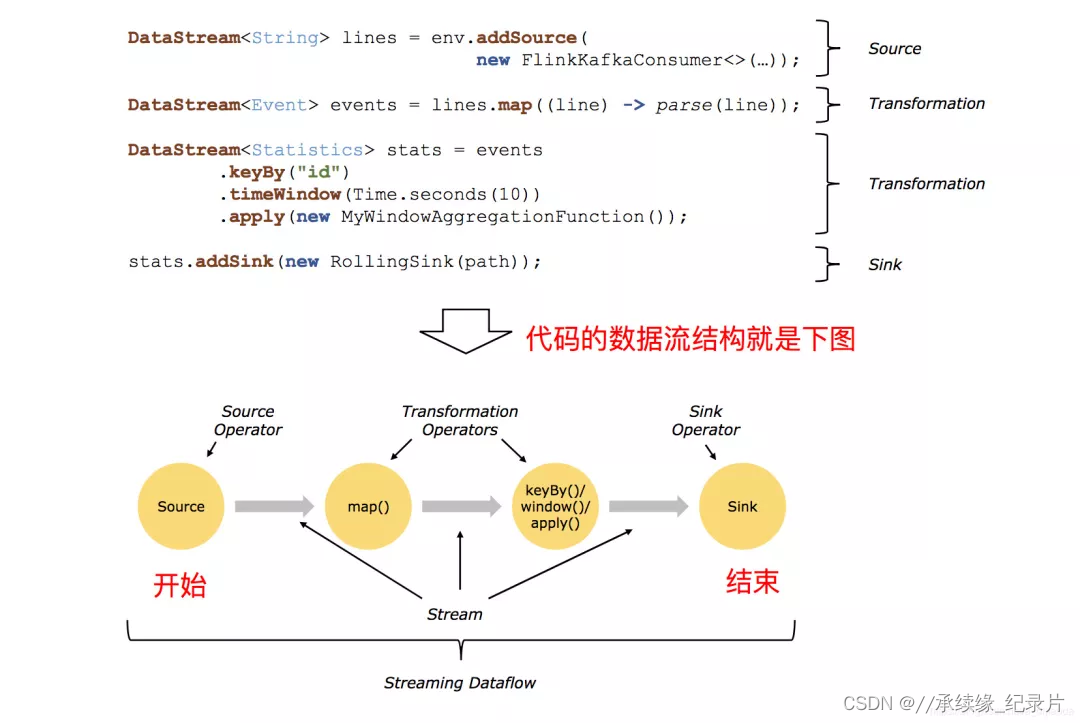
DataStream是Flink的较低级API,用于进行数据的实时处理任务,可以将该编程模型分为Source、Transformation、Sink三个部分,如下图所示。本文来介绍常用的并行度Source和多并行度Source。
1.Source简介
source是程序的数据源输入,你可以通过StreamExecutionEnvironment.addSource(sourceFunction)
来为你的程序添加一个source。
flink提供了大量的已经实现好的source方法,也可以自定义source:
- 通过实现sourceFunction接口来自定义无并行度的source
- 通过实现ParallelSourceFunction 接口or 继承RichParallelSourceFunction 来自定义有并行度的
source
大多数情况下,我们使用自带的source即可。
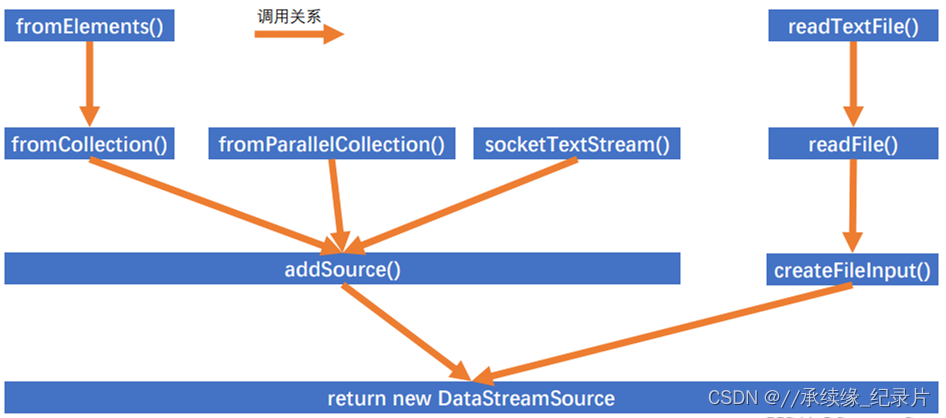
2. Flink预定义的Source
flink提供了大量的已经实现好的source,常见的有:Flink source
- 基于文件的Source
- 基于Socket的Source
- 基于集合的Source
- 基于Kafka的Source
3. 自定义单并行度Source
除了flink本身提供的source之外,我们也可以自定义source。可以通过实现sourceFunction接口来自定义无并行度的source。
示例如下:
(1)自定义Source
import org.apache.flink.streaming.api.functions.source.SourceFunction;
//功能:每秒产生一条数据
public class MyNoParallelSource implements SourceFunction<Long> {
private long number = 1L;
private boolean isRunning = true;
@Override
public void run(SourceContext<Long> sct) throws Exception {
while (isRunning){
sct.collect(number);
number++;
//每秒生成一条数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning=false;
}
}
(2)定义Consume,消费Source的数据,并打印输出
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
//功能:打印输出偶数
public class MyNoParallelConsumer {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment();
//默认并行度为1
DataStreamSource<Long> numberStream = env.addSource(new MyNoParallelSource());
DataStream<Long> dataStream = numberStream.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("接受到了数据:"+value);
return value;
}
});
DataStream<Long> filterDataStream = dataStream.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value % 2 == 0; //过滤偶数
}
});
filterDataStream.print().setParallelism(1);
env.execute();
}
}
4. 自定义多并行度Source
通过实现ParallelSourceFunction 接口or 继承RichParallelSourceFunction 来自定义有并行度的
source。
(1)自定义多并行度Source
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
//功能:自定义支持并行度的数据源
public class MyParallelSource implements ParallelSourceFunction<Long> {
private long number = 1L;
private boolean isRunning = true;
@Override
public void run(SourceContext<Long> sct) throws Exception {
while (isRunning){
sct.collect(number);
number++;
//每秒生成一条数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning=false;
}
}
(2)定义Consume,消费多并行度Source的数据,并打印输出
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
//功能:消费多并行度Source的数据,并打印输出偶数
public class MyParallelConsumer {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment();
//默认并行度为cpu core数,我这里为4
DataStreamSource<Long> numberStream = env.addSource(new MyParallelSource());
DataStream<Long> dataStream = numberStream.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("接受到了数据:"+value);
return value;
}
});
DataStream<Long> filterDataStream = dataStream.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value % 2 == 0;
}
});
filterDataStream.print().setParallelism(1);
env.execute();
}
}
可以看到,如果不设置并行度,Source默认并行度为cpu core数,我这里是4。