目录
?(Tez+Hive)与Impala、Dremel和Drill的区别
8.1 Hadoop的优化与发展
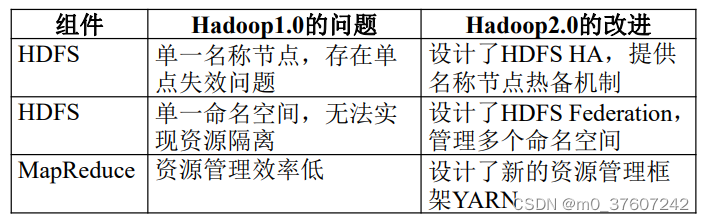
Hadoop1.0的局限与不足
抽象层次低,需人工编码;表达能力有限;开发者需要自己管理作业(Job)之间的依赖关系;
难以看到程序整体逻辑;执行迭代操作效率低;资源浪费(Map和Reduce分两阶段执行);
实时性差(适合批处理,不支持实时交互式)
Hadoop进行的改进的提升
一方面是Hadoop自身两大核心组件MapReduce和 HDFS的架构设计改进;
另一方面是Hadoop生态系统其它组件的不断丰富,加入 了Pig、Tez、Spark和Kafka等新组件。
Hadoop模块的自身改进:从1.0到2.0
Hadoop生态系统2.0新增组件
8.2 HDFS HA和HDFS Federation
Hadoop1.0 HDFS
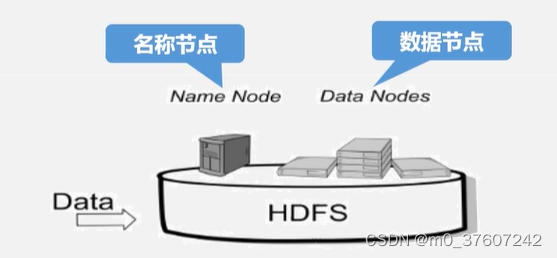
名称节点保存元数据
(1)在磁盘上:FsImage(文件系统树)和EditLog
(2)在内存中:映射信息,即文件包含哪些block块,每个块存储在哪个DataNode数据节点
数据节点储存文件内容
保存在磁盘上,维护block id到DataNode本地文件的映射关系。
第二名称节点
不是热备份;主要是防止日志文件EditLog过 大,导致名称节点失败恢复时消 耗过多时间;附带起到冷备份功能
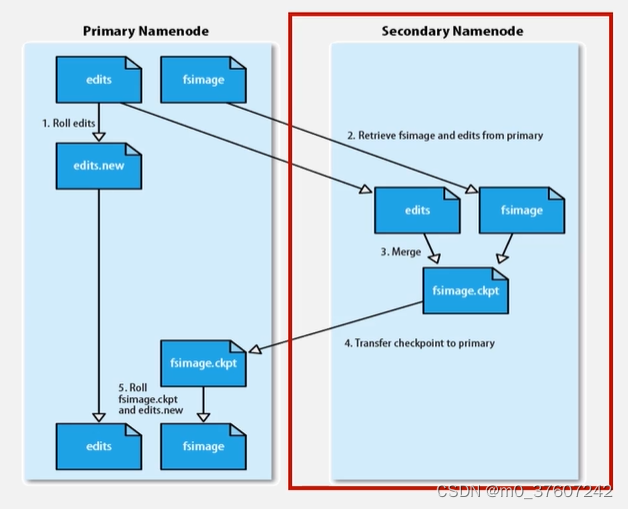
HDFS HA架构
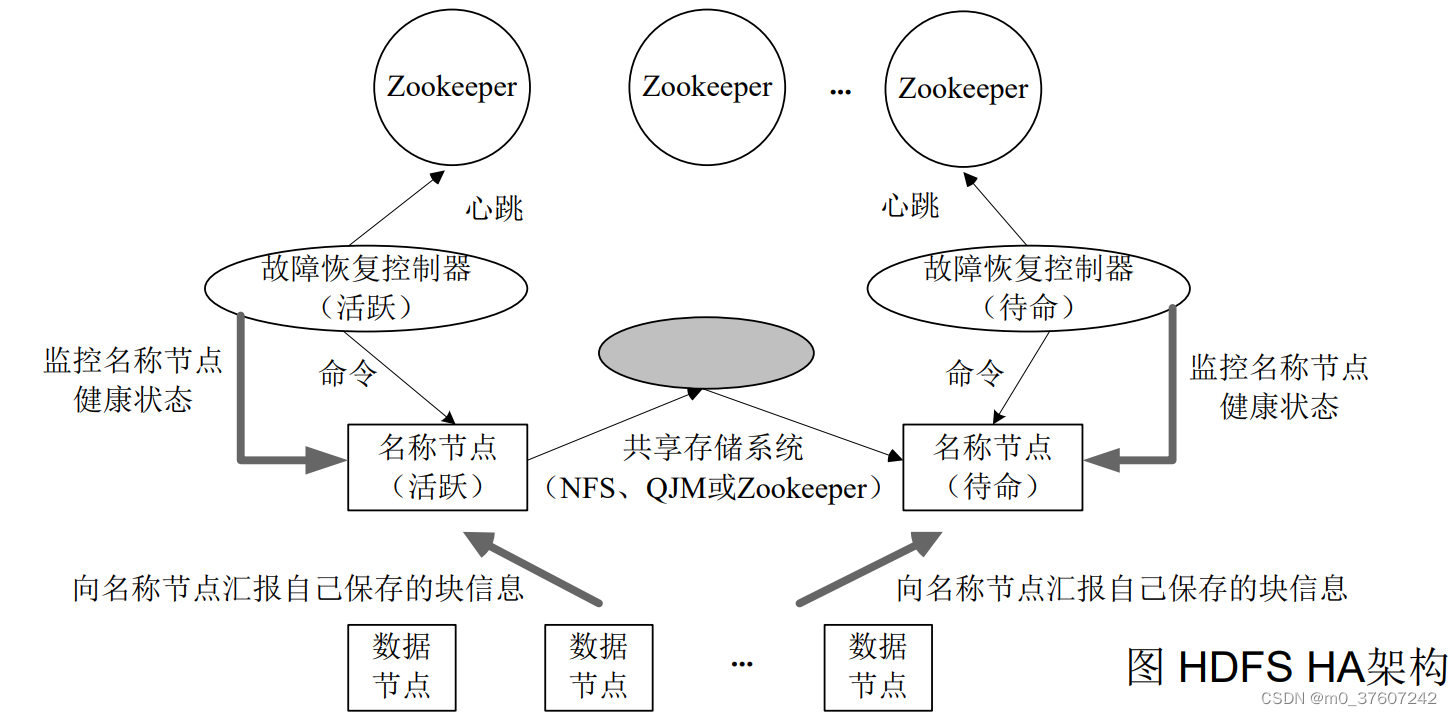
?HDFS HA(High Availability)是为了解决单点故障问题:HA集群设置两个名称节点,“活跃(Active)”和“待命(Standby)”;两种名称节点的状态同步,可以借助于一个共享存储系统(同步活跃状态名称节点的EditLog)来实现(block id与DataNode的映射关系则是数据节点向活跃和待命的名称节点都要汇报得到);一旦活跃名称节点出现故障,就可以立即切换到待命名称节点;Zookeeper确保一个名称节点在对外服务;名称节点维护映射信息,数据节点同时向两个名称节点汇报信息。
HDFS Federation
HDFS1.0存在的问题
单点故障问题(HDFS HA解决);
不可以水平扩展(只有一个名称节点,不能往里加很多个名称节点)是否可以纵向扩展来解决?
系统整体性能受限于单个名称节点的吞吐量;
单个名称节点难以提供不同程序之间的隔离性;
HDFS HA是热备份,提供高可用性,但是无法解决可扩展性、系统性能和隔离性。
HDFS Federation架构
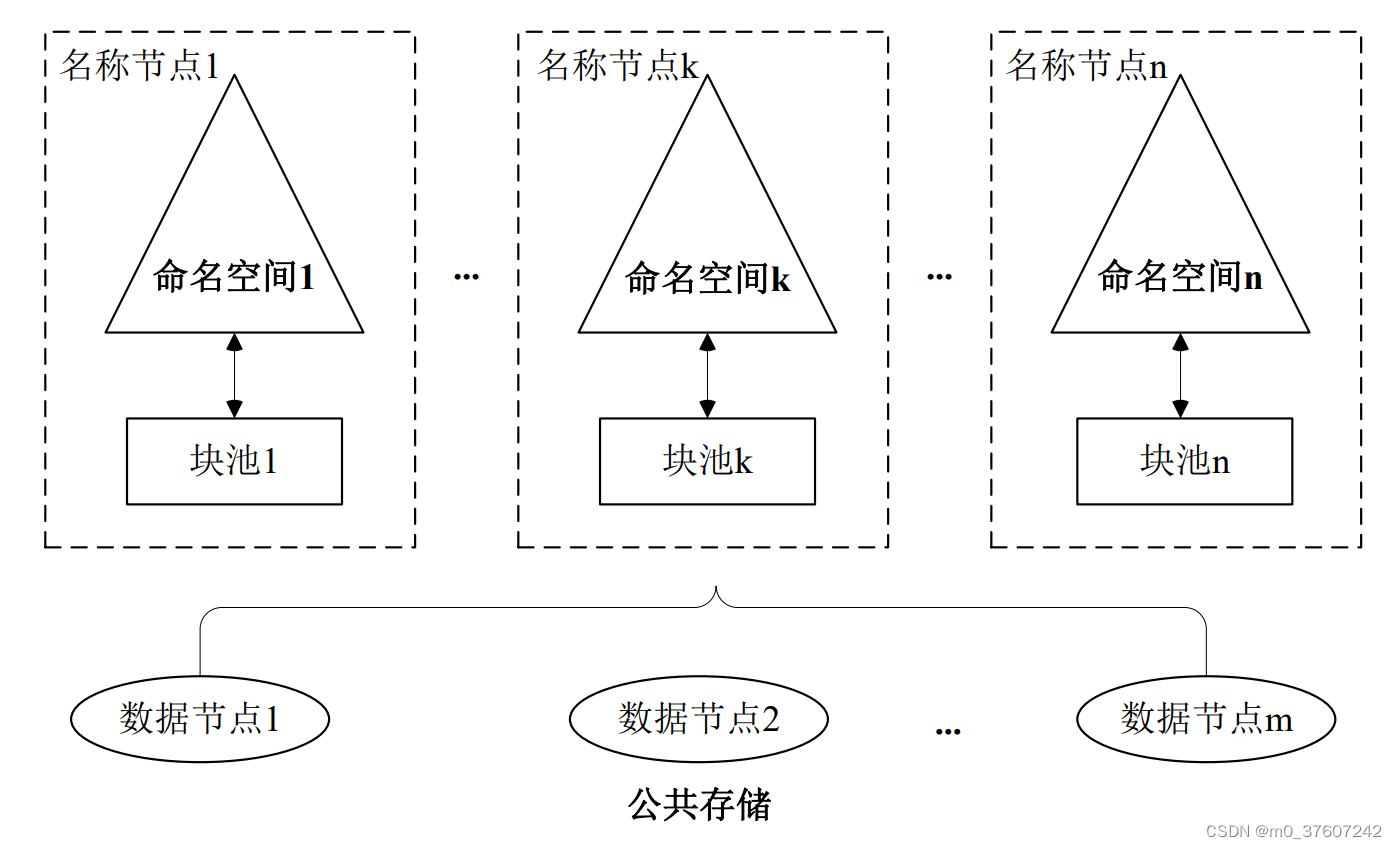
在HDFS Federation中,设计了 多个相互独立的名称节点,使得 HDFS的命名服务能够水平扩展, 这些名称节点分别进行各自命名空间和块的管理,相互之间是联盟(Federation)关系,不需要彼此协调;向后兼容性(基于单名称开发的程序可以直接迁移到Federation体系中);HDFS Federation中,所有名称节点会共享底层的数据节点存储资源,数据节点向所有名称节点汇报;属于同一个命名空间的块构成一个“块池”(逻辑概念,物理上仍然是数据节点的储存)。
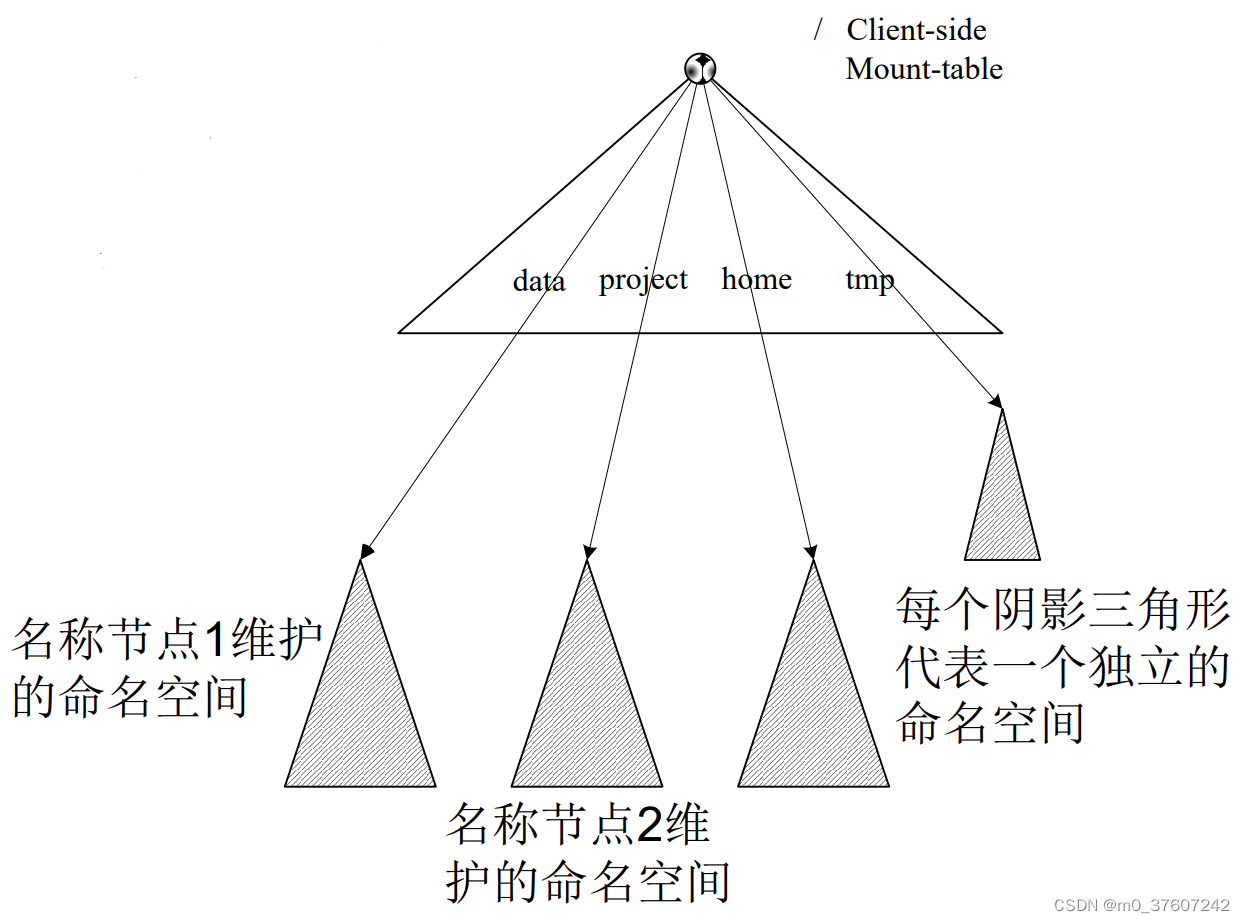
HDFS Federation的访问方式
对于Federation中的多个命名空间,可以采用客户端挂载表(Client Side Mount Table)方式进行数据共享和访问;客户可以访问不同的挂载点来访问不同的子命名空间;把各个命名空间挂载到全局“挂载表” (mount-table)中,实现数据全局共享;同样的命名空间挂载到个人的挂载表中, 就成为应用程序可见的命名空间。
HDFS Federation相对于HDFS1.0的优势
HDFS Federation设计可解决单名称节点存在的以下几个问题:
(1)HDFS集群扩展性。多个名称节点各自分管一部分目录,使得一个集群可以扩展到更多节点,不再像HDFS1.0中那样由于内存的限制制约文件 存储数目;
(2)性能更高效。多个名称节点管理不同的数据,且同时对外提供服务, 将为用户提供更高的读写吞吐率;
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同名称节点 管理,这样不同业务之间影响很小。
需要注意的,HDFS Federation并不能解决单点故障问题,也就是说,每个名称节点都存在在单点故障问题,需要为每个名称节点部署一个后备名称节点,以应对名称节点挂掉对业务产生的影响。
8.3 新一代资源管理框架Yarn
MapReduce1.0缺陷
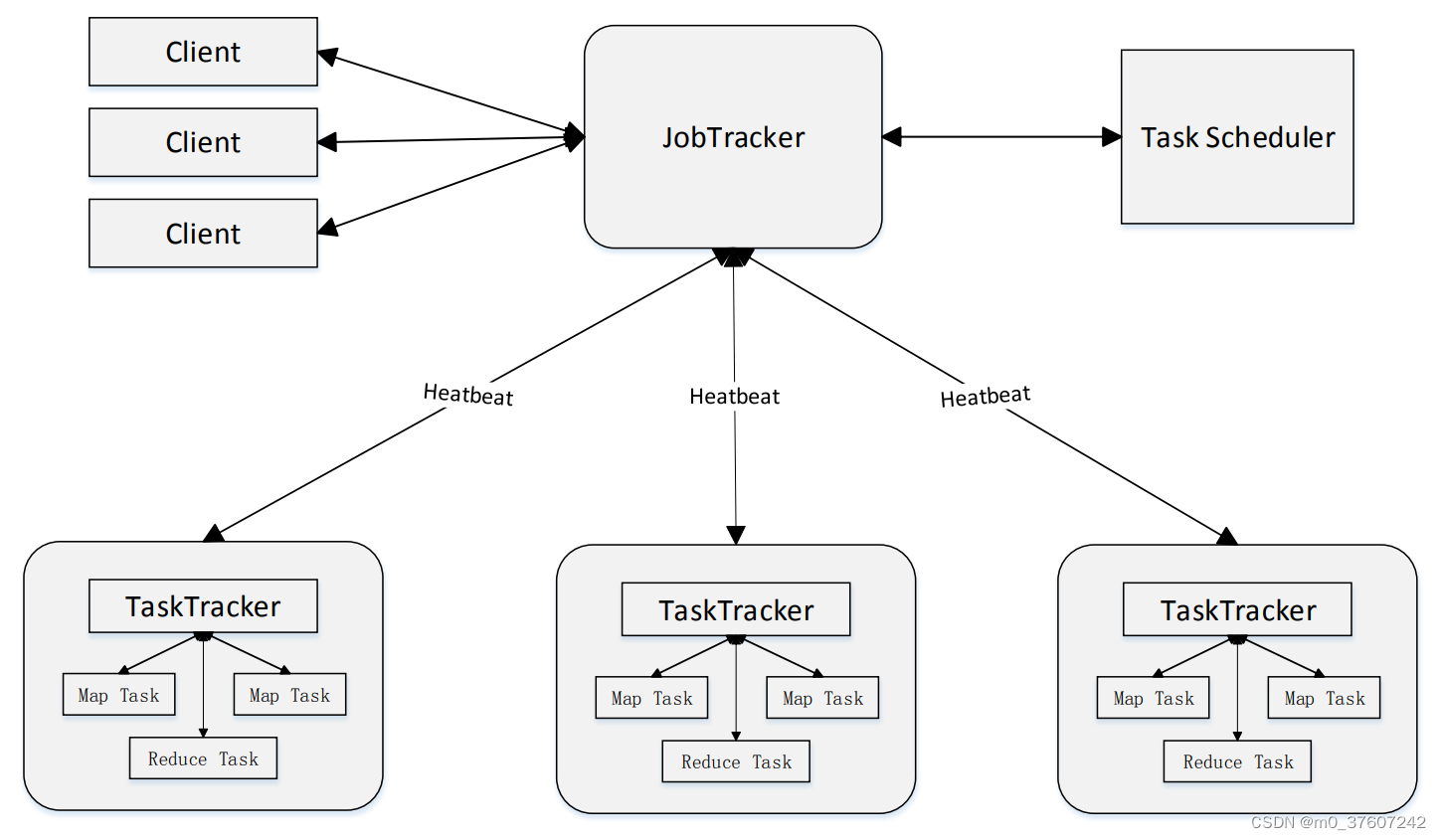
?(1)存在单点故障;
(2)JobTracker“大包大揽”导致任务过重(任务多时内存开销大,上限4000节点);
(3)容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存);
(4)资源划分不合理(强制划分为slot ,包括Map slot和Reduce slot)。
Yarn设计思路
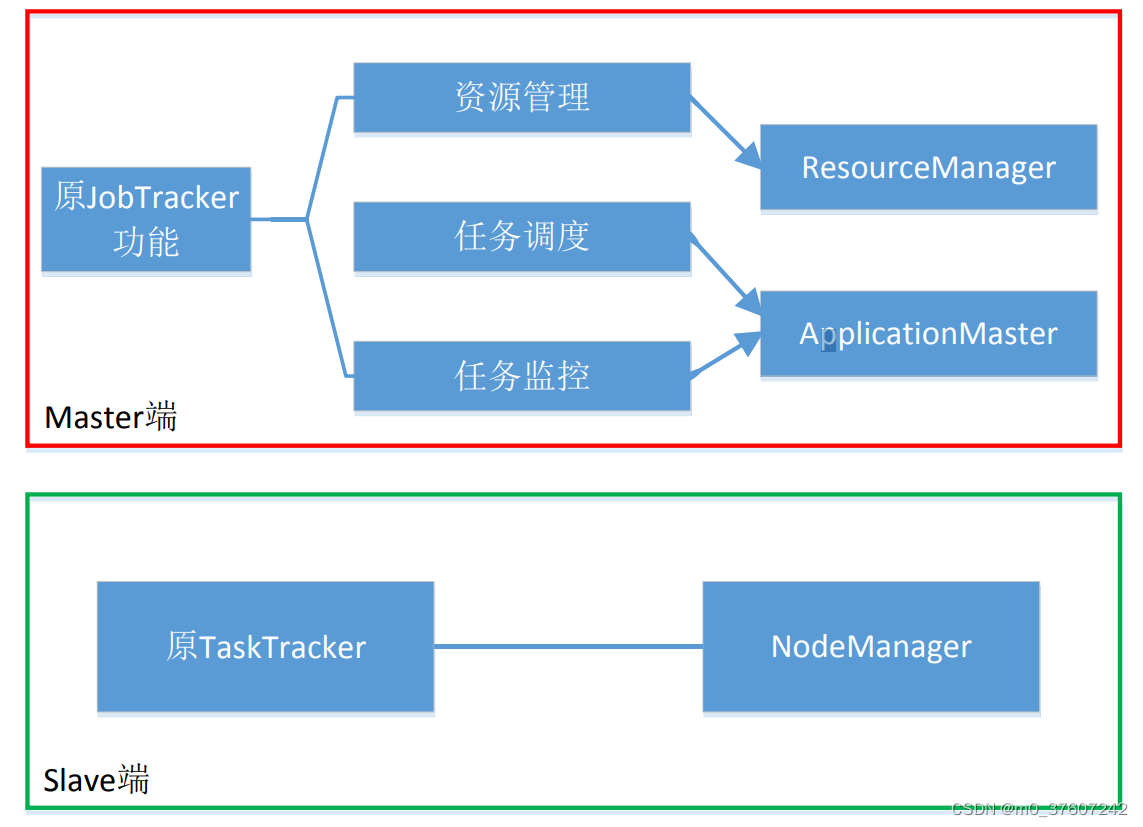 MapReduce1.0既是一个 计算框架,也是一个资源 管理调度框架;
MapReduce1.0既是一个 计算框架,也是一个资源 管理调度框架;
到了Hadoop2.0以后, MapReduce1.0中的资源管理调度功能,被单独分离出来形成了YARN,它 是一个纯粹的资源管理调度框架,而不是一个计算框架;
被剥离了资源管理调度功能的MapReduce 框架就变成了MapReduce2.0, 它是运行在YARN之上的一个纯粹的计算框架,不再自己负责资源调度管理服务,而是由YARN提供资源管理调度服务。
Yarn体系结构
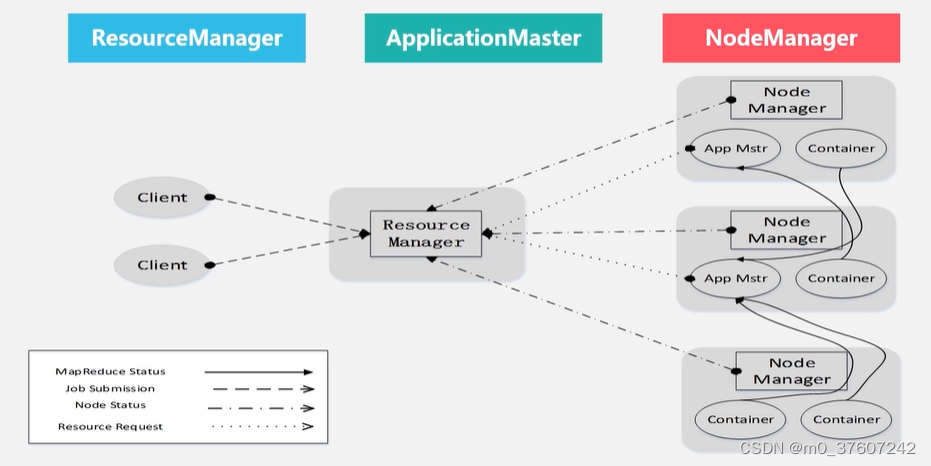
ResourceManager
概述:处理客户端请求;启动/监控ApplicationMaster;监控NodeManager;资源分配与调度。
(1)ResourceManager(RM)是一个全局的资源管理器,负责整个系统的资源管理 和分配,主要包括两个组件,即调度器(Scheduler)和应用程序管理器 (Applications Manager)。
(2)调度器接收来自ApplicationMaster的应用程序资源请求,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,进行就近选择,从而实现“计算向数据靠拢”。
(3)容器(Container)作为动态资源分配单位,每个容器中都封装了一定数量的CPU、 内存、磁盘等资源,从而限定每个应用程序可以使用的资源量,有效地实现了应用程序之间的隔离。
(4)调度器被设计成是一个可插拔的组件,YARN不仅自身提供了许多种直接可用的调度器,也允许用户根据自己的需求重新设计调度器。
(5)应用程序管理器(Applications Manager)负责系统中所有应用程序的管理工作, 主要包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控 ApplicationMaster运行状态并在失败时重新启动等。
ApplicationMaster
概述:为应用程序申请资源, 并分配给内部任务;任务调度、监控与容错(失败恢复)。
ResourceManager接收用户提交的作业,按照作业的上下文信息以及从 NodeManager收集来的容器状态信息,启动调度过程,为用户作业启动一个 ApplicationMaster,主要功能包括:
(1)当用户作业提交时,ApplicationMaster与ResourceManager协商获取资源, ResourceManager会以容器的形式为ApplicationMaster分配资源;
(2)把获得的资源进一步分配给内部的各个任务(Map任务或Reduce任务), 实现资源的“二次分配”;
(3)与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止, 监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行失败恢复(即重新申请资源重启任务);
(4)定时向ResourceManager发送heartbeat“心跳”消息,报告资源使用情况和应用进度信息;
(5)当作业完成时,ApplicationMaster向ResourceManager注销容器,执行周期完成。
NodeManager
概述:单个节点上的资源管理;处理来自ResourceManger的命令;处理来自ApplicationMaster的命令。(NodeManager是驻留在一个YARN集群中的每个节点上的代理)主要负责:
(1)容器生命周期管理;
(2)监控每个容器的资源(CPU、内存等)使用情况;
(3)跟踪节点健康状况;
(4)以“心跳”的方式与ResourceManager保持通信;
(5)向ResourceManager汇报作业的资源使用情况和每个容器的运行状态;
(6)接收来自ApplicationMaster的启动/停止容器的各种请求。
说明:NodeManager主要负责管理抽象的容器,只处理与容器相关的事情,而不具体负责每个任务(Map任务或Reduce任务)自身状态的管理,因为这些管理工作是由ApplicationMaster完成的,ApplicationMaster会通过不断与 NodeManager通信来掌握各个任务的执行状态。
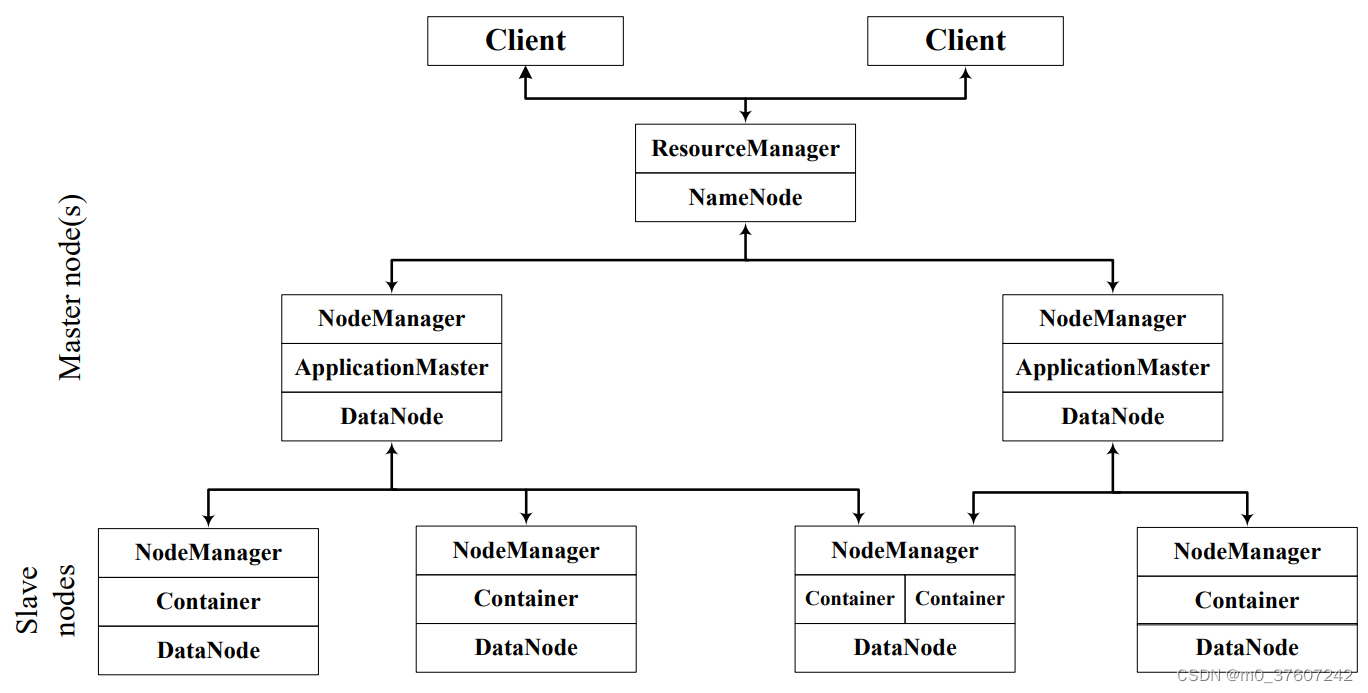
YARN和Hadoop平台其他组件的统一部署
Yarn的工作流程
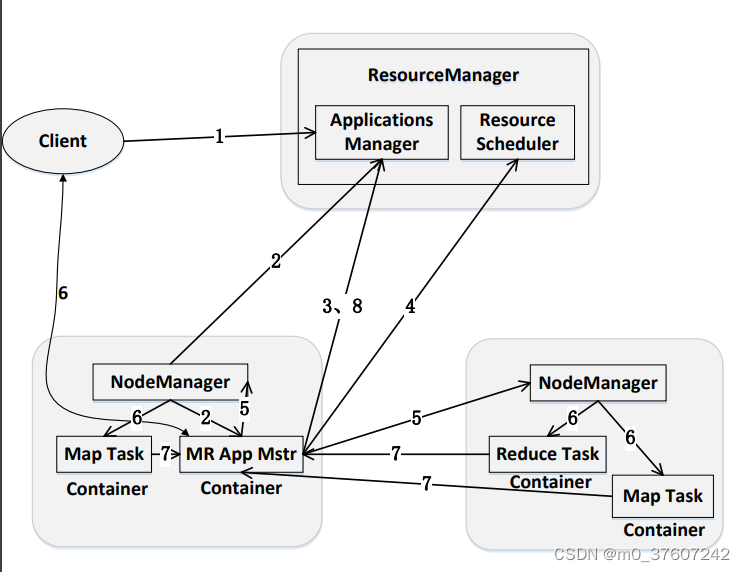
步骤1:用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括 ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等;
步骤2:YARN中的ResourceManager负责接收和处理来自客户端的请求,为应 用程序分配一个容器,在该容器中启动一个ApplicationMaster;
步骤3:ApplicationMaster被创建后会首 先向ResourceManager注册;
步骤4:ApplicationMaster采用轮询的方 式向ResourceManager申请资源;
步骤5:ResourceManager以“容器” 的形式向提出申请的ApplicationMaster 分配资源;
步骤6:在容器中启动任务(运行环境、 脚本);
步骤7:各个任务向ApplicationMaster汇 报自己的状态和进度;
步骤8:应用程序运行完成后, ApplicationMaster向ResourceManager 的应用程序管理器注销并关闭自己。
YARN框架与MapReduce1.0框架的对比分析
从MapReduce1.0框架发展到YARN框架,客户端并没有发生变化,其大部分调用API及接口都保持兼容,因此,原来针对Hadoop1.0开发的 代码不用做大的改动,就可以直接放到Hadoop2.0平台上运行。
YARN相对于MapReduce1.0的优势
大大减少了承担中心服务功能的ResourceManager的资源消耗;ApplicationMaster来完成需要大量资源消耗的任务调度和监控;多个作业对应多个ApplicationMaster,实现了监控分布化。
MapReduce1.0既是一个计算框架,又是一个资源管理调度框架,但是只能支持MapReduce编程模型。而YARN则是一个纯粹的资源调度管理框架,在它上面可以运行包括MapReduce在内的不同类型的计算框架, 只要编程实现相应的ApplicationMaster(可替换模块)。
YARN中的资源管理比MapReduce1.0更加高效;以容器(CPU,内存统筹管理)为单位,而不是以slot(分为Map slot和Reduce slot不互通)为单位。
YARN的发展目标
一个企业当中同时存在各种不同的业务应用场景,需要采用不同的计算框架:
使用MapReduce实现离线批处理;
使用Impala实现实时交互式查询分析;
使用Storm实现流式数据实时分析;
使用Spark实现迭代计算。
这些产品通常来自不同的开发团队,具有各自的资源调度管理机制。为了避免不同类型应用之间互相干扰,企业就需要把内部的服务器拆分成多个 集群,分别安装运行不同的计算框架,即“一个框架一个集群”。
导致问题:集群资源利用率低;数据无法共享;维护代价高。
YARN的目标――实现“一个集群多个框架”
在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架。由YARN为这些计算框架提供统一的资源调度管理服务,并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩;可以实现一个集群上的不同应用负载混搭,有效提高了集群的利用率;不同计算框架可以共享底层存储,避免了数据集跨集群移动。
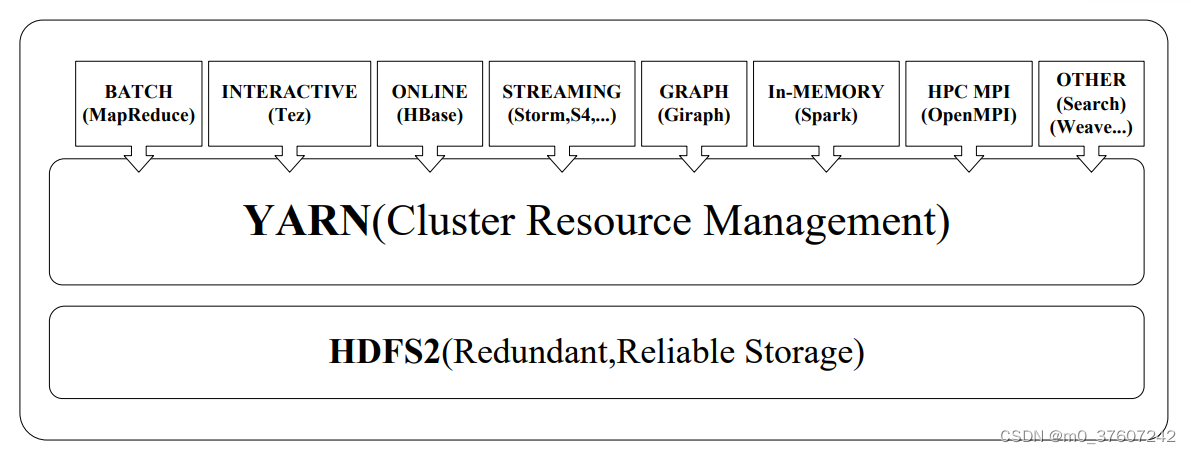
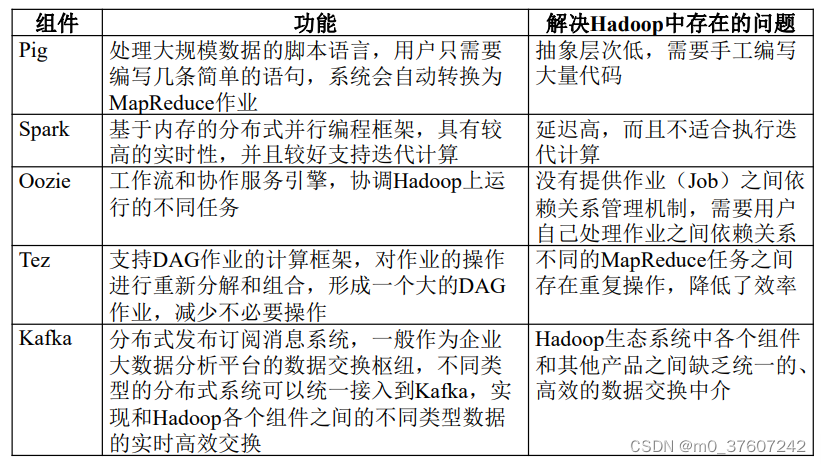
?8.4Hadoop生态系统中具有代表性的功能组件
Pig
Pig是Hadoop生态系统的一个组件;
提供了类似SQL的Pig Latin语言(包含Filter、GroupBy、Join、OrderBy等操作,同时也支持用户自定义函数);
允许用户通过编写简单的脚本来实现复杂的数据分析,而不需要编写复杂的MapReduce应用程序 Pig会自动把用户编写的脚本转换成MapReduce作业在Hadoop集群 上运行,而且具备对生成的MapReduce程序进行自动优化的功能;
用户在编写Pig程序的时候,不需要关心程序的运行效率,这就大大减少了用户编程时间;
通过配合使用Pig和Hadoop,在处理海量数据时可以实现事半功倍的效果,比使用Java、C++等语言编写MapReduce程序的难度要小很多,并且用更少的代码量实现了相同的数据处理分析功能。
Pig可以加载数据、表达转换数据以及存储最终结果。
Pig语句通常按照如下的格式来编写:
通过LOAD语句从文件系统读取数据;通过一系列“转换”语句对数据进行处理;通过一条STORE语句把处理结果输出到文件系统中,或者使用DUMP语句把处理结果输出到屏幕上。
下面是一个采用Pig Latin语言编写的应用程序实例,实现对用户访问网页 情况的统计分析:
visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(visits);
//得到的表的结构visitCounts(url,visits)
urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url;
//得到的连接结果表的结构visitCounts(url,visits,category,pRank)
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;Pig Latin是通过编译为 MapReduce在Hadoop集群上执行的。统计用户访问量程序被编译成 MapReduce时,会产生如下图所示 的Map和Reduce: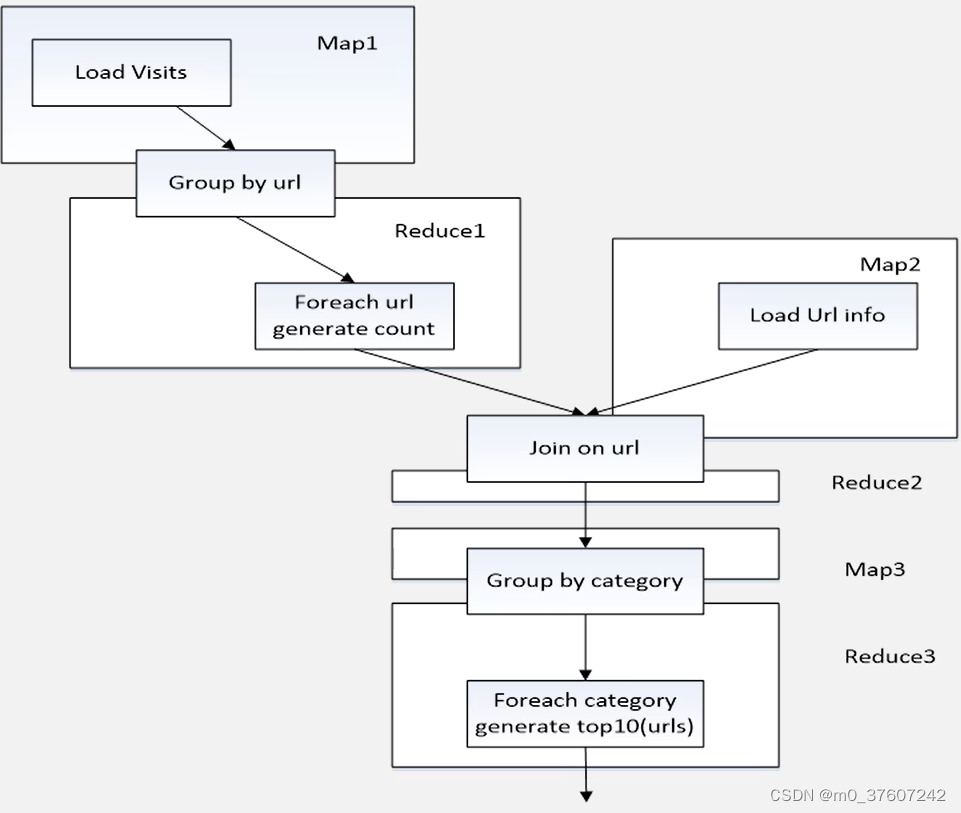
?Pig的应用场景:数据查询只面向相关技术人员。
即时性的数据处理需求,这样可以通过pig很快写一个脚本开始运行处理,而不需要创建表等相关 的事先准备工作。
Tez
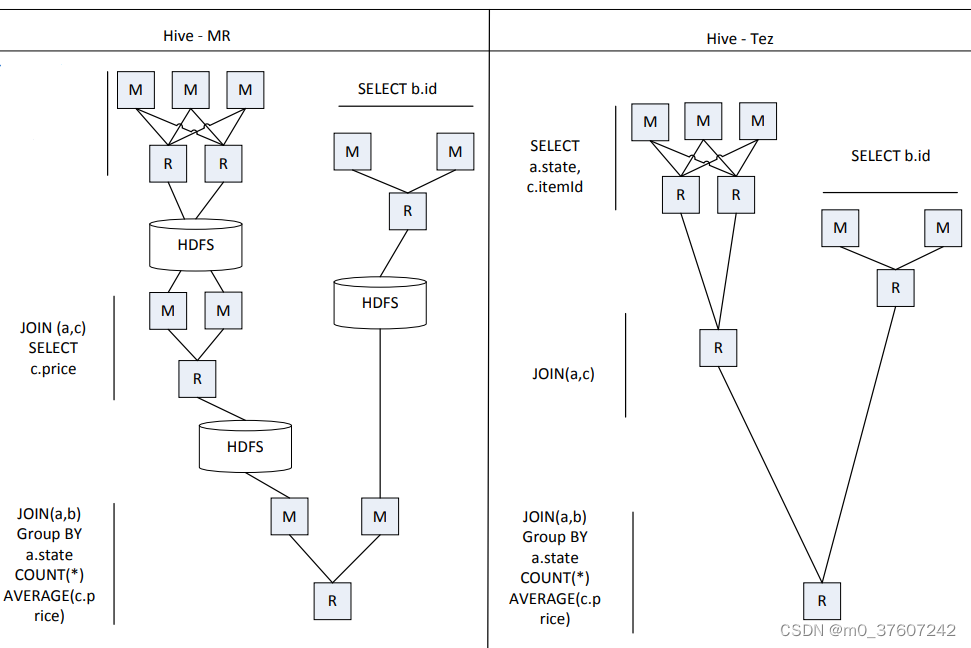
Tez是Apache开源的支持DAG(有向无环图)作业的计算框架,它直接源于 MapReduce框架。
核心思想是将Map和Reduce两个操作进一步拆分:Map被拆分成Input、Processor、Sort、Merge和Output;Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等。分解后的元操作可以任意灵活组合,产生新的操作;这些操作经过一些控制程序组装后,可形成一个大的DAG作业;通过DAG作业的方式运行MapReduce作业,提供了程序运行的整体处理逻辑,就可以去除工作流当中多余的Map阶段,减少不必要的操作, 提升数据处理的性能。
Hortonworks把Tez应用到数据仓库Hive的优化中,使得性能提升了约100倍。
代码示例:
SELECT a.state, COUNT(*),AVERAGE(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
Tez优化的主要体现
去除了连续两个作业之间的“写入HDFS”;去除了每个工作流中多余的Map阶段。
在Hadoop2.0生态系统中,MapReduce、Hive、Pig等计算框架,都需要最终以MapReduce任务的形式执行数据分析,因此,Tez框架可以发挥重要的作用。借助于Tez框架实现对MapReduce、Pig和Hive等的性能优化,可以解决现有MR框架在迭代计算(如PageRank计算)和交互式计算方面的问题。
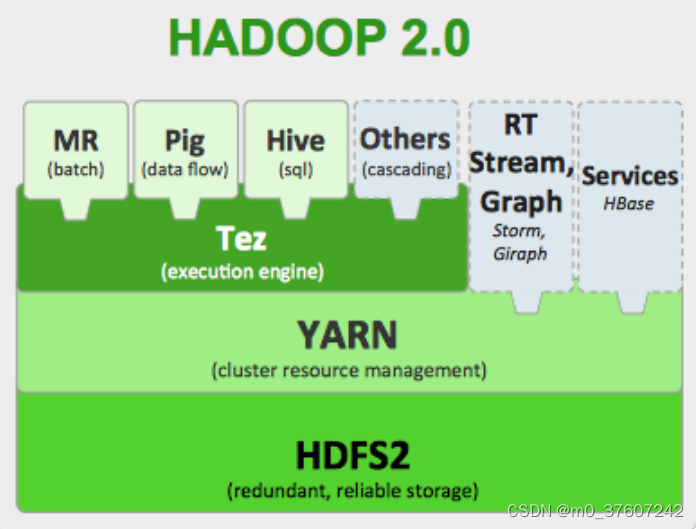
?(Tez+Hive)与Impala、Dremel和Drill的区别
Tez在解决Hive、Pig延迟大、性能低等问题的思路,是和那些支持实时交互式查询分析的产品(如Impala、Dremel和Drill等)是不同的。
Impala、Dremel和Drill的解决问题思路是抛弃MapReduce计算框架, 不再将类似SQL语句的HiveQL或者Pig语句翻译成MapReduce程序,而 是采用与商用并行关系数据库类似的分布式查询引擎,可以直接从HDFS或者HBase中用SQL语句查询数据,而不需要把SQL语句转化成 MapReduce任务来执行,从而大大降低了延迟,很好地满足了实时查询的要求。
Tez则不同,比如,针对Hive数据仓库进行优化的“Tez+Hive”解决方案, 仍采用MapReduce计算框架,但是对DAG的作业依赖关系进行了裁剪, 并将多个小作业合并成一个大作业,这样,不仅计算量减少了,而且写 HDFS次数也会大大减少。
Spark
Hadoop缺陷
其MapReduce计算模型延迟过高,无法胜任实时、快速计算的 需求,因而只适用于离线批处理的应用场景;
中间结果写入磁盘,每次运行都从磁盘读数据;
在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务。
Spark最初诞生于伯克利大学的APM实验室,是一个可应用于大规模数据处理的快速、通用引擎?。
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题:内存计算,带来了更高的迭代运算效率;基于DAG的任务调度执行机制,优于MapReduce的迭代执行机制。Spark以其结构一体化、功能多元化的优势,逐渐成为当今热门的大数据计算平台。
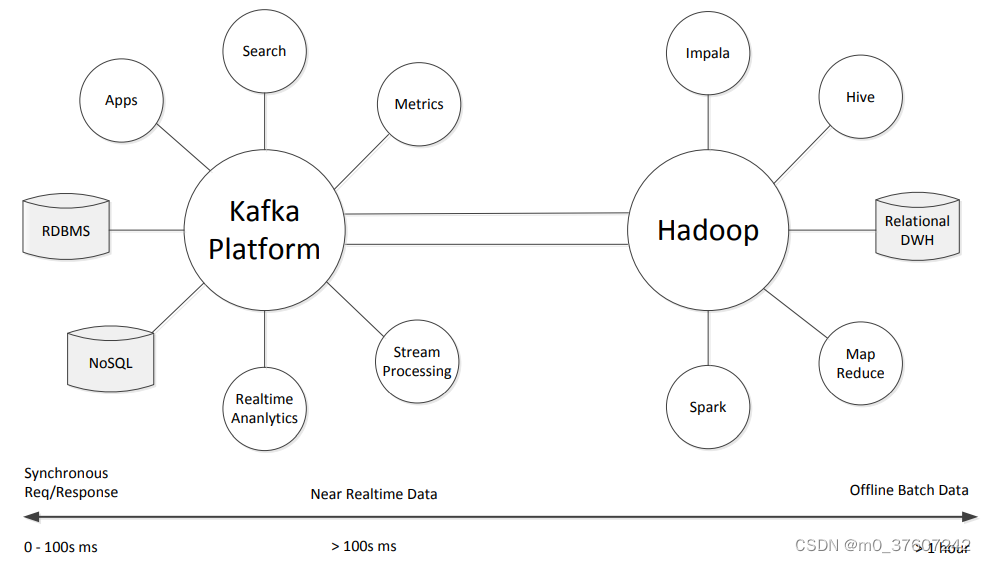
Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,用户通过Kafka系统可以发布大量的消息,同时也能实时订阅消费消息。Kafka可以同时满足在线实时处理和批量离线处理。
在公司的大数据生态系统中,可以把 Kafka作为数据交换枢纽,不同类型的分布式系统(关系数据 库、NoSQL数据库、 流处理系统、批处理系统等),可以统一接入到Kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换。
?