flilnk在消费kafka数据的时候,我们习惯性的add一个kafkaConsumer,似乎万年不变,但是单我们需求变化的时候,我们该怎么办?
DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>( "clicks", new SimpleStringSchema(), properties )); stream.print("Kafka");注意 这里的DataStreamSource 的类型是string,而这个string就是kafka的value
?现在有需求,我们要获取kafka的的timestamp,然后跟进入flink的时间的对比,看flink处理数据的延迟时间有多少?
那么我们如何获取这个timstamp呢?
?最简单的办法,百度。 这位是用scala写的。
flink读取kafka中的数据的所有信息_第一片心意的博客-CSDN博客_flink读取kafka的数据
我就用java写了个。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.Headers;
import java.text.SimpleDateFormat;
import java.util.*;
public class SourceKafkaConsumerRecordTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "xxxxxx1:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"ia-label",
new SimpleStringSchema(),
properties
);
FlinkKafkaConsumer<MyConsumerRecord> consumer2 = new FlinkKafkaConsumer<>(
"ia-label",
new KafkaDeserializationSchema<MyConsumerRecord>() {
@Override
public boolean isEndOfStream(MyConsumerRecord s) {
return false;
}
@Override
public MyConsumerRecord deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) throws Exception {
Headers headers = consumerRecord.headers();
HashMap<String, String> headerMap = new HashMap<>();
for (Header header : headers) {
headerMap.put(header.key(),new String(header.value()));
}
byte[] key1 = consumerRecord.key();
byte[] value1 = consumerRecord.value();
String key = key1==null?null:new String(key1);
String value = new String(value1);
String timeStamp=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(consumerRecord.timestamp());
MyConsumerRecord myConsumerRecord = new MyConsumerRecord(key, value, timeStamp, headerMap);
System.out.println(myConsumerRecord);
return myConsumerRecord;
}
@Override
public TypeInformation<MyConsumerRecord> getProducedType() {
return TypeInformation.of(MyConsumerRecord.class);
}
},
properties
);
consumer2.setStartFromEarliest();
consumer.setStartFromEarliest();
// DataStreamSource<String> stream = env.addSource(consumer);\
// stream.print("Kafka");
DataStreamSource<MyConsumerRecord> stream2 = env.addSource(consumer2);
stream2.print("All");
env.execute();
}
static class MyConsumerRecord{
String key;
String value;
String timeStamp;
Map<String,String> header;
public MyConsumerRecord(String key, String value, String timeStamp, Map<String, String> header) {
this.key = key;
this.value = value;
this.timeStamp = timeStamp;
this.header = header;
}
@Override
public String toString() {
return "MyConsumerRecord{" +
"key='" + key + '\'' +
", value='" + value + '\'' +
", timeStamp='" + timeStamp + '\'' +
", header=" + header +
'}';
}
}
}
打印输出如下
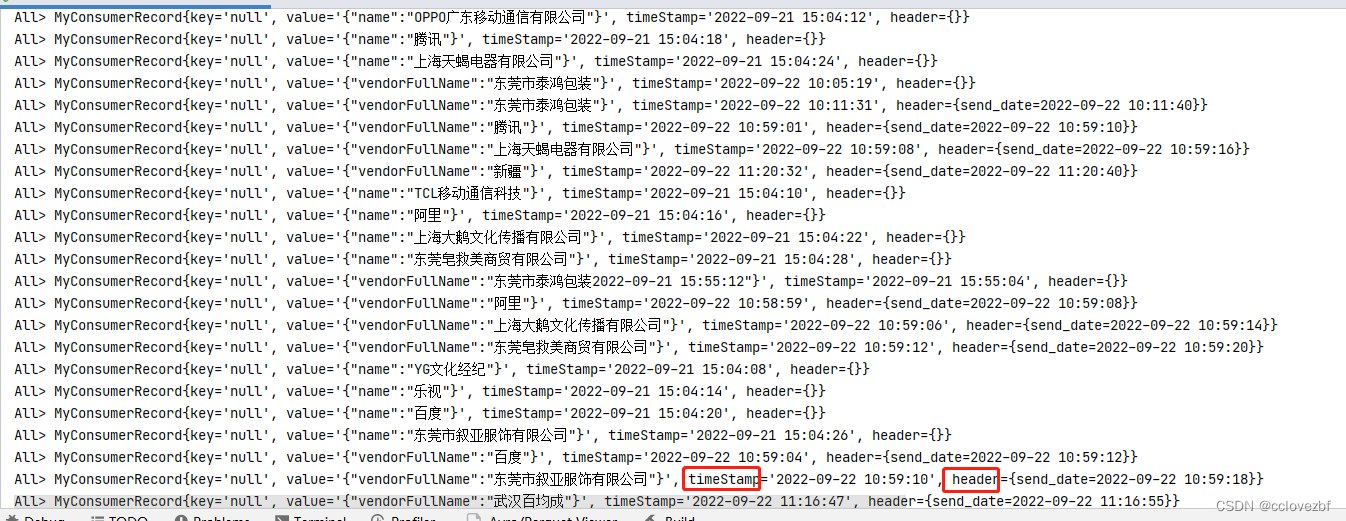
?ok。 还可以获取 partition offset 这些信息,看自己了。