DAG的计算引擎
? ? ??Spark 为代表的第三代的计算引擎,特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及实时计算,同时也能够很好的运行批处理的 Job。Spark不同于MapReducer只提供两种简单的编程接口,它提供了多种编程接口去操作数据,这些操作接口如果使用MapReduce去实现,需要更多的代码。Spark的操作接口可以分为两类:transformation(转换)和action(执行)。Transformation包含map、flatmap、distinct、reduceByKey和join等转换操作;Action包含reduce、collect、count和first等操作。
? ? ??在批处理方面相比于MapReduce处理同样的数据,Spark所要求的硬件设施更高,MapReduce在相同的设备下所能处理的数据量会比Spark多。所以在实际工作中,Spark在批处理方面只能算是MapReduce的一种补充。Spark可以使用YARN作为资源管理器,Spark也可以处理Hbase和HDFS上的数据。? ? ?
4、流批处理计算引擎
? ? ??“Flink是一个大数据量处理的统一的引擎”。这个“统一的引擎”包括流处理、批处理、AI、MachineLearning、图计算等等。主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
? ? ? ?没有哪一个框架可以完美的支持所有的场景,也就不可能有任何一个框架能完全取代另一个,就像 Spark 没有完全取代 Hadoop,当然 Flink 也不可能取代 Spark。?
三、HIVE计算引擎的工作原理
1、MR计算引擎
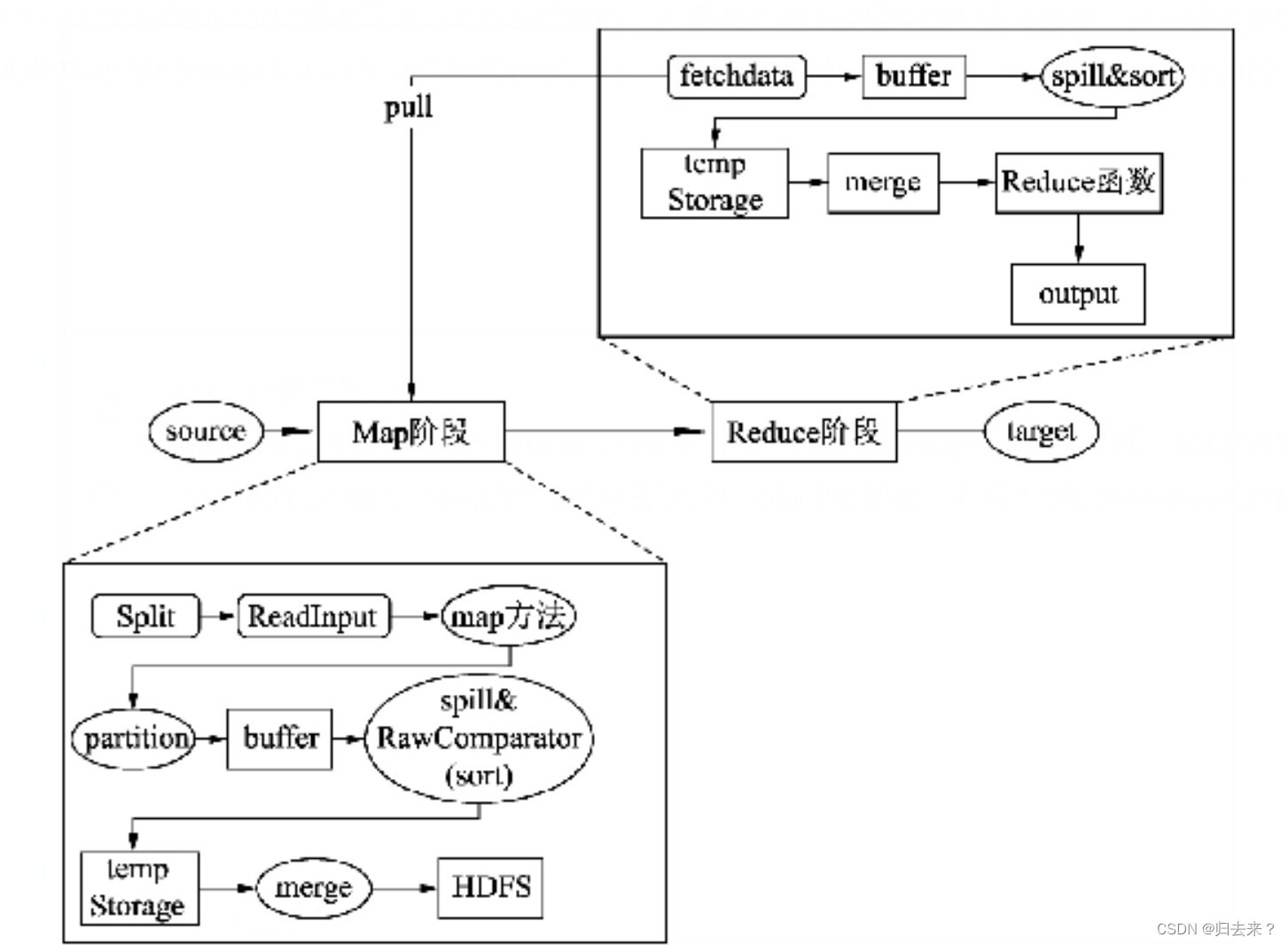
? ? ? ? Map在读取数据时,先将数据拆分成若干数据,并读取到Map方法中被处理。数据在输出的时候,被分成若干分区并写入内存缓存(buffer)中,内存缓存被数据填充到一定程度会溢出到磁盘并排序,当Map执行完后会将一个机器上输出的临时文件进行归并存入到HDFS中。
? ? ? ?当Reduce启动时,会启动一个线程去读取Map输出的数据,并写入到启动Reduce机器的内存中,在数据溢出到磁盘时会对数据进行再次排序。当读取数据完成后会将临时文件进行合并,作为Reduce函数的数据源。
2、Tez计算引擎
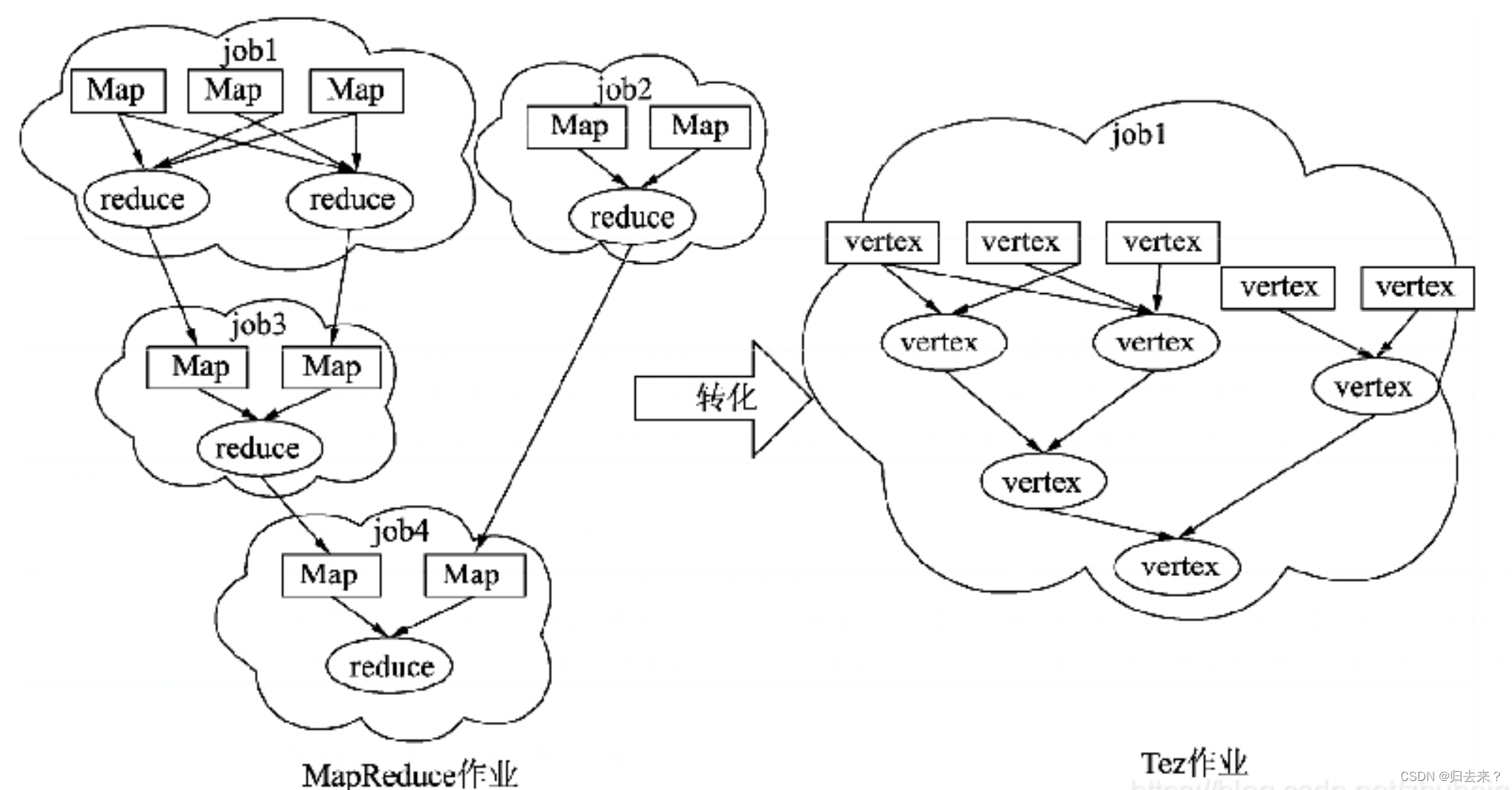
? ? ? ?Apache Tez是进行大规模数据处理且支持DAG作业的计算框架,它直接源于MapReduce框架,除了能够支持MapReduce特性,还支持新的作业形式,并允许不同类型的作业能够在一个集群中运行。
? ? ? ?Tez将原有的Map和Reduce两个操作简化为一个概念――Vertex,并将原有的计算处理节点拆分成多个组成部分:Vertex Input、Vertex Output、Sorting、Shuffling和Merging。计算节点之间的数据通信被统称为Edge,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
? ? ? ?通过允许Apache Hive运行复杂的DAG任务,Tez可以用来处理数据,之前需要多个MR jobs,现在一个Tez任务中。
3、Spark计算引擎
? ? ? ?Spark是继Hadoop之后的下一代分布式内存计算引擎,于2009年诞生于加州大学伯克利分校AMPLab实验室,现在主要由Databricks公司进行维护(公司创始员工均来自AMPLab)。
? ? ? ? Apache Spark是专为大规模数据处理而设计的快速、通用支持DAG(有向无环图)作业的计算引擎,类似于Hadoop MapReduce的通用并行框架,可用来构建大型的、低延迟的数据分析应用程序。
? ? ? ?Spark 是基于内存的分布式批处理引擎,它最大的特点是延迟小,具有很高的容错性和可拓展性,它和其他引擎的最大的区别在于,它支持进行迭代计算, Spark 主要适用的场景在低延迟的迭代计算中,它和传统的数据处理引擎最大的不同,在于 Spark 会将计算中的临时文件或者临时数据存放在内存中,这样在进行反复的引用时,就不需要再从磁盘中进行数据读取,而是选择更快的内存进行该操作。那么相比于传统 Hadoop 架构,Spark 理论速度会高于 Hadoop100 倍以上,但是,这个参数是有条件的,在迭代的层级较少的时候,这个差距并不明显,还有可能 Spark 的计算速度没有 hadoop 快,但是当反复的重复引用和迭代层数多以后,这个差距就会越来越明显。

Spark具有以下几个特性。
1.高效性
Spark会将作业构成一个DAG,优化了大型作业一些重复且浪费资源的操作,对查询进行了优化,重新编写了物理执行引擎,如可以实现MRR模式。
2.易用性
Spark不同于MapReducer只提供两种简单的编程接口,它提供了多种编程接口去操作数据,这些操作接口如果使用MapReduce去实现,需要更多的代码。Spark的操作接口可以分为两类:transformation(转换)和action(执行)。Transformation包含map、flatmap、distinct、reduceByKey和join等转换操作;Action包含reduce、collect、count和first等操作。
3.通用性
Spark针对实时计算、批处理、交互式查询,提供了统一的解决方案。但在批处理方面相比于MapReduce处理同样的数据,Spark所要求的硬件设施更高,MapReduce在相同的设备下所能处理的数据量会比Spark多。所以在实际工作中,Spark在批处理方面只能算是MapReduce的一种补充。
4.兼容性
Spark和MapReduce一样有丰富的产品生态做支撑。例如Spark可以使用YARN作为资源管理器,Spark也可以处理Hbase和HDFS上的数据。
扩展:Spark?On?YARN提供了两种提交作业的模式:YARN?Client和YARN?Cluster。两个模式在运行计算节点,完成数据从读入、处理、输出的过程基本一样。不同的是,YARN?Client作业的监控管理放在提交作业所在的节点,YARN?Cluster则是交给YARN去决定,YARN会根据集群各个节点资源的使用情况,选择最为合适的节点来存放作业监控和管理进程。YARN?Client一般用于测试,YARN?Cluster用于实际生产环境。
RDD:
? ? ? ?Spark提出了一个数据集抽象概念RDD,即弹性分布式数据集,它是一个只读的、带分区的数据集合,并支持多种分布式算子。RDD是Spark计算引擎的核心,具有以下几个特点:
(1)分布在集群中的只读对象集合,由多个Partition构成,这些Partition可能存储在不同机器上。
(2)RDD可以存储在磁盘或内存中,Partition可全部存储在内存或磁盘上,也可以部分在内存中,部分在磁盘上。
(3)通过并行“转换”操作构造:Spark提供了大量API听过并行的方式构造和生成RDD。
(4)失效后自动重构:RDD可通过一定计算方式转换成另外一种RDD,这种通过转换而产生的RDD关系称为“血统”。Spark通过记录RDD的血统,可了解每个RDD的产生方式,进而能够通过重算的方式构造因机器故障或磁盘损坏而丢失的RDD数据。
? ? ? RDD只是一个逻辑概念,它可能并不对应磁盘或内存中的物理数据,而仅仅是记录了RDD的由来,RDD由五个部分组成:一组partition、每个partition的计算函数、所依赖的RDD列表、对于key-value类型的RDD包含一个partitioner(默认是hash)、计算每个partition所倾向的节点位置。
作用在RDD上的操作主要分为两类:transformation和action:transformation是转换的意思,主要作用为将一种RDD转换为另一类RDD。action是行动的意思,通过处理RDD得到一个或一组结果。
DAG:
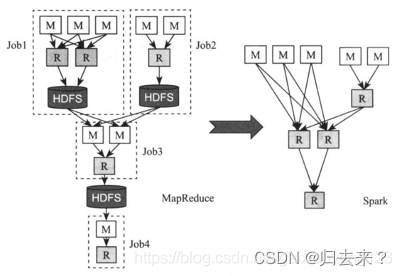
? ? ? ? Spark是一个通用的DAG引擎,这使得用户能够在一个应用程序中描述复杂的逻辑,以便于优化整个数据流,并让不同计算阶段直接通过本地磁盘或内存交换数据,而不是像MapReduce那样需要通过HDFS。
? ? ? ?下面左图是MapReduce生成的DAG数据流,右图是Spark生成的DAG数据流。可以看出,Spark的实现要简洁的多,内部不同计算单元通过本地磁盘或内存交换数据,使得磁盘和网络IO的消耗更小,性能更加高效。
四、几种计算引擎的对比
1、Spark VS MapReduce
(1)spark是基于内存进行数据处理的,MapReduce是基于磁盘进行数据处理的
MapReduce的设计:中间结果保存在文件中,提高了可靠性,减少了内存占用。但是牺牲了性能。
Spark的设计:数据在内存中进行交换,要快一些,但是内存这个东西,可靠性不如磁盘。所以性能方面比MapReduce要好。
DAG计算模型在迭代计算上还是比MapReduce的效率更高
(2)spark中具有DAG有向无环图,DAG有向无环图在此过程中减少了shuffle以及落地磁盘的次数
? ? ? ?Spark?计算比?MapReduce?快的根本原因在于?DAG?计算模型。一般而言,DAG?相比MapReduce?在大多数情况下可以减少?shuffle?次数。Spark?的?DAGScheduler?相当于一个改进版的?MapReduce,如果计算不涉及与其他节点进行数据交换,Spark?可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘?IO?的操作。但是,如果计算过程中涉及数据交换,Spark?也是会把?shuffle?的数据写磁盘的!有一个误区,Spark?是基于内存的计算,所以快,这不是主要原因,要对数据做计算,必然得加载到内存,Hadoop?也是如此,只不过?Spark?支持将需要反复用到的数据给?Cache?到内存中,减少数据加载耗时,所以?Spark?跑机器学习算法比较在行(需要对数据进行反复迭代)。Spark?基于磁盘的计算也是比?Hadoop?快。刚刚提到了?Spark?的?DAGScheduler?是个改进版的?MapReduce,所以?Spark天生适合做批处理的任务。Hadoop?的?MapReduce?虽然不如?spark?性能好,但是?HDFS?仍然是业界的大数据存储标准。
(3)spark是粗粒度资源申请,也就是当提交spark?application的时候,application会将所有的资源申请完毕,如果申请不到资源就等待,如果申请到资源才执行application,task在执行的时候就不需要自己去申请资源,task执行快,当最后一个task执行完之后task才会被释放。
优点是执行速度快,缺点是不能使集群得到充分的利用。
MapReduce是细粒度资源申请,当提交application的时候,task执行时,自己申请资源,自己释放资源,task执行完毕之后,资源立即会被释放,task执行的慢,application执行的相对比较慢。
优点是集群资源得到充分利用,缺点是application执行的相对比较慢。
MapReduce的缺陷:
1.仅支持Map和Reduce两种操作:由于MapReduce提供的编程结果比较低层次,因而实现一些常用的功能,如排序、分组等,需要编写大量的代码。
2.处理效率低:每次启动MapReduce均需要消耗大量资源,对于复杂的Hive?Sql,需要拆解成多个MapReduce作业。
3.不适合迭代式和交互式计算:MapReduce是一种基于磁盘的分布式计算框架,追求的是高吞吐率而非高性能,因此在迭代式(机器学习)和交互式(点击日志分析)等场景下表现并不好。
Spark的特点:
1.高性能:Spark采用内存计算引擎,允许用户将数据放到内存中以加快数据读取;同时,Spark提供了更加通用的DAG计算引擎,使得数据可通过本地磁盘或内存流向不同的计算单元。
2.简单易用:Spark提供了丰富的高层次API,包括sortByKey、groupByKey等操作,并且提供了四种编程语言API:Scala、Python、Java和R,从代码量看,Spark比MapReduce少2~5倍。
3.与Hadoop完好集成:Spark作为新型框架,可以部署在YARN集群桑,读取和存储HDFS/HBase中的数据。
2、Tez VS MapReduce
? ? ? Tez绕过了MapReduce很多不必要的中间的数据存储和读取的过程,直接在一个作业中表达了MapReduce需要多个作业共同协作才能完成的事情。
? ? ? Tez和MapReduce一样都运行使用YARN作为资源调度和管理。但与MapReduce?on?YARN不同,Tez?on?YARN并不是将作业提交到ResourceManager,而是提交到AMPoolServer的服务上,AMPoolServer存放着若干已经预先启动ApplicationMaster的服务。
? ? ? ?当用户提交一个作业上来后,AMPoolServer从中选择一个ApplicationMaster用于管理用户提交上来的作业,这样既可以节省ResourceManager创建ApplicationMaster的时间,而又能够重用每个ApplicationMaster的资源,节省了资源释放和创建时间。
? ? ? ?相比MR,TEZ的计算效率有所提升。当查询需要有多个reduce逻辑时,Hive的MapReduce引擎会将计划分解,每个Redcue提交一个MR作业。这个链中的所有MR作业都需要逐个调度,每个作业都必须从HDFS中重新读取上一个作业的输出并重新洗牌。而在Tez中,几个reduce接收器可以直接连接,数据可以流水线传输,而不需要临时HDFS文件,这种模式称为MRR(Map-reduce-reduce*)。
? ? ? ?Tez还允许一次发送整个查询计划,实现应用程序动态规划,从而使框架能够更智能地分配资源,并通过各个阶段流水线传输数据。对于更复杂的查询来说,这是一个巨大的改进,因为它消除了IO/sync障碍和各个阶段之间的调度开销。
? ? ? ? 在MapReduce计算引擎中,无论数据大小,在洗牌阶段都以相同的方式执行,将数据序列化到磁盘,再由下游的程序去拉取,并反序列化。Tez可以允许小数据集完全在内存中处理,而MapReduce中没有这样的优化。仓库查询经常需要在处理完大量的数据后对小型数据集进行排序或聚合,Tez的优化也能极大地提升效率。
3、Spark VS?Tez
? ? ? Spark与Tez都是以DAG方式处理数据,Spark更像是一个通用的计算引擎,提供内存计算、实时流处理、机器学习等多种计算方式,适合迭代计算。而Tez作为一个框架工具,特定为Hive和Pig提供批量计算。
? ? ? Spark属于内存计算,支持多种运行模式,可以运行在standalone、yarn上,而Tez只能跑在yarn上,但是Spark不能与其他yarn应用跑在一起。Tez能解释释放资源,重用container,节省调度时间,对内存的要求不高,而Spark如果存在迭代计算,则container一直占用资源。如果需要快速且资源充足,则可以使用Spark,否则资源是瓶颈时选择Tez或者MR。
五、HIVE底层架构及编译过程
? ? ? ?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark、 Tez 执行查询。
? ? ? ?Hive本身是支持多种计算引擎的,无论底层的计算引擎是什么,一条SQL在Hive中的逻辑计划都是一样的,而根据不同的计算引擎,它生成的物理计划就会有所差别。比如Hive On Mr生成的物理计划更多描述的是Mapreduce的相关操作,Hive On Spark生成的物理计划更多描述Spark RDD的相关操作。
1、HIVE的底层架构
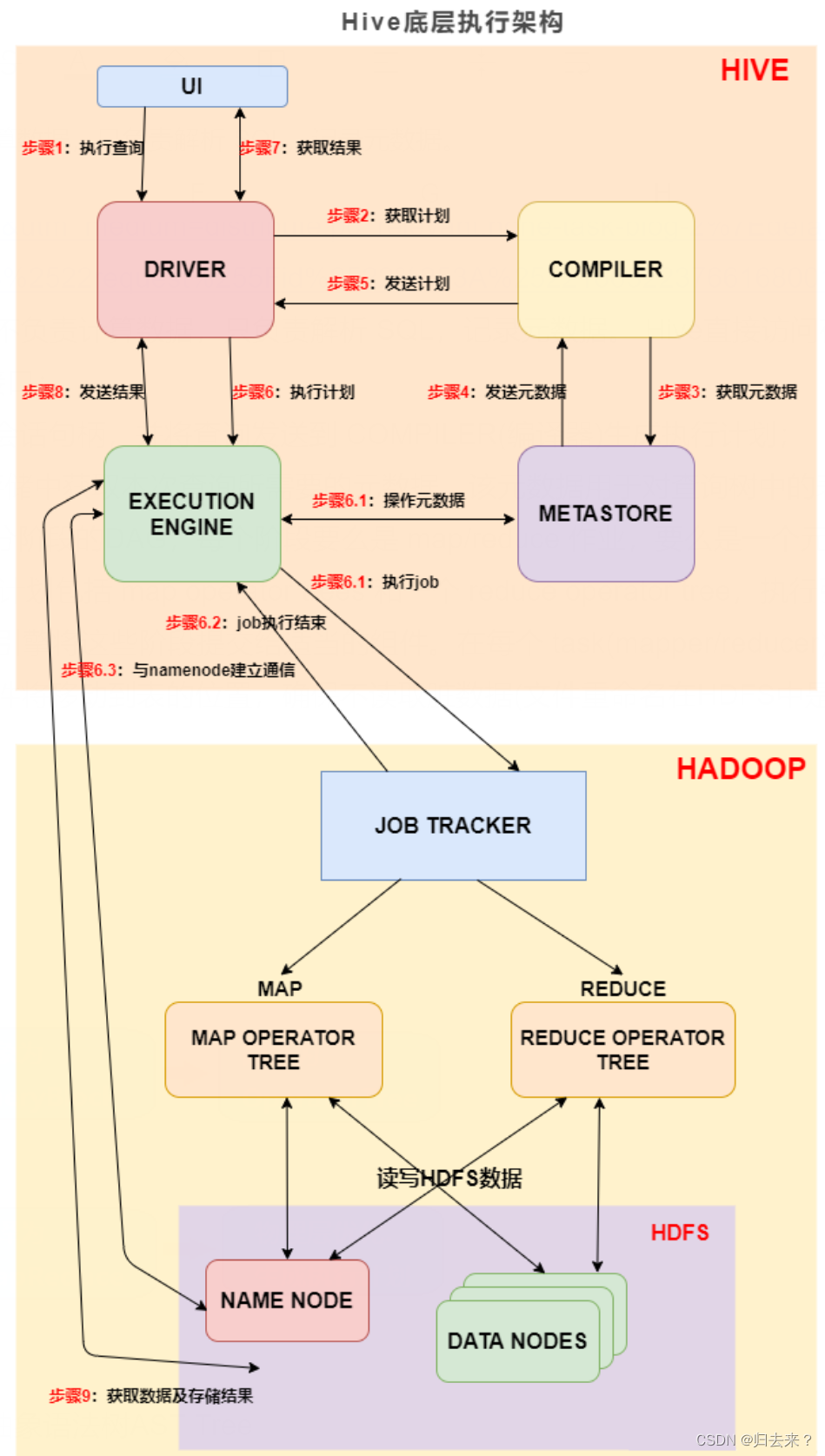
步骤1:UI 调用 DRIVER 的接口;
步骤2:DRIVER 为查询创建会话句柄,并将查询发送到 COMPILER(编译器)生成执行计划;
步骤3和4:编译器从元数据存储中获取本次查询所需要的元数据,该元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
步骤5:编译器生成的计划是分阶段的DAG,每个阶段要么是 map/reduce 作业,要么是一个元数据或者HDFS上的操作。将生成的计划发给 DRIVER。如果是 map/reduce 作业,该计划包括 map operator trees 和一个 reduce operator tree,执行引擎将会把这些作业发送给 MapReduce :
步骤6、6.1、6.2、6.3:执行引擎将这些阶段提交给适当的组件。在每个 task(mapper/reducer) 中,从HDFS文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这些数据。最终这些数据通过序列化器写入到一个临时HDFS文件中(如果不需要 reduce 阶段,则在 map 中操作)。临时文件用于向计划中后面的 map/reduce 阶段提供数据。
步骤7、8、9:最终的临时文件将移动到表的位置,确保不读取脏数据(文件重命名在HDFS中是原子操作)。对于用户的查询,临时文件的内容由执行引擎直接从HDFS读取,然后通过Driver发送到UI。
2、HIVE的编译原理
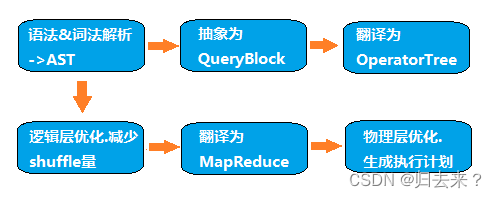
Hive是如何将SQL转化为MapReduce任务的,整个编译过程分为六个阶段:
1、语法词法解析:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree;
2、语义解析:遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
? ? ? ?AST Tree生成后由于其复杂度依旧较高,不便于翻译为mapreduce程序,需要进行进一步抽象和结构化,形成QueryBlock。QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出。简单来讲一个QueryBlock就是一个子查询。QB的生成过程为一个递归过程,先序遍历 AST Tree ,遇到不同的Token 节点(理解为特殊标记),保存到相应的属性中
3、生成逻辑执行计划:遍历QueryBlock,翻译为执行操作树OperatorTree;
? ? ? ? Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。逻辑操作符,就是在Map阶段或者Reduce阶段完成单一特定的操作。
??基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator。ReduceSinkOperator将Map端的字段组合序列化为Reduce Key/value, Partition Key,只可能出现在Map阶段,同时也标志着Hive生成的MapReduce程序中Map阶段的结束。
??Operator在MapReduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。由于Join/GroupBy/OrderBy均需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce Key/value, Partition Key。
4、优化逻辑执行计划:逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
? ? ? ?使用ReduceSinkOperator,减少shuffle数据量。大部分逻辑层优化器通过变换 OperatorTree ,合并操作符,达到减少 MapReduce Job ,减少 shuffle 数据量的目的。
Hive中的逻辑查询优化可以大致分为以下几类:
投影修剪
推导传递谓词
谓词下推:在join或聚合前提前进行数据过滤,减少参与join的数据量
将Select-Select,Filter-Filter合并为单个操作
多路 Join
查询重写以适应某些列值的Join倾斜
5、生成物理执行计划:遍历OperatorTree,翻译为MapReduce任务;
OperatorTree 转化为 Task tree的过程分为下面几个阶段:
对输出表生成 MoveTask;
从 OperatorTree 的其中一个根节点向下深度优先遍历;
ReduceSinkOperator 标示 Map/Reduce 的界限,多个 Job 间的界限;
遍历其他根节点,遇过碰到 JoinOperator 合并 MapReduceTask;
生成 StatTask 更新元数据;
剪断 Map 与 Reduce 间的 Operator 的关系;
6、优化物理执行计划:物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
Hive中的物理优化可以大致分为以下几类:
分区修剪(Partition Pruning);
基于分区和桶的扫描修剪(Scan pruning);
如果查询基于抽样,则扫描修剪;
在某些情况下,在 map 端应用 Group By;
在 mapper 上执行 Join;
优化 Union,使Union只在 map 端执行;
在多路 Join 中,根据用户提示决定最后流哪个表;
删除不必要的 ReduceSinkOperators;
对于带有Limit子句的查询,减少需要为该表扫描的文件数;
对于带有Limit子句的查询,通过限制 ReduceSinkOperator 生成的内容来限制来自 mapper 的输出;
减少用户提交的SQL查询所需的Tez作业数量;
如果是简单的提取查询,避免使用MapReduce作业;
对于带有聚合的简单获取查询,执行不带 MapReduce 任务的聚合;
重写 Group By 查询使用索引表代替原来的表;
当表扫描之上的谓词是相等谓词且谓词中的列具有索引时,使用索引扫描;?
六、MR实现HQL操作的原理(生成物理执行计划)
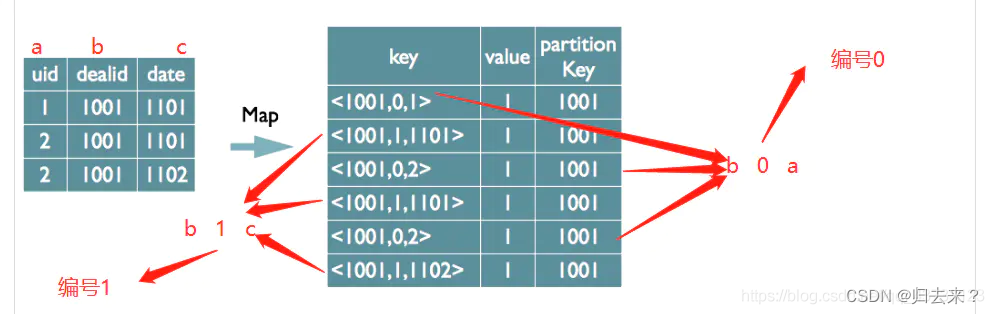
1、join的实现原理
在map的输出velue中为不同表的数据打上tag标记,在reduce阶段判断数据来源根据tag;
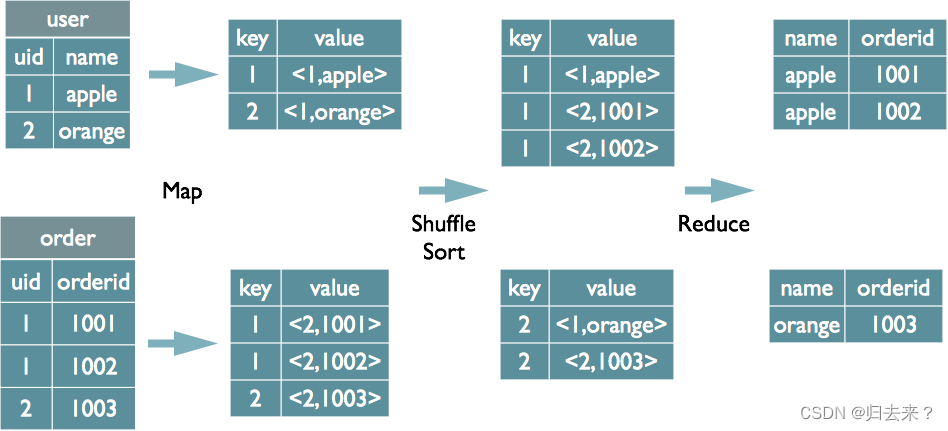
Map:
1、以?JOIN?ON?条件中的列作为?Key,如果有多个列,则?Key?是这些列的组合
2、以?JOIN?之后所关心的列作为?Value,当有多个列时,Value?是这些列的组合。在?Value?中还会包含表的?Tag?信息,用于标明此?Value?对应于哪个表
3、按照?Key?进行排序
Shuffle:
1、根据?Key?的值进行?Hash,并将?Key/Value?对按照?Hash?值推至不同对?Reduce?中
Reduce:
1、?Reducer?根据?Key?值进行?Join?操作,并且通过?Tag?来识别不同的表中的数据
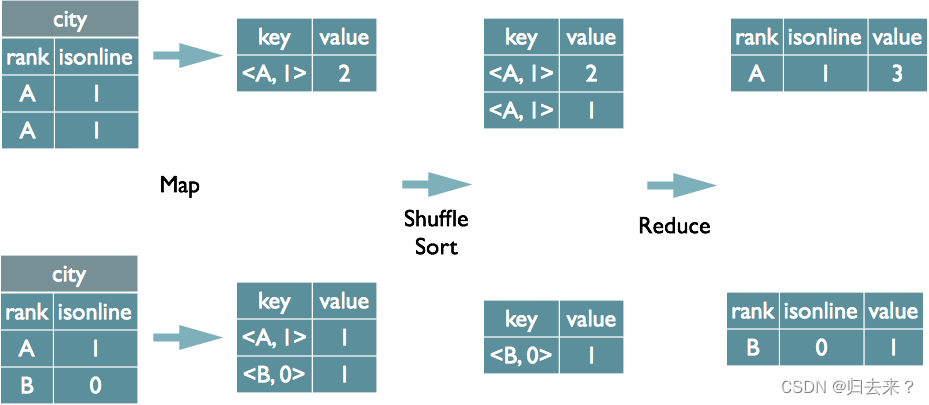
2、group by 的实现原理
? ? ? ?将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的key;
3、distinct的实现原理
? ? ? 当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作 为reduce的key,在reduce阶段保存LastKey即可完成去重;?
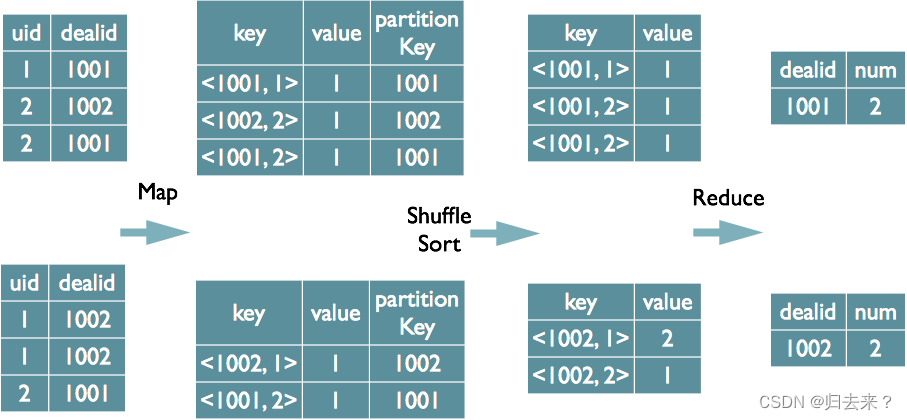
? ? ? ?当有多个distinct字段时,对所有的distinct字段编号,每行数据生成n行数据,那么相同字段就会分别排序,这时只需要在reduce阶段记录LastKey即可去重。这种实现方式很好的利用了MapReduce的排序,节省了reduce阶段去重的内存消耗,但是缺点是增加了shuffle的数据量。需要注意的是,在生成reduce value时,除第一个distinct字段所在行需要保留value值,其余distinct数据行value字段均可为空;
?4、order by的实现
只在reduce端执行,且1个order by 对应1个reducer。