一、测试(可忽略)
这里使用IDEA创建java项目进行测试
1.创建Java项目
2.编写java代码(源代码在后面)
3.生成jar包
(1)修改项目结构(个人觉得可以忽略掉)
文件→项目结构→工件
添加来自具有依赖项的模块
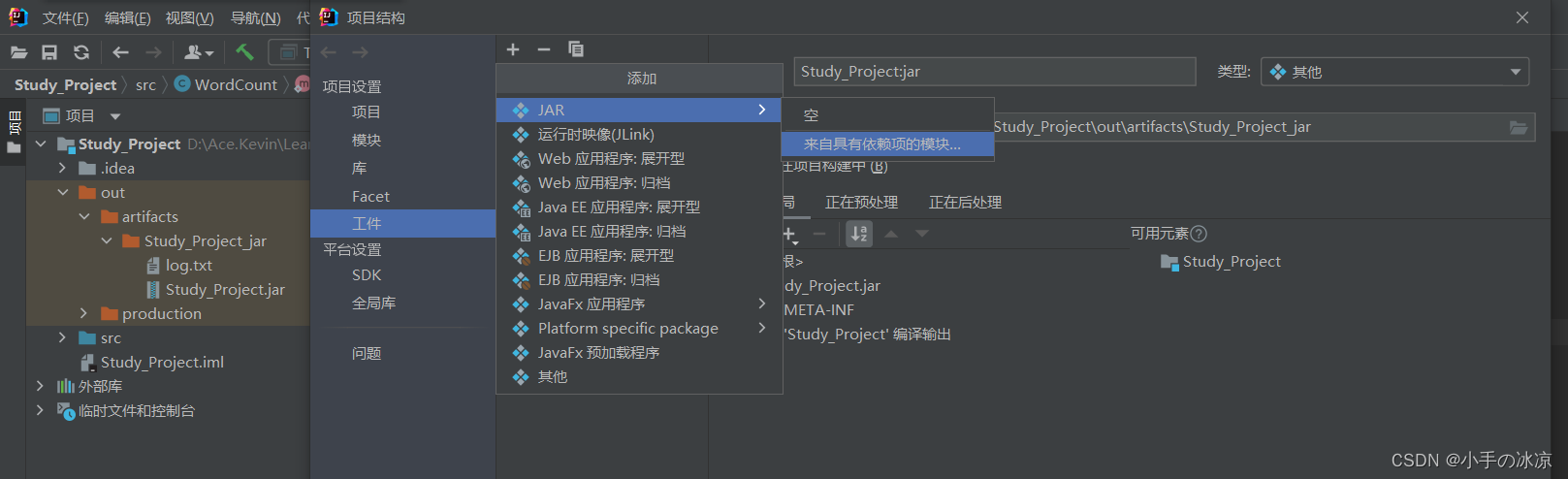
选择主类
复制到输出目录并通过清单链接
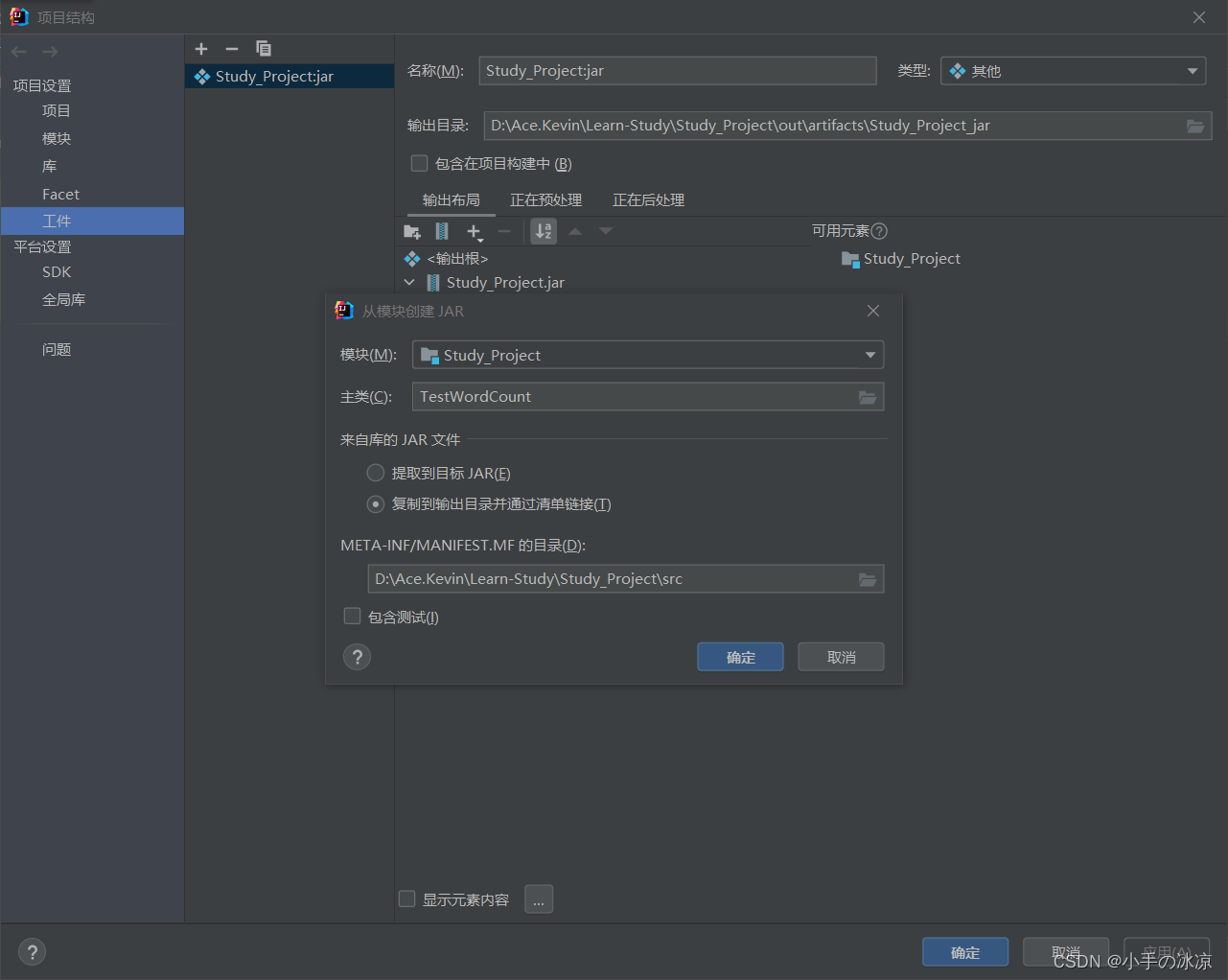
(2)导出jar包
构建→构建工件→构建
IDEA项目将在out文件中生成对应jar包
4.运行jar包
注意:需要正确配置jdk环境变量,不然无法运行jar包


【以上对完成此次作业没有任何帮助(#^.^#)】
【以上对完成此次作业没有任何帮助(#^.^#)】
【以上对完成此次作业没有任何帮助(#^.^#)】
二、创建mywordfile文件【省略图片】
(1)在本地/usr/local/hadoop创建mywordfile.txt文件(略)
(2)在Hadoop上创建input,output目录
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -mkdir output
(3)启动Hadoop,上传文件mywordfile.txt到input目录中
./bin/hdfs dfs - put mywordfile.txt input
(4)创建myapp目录(将生成的jar包导入此目录)
sudo mkdir /usr/local/hadoop/myapp
三、使用Eclipse创建java文件,生成Test5.jar包
(1)使用Eclipse创建java项目
注意:使用Eclipse前一定要配置好jdk,创建和自己本地jdk版本一致的项目!
导入项目需要的jar包:
①/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar;
②“/usr/local/hadoop/share/hadooplcommon/lib”目录下的所有JAR包;
③“/usrlocal/hadoop/share/hadoop/mapreduce”目录下的所有JAR包,但是,不包括jdiff、lib、lib-examples和sources目录
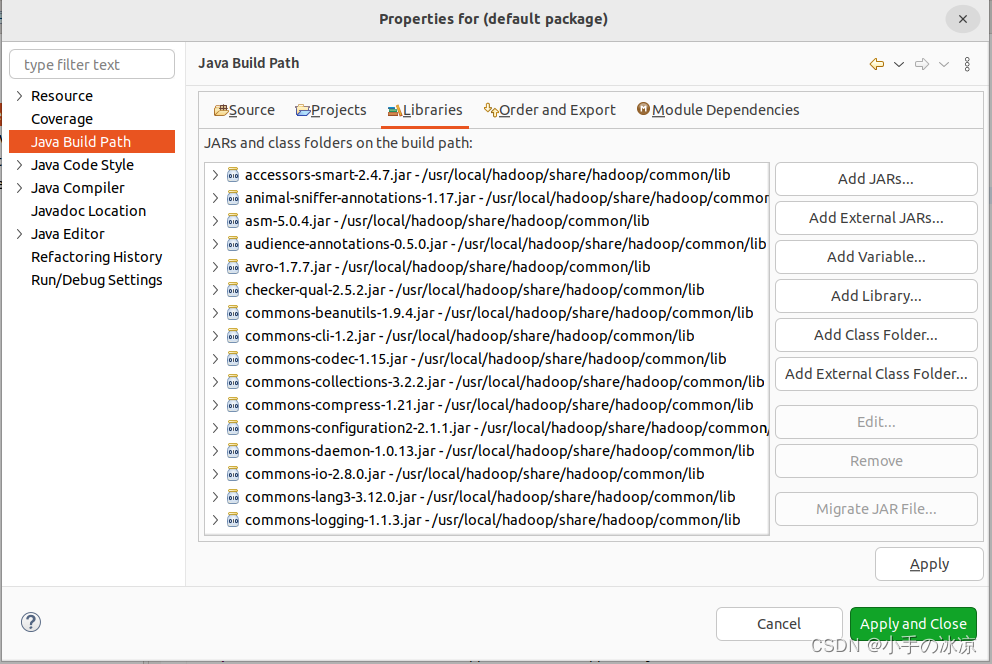
JRE System Library建议选用[JS2E-1.5]
(2)编写java代码
源代码:(WordCount)
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
????public WordCount() {
????}
?????public static void main(String[] args) throws Exception {
????????Configuration conf = new Configuration();
????????String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
????????if(otherArgs.length < 2) {
????????????System.err.println("Usage: wordcount <in> [<in>...] <out>");
????????????System.exit(2);
????????}
????????Job job = Job.getInstance(conf, "word count");
????????job.setJarByClass(WordCount.class);
????????job.setMapperClass(WordCount.TokenizerMapper.class);
????????job.setCombinerClass(WordCount.IntSumReducer.class);
????????job.setReducerClass(WordCount.IntSumReducer.class);
????????job.setOutputKeyClass(Text.class);
????????job.setOutputValueClass(IntWritable.class);
????????for(int i = 0; i < otherArgs.length - 1; ++i) {
????????????FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
????????}
????????FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
????????System.exit(job.waitForCompletion(true)?0:1);
????}
????public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
????????private static final IntWritable one = new IntWritable(1);
????????private Text word = new Text();
????????public TokenizerMapper() {
????????}
????????public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
????????????StringTokenizer itr = new StringTokenizer(value.toString());
????????????while(itr.hasMoreTokens()) {
????????????????this.word.set(itr.nextToken());
????????????????context.write(this.word, one);
????????????}
????????}
????}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
????????private IntWritable result = new IntWritable();
????????public IntSumReducer() {
????????}
????????public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
????????????int sum = 0;
????????????IntWritable val;
????????????for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
????????????????val = (IntWritable)i$.next();
????????????}
????????????this.result.set(sum);
????????????context.write(key, this.result);
????????}
????}
}
(3)生成jar包:
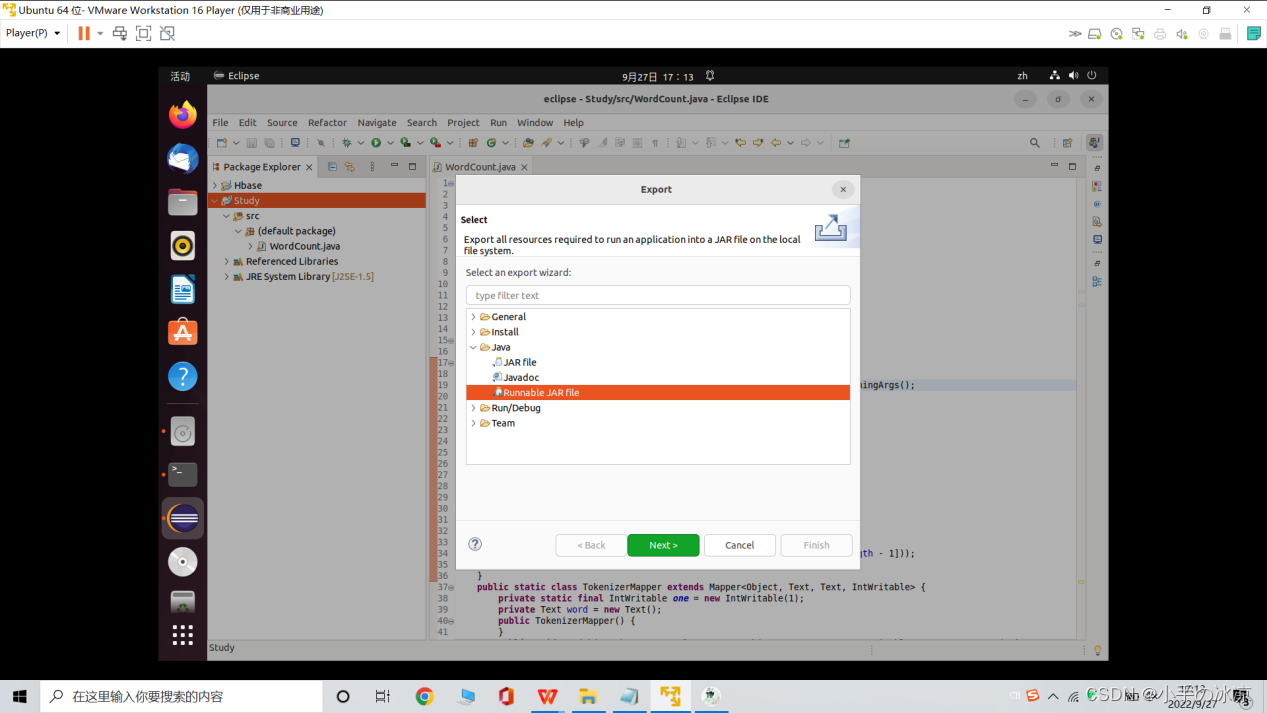
右键项目→选择Export→选择Java/Runnable JAR file
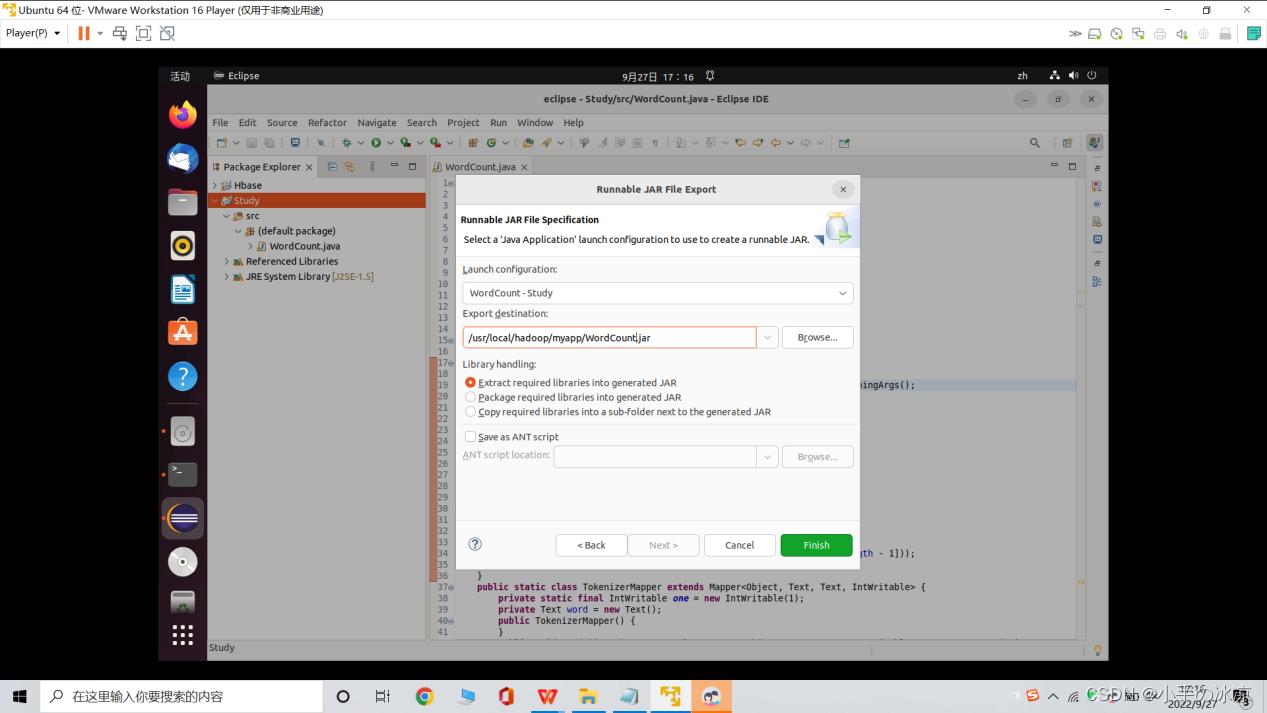
Launch configuration:选择运行的主类(我的是WordCount -Study)
Export destination:选择导出位置:/usr/lcoal/hadoop/myapp
 ?
?
?
注意:权限问题:sudo chmod 777 -R /usr/local/hadoop
四、使用Test5.jar包
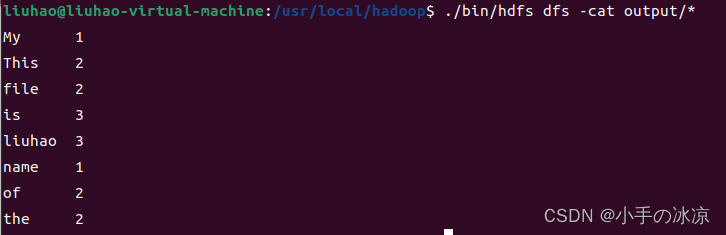
备注:本人的Eclipse导出jar包后报错找不到input,所以由使用idea导出jar包(原理和Eclipse一致,过程可以上网搜索),导出后的jar包名字为:test5.jar

 ?
?
【参考资料】