一、MapReduce的定义
MapReduce 是一个分布式计算框架,用于编写分布式应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多TB数据集)。
MapReduce 是一种面向海量数据处理的一种指导思想,也是一种用于对大规模数据进行分布式计算的编程模型。
二、MapReduce的优点
-
易于编程
Mapreduce 框架提供了用于二次开发的接口;简单地实现一些接口,就可以完成一个分布式程序。任务计算交给计算框架去处理,将分布式程序部署到hadoop集群上运行,集群节点可以扩展到成百上千个。 -
良好的扩展性
当计算资源不能得到满足的时候,可以通过简单的增加机器来扩展它的计算能力。 -
高容错性
Hadoop集群是分布式搭建和部署的,任何单一机器节点宕机了,它可以把上面的计算任务转移到另一个节点上运行,不影响整个作业任务的完成,过程完全是由Hadoop内部完成的。 -
适合海量数据的离线处理( PB 级以上)
可以实现上千台服务器集群并发工作,提供数据处理能力。
三、MapReduce的局限性
-
实时计算性能差
MapReduce主要应用于离线作业,无法作到秒级或者是亚秒级的数据响应。 -
不能进行流式计算(流式计算特点是数据是源源不断得计算,并且数据是动态的)
MapReduce作为一个离线计算框架,主要是针对静态数据集得,数据是不能动态变化的。
四、MapReduce核心思想
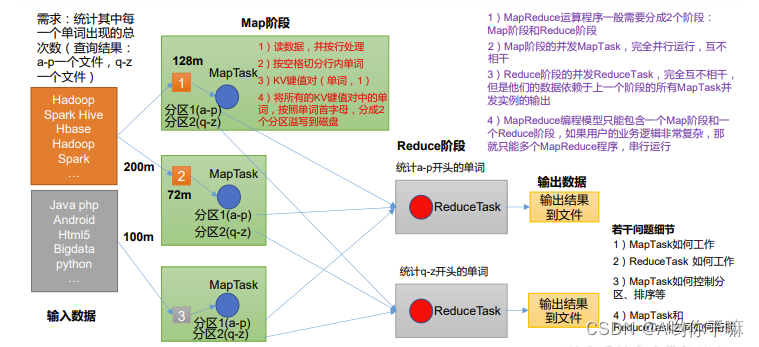
五、MapReduce进程
一个完整的MapReduce程序在分布式运行时有三类:
-
MRAppMaster:负责整个MR程序的过程调度及状态协调。
-
MapTask:负责map阶段的整个数据处理流程。
-
ReduceTask:负责reduce阶段的整个数据处理流程。