shardingjdbc�ں˽����ͺ���Դ�����
�ں˽���
ShardingSphere��3����Ʒ���������ǵ����ݷ�Ƭ��Ҫ��������ȫһ�µġ� ���̺��������¼�������ɡ�
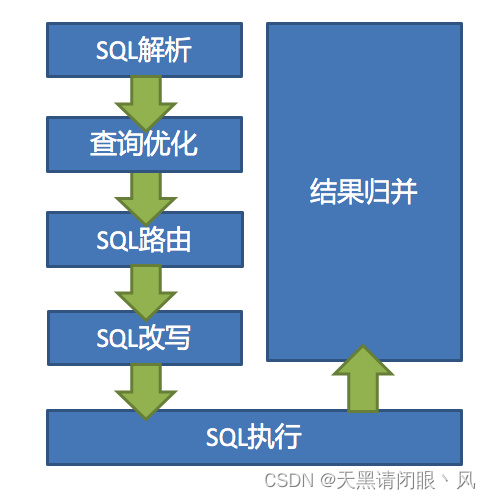
SQL�����Ͳ�ѯ�Ż����Ǹ���������ݿ��Ʒ�й�,��5.x�°汾��,��ͳһ����SQL�����
��������
����������������,SQL�DZȽϼġ� ����,����Ȼ��һ�����Ƶı������,��˶�SQL������н���,����������������(��:Java���ԡ�C���ԡ�Go���Ե�)���ޱ�������
�������̷�Ϊ�ʷ�������������� �ʷ����������ڽ�SQL���Ϊ�����ٷֵ�ԭ�ӷ���,��ΪToken�������ݲ�ͬ���ݿⷽ�����ṩ���ֵ�,�������Ϊ�ؼ���,����ʽ,�������Ͳ������� ��ʹ�����������SQLת��Ϊ���������
����,����SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
����֮���Ϊ�����������ͼ��

Ϊ�˱�������,��������еĹؼ��ֵ�Token����ɫ��ʾ,������Token�ú�ɫ��ʾ,��ɫ��ʾ��Ҫ��һ����֡�
���,ͨ���Գ�������ı���ȥ������Ƭ�����������,������п�����Ҫ��д��λ�á� ����Ƭʹ�õĽ��������İ�����ѯѡ����(Select Items)������Ϣ(Table)����Ƭ����(Sharding Condition)������������Ϣ(Auto increment Primary Key)��������Ϣ(Order By)��������Ϣ(Group By)�Լ���ҳ��Ϣ(Limit��Rownum��Top)�� SQL��һ�ν��������Dz������,һ����Token�İ�SQLԭ����˳�����ν��н���,���ܸܺߡ� ���ǵ��������ݿ�SQL���Ե���ͬ,�ڽ���ģ���ṩ�˸������ݿ��SQL�����ֵ䡣
��3.0.x�汾��ʼ,ShardingSphere����ʹ��ANTLR��ΪSQL����������,���ƻ�����DDL -> TCL -> DAL �C> DCL -> DML �C>DQL���˳��,�����滻ԭ�еĽ�������,Ŀǰ�Դ����滻�����С� ʹ��ANTLR��ԭ����ϣ��ShardingSphere�Ľ��������ܹ����õĶ�SQL���м��ݡ����ڸ��ӵı���ʽ���ݹ顢�Ӳ�ѯ�����,��ȻShardingSphere�ķ�Ƭ���IJ�����ע,���ǻ�Ӱ�����SQL������Ѻöȡ� ����ʵ������,ANTLR����SQL�����ܱ����е�SQL����������3-10�����ҡ�Ϊ���ֲ���һ���,ShardingSphere��ʹ��PreparedStatement��SQL������������뻺�档 ��˽������PreparedStatement����SQLԤ����ķ�ʽ�������ܡ�
������SQL�������������ṹ��������ͼ��ʾ
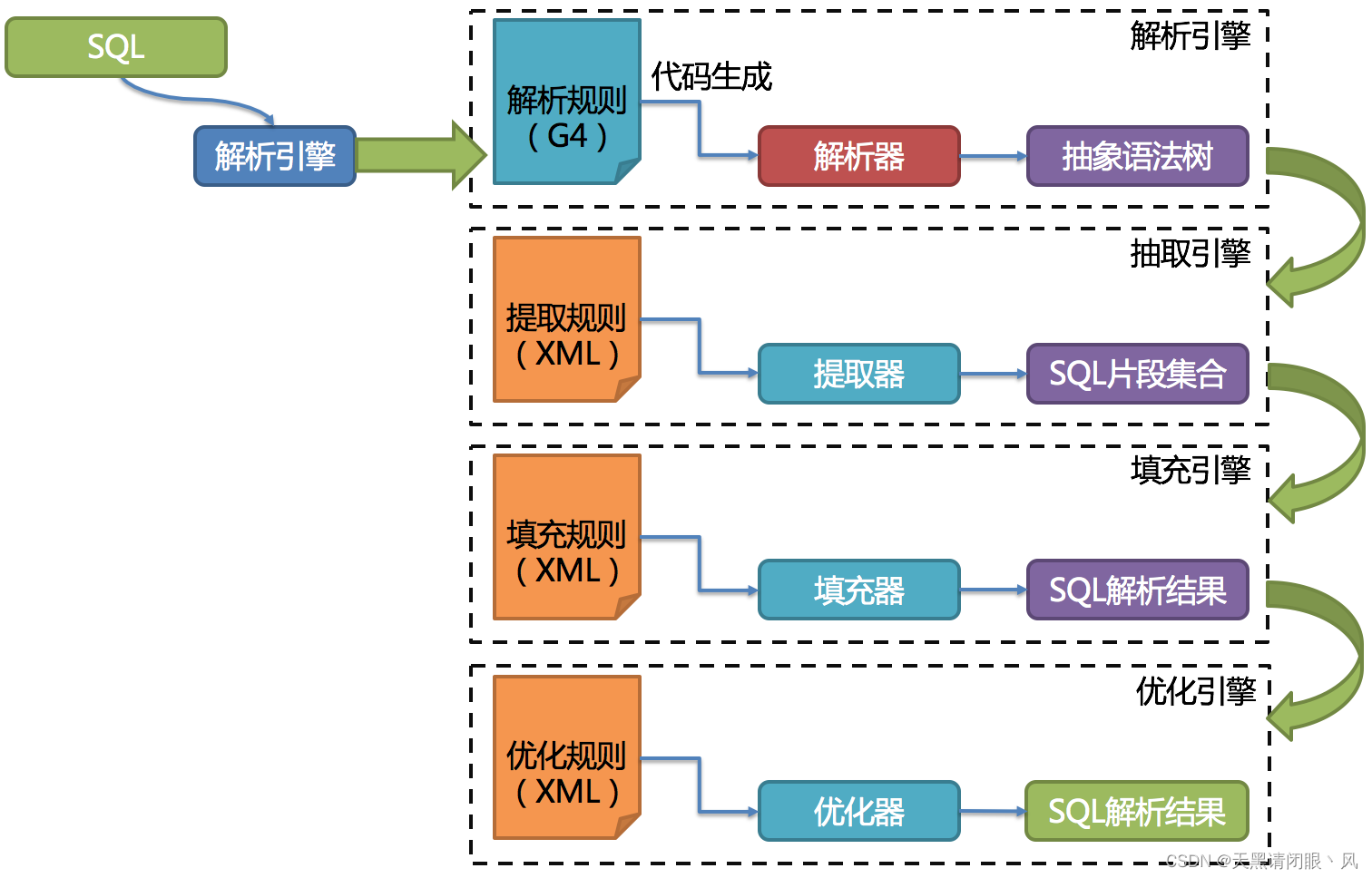
·������
���ݽ���������ƥ�����ݿ�ͱ��ķ�Ƭ����,������·��·�������ݽ���������ƥ�����ݿ�ͱ��ķ�Ƭ����,������·��·���� ����Я����Ƭ����SQL,���ݷ�Ƭ���IJ�ͬ���Ի���Ϊ��Ƭ·��(��Ƭ���IJ������ǵȺ�)����Ƭ·��(��Ƭ���IJ�������IN)�ͷ�Χ·��(��Ƭ���IJ�������BETWEEN)�� ��Я����Ƭ����SQL����ù㲥·�ɡ�
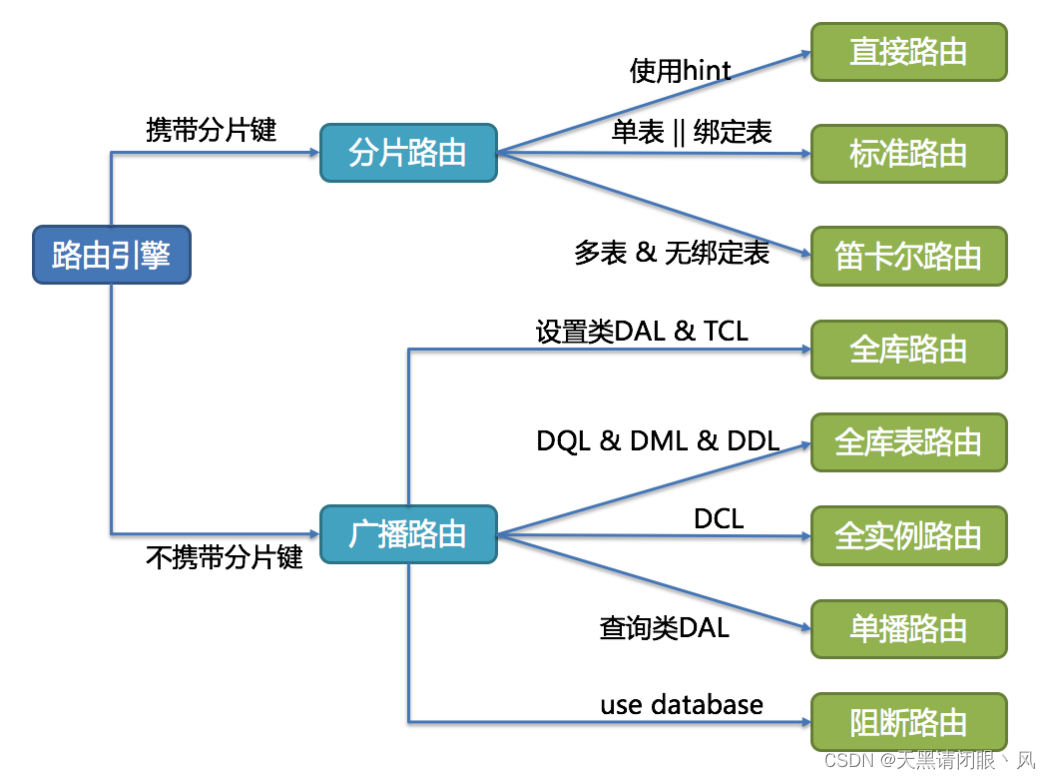
�����
����ʦ����������������д��SQL,�����ܹ�ֱ������ʵ�����ݿ���ִ��,SQL��д���ڽ���SQL��дΪ����ʵ���ݿ��п�����ȷִ�е�SQL�� ��������ȷ�Ը�д���Ż���д�����֡�
��ȷ�Ը�д
��sql:SELECT order_id FROM t_order WHERE order_id=1; ��дΪ:SELECT order_id FROM t_order_1 WHERE order_id=1
���ڸ��ӵ�sql:SELECT t_order.order_id FROM t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
��дΪ:SELECT t_order_1.order_id FROM t_order_1 WHERE t_order_1.order_id=1 AND remarks=' t_order xxx';
�Ż���д
�Ż���д��Ŀ�����ڲ�Ӱ���ѯ��ȷ�Ե������,�����ܽ�����������Ч�ֶΡ�����Ϊ���ڵ��Ż�����ʽ�鲢�Ż���
���ڵ��Ż�
·�������ڵ��SQL,�������Ż���д�� �����һ�β�ѯ��·�ɽ����,�����·����Ψһ�����ݽڵ�,�������漰������鲢����˲��кͷ�ҳ��Ϣ�ȸ�д��û�б�Ҫ���С� �����Ƿ�ҳ��Ϣ�ĸ�д,���轫���ݴӵ�1����ʼȡ,�����Ľ����˶����ݿ��ѹ��,���ҽ�ʡ�������������ν���ġ�
��ʽ�鲢�Ż�
����Ϊ����GROUP BY��SQL����ORDER BY�Լ��ͷ�������ͬ�������������˳��,���ڽ��ڴ�鲢ת��Ϊ��ʽ�鲢�� �ڽ���鲢�IJ�����,������ʽ�鲢���ڴ�鲢������ϸ˵����
��д���������ṹ��������ͼ��ʾ
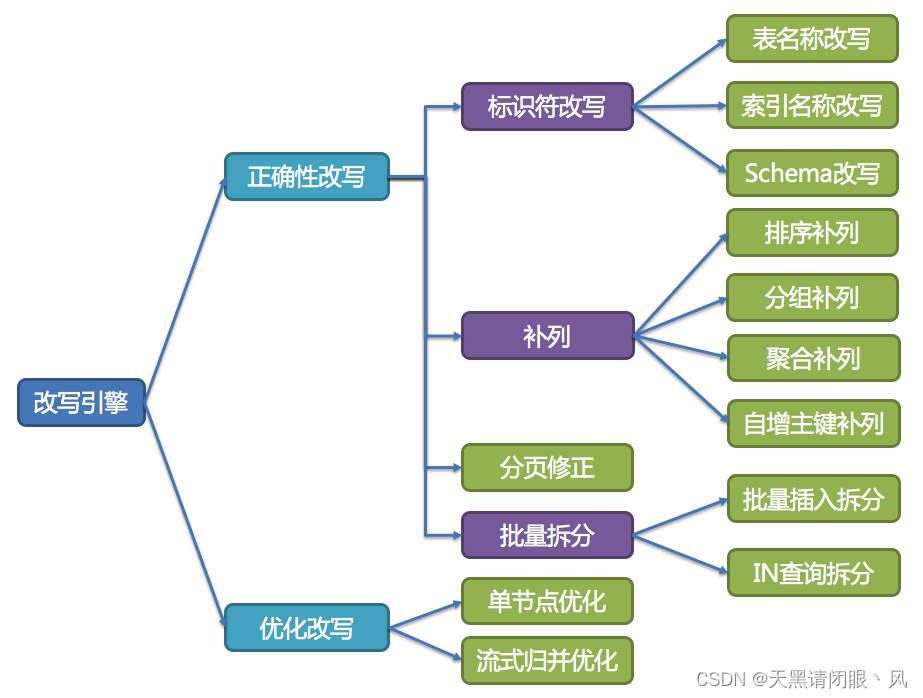
ִ������
ShardingSphere����һ���Զ�����ִ������,����·�ɺ�д���֮�����ʵSQL��ȫ�Ҹ�Ч���͵��ײ�����Դִ�С� �����Ǽؽ�SQLͨ��JDBCֱ�ӷ���������Դִ��;Ҳ����ֱ�ӽ�ִ����������̳߳�ȥ����ִ�С�������עƽ������Դ���Ӵ����Լ��ڴ�ռ��������������,�Լ�����ȵغ������ò��������⡣ ִ�������Ŀ�����Զ�����ƽ����Դ������ִ��Ч�ʡ�
������������ģʽ��Ϊ�ڴ�����ģʽ(MEMORY_STRICTLY)����������ģʽ(CONNECTION_STRICTLY)���ڴ�����ģʽֻ��עһ�����ݿ����ӵĴ�������,ͨ��һ����ʵ��һ�����ݿ����ӡ�����������ģʽ��ֻ��ע���ݿ����ӵ�����,�ϴ�IJ�ѯ����д��в�����
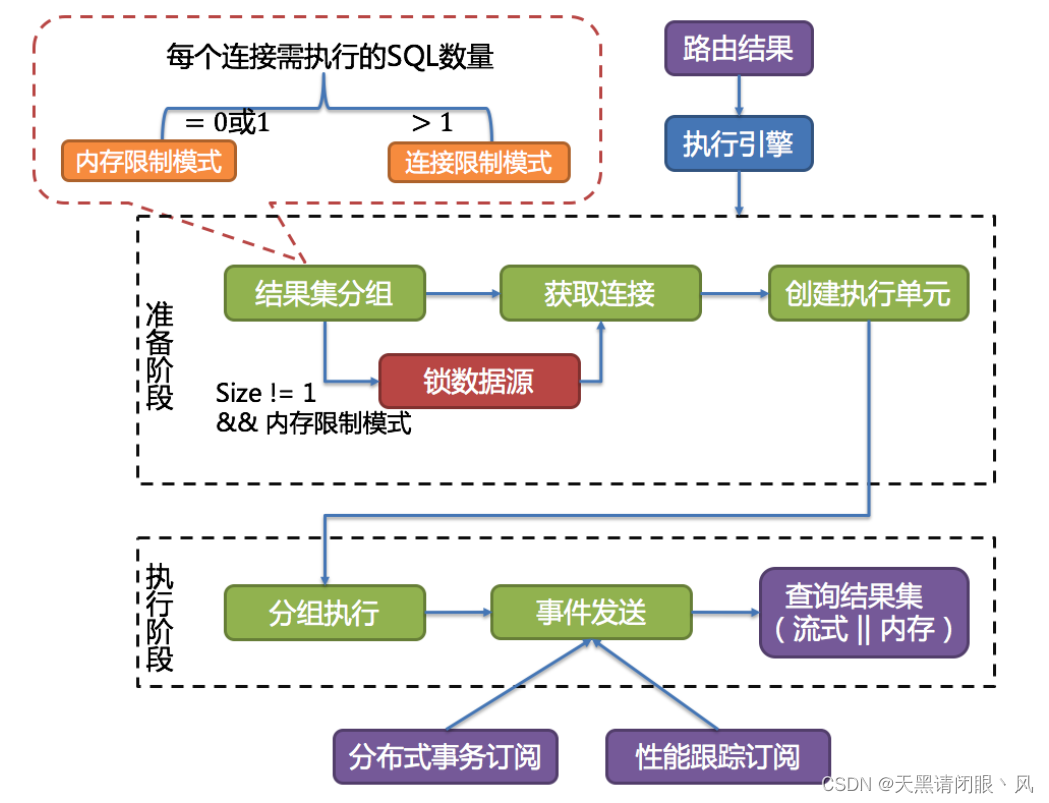
������ģʽ�������漰��һ������ spring.shardingsphere.props.max.connections.size.per.query=50
(Ĭ��ֵ1,���òμ�Դ����ConfigurationPropertyKey��)��ShardingSphere����� ·�ɵ�ijһ������Դ��·�ɽ�������������
�����ݿ���ִ�е�SQL����,������������� �û���������,�õ�ÿ�����ݿ�������ִ�е�SQL����������>1�ͻ�ѡ����������ģʽ,����<=1�ͻ�ѡ���ڴ�����ģʽ��
�ڴ�����ģʽ������������,Ҳ����˵�Ὠ�������������,Ȼ������ÿ������ֻȥ��ȡһ�����ݷ�Ƭ�����ݡ�������������ٶȵİ�������Ҫ�����ݶ������������ں���Ĺ鲢��,��ѡ����ÿһ������Ϊ��λ���й鲢,���Ǻ����ᵽ����ʽ�鲢�����ֹ鲢��ʽ�鲢��һ�����ݺ�,�����ͷ��ڴ���,���Ժܺõ�������ݹ鲢��Ч��,���ҷ�ֹ�����ڴ��������������Ƶ��������������������Ƚϴ�,�Ƚ��ʺ�OLAP������
��������ģʽ�����������������,Ҳ����˵������һ�����ݿ����ӻ�Ҫȥ��ȡ������ݷ�Ƭ�����ݡ����������������ݿ����Ӳ��ô��еķ�ʽ���ζ�ȡ������ݷ�Ƭ�����ݡ������ַ�ʽ��,�Ὣ����ȫ�����뵽�ڴ�,����ͳһ�����ݹ鲢,Ҳ���Ǻ����ᵽ���ڴ�鲢�����ַ�ʽ�鲢Ч�ʻ�Ƚϸ�,����һ��MAX�鲢,ֱ�Ӿ����õ����ֵ,����ʽ�鲢����Ҫһ�����ıȽϡ��Ƚ��ʺ�OLTP������
�鲢����
���Ӹ������ݽڵ��ȡ�Ķ����ݽ����,��ϳ�Ϊһ�����������ȷ�ķ���������ͻ���,��Ϊ����鲢��
ShardingSphere֧�ֵĽ���鲢�ӹ����Ϸ�Ϊ�����������顢��ҳ�;ۺ�5������,��������϶��ǻ���Ĺ�ϵ�� �ӽṹ����,�ɷ�Ϊ��ʽ�鲢���ڴ�鲢��װ���߹鲢����ʽ�鲢���ڴ�鲢�ǻ����,װ���߹鲢��������ʽ�鲢���ڴ�鲢֮������һ���Ĵ�����
���ڴ����ݿ��з��صĽ�������������ص�,������Ҫ�����е�����һ���Լ������ڴ���,���,�ڽ��н���鲢ʱ,�������ݿⷵ�ؽ�����ķ�ʽ���й鲢,�ܹ���������ڴ������,�ǹ鲢��ʽ������ѡ��
��ʽ�鲢��ָÿһ�δӽ�����л�ȡ��������,���ܹ�ͨ��������ȡ�ķ�ʽ������ȷ�ĵ�������,�������ݿ�ԭ���ķ��ؽ�����ķ�ʽ��Ϊ���ϡ������������Լ���ʽ���鶼������ʽ�鲢��һ�֡�
�ڴ�鲢������Ҫ����������������ݶ��������洢���ڴ���,��ͨ��ͳһ�ķ��顢�����Լ��ۺϵȼ���֮��,�ٽ����װ��Ϊ�������ʵ����ݽ�������ء�
װ���߹鲢�Ƕ����еĽ�����鲢����ͳһ�Ĺ�����ǿ,Ŀǰװ���߹鲢�з�ҳ�鲢�;ۺϹ鲢��2�����͡�
�鲢���������ṹ��������ͼ

����Դ�����
shardingjdbc��Դ���кܶ�ģ��,��ôȥ��Դ����,����Ҫ�ҵ�һ�����,������ʹ�ù�����һ������
// ������ʵ����Դ
Map<String, DataSource> dataSourceMap = new HashMap<>();
// ���õ�һ������Դ
BasicDataSource dataSource1 = new BasicDataSource();
dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
dataSource1.setUrl("jdbc:mysql://localhost:3306/ds0");
dataSource1.setUsername("root");
dataSource1.setPassword("");
dataSourceMap.put("ds0", dataSource1);
// ���õڶ�������Դ
BasicDataSource dataSource2 = new BasicDataSource();
dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
dataSource2.setUrl("jdbc:mysql://localhost:3306/ds1");
dataSource2.setUsername("root");
dataSource2.setPassword("");
dataSourceMap.put("ds1", dataSource2);
// ����Order������
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_order","ds${0..1}.t_order${0..1}");
// ���÷ֿ� + �ֱ�����
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order${order_id % 2}"));
// ���÷�Ƭ����
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
// ʡ������order_item������...
// ...
// ��ȡ����Դ����
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());
//ͨ�������ۻ�ȡ���� �������ݿ�
Connection conn = null;
try {
//ShardingConnectioin
conn = dataSource.getConnection();
//ShardingStatement
Statement statement = conn.createStatement();
String sql = "SELECT cid,cname,user_id,cstatus from course";
//ShardingResultSet ִ��sql
ResultSet result = statement.executeQuery(sql);
while (result.next()) {
System.out.println("result:" + result.getInt("cid"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (null != conn) {
conn.close();
}
}
��ô��ڵ�������,һ������shardingjdbc������Դ DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());;
һ����ͨ������Դ���ȡ���ݿ�����ִ��sql ResultSet result = statement.executeQuery(sql);
����shardingjdbc����Ҫ����
����һ:��������Դ
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());
//dataSourceMap ��������Դ����Ϣ����(��ַ,���� �û���,���ӵ�),
//shardingRuleConfig �ֿ�ֱ���������Ϣ��
//props:������������
public static DataSource createDataSource(
final Map<String, DataSource> dataSourceMap, final ShardingRuleConfiguration shardingRuleConfig, final Properties props) throws SQLException {
//����ShardingRule�Լ�ShardingDataSourceʵ��
return new ShardingDataSource(dataSourceMap, new ShardingRule(shardingRuleConfig, dataSourceMap.keySet()), props);
}
���д�������ʲô����,��Ҫ����������:1 ���ݷֿ�ֱ�����·�ɹ��� 2 ��ʼ������ʱ������ 3 ��ȡ����Դ�б�
�ص��ǵ�һ�� ���ݷֿ�ֱ�����·�ɹ��� ��Ӧ�Ĵ������new ShardingRule(shardingRuleConfig, dataSourceMap.keySet())
public ShardingRule(final ShardingRuleConfiguration shardingRuleConfig, final Collection<String> dataSourceNames) {
Preconditions.checkArgument(null != shardingRuleConfig, "ShardingRuleConfig cannot be null.");
Preconditions.checkArgument(null != dataSourceNames && !dataSourceNames.isEmpty(), "Data sources cannot be empty.");
this.ruleConfiguration = shardingRuleConfig;
//��ȡ���е�ʵ�����ݿ�
shardingDataSourceNames = new ShardingDataSourceNames(shardingRuleConfig, dataSourceNames);
//��·�ɹ���
tableRules = createTableRules(shardingRuleConfig);
//��ȡ�㲥��
broadcastTables = shardingRuleConfig.getBroadcastTables();
//��
bindingTableRules = createBindingTableRules(shardingRuleConfig.getBindingTableGroups());
//����Ĭ�ϵķֿ����
defaultDatabaseShardingStrategy = createDefaultShardingStrategy(shardingRuleConfig.getDefaultDatabaseShardingStrategyConfig());
//����Ĭ�ϵķֱ�����
defaultTableShardingStrategy = createDefaultShardingStrategy(shardingRuleConfig.getDefaultTableShardingStrategyConfig());
//��Ƭ��
defaultShardingKeyGenerator = createDefaultKeyGenerator(shardingRuleConfig.getDefaultKeyGeneratorConfig());
//���ӹ���
masterSlaveRules = createMasterSlaveRules(shardingRuleConfig.getMasterSlaveRuleConfigs());
//���ܹ���
encryptRule = createEncryptRule(shardingRuleConfig.getEncryptRuleConfig());
}
�ص��DZ�·�ɹ��� tableRules = createTableRules(shardingRuleConfig); �������漰�����ĸ��ֲ������ú��������ɲ��Ե�ѡ�� Ҳ����֮ǰ˵SPI���ơ�
���̶�:�������ݿ�����
����������Դ��,��������Դ�������ݿ������ conn = dataSource.getConnection();
//runtimeContext ��������Դʱ��ʼ���������Ķ���
// TransactionTypeHolder.get()Ĭ���� ��������
@Override
public final ShardingConnection getConnection() {
return new ShardingConnection(getDataSourceMap(), runtimeContext, TransactionTypeHolder.get());
}
private static final ThreadLocal<TransactionType> CONTEXT = ThreadLocal.withInitial(() -> TransactionType.LOCAL);
public static TransactionType get() {
return CONTEXT.get();
}
�ڴ�������Դ��ʱ���Ѿ��������õ������������,���ض�Ӧ���������,�������ӵ�ʱ��Ĭ�ϵ��������;��DZ�������
������:�����ݿ����ӻ�ȡStatement����
Statement statement = conn.createStatement();
@Override
public Statement createStatement() {
return new ShardingStatement(this);
}
public ShardingStatement(final ShardingConnection connection, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) {
super(Statement.class);
this.connection = connection;
statementExecutor = new StatementExecutor(resultSetType, resultSetConcurrency, resultSetHoldability, connection);
}
���� statementExecutor = new StatementExecutor(resultSetType, resultSetConcurrency, resultSetHoldability, connection); ����һ��sql��ִ����,ͬʱ�÷���������ø���Ĺ��췽��
public AbstractStatementExecutor(final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability, final ShardingConnection shardingConnection) {
this.databaseType = shardingConnection.getRuntimeContext().getDatabaseType();
this.resultSetType = resultSetType;
this.resultSetConcurrency = resultSetConcurrency;
this.resultSetHoldability = resultSetHoldability;
this.connection = shardingConnection;
int maxConnectionsSizePerQuery = connection.getRuntimeContext().getProperties().<Integer>getValue(ConfigurationPropertyKey.MAX_CONNECTIONS_SIZE_PER_QUERY);
ExecutorEngine executorEngine = connection.getRuntimeContext().getExecutorEngine();
sqlExecutePrepareTemplate = new SQLExecutePrepareTemplate(maxConnectionsSizePerQuery);
sqlExecuteTemplate = new SQLExecuteTemplate(executorEngine, connection.isHoldTransaction());
}
��������һ��Ϊ��һ��ִ������ ��ִ�л�����
������:ִ��sql�ͽ���鲢
ResultSet result = statement.executeQuery(sql);
@Override
public ResultSet executeQuery(final String sql) throws SQLException {
if (Strings.isNullOrEmpty(sql)) {
throw new SQLException(SQLExceptionConstant.SQL_STRING_NULL_OR_EMPTY);
}
ResultSet result;
try {
//����������а�����ʵ����������Ҫ��ȫ����Ϣ��������ʵ����Դ����ʵSQL����ʵ����
//ִ�����������(����sql�������Ż���·�ɡ���д��������)
executionContext = prepare(sql);
//ִ�������ִ�н�
List<QueryResult> queryResults = statementExecutor.executeQuery();
//����鲢��
MergedResult mergedResult = mergeQuery(queryResults);
result = new ShardingResultSet(statementExecutor.getResultSets(), mergedResult, this, executionContext);
} finally {
currentResultSet = null;
}
currentResultSet = result;
return result;
}
һ���������������� executionContext = prepare(sql); sql��������
//ִ�����������:���������-����ȡ����(������Դ)-������ִ�е�Ԫ
private ExecutionContext prepare(final String sql) throws SQLException {
//��պر�ִ����Ҫ����Դ
statementExecutor.clear();
//���»�ȡ����ʱ��Ҫ�Ļ���
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
//����Ƭ�����������á����ӵ����ݿ����ݡ�sql�������� ��װ��������
BasePrepareEngine prepareEngine = new SimpleQueryPrepareEngine(
runtimeContext.getRule().toRules(), runtimeContext.getProperties(), runtimeContext.getMetaData(), runtimeContext.getSqlParserEngine());
//ͨ�������� ����·��,��дsql ����ִ�е�Ԫ
ExecutionContext result = prepareEngine.prepare(sql, Collections.emptyList());
//��ʼ��ִ������ �����ʵsql�Ͳ���
statementExecutor.init(result);
statementExecutor.getStatements().forEach(this::replayMethodsInvocation);
return result;
}
sqlִ�н� List<QueryResult> queryResults = statementExecutor.executeQuery();
public List<QueryResult> executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
//����sqlִ�лص�����
SQLExecuteCallback<QueryResult> executeCallback = new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {
@Override
protected QueryResult executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {
//���ؽ���鲢ģʽ ���ڴ�����ģʽ����������ģʽ
return getQueryResult(sql, statement, connectionMode);
}
};
return executeCallback(executeCallback);
}
//inputGroups�а���������ִ�е���ʵ���ݿ��Լ���ʵSQL�Ͳ�����
@SuppressWarnings("unchecked")
protected final <T> List<T> executeCallback(final SQLExecuteCallback<T> executeCallback) throws SQLException {
//ִ��sql�������ص�����
List<T> result = sqlExecuteTemplate.execute((Collection) inputGroups, executeCallback);
refreshMetaDataIfNeeded(connection.getRuntimeContext(), sqlStatementContext);
return result;
}
public <T> List<T> execute(final Collection<InputGroup<? extends StatementExecuteUnit>> inputGroups,
final SQLExecuteCallback<T> firstCallback, final SQLExecuteCallback<T> callback) throws SQLException {
try {
//serial ���л��Dz���,ȡ��������ģʽ
return executorEngine.execute((Collection) inputGroups, firstCallback, callback, serial);
} catch (final SQLException ex) {
ExecutorExceptionHandler.handleException(ex);
return Collections.emptyList();
}
}
�ص���executorEngine.execute����
public <I, O> List<O> execute(final Collection<InputGroup<I>> inputGroups,
final GroupedCallback<I, O> firstCallback, final GroupedCallback<I, O> callback, final boolean serial) throws SQLException {
if (inputGroups.isEmpty()) {
return Collections.emptyList();
}
//����serial ����sqlִ��ģʽ ��������ģʽ:serialExecute(����ִ��) �ڴ�����ģʽ:parallelExecute(����ִ��)
return serial ? serialExecute(inputGroups, firstCallback, callback) : parallelExecute(inputGroups, firstCallback, callback);
}
��ôserial ��ֵ����ô����������?����������ʱ��,�ᴴ��һ�� sqlExecuteTemplate = new SQLExecuteTemplate(executorEngine, connection.isHoldTransaction());����ôconnection.isHoldTransaction()��ֵ����serial ��
public boolean isHoldTransaction() {
//����DZ�������,���Ҳ����Զ��ύ ����true ���� �ֲ�ʽ���������������з��� true
return (TransactionType.LOCAL == transactionType && !getAutoCommit()) || (TransactionType.XA == transactionType && isInShardingTransaction());
}
����������ִ�л��Dz���ִ��,sqlִ������ص�����,�ص��������շ��ؽ�����Ĺ鲢ģʽ:�ڴ�����ģʽѡ����ʽ�鲢,����������ģʽѡ���ڴ�鲢��
����鲢
MergedResult mergedResult = mergeQuery(queryResults);
private MergedResult mergeQuery(final List<QueryResult> queryResults) throws SQLException {
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
MergeEngine mergeEngine = new MergeEngine(runtimeContext.getRule().toRules(), runtimeContext.getProperties(), runtimeContext.getDatabaseType(), runtimeContext.getMetaData().getSchema());
return mergeEngine.merge(queryResults, executionContext.getSqlStatementContext());
}
�鲢Դ��Ͳ�������,ֻҪ֪��ʲôʱ��������ʽ�鲢,ʲôʱ������ڴ�鲢�ͺá�