文章目录
0. 简介
FlinkCDC是什么
- CDC Connectors for Apache Flink 是一组用于Apache Flink 的源连接器,使用变更数据捕获(CDC)从不同的数据库接收变更。用于ApacheFlink 的CDC连接器集成了Debezium(讲数据库转换成事件流)作为捕获数据更改的引擎。因此,它可以充分利用Debezium的能力
- 将数据库中的数据转换成Flink的数据流(StreamData)或 Table&SQL 的形式进行处理操作
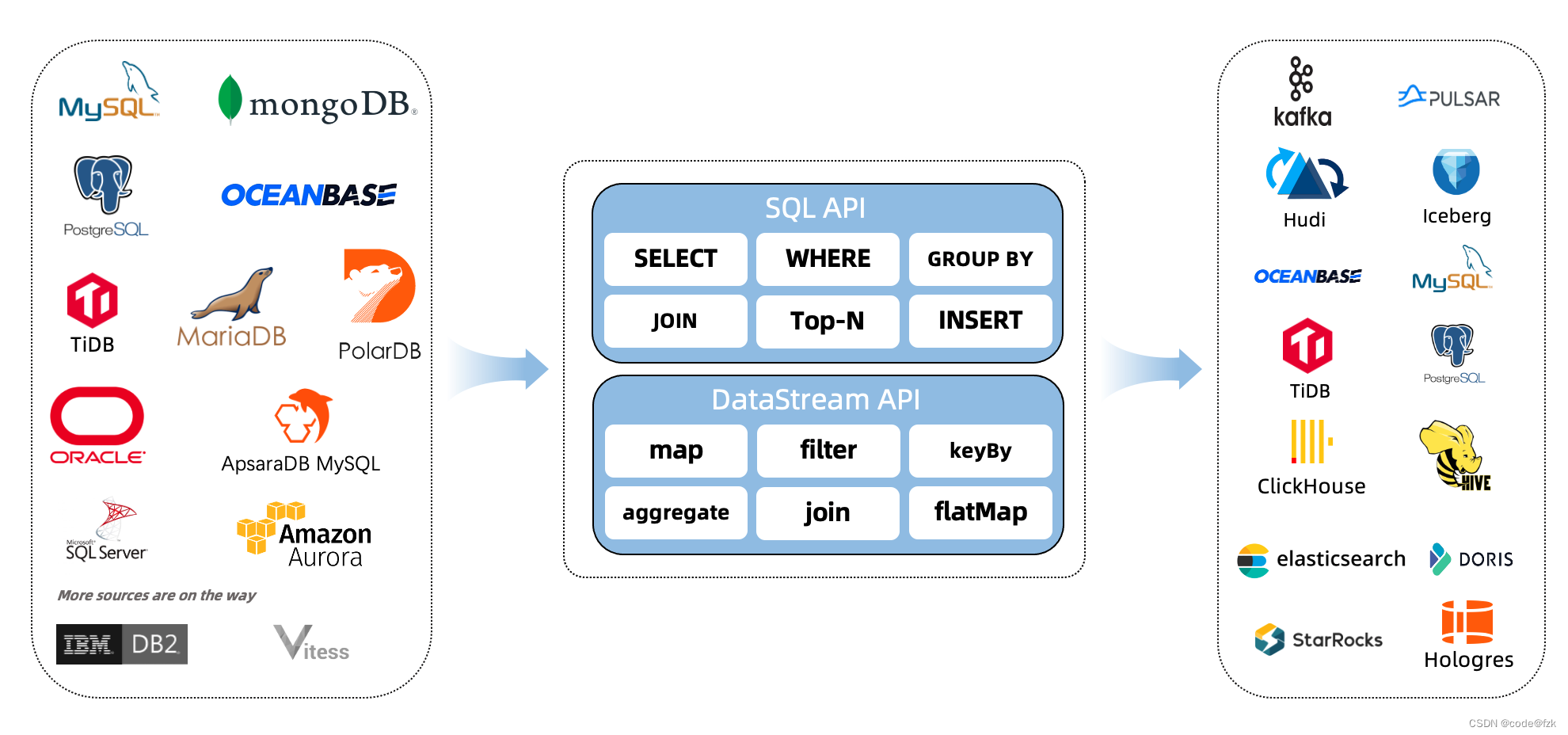
支持的连接源及版本
| Connector | Database | Driver |
|---|---|---|
| mongodb-cdc | [MongoDB]: 3.6, 4.x, 5.0 | MongoDB Driver: 4.3.1 |
| mysql-cdc | [MySQL]: 5.6, 5.7, 8.0.x [RDS MySQL]: 5.6, 5.7, 8.0.x [PolarDB MySQL]: 5.6, 5.7, 8.0.x [Aurora MySQL]: 5.6, 5.7, 8.0.x [MariaDB]: 10.x [PolarDB X]: 2.0.1 | JDBC Driver: 8.0.27 |
| oceanbase-cdc | [OceanBase CE]: 3.1.x [OceanBase EE]【MySQL mode】: 2.x, 3.x | JDBC Driver: 5.1.4x |
| oracle-cdc | [Oracle]: 11, 12, 19 | Oracle Driver: 19.3.0.0 |
| postgres-cdc | [PostgreSQL]: 9.6, 10, 11, 12 | JDBC Driver: 42.2.12 |
| sqlserver-cdc | [Sqlserver]: 2012, 2014, 2016, 2017, 2019 | JDBC Driver: 7.2.2.jre8 |
| tidb-cdc | [TiDB]: 5.1.x, 5.2.x, 5.3.x, 5.4.x, 6.0.0 | JDBC Driver: 8.0.27 |
FlinkCDC与Flink版本
| Flink CDC Version | Flink Version |
|---|---|
| 1.0.0 | 1.11.x |
| 1.1.0 | 1.11.x |
| 1.2.0 | 1.12.x |
| 1.3.0 | 1.12.x |
| 1.4.0 | 1.13.x |
| 2.0.x | 1.13.x |
| 2.1.x | 1.13.x |
| 2.2.x | 1.13.x, 1.14.x |
1. 用法(MySQL为例)
DataStream Source
代码
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Flink-CDC 将读取 binlog 的位置信息以状态的方式保存在 CK,如果想要做到断点续传,需要从 Checkpoint 或者 Savepoint 启动程序
//2.1 开启 Checkpoint,每隔 5 秒钟做一次 CK
env.enableCheckpointing(5000L);
//2.2 指定 CK 的一致性语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2.3 设置任务关闭的时候保留最后一次 CK 数据
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//2.4 指定从 CK 自动重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
//2.5 设置状态后端
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC"));
//2.6 设置访问 HDFS 的用户名
System.setProperty("HADOOP_USER_NAME", "xxx");
//3.创建 Flink-MySQL-CDC 的 Source
DebeziumSourceFunction<String> mysqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.username("yourUsername")
.password("yourPassword")
.databaseList("test")
.tableList("test.book") //可选配置项,如果不指定该参数,则会读取databaseList下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.deserializer(new StringDebeziumDeserializationSchema()) // 序列化,输出的数据格式,StringDebeziumDeserializationSchema是String格式的数据
.build();
//4.使用 CDC Source 从 MySQL 读取数据
DataStreamSource<String> sourceData = env.addSource(mysqlSource);
//5.打印数据
sourceData.print();
//6.执行任务
env.execute();
}
自定义反序列化器
-
上面所用的反序列化器
new StringDebeziumDeserializationSchema()是自带的String字符串序列化器 -
我们可以自定义反序列化器,实现
DebeziumDeserializationSchemapublic static void main(String[] args) throws Exception { //1.创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.Flink-CDC 将读取 binlog 的位置信息以状态的方式保存在 CK,如果想要做到断点续传,需要从 Checkpoint 或者 Savepoint 启动程序 //2.1 开启 Checkpoint,每隔 5 秒钟做一次 CK env.enableCheckpointing(5000L); //2.2 指定 CK 的一致性语义 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //2.3 设置任务关闭的时候保留最后一次 CK 数据 env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); //2.4 指定从 CK 自动重启策略 env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L)); //2.5 设置状态后端 env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC")); //2.6 设置访问 HDFS 的用户名 System.setProperty("HADOOP_USER_NAME", "xxx"); //3.创建 Flink-MySQL-CDC 的 Source DebeziumSourceFunction<String> mysqlSource = MySqlSource.<String>builder() .hostname("yourHostname") .port(yourPort) .username("yourUsername") .password("yourPassword") .databaseList("test") .tableList("test.book") .deserializer(new DebeziumDeserializationSchema<String>() { /** * 反序列化操作 * @param sourceRecord 源数据 * @param collector * @throws Exception */ @Override public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception { // TODO 序列化逻辑,最终将反序列化后的数据通过 collector.collect() 方法输出 collector.collect(xxx); } // 序列化类型 @Override public TypeInformation<String> getProducedType() { return TypeInformation.of(String.class); } }) .build(); //4.使用 CDC Source 从 MySQL 读取数据 DataStreamSource<String> sourceData = env.addSource(mysqlSource); //5.打印数据 sourceData.print(); //6.执行任务 env.execute(); }
Table/SQL API
代码
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建 Flink-MySQL-CDC 的 Source
tableEnv.executeSql("CREATE TABLE user_info (" +
" id INT," +
" name STRING," +
" phone_num STRING" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'yourHostname'," +
" 'port' = 'yourPort'," +
" 'username' = 'yourUsername'," +
" 'password' = 'yourPassword'," +
" 'database-name' = 'gmall-flink'," +
" 'table-name' = 'z_user_info'" +
")");
// 3.执行sql,并打印
tableEnv.executeSql("select * from user_info").print();
// 4.执行任务
env.execute();
}
MySQL参数列举
| Option | Required | Default | Type | Description |
|---|---|---|---|---|
| connector | required | (none) | String | 指定要使用的连接器, 这里应该是 'mysql-cdc'. |
| hostname | required | (none) | String | MySQL 数据库服务器的 IP 地址或主机名。 |
| username | required | (none) | String | 连接到 MySQL 数据库服务器时要使用的 MySQL 用户的名称。 |
| password | required | (none) | String | 连接 MySQL 数据库服务器时使用的密码。 |
| database-name | required | (none) | String | 要监视的 MySQL 服务器的数据库名称。数据库名称还支持正则表达式,以监视多个与正则表达式匹配的表。 |
| table-name | required | (none) | String | 要监视的 MySQL 数据库的表名。表名还支持正则表达式,以监视多个表与正则表达式匹配。 |
| port | optional | 3306 | Integer | MySQL 数据库服务器的整数端口号。 |
| server-id | optional | (none) | String | 读取数据使用的 server id,server id 可以是个整数或者一个整数范围,比如 ‘5400’ 或 ‘5400-5408’, 建议在 ‘scan.incremental.snapshot.enabled’ 参数为启用时,配置成整数范围。因为在当前 MySQL 集群中运行的所有 slave 节点,标记每个 salve 节点的 id 都必须是唯一的。 所以当连接器加入 MySQL 集群作为另一个 slave 节点(并且具有唯一 id 的情况下),它就可以读取 binlog。 默认情况下,连接器会在 5400 和 6400 之间生成一个随机数,但是我们建议用户明确指定 Server id。 |
| scan.incremental.snapshot.enabled | optional | true | Boolean | 增量快照是一种读取表快照的新机制,与旧的快照机制相比, 增量快照有许多优点,包括: (1)在快照读取期间,Source 支持并发读取, (2)在快照读取期间,Source 支持进行 chunk 粒度的 checkpoint, (3)在快照读取之前,Source 不需要数据库锁权限。 如果希望 Source 并行运行,则每个并行 Readers 都应该具有唯一的 Server id,所以 Server id 必须是类似 5400-6400 的范围,并且该范围必须大于并行度。 请查阅 增量快照读取 章节了解更多详细信息。 |
| scan.incremental.snapshot.chunk.size | optional | 8096 | Integer | 表快照的块大小(行数),读取表的快照时,捕获的表被拆分为多个块。 |
| scan.snapshot.fetch.size | optional | 1024 | Integer | 读取表快照时每次读取数据的最大条数。 |
| scan.startup.mode | optional | initial | String | MySQL CDC 消费者可选的启动模式, 合法的模式为 “initial” 和 “latest-offset”。 请查阅 启动模式 章节了解更多详细信息。 |
| server-time-zone | optional | (none) | String | 数据库服务器中的会话时区, 例如: “Asia/Shanghai”. 它控制 MYSQL 中的时间戳类型如何转换为字符串。 更多请参考 这里. 如果没有设置,则使用ZoneId.systemDefault()来确定服务器时区。 |
| debezium.min.row. count.to.stream.result | optional | 1000 | Integer | 在快照操作期间,连接器将查询每个包含的表,以生成该表中所有行的读取事件。 此参数确定 MySQL 连接是否将表的所有结果拉入内存(速度很快,但需要大量内存), 或者结果是否需要流式传输(传输速度可能较慢,但适用于非常大的表)。 该值指定了在连接器对结果进行流式处理之前,表必须包含的最小行数,默认值为1000。将此参数设置为0以跳过所有表大小检查,并始终在快照期间对所有结果进行流式处理。 |
| connect.timeout | optional | 30s | Duration | 连接器在尝试连接到 MySQL 数据库服务器后超时前应等待的最长时间。 |
| connect.max-retries | optional | 3 | Integer | 连接器应重试以建立 MySQL 数据库服务器连接的最大重试次数。 |
| connection.pool.size | optional | 20 | Integer | 连接池大小。 |
| jdbc.properties.* | optional | 20 | String | 传递自定义 JDBC URL 属性的选项。用户可以传递自定义属性,如 ‘jdbc.properties.useSSL’ = ‘false’. |
| heartbeat.interval | optional | 30s | Duration | 用于跟踪最新可用 binlog 偏移的发送心跳事件的间隔。 |
| debezium.* | optional | (none) | String | 将 Debezium 的属性传递给 Debezium 嵌入式引擎,该引擎用于从 MySQL 服务器捕获数据更改。 For example: 'debezium.snapshot.mode' = 'never'. 查看更多关于 Debezium 的 MySQL 连接器属性 |
Maven
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>