Ŀ¼
һ�����ò�ѯ
(����ɾ���ġ���)
? ? ? ?��MySQL���ݿ�IJ�ѯ,���˻����IJ�ѯ��,��ʱ����Ҫ�Բ�ѯ�Ľ�������д���������ֻȡ�������ݡ��Բ�ѯ���������������ȵȡ�
1.���ؼ�������
�����windows���������
? ? ? ?ʹ��SELECT�����Խ���Ҫ�����ݴ�MySQL���ݿ��в�ѯ����,����Բ�ѯ�Ľ����������,����ʹ��ORDER? ?BY����������ʵ������,�����ս������Ľ�����ظ��û��������������������ijһ���ֶ�,Ҳ������Զ���ֶΡ�
�
select column1, column2, ... FROM table_name order by colunn1, column2, ...ASC|DESC;
? ? ? ?? ? ? ? ASC�ǰ���������������,��Ĭ�ϵ�����ʽ,��ASC����ʡ�ԡ�select��������û��ָ�����������ʽ,��Ĭ�ϰ�ASC��ʽ��������
? ? ? ?DESC�ǰ�����ʽ�������С���Ȼorder byǰ��Ҳ����ʹ��where�Ӿ�Բ�ѯ�����һ�����ˡ�
��:
���ݿ���һ�ű�,��¼��id,����,����,��ַ�Ͱ���
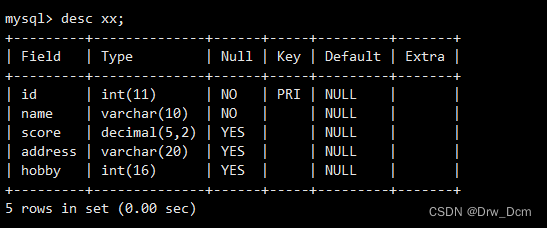
create table ���� (id int, name varchar(10) primary key not null,score decimal(5,2),address varchar (20), hobbid int(5));
insert into info values(1,'liuyi',80, 'beijing',2);
insert into info values (2,'wangwu',90,'shengzheng',2);
insert into info values(3,'lisi',60,'shanghai',4);
insert into info values(4,'tianqi',99,'hangzhou',5);
insert into info values(5,'j iaoshou',98,'laowo',3);
insert into info values (6,'hanmeimei',10,'nanjing,3);
insert into info values(7,'lilei',11,'nanjing',5);
select * from ����; ??
??
 ?
?
 ??
??
����������,Ĭ�ϲ�ָ������������
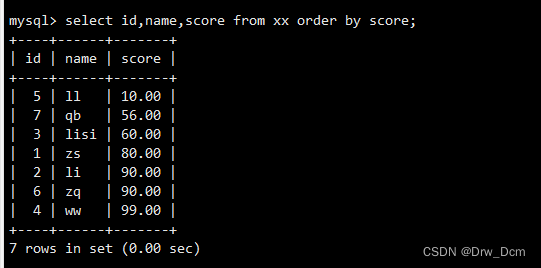
select id, name, score from ���� order by score;
?
��������������
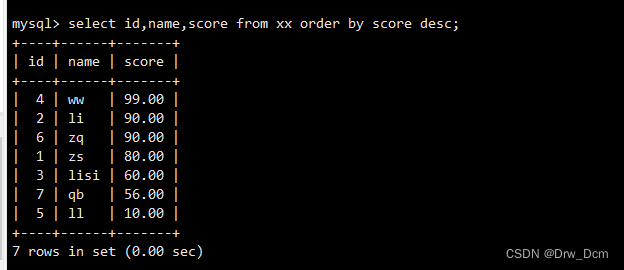
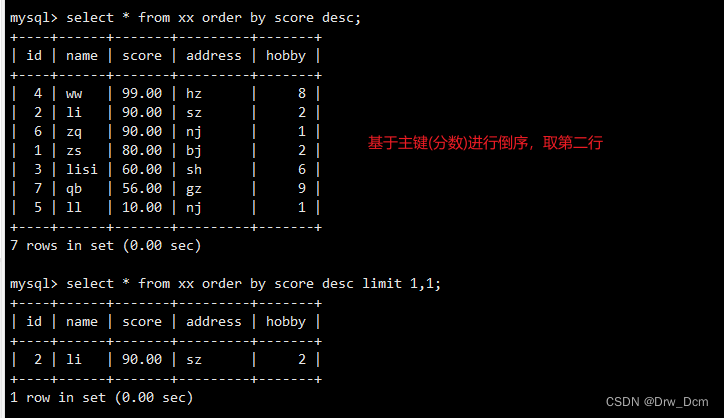
select id, name, score from ���� order by score desc;
 ??
??
 ??
??
 ?
? ??
??
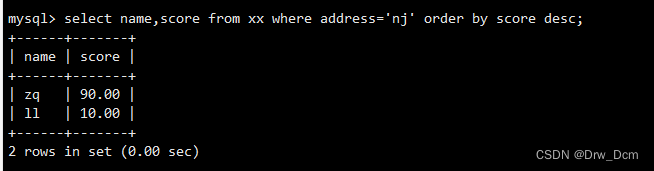
order? by�����Խ��where������������,ɸѡij����ַ��ѧ����������������
select name, score from ���� where address-'address' order by score desc;
?
order? by
? ? ? ? ���Ҳ����ʹ�ö���ֶ�����������,������ĵ�--���ֶ���ͬ�ļ�¼�ж����������,��Щ�����ļ�¼�ٰ��յڶ����ֶν�������,order? by���������ֶ�ʱ,�ֶ�֮��ʹ��Ӣ�Ķ��Ÿ���,���ȼ��ǰ��Ⱥ�˳�������
? ? ? ? ��order by֮��ĵ�һ������ֻ���ڳ�����ֵͬʱ,�ڶ����ֶβ�������
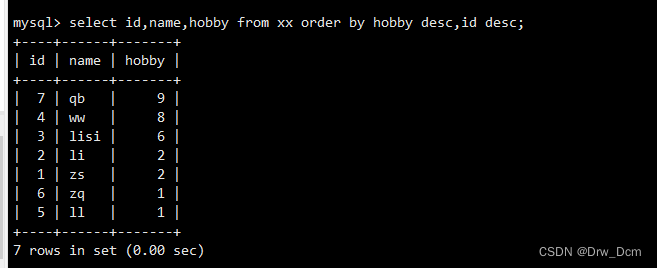
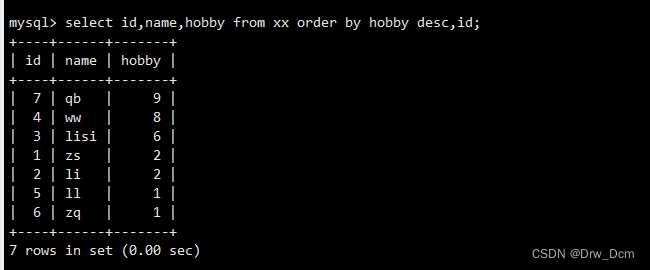
�ٲ�ѯѧ����Ϣ�Ȱ���Ȥid��������,��ͬ������,idҲ���������С�select id, name, hobbid from ���� order by hobbid desc, id desc;�ڲ�ѯѧ����Ϣ�Ȱ���Ȥid��������,��ͬ������,id����������
select id, name, hobbid from ���� order by hobbid desc, id;
 ?
?
 ?
?
?2.�����жϼ���ѯ���ظ���¼
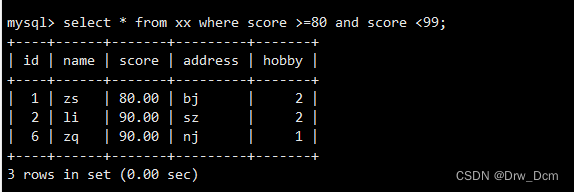
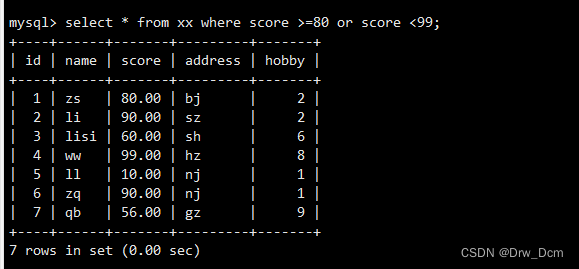
��and/orһ��/��
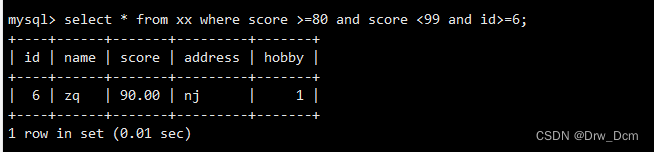
?select * from ����?where score >80 and score <=99; select * from ���� where score >80 or score <=99;Ƕ��/������
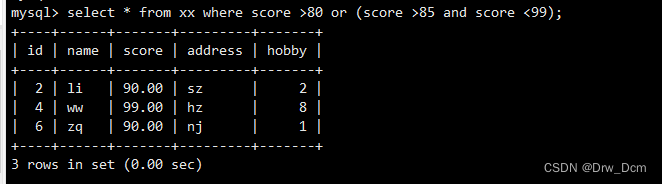
select * from ���� where score >80 or (score >85 and score <99);����:
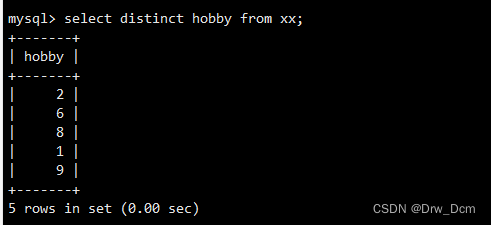
��distinct ��ѯ���ظ���¼
�:
?select distinct �ֶ� from ����; select distinct hobbid from ����;
 ?
?
?
 ?
?
?
 ?
?
?3.�Խ�����з���
? ? ? ?ͨ��SQL��ѯ�����Ľ��,�����Զ�����з���,ʹ��group by�����ʵ��,group by
ͨ�����ǽ�ϾۺϺ���һ��ʹ�õ�,���õľۺϺ�������:����(COUNT)�����(SUM)����ƽ����(AVG) �����ֵ(MAX) ����Сֵ(MIN),group by�����ʱ�����һ�������ֶζԽ�����з��鴦����(1) �??
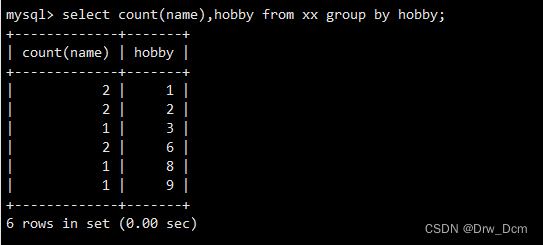
select column_name, aggregate_function (column_name) from table_name where column_name operator value group by?column_name;��hobbid��ͬ�� ����,������ͬ������ѧ������( ����name�������м���)
select count (name),hobby from ���� group by hobby;?���where���, ɸѡ�������ڵ���80�ķ���,����ѧ������
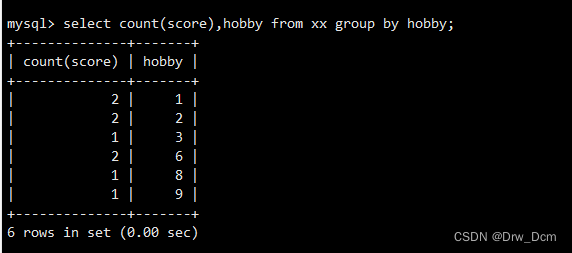
select count (name) ,hobby from ���� where score>=80 group by hobby;���order by �Ѽ������ѧ����������������
select count (name) , score,hobby from ���� where score>=80 group by hobby order by count (name) asc;
 ?
?
 ?
?
?4.���ƽ����Ŀ(limit)
limit��������Ľ����¼
? ? ? ?��ʹ��MySQLSELECT�����в�ѯʱ,��������ص�������ƥ��ļ�¼(��)����ʱ�����Ҫ���ص�һ�л���ǰ����,��ʱ�����Ҫ�õ�limit�Ӿ䡣(1)�
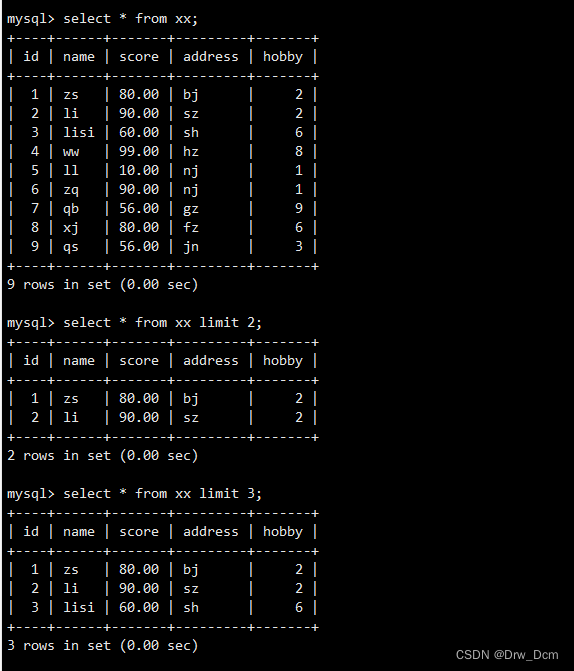
select column1, column2, ... from table_name limit [offset, ] numberlimit �ĵ�һ��������λ��ƫ����(��ѡ����),������MySQL����һ�п�ʼ��ʾ��
������趨��һ������,����ӱ��еĵ�һ����¼��ʼ��ʾ����Ҫע�����,��һ����¼��λ��ƫ������0, �ڶ�����1,�Դ����ơ��ڶ������������÷��ؼ�¼�е������Ŀ����ѯ������Ϣ��ʾǰ4�м�¼
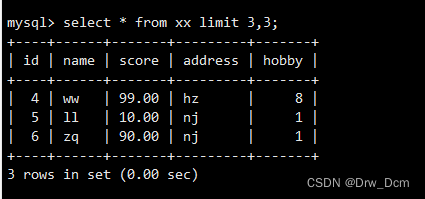
select * from ���� limit 3;�ӵ�4�п�ʼ,������ʾ3������
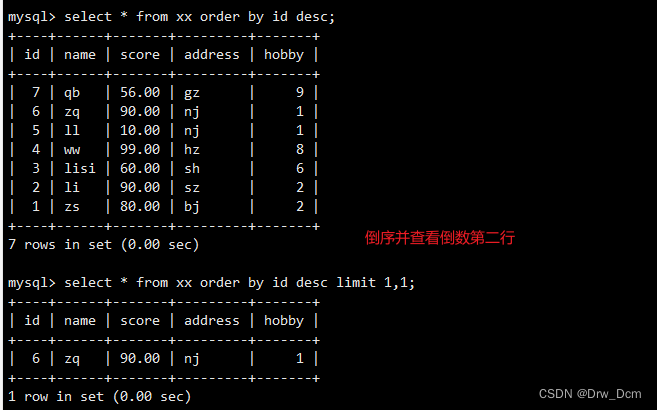
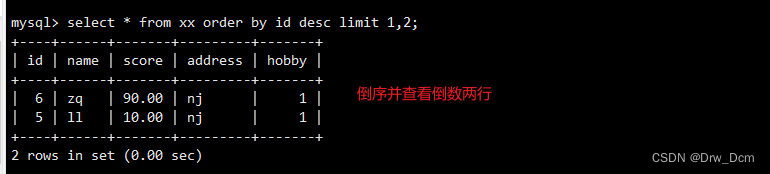
select * from ���� limit 3,3;���order by���,��id�Ĵ�С����������ʾǰ����
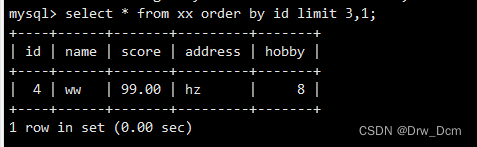
select id,name from ���� order by id limit 3.����������
select id, name from ���� order by id desc limit 3;select * from ���� order by �����ֶ� desc limit ;
 ?
?
 ?
?
 ?
?
?5.����(alias��as)
? ? ? ?
? ? ? ?��MySQL��ѯʱ,���������ֱȽϳ����߱���ijЩ�ֶαȽϳ�ʱ,Ϊ�˷�����д���߶��ʹ����ͬ�ı�,���Ը��ֶ��л�����ñ�����ʹ�õ�ʱ��ֱ��ʹ�ñ���,�������,��ǿ�ɶ��ԡ�
�
�����еı���select column_name as alias_name from table_name;?���ڱ��ı���
select column_name(s) from table_name as alias_name;? ? ? ?��ʹ��as��,������alias_name ����table_name, ����as����ǿ�ѡ�ġ�as֮��ı���,��Ҫ��Ϊ���ڵ��л��߱��ṩ��ʱ������,�ڲ�ѯ������ʹ��,����ʵ�ʵı������ֶ����Dz��ᱻ�ı�ġ�
�б�������ʾ��:
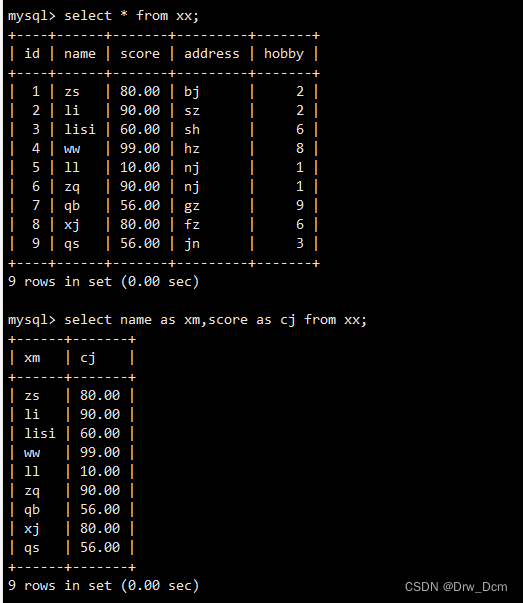
select name as ����,score as�ɼ� from info;������ij��ȱȽϳ�,����ʹ��as�������ñ���,�ڲ�ѯ�Ĺ�����ֱ��ʹ�ñ�����
��ʱ�������ݱ��ı���Ϊi
select name as ����,score as �ɼ� from ���� as i;��ѯ���ݱ����ֶ�����,��number ��ʾ
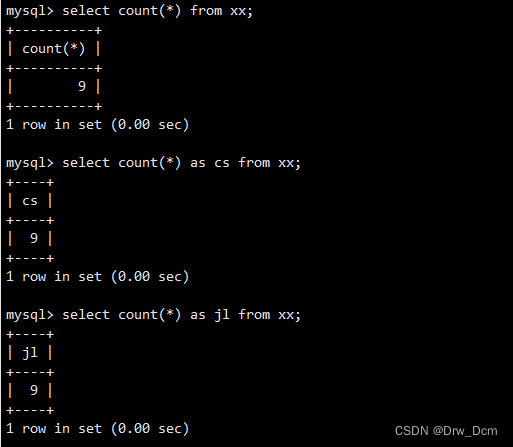
select count (*) as number from ����;����asҲ����,һ����ʾ
select count(*) number from ����;ʹ�ó���:
(1)�Ը��ӵı����в�ѯ��ʱ��,�����������̲�ѯ���ij��ȡ�
(2)���������ѯ��ʱ��(ͨ����������sql���)����,as��������Ϊ�������IJ�������
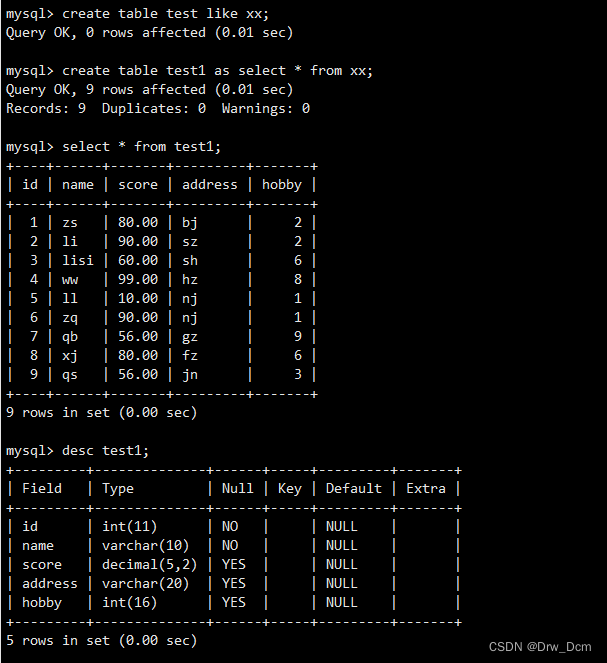
����t1��,�����ݱ��IJ�ѯ��¼ȫ������t1��create table test1 like info; create table t1 as select * from ����; select * from t1;�˴�as������:
(1)������һ���±�t1��������ṹ,���������(��info����ͬ)
(2)����"Լ����û�б���ȫ�����ơ�����#�������ԭ������������,��ô������: default�ֶλ�Ĭ������һ��0
����:
��¡�����Ʊ��ṹcreate table t1?(select * from ����) ;Ҳ���Լ���where����ж�
create table test1 as select * from ���� where score >=60;��Ϊ�����ñ���ʱ,Ҫ��֤�������������ݿ��е������������Ƴ�ͻ��
�еı������ڽ��������ʾ��,�����ı����ڽ����û����ʾ,ֻ��ִ�в�ѯʱʹ�á�
 ?
?
 ?
?
?
 ?
?
?6.ͨ���
ͨ�����Ҫ�����滻�ַ����еIJ����ַ�,ͨ�������ַ���ƥ�佫��ؽ����ѯ������
? ? ? ? ͨ��ͨ������Ǹ�likeһ��ʹ�õ�,��ЭͬWHERE �Ӿ乲ͬ����ɲ�ѯ�����õ�ͨ���������,�ֱ���:
%:�ٷֺ���ʾ�����һ�������ַ���? ? *? ?(ͨ���)
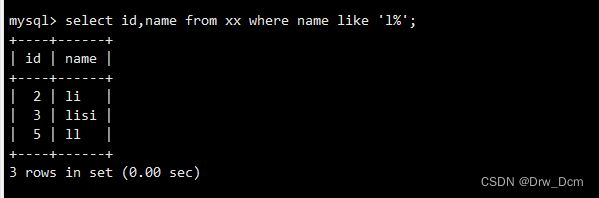
_ :�»��߱�ʾ�����ַ���? ? ? ? ? ? ? ? ? ? ? ? ? .? ?(�����ַ�)��ѯ������c��ͷ�ļ�¼
select id, name from ���� where name like 'c%' ;��ѯ��������c��i�м���һ���ַ��ļ�¼
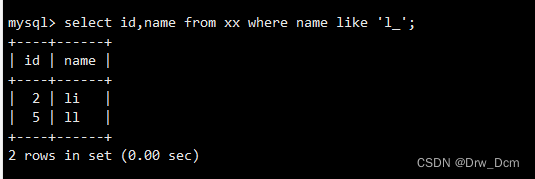
select id,name from ���� where name like 'c_ic_i';��ѯ�����м���g�ļ�¼
select id, name from ���� where name like '%g%' ;��ѯָ�����ݺ���3���ַ������ּ�¼
select id, name from ���� where name like 'ָ������__';ͨ�����%���͡� "�������Ե���ʹ��,Ҳ�������ʹ��
��ѯ������s��ͷ�ļ�¼select id, name from ���� where name like 's%_';
 ?
?
 ?
?
?7.�Ӳ�ѯ
? ? ? ?
? ? ? ? �Ӳ�ѯҲ�������ڲ�ѯ����Ƕ�ײ�ѯ,��ָ��һ����ѯ������滹Ƕ������һ����ѯ��䡣�Ӳ�ѯ�������������ѯ��䱻ִ�е�,������Ϊ�����������ظ�����ѯ������һ���IJ�ѯ���ˡ�
PS:�������������������ѯ�ı���ͬ,Ҳ�����Dz�ͬ������ͬ��ʾ��:
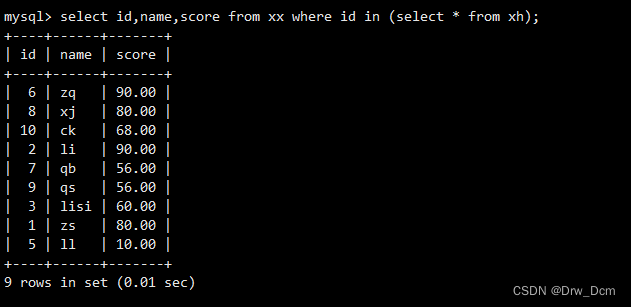
select name, score from ���� where id in (select id from ���� where score >80);���������
select name,score from info where id?�����(����):
select id from info where score >80;PS:������е�sq1�����Ϊ��,�����˳�-һ�������,�����������ж�����
in: ���������ӱ�����/���ӵ����ͬ��/���ʾ��:?
create table ���� (id int);? insert into ���� values(1),(2),(3);�����ѯ
select id,name,score from ���� where id in (select * from ����);? ? ? ?�Ӳ�ѯ����������select �����ʹ��,��insert��update��delete��Ҳͬ�����á���Ƕ��ʱ��,�Ӳ�ѯ�ڲ��������ٴ�Ƕ���µ��Ӳ�ѯ,Ҳ����˵���Զ��Ƕ�ס�
�
in �����ж�ij��ֵ�Ƿ��ڸ����Ľ������,ͨ������Ӳ�ѯ��ʹ���:
<����ʽ> [not] in <�Ӳ�ѯ>
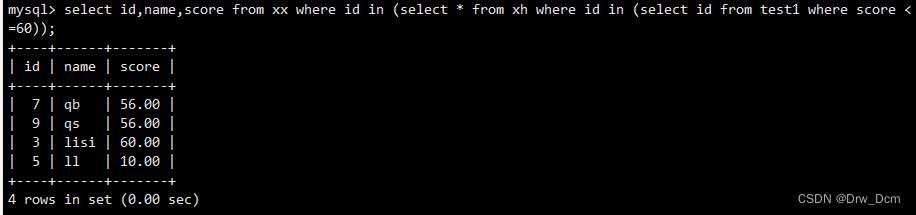
? ? ? ? ������ʽ�� �Ӳ�ѯ���صĽ�����е�ij��ֵ���ʱ,����true,���� false����������not�ؼ���,��ֵ�෴����Ҫע�����,�Ӳ�ѯֻ�ܷ���һ������,�������Ƚϸ���,һ�н����������,����ʹ�ö��Ƕ�ķ�ʽ��Ӧ�ԡ����������,�Ӳ�ѯ������select���һ��ʹ�õġ���ѯ��������80�ļ�¼
select name,score from ���� where id in (select id from ���� where score>80);�Ӳ�ѯ����������insert����С��Ӳ�ѯ�Ľ��������ͨ��insert�����뵽�����ı���
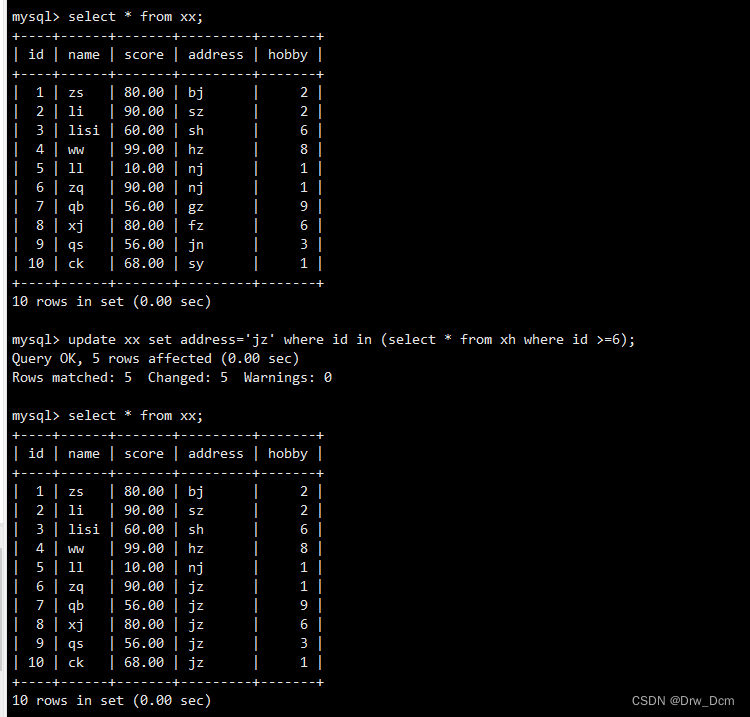
��t1��ļ�¼ȫ��ɾ��, ���²������ݱ��ļ�¼��insert into t1 select * from ���� where id in (select id from ����) ; select * from t1;update���Ҳ����ʹ���Ӳ�ѯ��update�ڵ��Ӳ�ѯ,��set��������ʱ,�����ǵ�����һ��, Ҳ�����Ƕ��С�
��������Ϊ50
update info set score=50 where id in (select * from ���� where id=2); select * from info; update info set score=100 where id not in (select * from ���� where id >1);��ʾ��ƥ������ݱ��ڵ�id�ֶ�Ϊ����ƥ��Ľ����(2,3)
Ȼ����ִ�������,��������idΪ��������where �����ж�/����delete Ҳ�������Ӳ�ѯ
ɾ����������80�ļ�¼
delete from ���� where id in (select id where score>80); select id, name, score from t1;��inǰ�滹��������not,��������in�෴,��ʾ��(�������Ӳ�ѯ�Ľ��������)
ɾ���������Ǵ��ڵ���80�ļ�¼delete from t1 where id not in (select id where score>=80); select id,name,score from t1;? ? ? ?exists ����ؼ������Ӳ�ѯʱ,��Ҫ�����ж��Ӳ�ѯ�Ľ�����Ƿ�Ϊ�ա������Ϊ��, ��true: ��֮,��false��
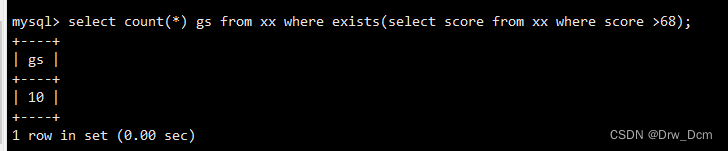
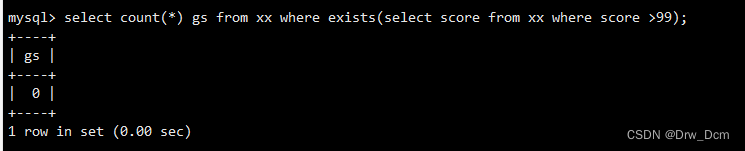
? ? ? ?��ѯ������ڷ�������80�ļ�¼�����info���ֶ���select count(*) from ���� where exists(select id from ���� where score=80);��Ա��Ϣͳ��,ֻ�е�������ȫ��ǩ��֮��,����Ա��Ϣͳ�Ʊ�¼����ɺ�,����Ҫ����ͳ��)
��ѯ������ڷ���С��50�ļ�¼�����info���ֶ���, info��û��С��50��,���Է���0select count(*) from ���� where exists (select id from ���� where score<50);�Ӳ�ѯ,����as
��ѯ���ݱ�id, name�ֶ�select id, name from ����;����������Բ鿴�����ݱ�������
���������Ϊһ�ű����в�ѯ��ʱ��,Ҳ��Ҫ�õ�����,ʾ��:
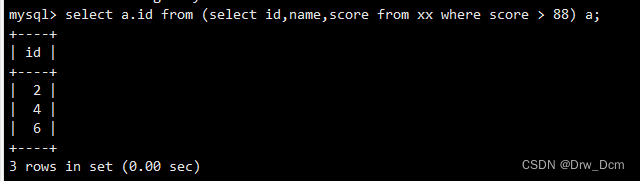
�����ݱ��е�id��name�ֶε�������Ϊ"����"���id�IJ���select id from (select id,name from ����);��ʱ�ᱨ��,ԭ��Ϊ: .
select * from ������Ϊ����ʽ,�����ϵIJ�ѯ���,"����"��λ����ʵ��һ�����������,mysql������ֱ��ʶ��,����ʱ������������һ������,��"select a.id from a���ķ�ʽ��ѯ���˽������Ϊһ ��"��", �Ϳ���������ѯ������,����:
select a.id from (select id,name from ����) a�൱��
select info.id, name from ����; select ��.�ֶ�,�ֶ� from ��:
 ?
?
 ?
?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
?����MySQL��ͼ
��ͼ:�Ż�����+��ȫ����
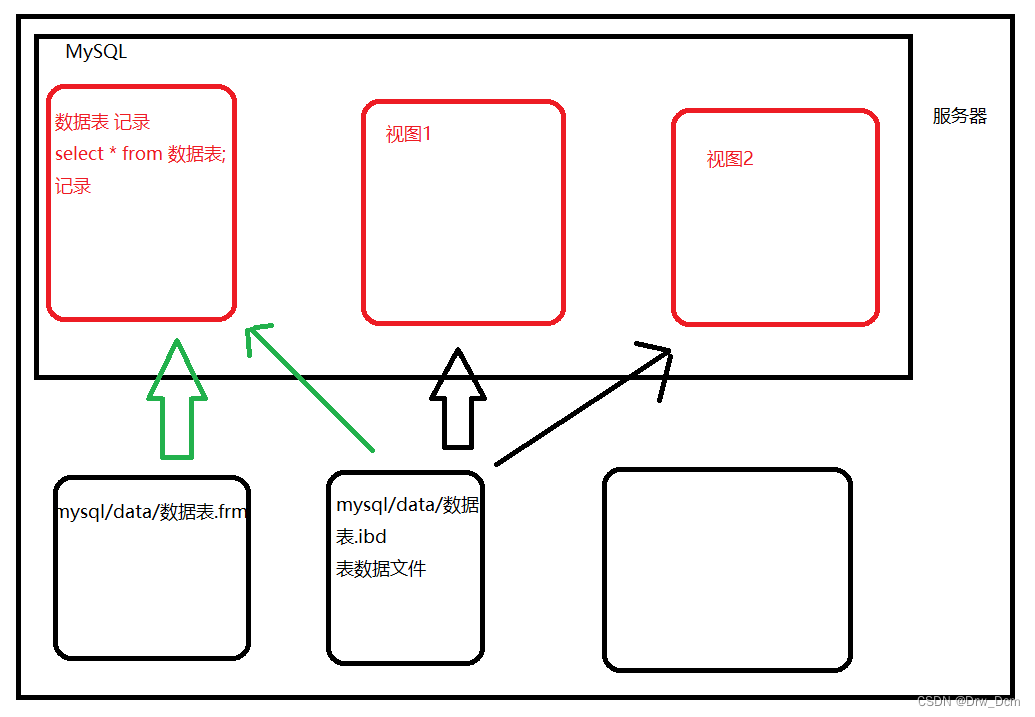
���ݿ��е������, ����������в�������ʵ����,ֻ��������ʵ���ݵ�ӳ�䡣
��ͼ��������Ϊ����ˮ��/��Ӱ,��̬��������( ����)���������ݱ�
(��¼)��ӳ��(ͶӰ) --��ͼ���ó���[ͼ]
��Բ�ͬ����(Ȩ������),�ṩ��ͬ������ġ�����(�Ա������ʽչʾ)�����÷�Χ:
select * from info;? ? չʾ�IJ�����info�� select * from view_name;? ?չʾ��һ�Ż���ű�����:
(1)��ѯ�����������ѯ��������Բ�ͬ�û����ֲ�ͬ�����������и��ߵİ�ȫ��
(2)���ʶ�����ͼ��һ��select(������ij���)��PS:��ͼ�ʺ��ڶ���������ʱʹ��!���ʺ�����ɾ����
���洢�����ʺ���ʹ�ý�Ƶ����SQL���,�����������ִ��Ч�ʡ���ͼ�ͱ����������ϵ
����:
(1)��ͼ���Ѿ�����õ�sql��䡣�������ǡ�
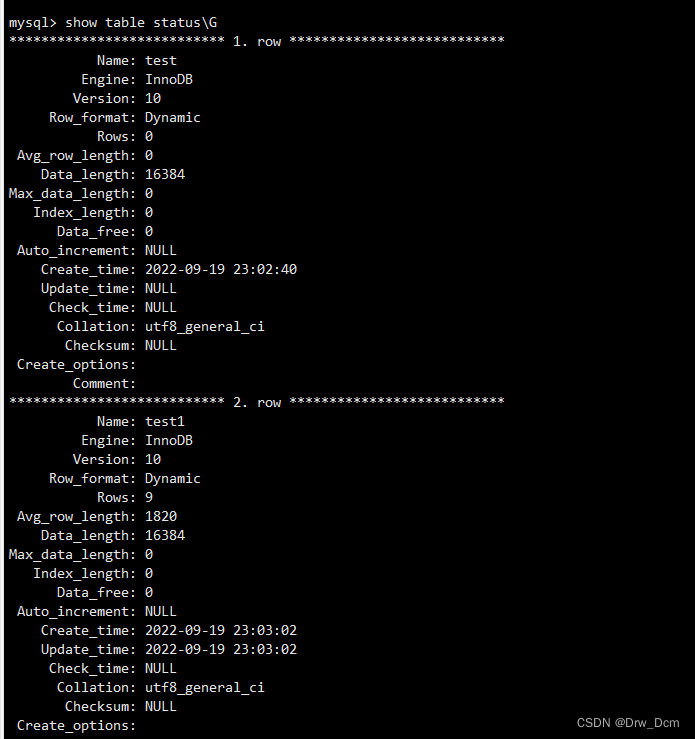
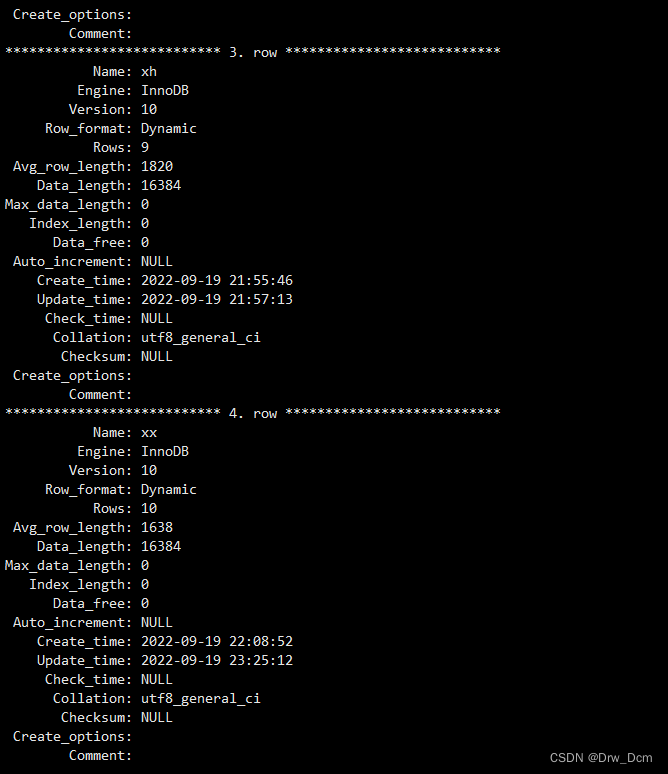
(2)��ͼû��ʵ�ʵ�������¼�������С�show table status\G(3)��ֻ�������ռ����ͼ��ռ�������ռ�,��ͼֻ��������Ĵ���,�����Լ�ʱ����������,����ͼֻ���д�����������ġ�
(4)��ͼ�Dz鿴���ݱ���һ�ַ���,���Բ�ѯ���ݱ���ijЩ�ֶι��ɵ�����,ֻ��һЩSQL���ļ��ϡ��Ӱ�ȫ�ĽǶ�˵,��ͼ���Բ����û��Ӵ����ݱ�,�Ӷ���֪�����ṹ��
(5)������ȫ��ģʽ�еı�,��ʵ��:��ͼ���ھֲ�ģʽ�ı�,�������
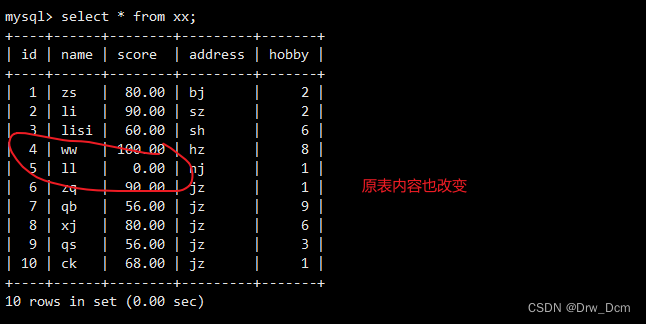
(6)��ͼ�Ľ�����ɾ��ֻӰ����ͼ����,��Ӱ���Ӧ�Ļ�������(���Ǹ�����ͼ����,�ǻ�Ӱ�쵽��������)����ϵ:
(1)��ͼ(view)���ڻ�����֮�Ͻ����ı�,���Ľṹ(�����������)������(������������)�����Ի�����,�����ݻ��������ڶ����ڡ�һ����ͼ���Զ�Ӧһ��������,Ҳ���Զ�Ӧ�������������ͼ�ǻ������ij�������������Ͻ������¹�ϵ��ʾ��:
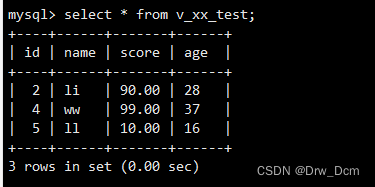
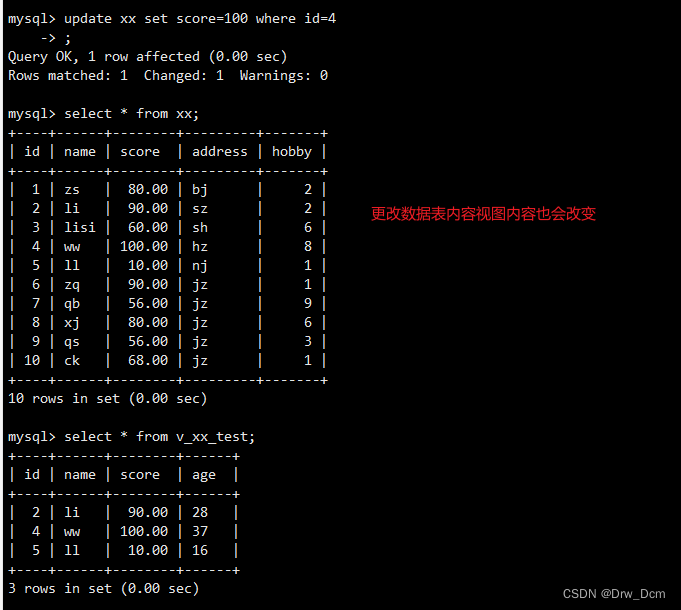
����80�ֵ�չʾ����ͼ�С�
PS:�������ᶯ̬�仯,ͬʱ���Ը���ͬ����Ⱥ(����Ȩ��Χ)չʾ��ͬ����ͼ��������ͼ(����)
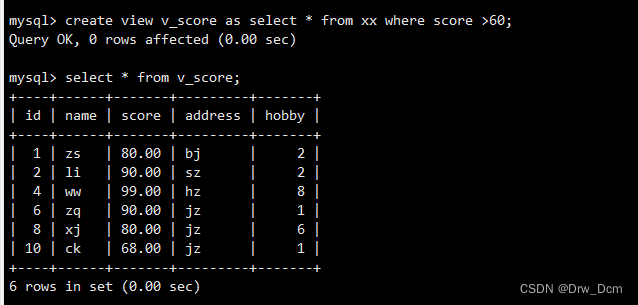
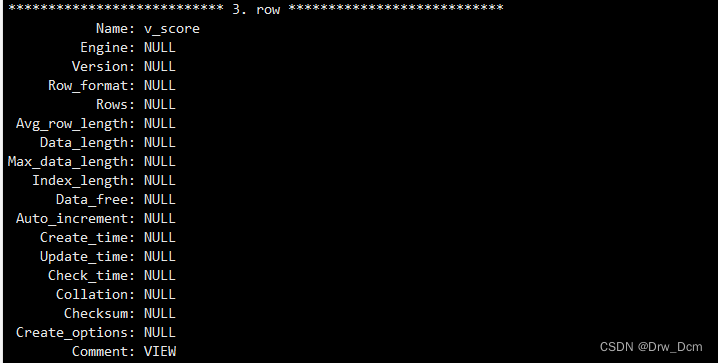
create view v_score as select * from ���� where score>=80;�鿴��״̬
show table status\G�鿴��ͼ
select * from v_score;�鿴��ͼ��Դ���ṹ
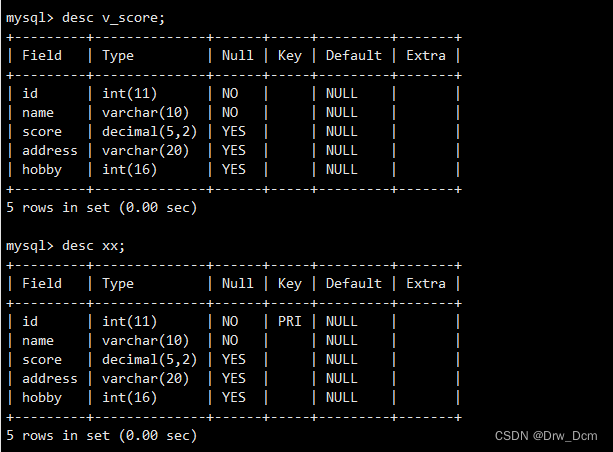
desc v_score; desc info;���������ͼ
����test01��
create table test01 (id int, name varchar(10) ,age char(10)) ; insert into test01 values(1, ' zhangsan',20) ; insert into test01 values(2, 'lisi',30) ; insert into test01 values (3, 'wangwu',29) ;����һ�� ��ͼ,��Ҫ���id�������������Լ�����
create view v_����(id, name, score,age) as select ����.id, ����.name, ����.score, test01.age from ����, test01 where ����.name-test01.name; select * from v_info;��ԭ������
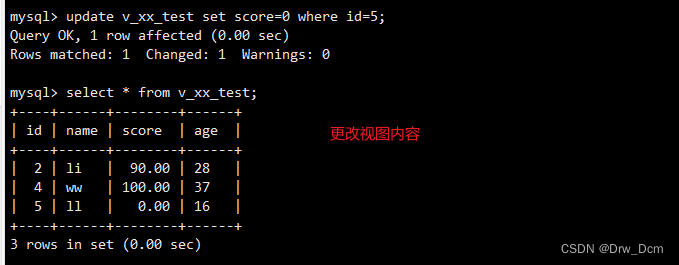
update ���� set score='60' where name='liuyi';�鿴��ͼ
select * from v_score; select * from ����;�ı��������Ժ��������Ϻ�����ʽ����������ֶ�
��ѯ���㡢��ȫ��
��ѯ����:�����ٶȿ졢ͬʱ���Զ����ѯ��ΪѸ��(��ͼ��������ʵ����,��ͼ��������select)��
��ȫ��:����ʵ�ֵ�½���˻���root����ӵ��Ȩ��,��ͼ����ʾ������Լ����NULLֵ
? ? ? ? ��SQL���ʹ�ù�����,����������NULL�⼸���ַ���ͨ��ʹ��NULL����ʾȱʧ��ֵ,Ҳ�����ڱ������ֶ���û��ֵ�ġ�����ڴ�����ʱ,����ijЩ�ֶβ�Ϊ��,�����ʹ��NOT? NULL��
�ؼ���? ? ? ? ��ʹ����Ĭ�Ͽ���Ϊ�ա�������ڲ����¼���߸��¼�¼ʱ,������ֶ�û��NOT NULL ����û��ֵ,��ʱ���¼�¼�ĸ��ֶν�������ΪNULL�� ��Ҫע�����,NULL ֵ������0���߿հ�(spaces) ���ֶ��Dz�ͬ��,ֵΪNULL���ֶ���û��ֵ�ġ���SQL�����,ʹ��IS NULL �����жϱ��ڵ�ij���ֶ��Dz���NULL ֵ,�෴���� IS NOT NULL �����жϲ��� NULLֵ��
��ѯ���ݱ��ṹ,name�ֶ��Dz�������ֵ�ġ�
nullֵ���ֵ������(���������)��
��ֵ����Ϊ0,��ռ�ռ�,NULLֵ�ij���Ϊnull,ռ�ÿռ䡣
is null���жϿ�ֵ��
��ֵʹ��"=������"<>"������(! =)��count ()����ʱ,NULL�����,��ֵ�������㡣
desc ����;
����һ����¼,�����ֶ�����null,��ʾ��������null��
�� ֤:alter table ���� add column addr varchar(50); update info set addr-'nj' where score >=70;ͳ������:���null�Ƿ�����ͳ���С�
update info set addr='nj' where score >=70;ͳ������:���null�Ƿ�����ͳ���С�
select count (addr) from info;��info��������һ��������Ϊ��ֵ''
update info set addr=''where name-'wangwu';ͳ������,����ֵ�Dz��ᱻ���ӵ�ͳ����
select count (addr) from info;��ѯnullֵ
select * from ���� where addr is NULL;��ѯ��Ϊ�յ�ֵ
?select * from ���� where addr is not null;
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
?
![]() ?
?
?
?
 ??
??
? ?
?
 ?
?
?
 ?
?
 ?
?
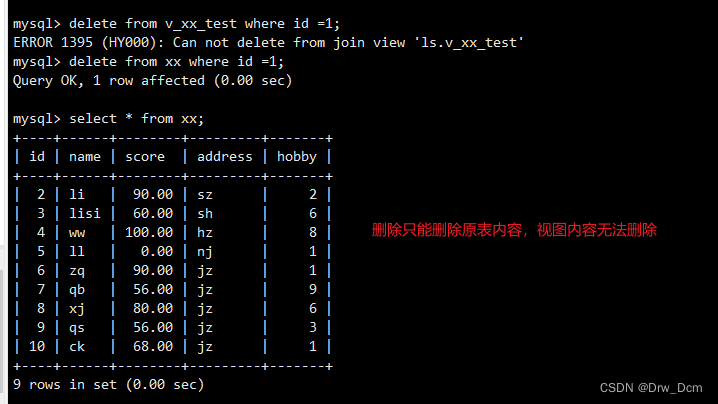
��ͼû������,�洢����,ֻ��һ��ӳ��?
?