SQL学习分享
数据库基础
建表的原则(三大范式)
- 1NF:保证原子性。比如地址:杭州市江干区xxx这样的地址就不是原子性的,是可以切割的。
- 2NF:保证各列完全依赖主键。比如
- (学生,课程) -> 高考成绩。成绩完全依赖于学生和课程
- (学生,课程,学校)-> 高考成绩。这就不是完全依赖
- 3NF:消除传递依赖:可以根据非主键的列,找到与其他列的对应关系。
drop、delete、truncate
drop:删除一张表,删除数据并且删除表的数据结构
delete:删除的是行数据
truncate:是先把表删除,再创建一张完全一样的表。
DDL、DML
DDL就是建表,对表的数据结构做出改变的操作
DML增删改查
关系型数据库和非关系型数据库
关系型数据库:表都是由结构的。
非关系型数据库:以元组为单位,一个元组中有的数据不固定
Mysql相关
一条SQL的执行顺序
- from
- where
- group by xxx having
- 聚合函数
- select
- order by
Mysql事务
- Mysql中事务的等级
- 读未提交
- 读已提交
- 不可重复读
- 串行化
- Mysql事务的性质:
- 原子性
- 一致性
- 持久性
- 隔离性
- Mysql实现事务的机制:MVCC,本质上是通过一个readView这样的数据结构来完成这件事的。
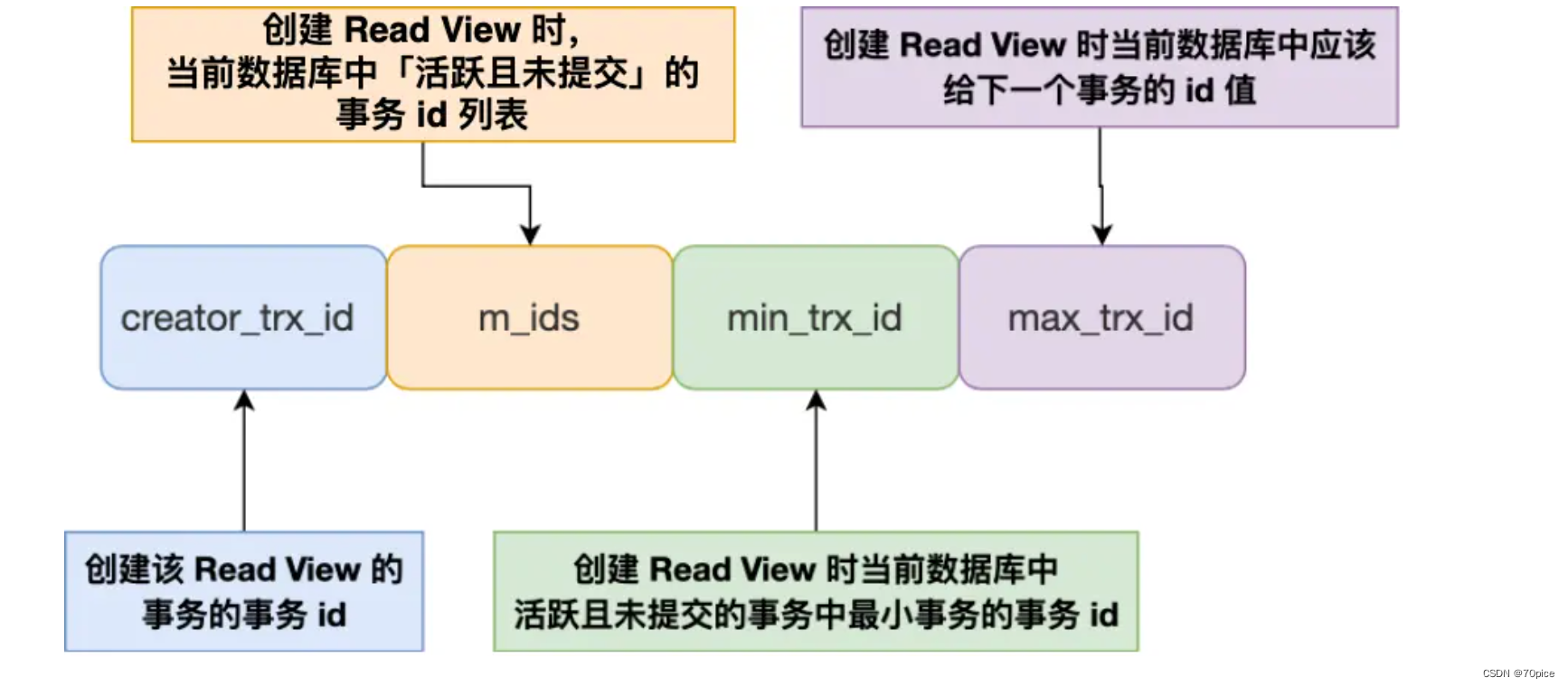
readView:- creator_trx_id:创建该readView的事务id
- m_ids:创建该ReadView时当前数据库中活跃,且未提交的事务id
- min_ids:创建该ReadView时数据库最小活跃事务的id
- max_ids:下一个创建readView的事务id
读未提交
readView没有限制。读取数据库中当前的数据,不管有没有提交。这样造成的问题是脏读
事务A:看到事务B修改后的数据,然而这个事务B回滚了,事务A看到的数据就是脏数据,基于这个脏数据做数据加工就会出现问题。
读已提交
readView限制,当前readView创建时,活跃的未提交的事务id所修改的内容是不能被查看到的。
不可重复读:事务A在执行过程中,事务B提交了,那事务A两次查询的数据可能不一致,这就导致了不可重复度的问题。
可重复读
readView限制,当前readView创建时,只有小于最小活跃事务id的事务修改的内容才可以被读取到。这就造成了幻读的问题。
幻读:当事务A执行的过程中,事务B增加了一些数据,可能会造成事务A幻读
串行化
事务A执行完事务B才能执行,并发量太低了,在Mysql中是通过行锁和间隙锁来处理幻读问题的。
Mysql中的锁
- 全局锁:这个锁是把当前数据库锁起来了。一般是数据库备份的时候采用。
- 表锁:锁一张表
- 意向锁是,防止锁一张表的时候,还有行锁的存在,一行一行的比较比较麻烦。加入意向锁提高性能。
- 行级别锁:
- 记录锁:锁一行数据
- 排他锁:如果获得了排他锁,就禁止其他的共享锁和排它锁进入。
- 共享锁:如果有一个事务获得了这个数据集的共享锁,那么其他事务还是可以获得这个数据集的共享锁。但是不能拿到排他锁。
- 间隙锁:锁行与行之间不存在的间隙数据
意向锁和共享锁和排它锁的关系。
首先在DML语句,增删改查的时候,会自动对数据加锁。
共享锁(读锁)在加共享锁的之前,要先获得这张表的意向共享锁。
同理,排它锁(写锁)在加排他锁之前,要先拿到意向排它锁。
这样意向标所,表明这张表里此时有行正处于共享锁和排它锁的状态中,不需要再一行一行比较了
- 记录锁:锁一行数据
mysql中的索引
按照数据结构划分
众所周知,mysql底层用的是B+树做索引的。
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的
为什么在Mysql中,用B+树做索引呢?
首先,我们希望数据是有序的,这样就可以用二分查找法,时间效率为logn

- 但是,如果采用线性结构去存储数据,为了保持数据的有序性,必须在插入数据的时候,将整体的数据向后移动,而数据又是存储在磁盘上的,这回带来可怕的消耗。
所以我们引入二叉查找树来解决这个问题,但是二叉查找树,首先一层的节点只有两个,其次,他会退化成O(n)的时间复杂度。 - 为此,我们引入自平衡树来解决这个问题,比如限制两边子树的高度不能超过1,又比如类似红黑树的数据结构。可是这还是不够,因为一层到底只有两个节点,树的深度依旧会很大
- 为此,我们引入B树,所谓的B树,就是不再限制一个节点只有一个子节点了,这样树的深度会小很多。但是带来一个问题,B树是,索引和数据一起存的,用户写入的数据很有可能是会大于索引的,有时候为了访问索引,我们不得不读入多余的数据,这是我们不想看到的。
- 为此我们引入了B+树,B+树就是只有叶子节点会存放数据。
接下来详细比较一下B树和B+树做索引的区别。
5. B树其实是有可能比B+树快的,因为B树可能O(1)就能完成对于数据的访问。但是总体而言,B+树的时间更少。因为B+树的非叶子节点只用于存储索引,所以B+树的索引能更多,因而B+树可以比B树更加矮胖,查询底层节点I/O次数可以更少。
6. 插入删除,由于B+树有荣誉节点,所以删除节点的瘦比较快
7. 范围查询,因为B+树子节点有链表,因此可以通过链表来进行范围查询
比较B+与二叉树
主要优势在于深度可以很小
B+树比较Hash
Hash有Hash冲突等等问题,而且用Hash不能做范围查询
聚簇索引和非聚簇索引
聚簇索引的叶子节点是数据
非聚簇索引的叶子节点是聚簇索引,通过回表查询来处理
SQL优化
- Mysql实现分布式锁
- 创建一张表,如果用到了某一个资源,就插入一条数据,等到资源被释放了,就把这条记录删除,
- 解锁的过程只要吧对应的进程Id给kill掉就行。
- 数据库查询优化
- 加索引
- 分页
- 分表:
- 水平分表(按照主键递增的规律或者Hash%来粉白)
- 垂直分表(把用的多的数据和用的不多的数据(或者较大的数据)分开)
- Mysql分页:
- 还要分页再优化,那就是懒加载模式了
- 索引的选择性:
区分度越大的做索引越合适,所以性别没必要做索引