���ݿ����
- ����һ�������ݽṹ����֯���洢�������ݵIJֿ⡣
���ݿ����ϵͳ
- ���ݺ������ݿ�Ĵ�������,���ڴ�����ʹ�ú�ά�����ݿ�,���DBMS
��ϵ�����ݿ�(RDBMS)
- ����:��ϵ�����ݿ��ǽ����ڹ�ϵģ�͵Ļ�����,�ɶ�������ӵĶ�ά��������ݿ�
- �ص�:ʹ�ñ��洢����, ��ʽͳһ,����ά��;ʹ��SQL���,��ͳһ,ʹ�÷���;���ݴ洢�ڴ�����,�ϵ�Ҳ����Ӱ�����ݰ�ȫ��
�ǹ�ϵ�����ݿ�(NoSQL)
- ����:Not-Only SQL,��ָ�ǹ�ϵ�����ݿ�,�ǶԹ�ϵ�����ݿ�IJ���
- �ص�:���ݽṹ���;������ǿ
SQL����
- �ṹ����ѯ����(Structured Query Language)
- ��һ�ֲ�����ϵ�����ݿ�ı������,������һ�ײ�����ϵ�����ݿ��ͳһ��
Mysql �汾
- Mysql������:���,MYSQL���ṩ����֧��
- Mysql��ҵ��:�շ�,���������30��
- �����Ѱ�װ8.0.26Ϊ��,���Ҫ��װ���°�,��Ҫ��ж�ؾɰ�
Mysql��װ
- ѡ��Ĭ�ϵĿ�����ģʽ
 - ��黷��,�������
 - ִ�а�װ���������
 - ��װ���,��ʱ5��������
 - ���������һ��
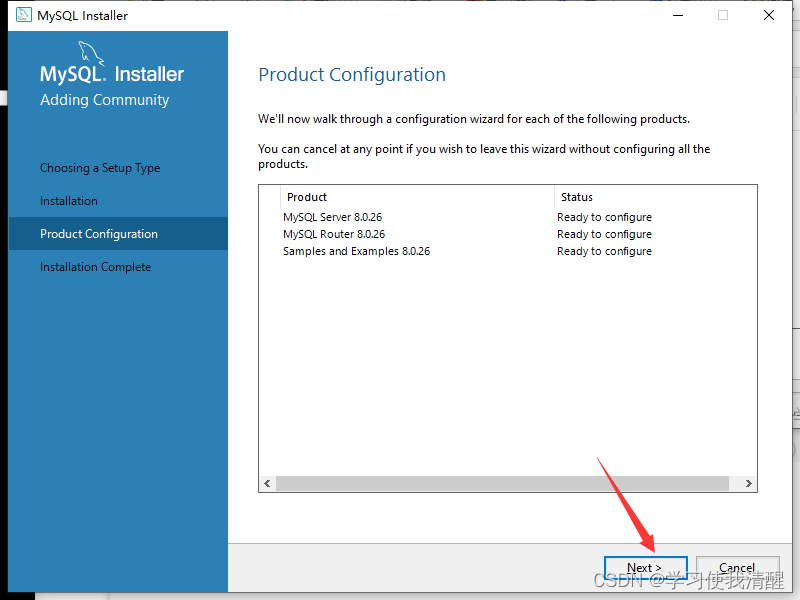 - Ĭ�϶˿�3306,����Ķ�,�������
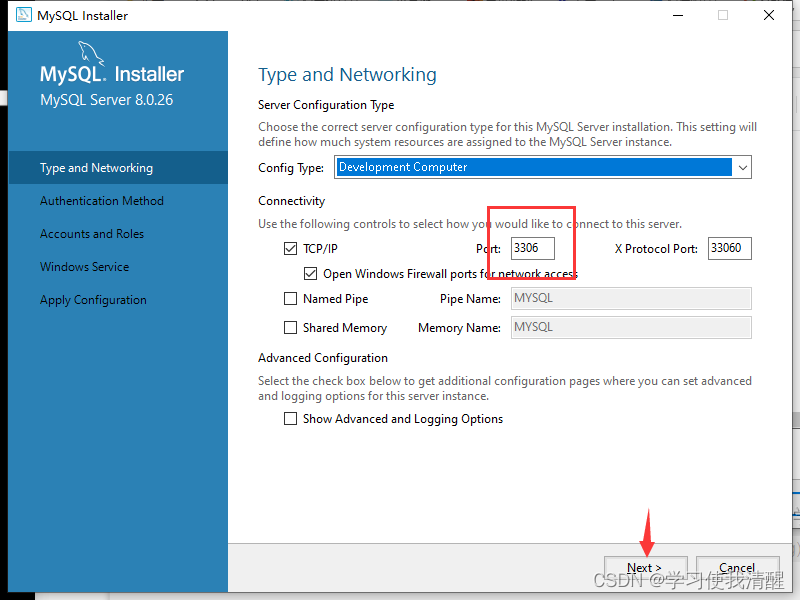 - ѡ��Ĭ�ϵ��Ƽ���װ,���������һ��
 - ��������,�����һ��
 - ������һ��
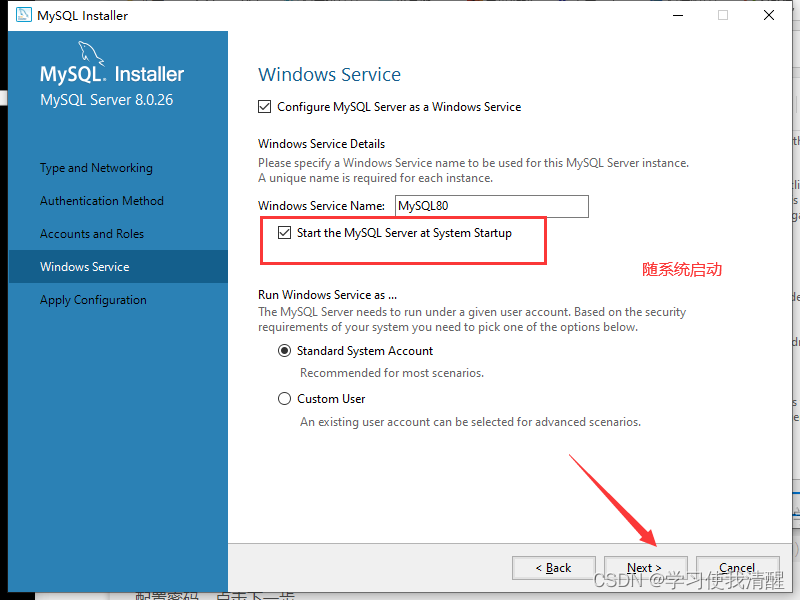 - �������ִ��
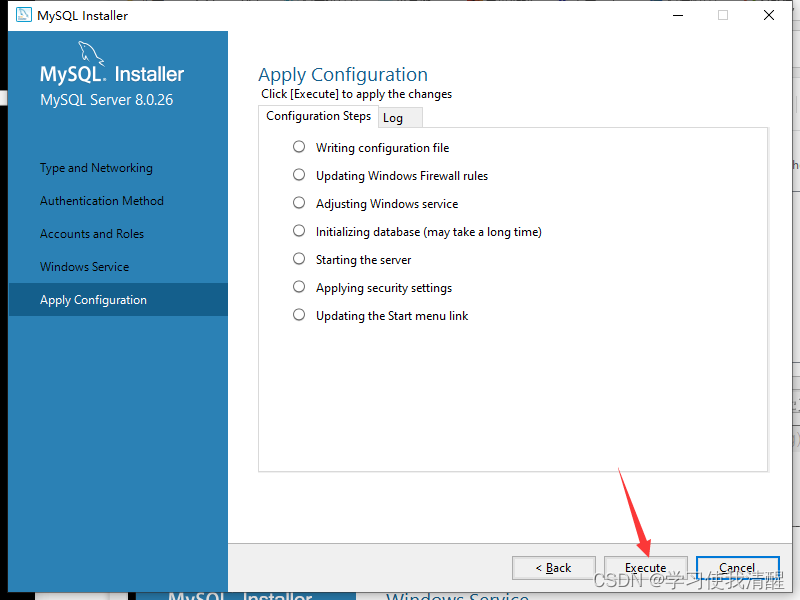 - ��װ���
Mysql����
��ʽһ
- ����ϵͳ����(mysql��װ��ɺ��Զ�ע��Ϊ��������)
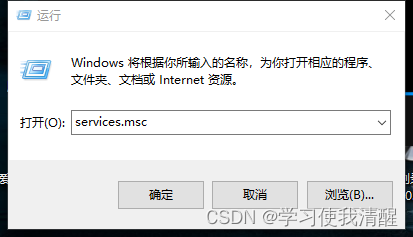
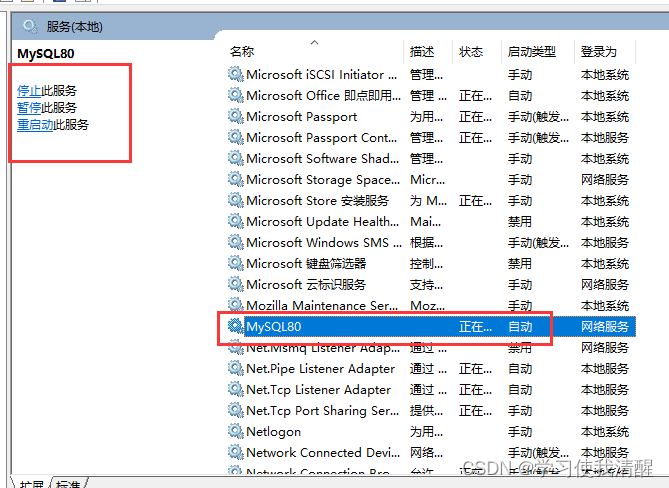
��ʽ��
- CMD������ ���� net start mysql80
- CMD������ ֹͣ net stop mysql80
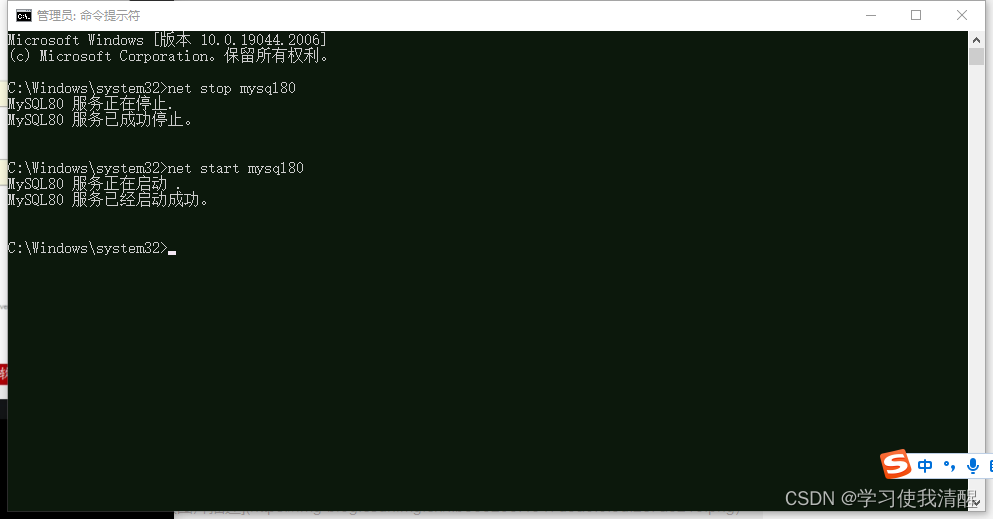
Mysql�ͻ�������
��ʽһ
- ʹ��MYSQL�ṩ�Ŀͻ������ӹ���
 - �ѵ�¼
��ʽ��
- windows������ִ������,ʹ�����ַ�ʽʱ,��Ҫ����PATH���� ����
- �༭PATH��������
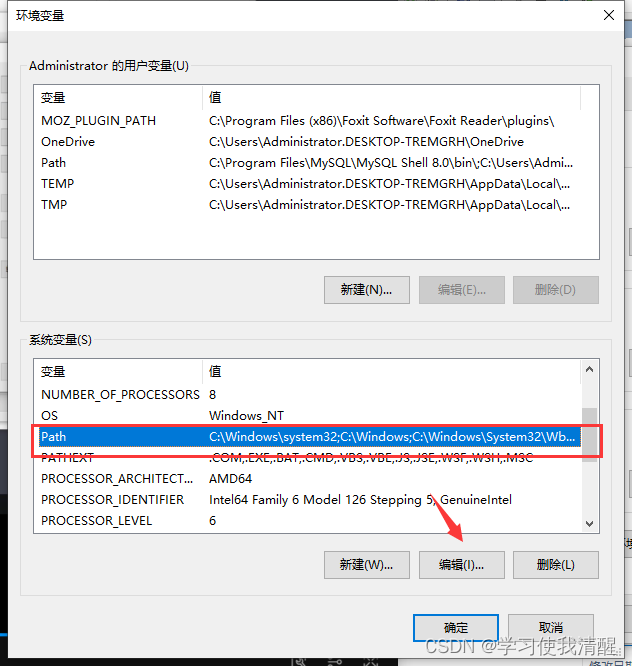 - ��������·��
 - ���ӻ�������
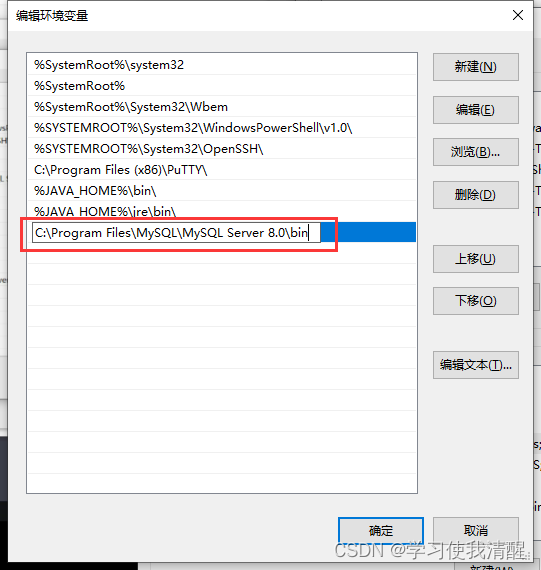 - ���ʽΪ:mysql [127.0.0.1] [-P 3306] -u user -p
- �����е�¼:
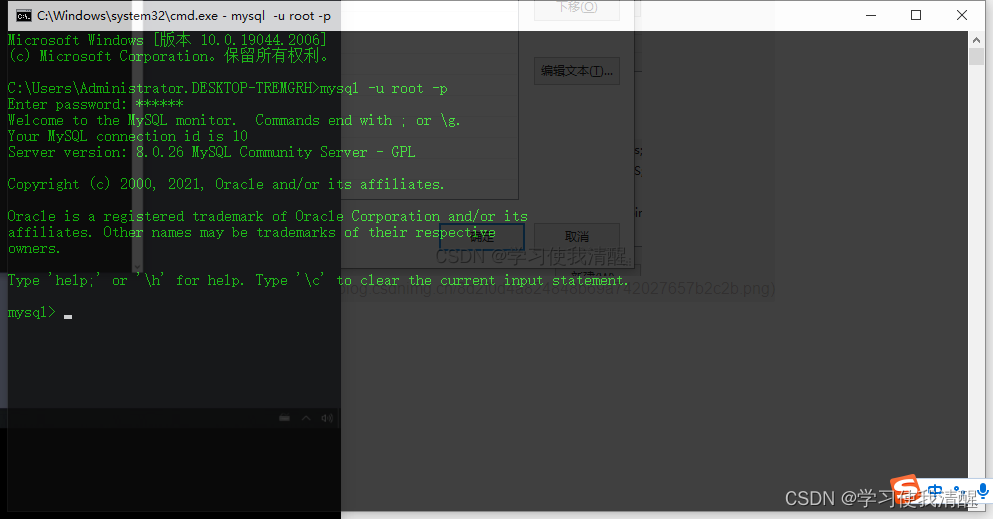
��ʽ��
- ������ͼ�λ�����,��Navicat
MYSQL����ģ��
- ͨ��DBMS�������ݿ�
MYSQL ͼ�λ�����
- sqlyog��navicat ��datagrip (�����й�����ǿ��)
- ͨ��ͼ�λ���������,Ҳ�����б�дsql�������ݿ����
- �������ݿ�,�Ҽ����ݿ����½�
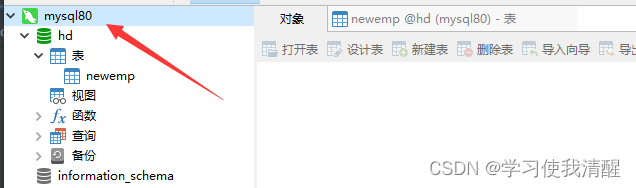
 - ������

 - �������
 - �Ҽ� ��Ʊ�����
 - ���������н���,�Ҽ����������н���
SQL
SQLͨ���
- SQL�����Ե��л������д,�ԷֺŽ�β
- SQL������ʹ�ÿո������(�ո�������ĸ���û������)����ǿ���Ŀɶ���
- Mysql���ݵ�SQL��䲿�ִ�Сд,�ؼ��ֽ���ʹ�ô�д
- ע��
- ����ע��:���C��ֻ�����ݻ��ߡ�#��(MYSQL����)
- ����ע��:��*/����/*��
SQL����
DDL
- ���ݿⶨ������(DATA Definition Language),�����������ݿ����(���ݿ�,��,��,����)
DDL-���ݿ����
��ѯ
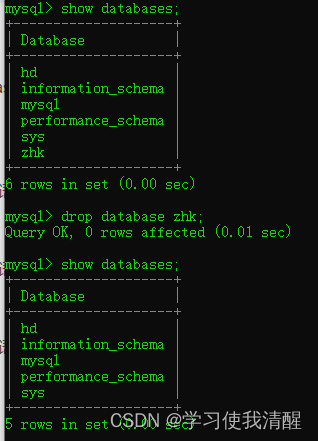
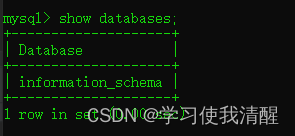
- ��ѯ�������ݿ�:show databases;
 - ��ѯ�ĵ�ǰ���ݿ�:select database();
����
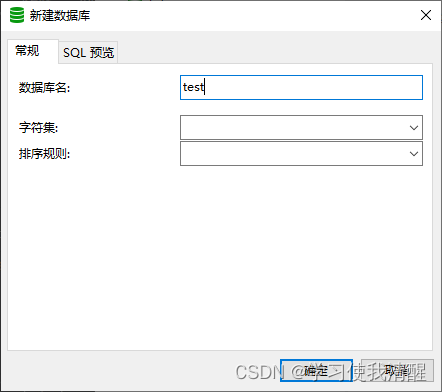
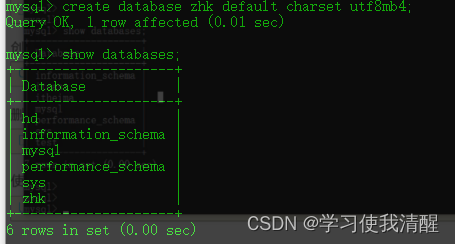
- �������ݿ�:create datatbase [if not exists] ���ݿ��� [default charset �ַ���] [coliate �������];(���������ݿ�ѡ)
 - ������ݿ����,����ʱ������ʾ
 - ������뱨��,���ڲ�����,��������
 - �ַ�������,���Ҫ�����ַ�������������UTF8,�洢����ֻ��3�ֽ�,һЩ�����ַ���Ҫ4���ֽ�
ɾ��
- drop database [if exists] ���ݿ�;
ʹ��
- use ���ݿ�;
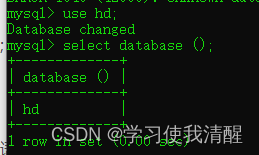 - ���ݿ���л�ֱ����use�л�
DDL- ������
��ѯ
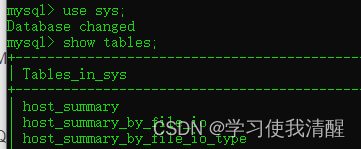
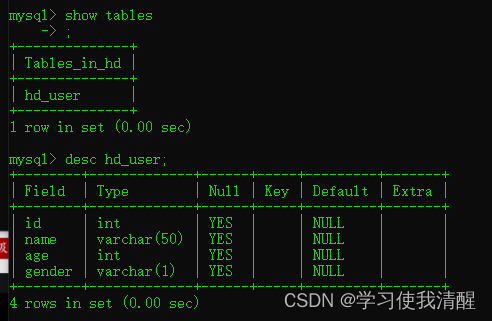
- ��ѯ��ǰ���ݿ����б� show tables;
 - ��ѯ���ṹ desc ����;
 - ��ѯָ�����Ľ������ show create table ����;
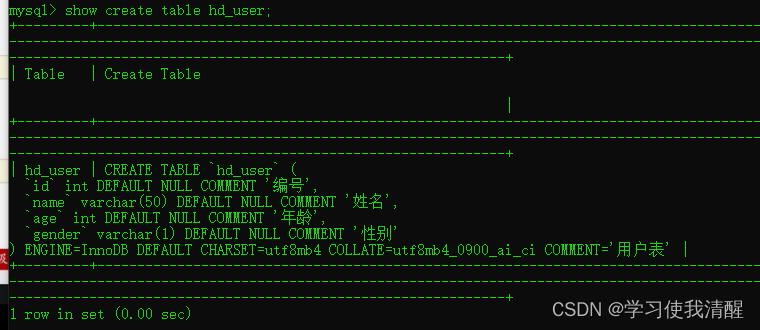
����
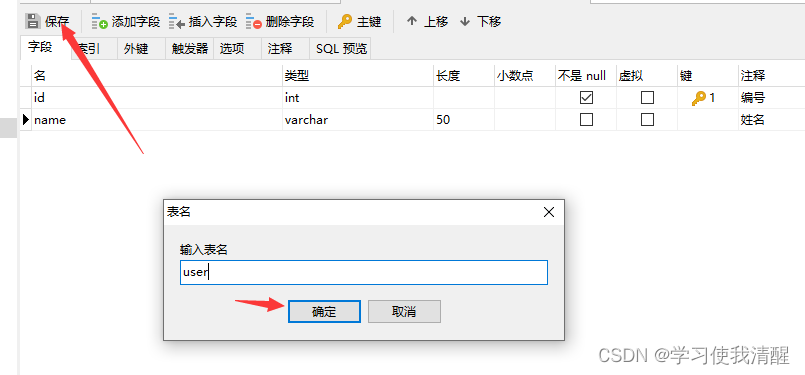
- create table ����(�ֶ�1 �ֶ�1 ���� [COMMENT �ֶ�1ע��] , ����������(���һ���ֶκ���û�ж���)
- )[COMMENT ��ע��];
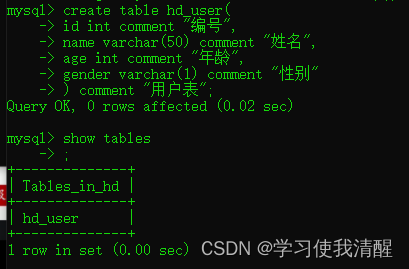
��������
- �������ͺܶ�,��Ҫ������:��ֵ����,�ַ�������,����ʱ������
��ֵ����
| ���� | ��С | �з���(signed)��Χ | ����(UNSIGNED)��Χ | ���� |
|---|
| TINYINT | 1 byte | (-128,127) | (0,255) | С����ֵ | | SMALLINT | 2 bytes | (-32768,32767) | (0,65535) | ������ֵ | | MEDIUINT | 3 bytes | (-8388608,8388607) | (0,16777215) | ������ֵ | | INT��INTEGER | 4 bytes | (0,4294967295) | (0,2^64-1) | ��������ֵ | | BIGINT | 8 bytes | (-2^63,2^63-1) | (0,2^64-1) | ��������ֵ | | FLOAT | 4 bytes | (-3.402823466 E+38,3.402823466351 E+38) | 0��(1.75494351 E-38,3.402823466 E+38) | �����ȸ�����ֵ | | DOUBLE | 8 bytes | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0��(2.2250738585072014 E-308,1.7976931348623157 E+308) | ˫���ȸ�����ֵ | | DECIMAL | - | ������M(����)��D(���)��ֵ | ������M(����)��D(���)��ֵ | С��ֵ(��ȷ������) |
- �з��ż����ָ���
- DECIMAL���Ⱥͱ��:��С��123.45����Ϊ5,λ��Ϊ5;����Ϊ2,С���������λ
- ���������ѡ�����ŵ�TINYINT :age TINYINT UNSIGNED
- ����������ѡ��DOUBLE,���ֳ����4λ,С��Ϊ���1λ:score DOUBLE(4,1)
�ַ�������
| ���� | ��С | ���� |
|---|
| CHAR | 0-255 bytes | �����ַ��� | | VARCHAR | 0-65535 bytes | �䳤�ַ��� | | TINYBLOB | 0-255 bystes | ������255���ַ����Ķ��������� | | TINYTEXT | 0-255 bytes | ���ı��ַ��� | | BLOB | 0-65535 bytes | ��������ʽ�ij��ı����� | | TEXT | 0-65535 bytes | ���ı����� | | MEDIUMBLOB | 0-16777215 bytes | ��������ʽ���еȳ����ı����� | | MEDIUMTEXT | 0-16777215 bytes | �еȳ����ı����� | | LONGBLOB | 0-4294967295 bytes | ��������ʽ�ļ����ı����� | | LONGTEXT | 0-4294967295 bytes | �����ı����� |
- ��BLOB���������������ݵ�,����Ƶ��Ƶ,������װ����,��Ϊ�������ݿ��в�������������ܲ���,���������ר�ŵ��ļ�����������
- char�ַ�:�������char(10),10�����洢10���ַ�,������ֻ��1���ַ�,Ҳ��ռ��,����9λ�ÿո�λ
- vachar�ַ�:����VMware�ľ����ñ�,varchar(10),�洢���ٸ��ַ�ռ���ٿռ䡣
- char�������varchar��˵���ܻ����,��Ϊvarchar����һ���������ݼ���ռ䡣
����ʱ������
| ���� | ��С | ��Χ | ��ʽ | ���� |
|---|
| DATE | 3 | 1000-01-01 �� 9999-12-31 | YYYY-MM-DD | ����ֵ | | TIME | 3 | -838:59:59 �� 838:59:59 | HH:MM:SS | ʱ��ֵ�����ʱ�� | | YEAR | 1 | 1901 �� 2155 | YYYY | ���ֵ | | DATETIME | 8 | 1000-01-01 00:00:00 �� 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | ������ں�ʱ��ֵ | | TIMESTAMP | 4 | 1970-01-01 00:00:01 �� 2038-01-19 01:14:07 | YYYY-MM-DD HH:MMlSS | ������ں�ʱ��ֵ,ʱ��� |
����
- ����������(��ƺ������������͡�����)
- ���һ��Ա����Ϣ��:
- 1 ���(������)
- 2 Ա������(�ַ�������,���Ȳ���10λ)
- 3 Ա������(�ַ�������,���Ȳ���10λ)
- 4 �Ա� (�л�Ů,���洢һ������)
- 5 ����
- 6 ����֤��(18λ2������֤)
- 7 ��ְʱ��(������)
- �����������

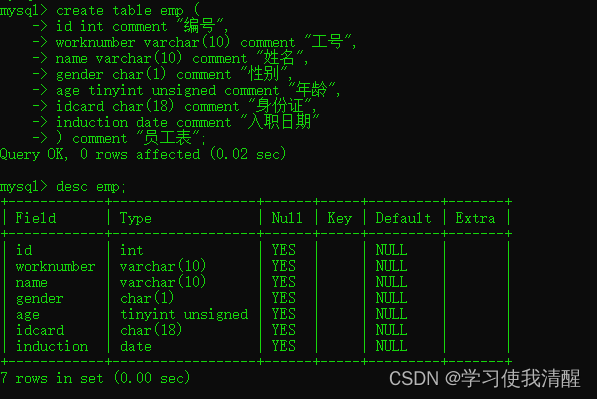
��
- �����ֶ�:ALTER TABLE ���� ADD �ֶ��� ����(����)[COMMENT ע��] [Լ��];
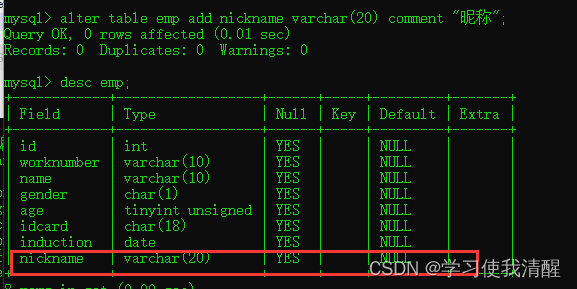 - ���ֶ������ֶ�����:ALTER TABLE ���� CHANGE ���ֶ��� ���ֶ��� ����(����)[COMMENT ע��] [Լ��];
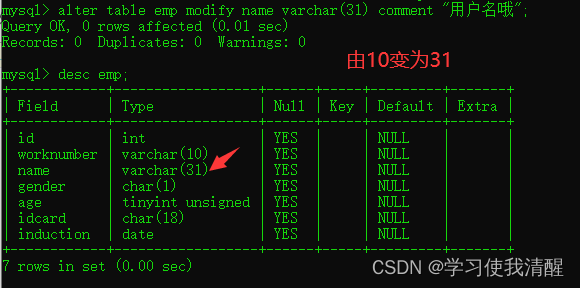
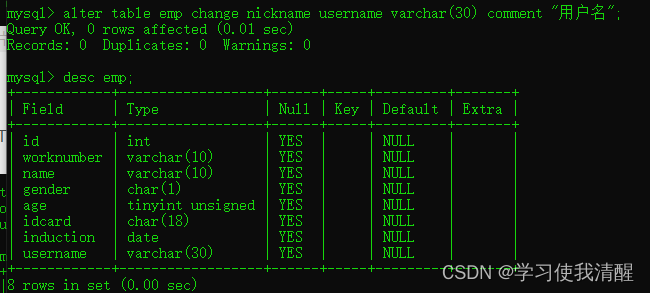 - ����������:ALTER TABLE ���� MODIFY �ֶ��� ����������(����);
 - �ı���:ALTER TABLE ���� RENAME TO �±���;

ɾ��
- ɾ���ֶ�:ALTER TABLE ���� DROP �ֶ���;
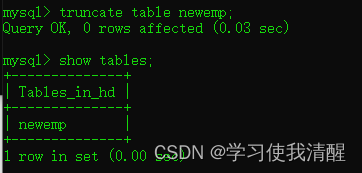
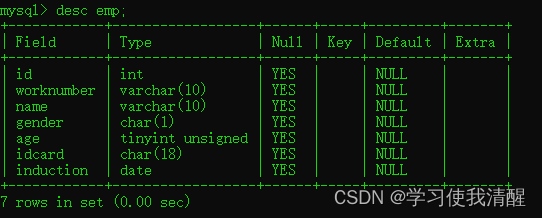 - ɾ����:DROP TABLE [IF EXITS] ����;
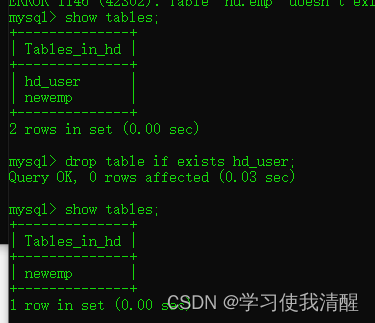 - ɾ��ָ����,�����´����ñ�(ֻ�б��ṹ,û������):TRUNCATE TABLE ����;
DML
- ���ݿ������������(DATA Manipulation Language),���������ݿ��б������ݼ�¼��������ɾ����
�������� insert
- ��ָ���ֶ���������:INSERT INTO ����(�ֶ���1,�ֶ���2,��)VALUES(ֵ1,ֵ2��);
- sql������Ӳ�ѯ
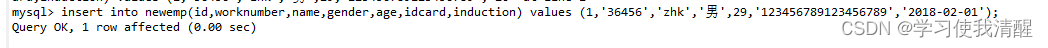
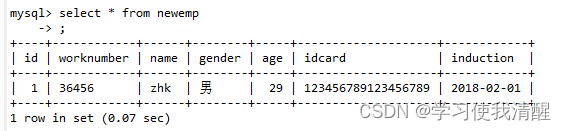 - ������ʾ
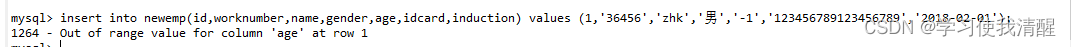 - ͼ�λ����߲�ѯ
 - ��ȫ���ֶ���������:INSERT INTO ���� VALUES(ֵ1(��Ӧ���еĵ�һ���ֶ�),ֵ2��);
  - ������������:INSERT INTO ����(�ֶ���1,�ֶ���2,��)VALUES(ֵ1,ֵ2),(ֵ1,ֵ2��)(ֵ1,ֵ2)��;
INSERT INTO ���� VALUES(ֵ1(��Ӧ���еĵ�һ���ֶ�),ֵ2��),ֵ1(��Ӧ���еĵ�һ���ֶ�),ֵ2��)��;
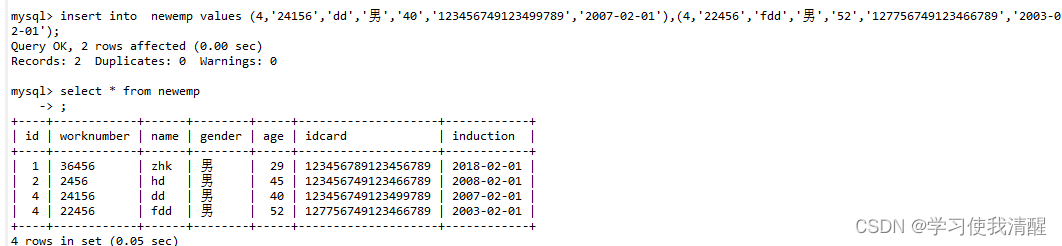 - ע��:��������ʱ,ָ�����ֶ�˳����Ҫ��ֵ��˳����һһ��Ӧ��;�ַ�������������Ӧ�ð�����������;��������ݴ�С,Ӧ�����ֶεĹ涨��Χ��
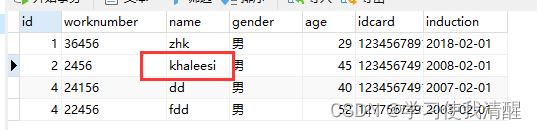
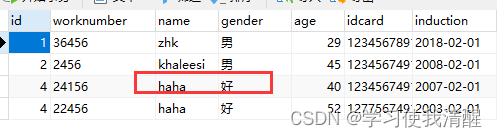
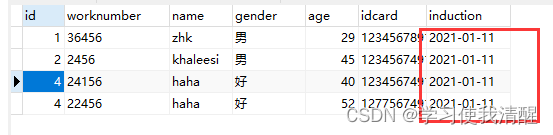
�� update
- update ���� SET �ֶ���=ֵ1,�ֶ���=ֵ2,��[where ����];
- ע��:����������������,Ҳ����û��,���û������,��������ű����������ݡ�
- �ĵ���ֵ

 - �Ķ��ֵ

 - �����ű�

ɾ�� delete
- delete from ���� [where ����];
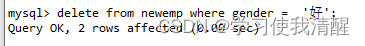
 - ɾ������
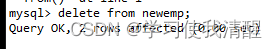

- delete��������������,Ҳ����û��,���û������,���ɾ�����ű������ݡ�
- delete��䲻��ɾ��ijһ���ֶε�ֵ(����ʹ��update)
DQL
- ���ݿ��ѯ����(DATA Query Language),������ѯ���ݿ��б��ļ�¼
��ṹ
- select ����
- from �����б�
- where �����б�
- group by �����ֶ��б�
- having ����������б�
- order by �����ֶ��б�
- limit ��ҳ����
������ѯ
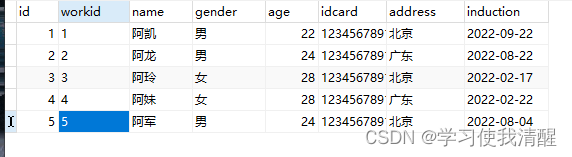
��ѯ����ֶ�
- select �ֶ�1,�ֶ�2��from ����;
 - select * from ����(Ҳ�ɰ������ֶζ����г�);
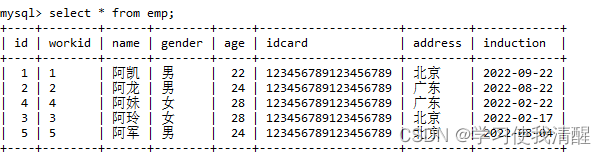
����
- select �ֶ�1 [as ����1], �ֶ�2 [as ����2] �� from ����;
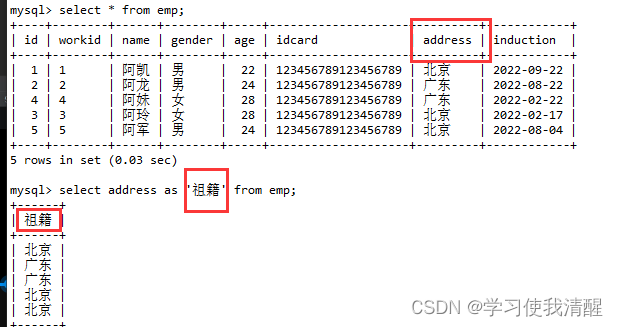
ȥ���ظ���¼
select distinct �ֶ��б� from ����;
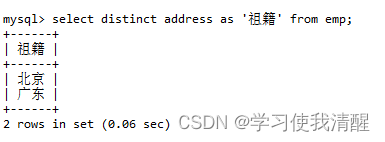
������ѯ(where)
�
- select �ֶ��б� from ���� where �����б�;
����
| �Ƚ������ | ���� |
|---|
| > | ���� | | >= | ���ڵ��� | | < | С�� | | <= | С�ڵ��� | | = | ���� | | <>��!= | ������ | | between��and�� | ��ij����Χ֮��(����Сֵ,���ֵ) | | in(��) | ��in֮����б��е�ֵ,��ѡһ | | like ռλ�� | ģ��ƥ��,_(�»���)ƥ�䵥���ַ�,%ƥ��������ַ� | | is null | ��null |
| ������� | ���� |
|---|
| and ��&& | ����(�������ͬʱ����) | | or��|| | ����(�����������1������) | | not ��! | ��,���� |
ʾ��
- ��ѯ����Ϊ22���
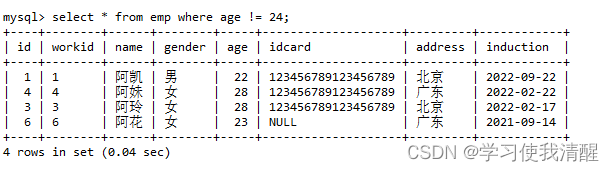
 - ��ѯ����С�ڵ���24��
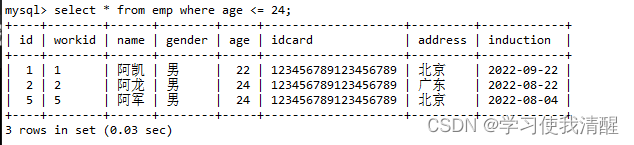 - ��ѯû��id�����,����������û��idcard�İ�������
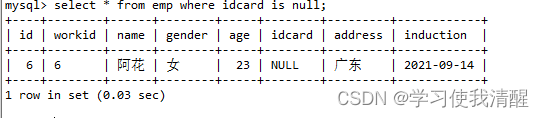 - ��ѯ��idcard
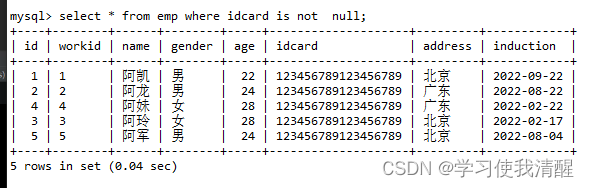 - ��ѯ���䲻����24���
 - ��ѯ������20-23֮���,����20��23
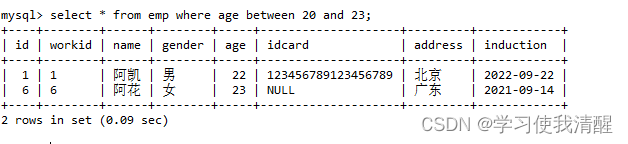
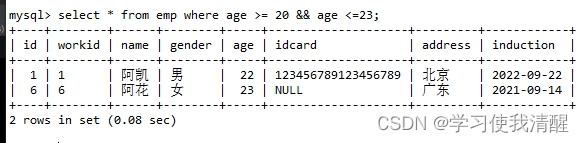 - between and�÷�
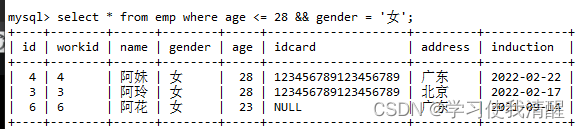
 - �Ա�ΪŮ,������С��28���
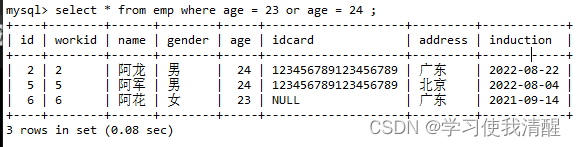
 - or�÷�
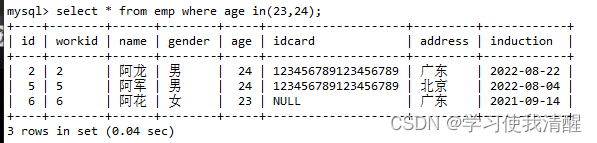
 - in �÷�
 - ���������ֵ��û���ϢСС��,��ѯ����Ϊ3���ֵ�Ա��
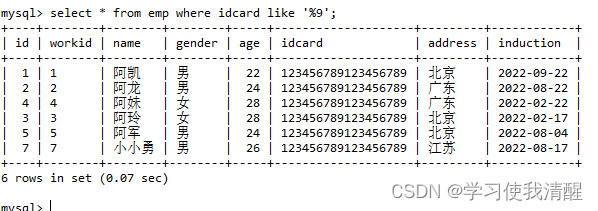
 - ��ѯidcard���һλ��9��
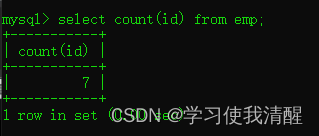
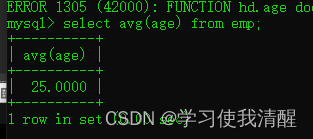
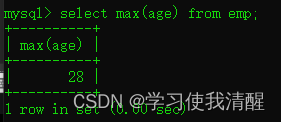
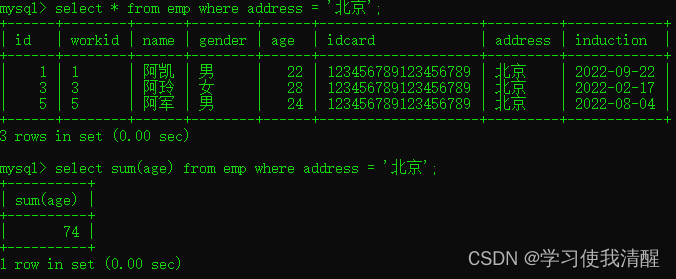
�ۺϺ���(count��max��min��avg��sum)
����
- ��һ��������Ϊһ������,����������㡣
�����ۺϺ���
| ���� | ���� |
|---|
| count | ͳ������ | | max | ���ֵ | | min | ��Сֵ | | avg | ƽ��ֵ | | sum | ��� |
�
- select �ۺϺ���(�ֶ��б�) from ����;
- ע�� ����nullֵ���������оۺϺ������㡣
ʾ��
- ��Ա������
 - ͳ��ƽ������
 - ��ȡ������С����
 - ͳ�Ʊ�������������֮��
�����ѯ(group by)
�
- select �ֶ� from ���� [where ����] group by �����ֶ� [having ������������];
where��having����
- ִ��ʱ����ͨ:where�Ƿ���֮ǰ���й���,������where����,���������;��having�Ƿ���֮��Խ�����й��ˡ�
- �ж�������ͬ:where���ܶԾۺϺ��������ж�,��having���ԡ�.
- ִ��˳��:where>�ۺϺ���>having
- ����֮��,��ѯ���ֶ�һ��Ϊ�ۺϺ����ͷ����ֶ�,��ѯ�������ֶ����κ�������
ʾ��
- �����Ա����,ͳ�����Ժ�Ů�Ե�����
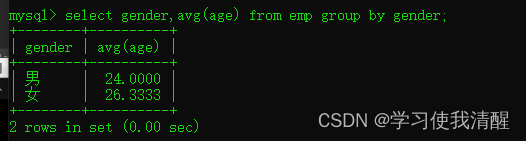
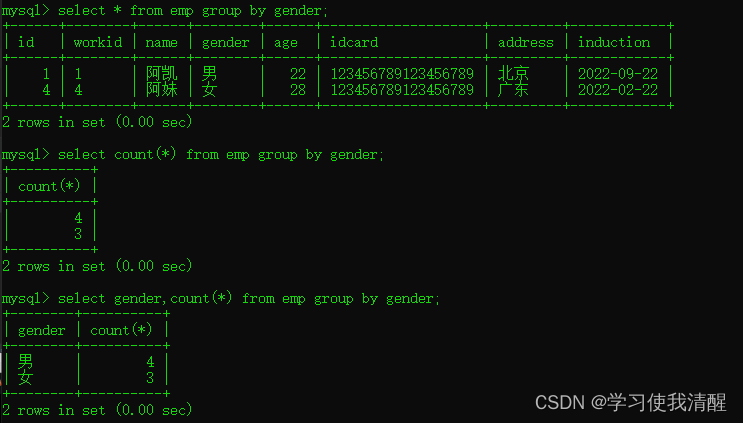 - �����Ա����,ͳ����Ů��ƽ������
 - ��ѯ����С��25��Ա��,�����ݹ�����ַ����,��ȡԱ����������2���ĵ�ַ��

�����ѯ(order by)
�
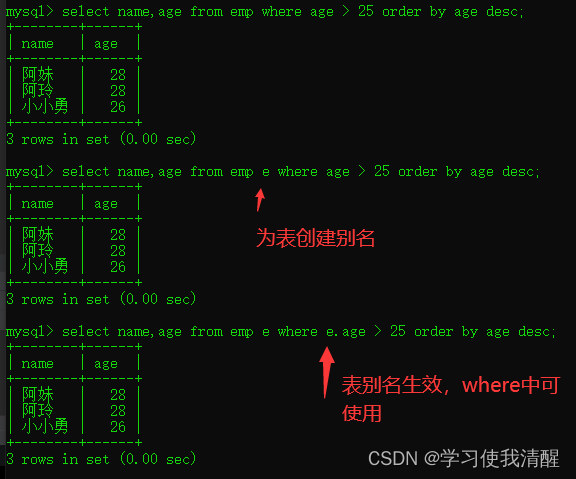
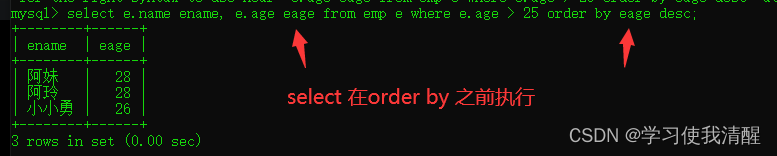
- select from ���� order by �ֶ�1 ����ʽ,�ֶ�2 ����ʽ 2;
����ʽ
- ASC:����(Ĭ��ֵ)
- DESC:����
- �������ֶ�����,����һ���ֶ�ֵ��ͬʱ,�Ż���ݵڶ����ֶν�������
ʾ��
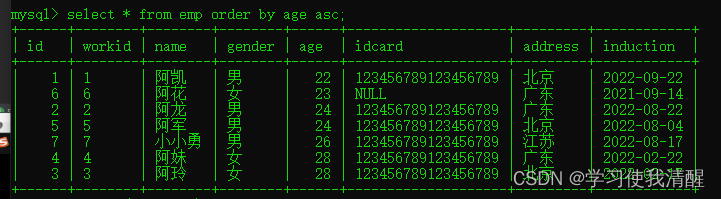
- �������������������,asc��ʡ�ԡ�
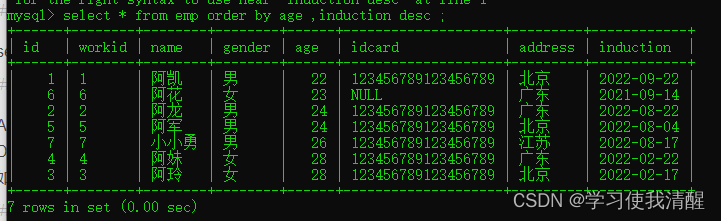
 - �������������������,��������ͬ��,������ְʱ����н�������
��ҳ��ѯ(limit)
�
- select �ֶ� from ���� limit ��ʼ����,��ѯ��¼��;
- ע��:��ʼ�����Ǵ�0��ʼ,��ʼ����=(��ѯҳ��-1)����ÿҳ��ʾ��¼��;��ҳ��ѯʱ���ݵķ���,��ͬ���ݿ������ϲ�ͬ��ʵ��,mysql����limit;�����ѯ���ǵ�һҳ����,��ʼ��������ʡ��,ֱ�Ӽ�дΪlimit ��ѯ��¼��
ʾ��
- ��ѯ��һҳ��Ա������,ÿҳչʾ3��
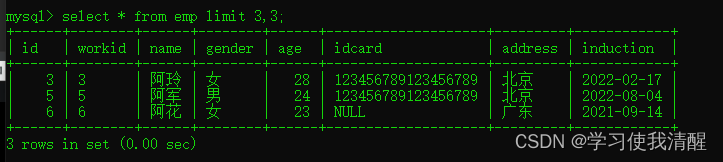
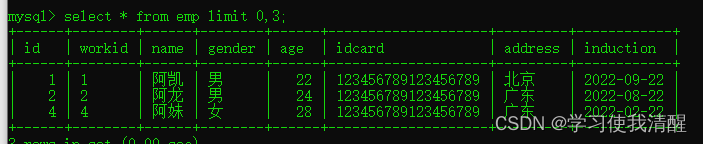 - ��ѯ�ڶ�ҳԱ������,ÿҳչʾ3��
DQL�ܽ�ʾ��
- ��ѯ�Ա�Ϊ��,������24���ϵIJ��������������ֵ�Ա��
 - ��ѯ����С��25,���Ժ�Ů�Ե�����
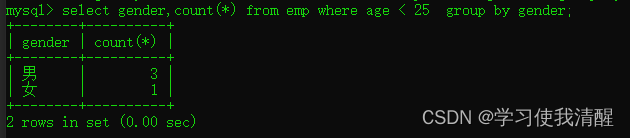 - ��ѯ��������С��26��Ա��������������,���Բ�ѯ�����������������,���������ͬ,����ְʱ�併������
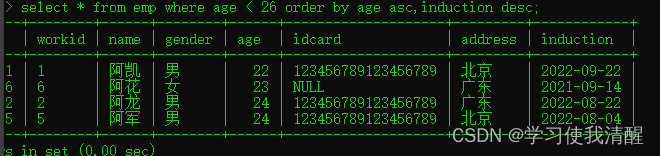 - ��ѯ�Ա�Ϊ��,��������24���ϵ�2��Ա����Ϣ�Բ�ѯ�Ľ������������,������ͬ�İ���ְʱ����������
 - ע��limit�������
DQL���Ա�д��ִ��˳��
��д˳��
- select �ֶ� from �� where �����б� group by �����ֶ� having ����������б� order by �����ֶ��б� limit ��ҳ����
ִ��˳��

DQL����ܽ�
- select �ֶ� [as] ����(as��ʡ��)
ִ��˳�� ��֤


DCL
- ���ݿ��������(DATA Control Language),�����������ݿ��û�,�������ݿ�ķ���Ȩ��
�����û�
- ����������ʹ��%��ʾͨ��
- ����sql������Ա��������,��Ҫ��DBAʹ��
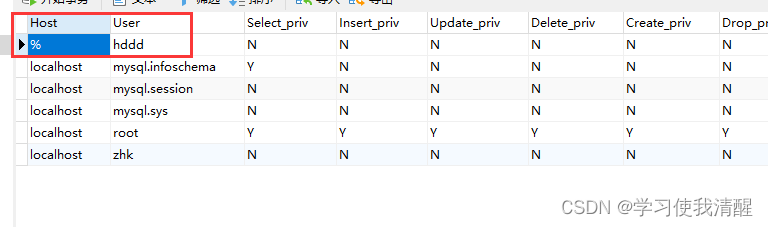
��ѯ�û�
- mysql�����е��û���Ϣ���û�Ȩ����Ϣ�������mysql���ݿ��е�user��

�����û�
- create user ���û�����@���������� identified by �����롯;ֻ���ڱ�����¼

 - ʹ�ô������û���¼,����δ����Ȩ��

 - �����û��������κ������ϵ�¼

���û�����
- alter user ���û�����@���������� identified with mysql_native_password by �������롯;
 - �ٴε�¼����,�����ijɹ�
ɾ���û�
- drop user ���û�����@����������;

Ȩ����
- ���Ȩ��֮��,ʹ�ö��ŷָ�;��Ȩʱ,���ݿ����ͱ�������ʹ��*����ͨ��,�������С�
- mysql�ж����˶���Ȩ��,��������
| Ȩ�� | ˵�� |
|---|
| all,all,privileges | ����Ȩ�� | | select | ��ѯ���� | | insert | �������� | | update | ������ | | delete | ɾ������ | | alter | �ı� | | drop | ɾ�����ݿ�/��ͼ | | create | �������ݿ�/�� |
��ѯȨ��
- show grants for ���û�����@����������;
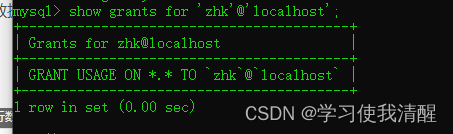 - usage��ʾû���κ�Ȩ��,�����ܵ�¼mysql
����Ȩ��
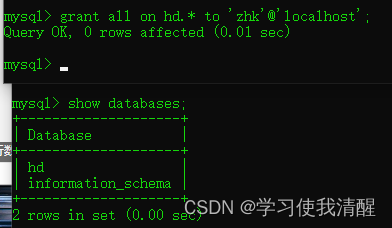
- grant Ȩ���б� on ���ݿ���.���� to ���û�����@����������;
����Ȩ��
- revoke Ȩ���б� on ���ݿ���.���� from ���û�����@����������;
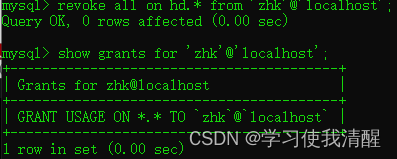 - �ٴβ鿴
|