一条简单的SQL查询语句,执行流程:
查询缓存-词法分析-语法分析-语法书-预处理器-优化器-执行计划-执行器-调用API-引擎-数据
执行器-返回数据-返回缓存
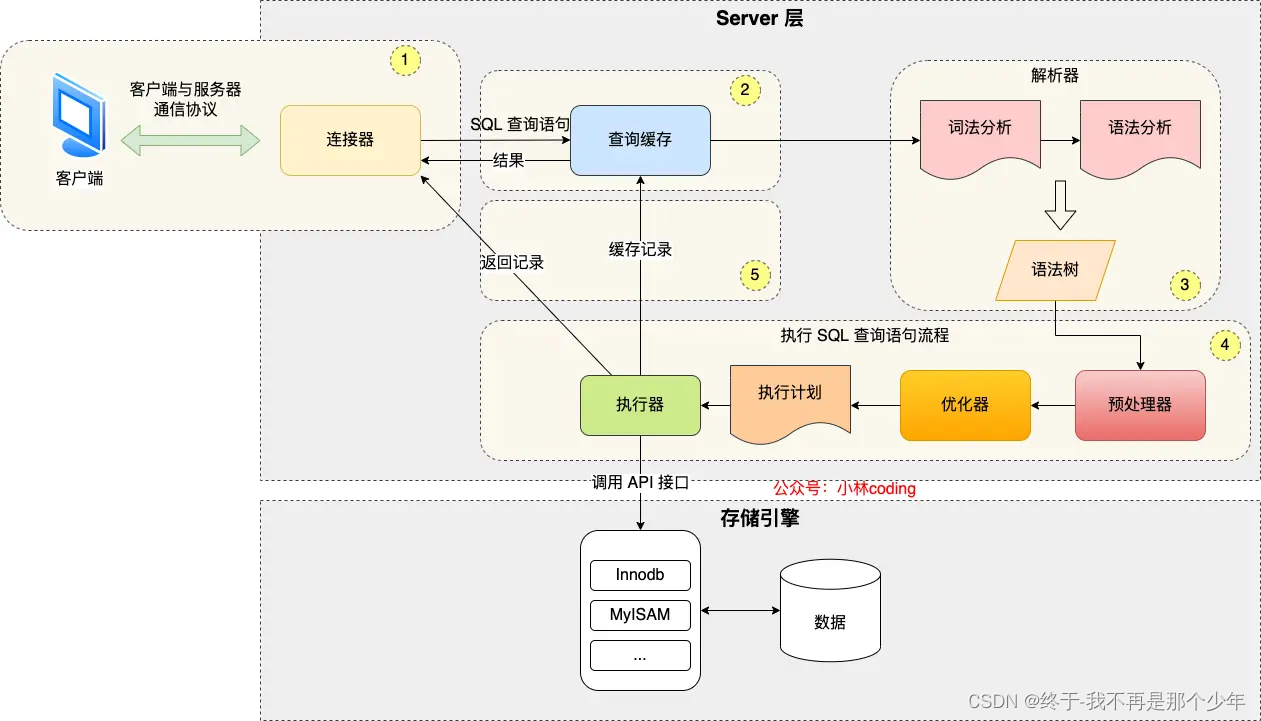
概述
undo log:回滚日志,原子性,实现事务回滚和MVCC,引擎层实现
redo log:重做日志,崩溃恢复,持久性 ,引擎层实现
bin log:主从复制,数据备份,Server层实现
undo log作用?
undo log:在事务还没有提交之前,记录更新修改前的数据,插入一个新的记录保存新纪录的索引,需要回滚时
找到索引并删掉记录,更新和删除需要保存完整记录,用于恢复。记录的是逻辑日志,delete操作时会有insert记录,
update时反向的update记录。
每产生一个undo log日志都会有一个trx_id和roll_point生成:
trx_id:保存生成此日志的事务id;
roll_point:将undo log连接起来形成版本连;
undo log+ReadView 实现MVCC(多版本并发控制):根据ReadView里面存储的trx_id 和undo log版本链记录中的trx_id进行对比。
读提交隔离级别:每次select操作都生成一个ReadView,保证每次查询到的数据都是已经提交的
可重复读隔离界别:只有第一次select生成一个ReadView,后续每次查询都依据那个ReadView进行查找。
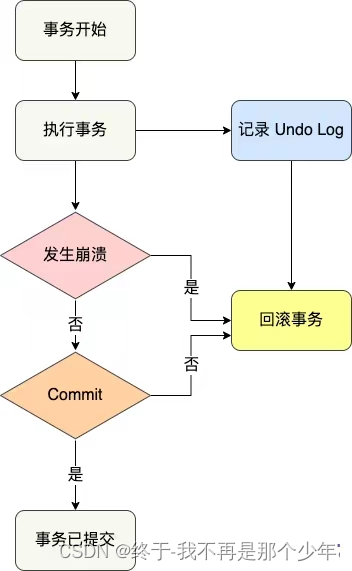
redo log作用?
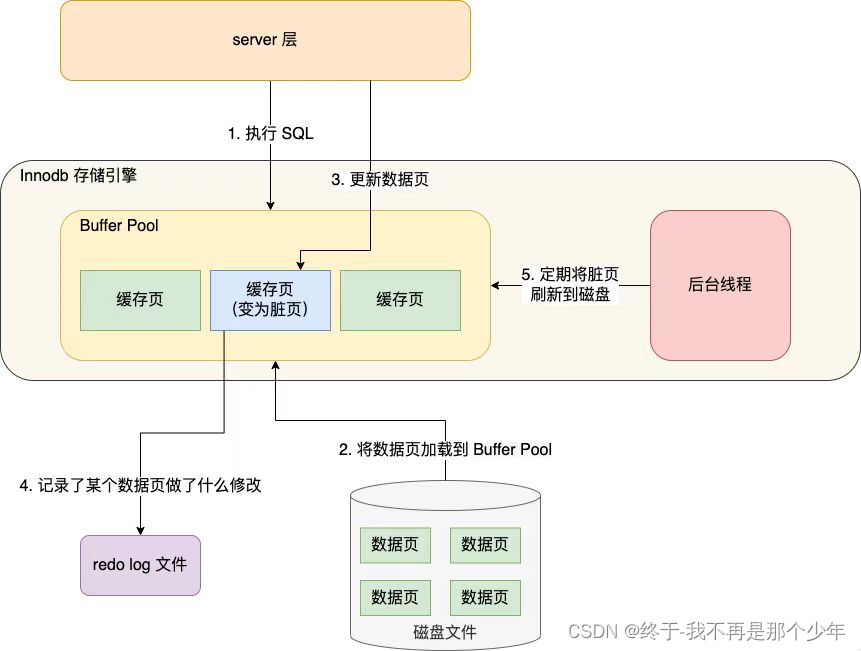
redo log:Buffer pool提高了读写性能,但是数据放在内存中是不可靠的,当程序崩溃或者系统断电时会造成缓冲区中脏页
数据没来及持久化到磁盘,因此InnoDB引擎在一条记录需要更新时,现将内容保存在redo log中,后台线程择机将记录持久化
到磁盘中。WAL(Write-Ahead-Logging),即MySQL写操作并不马上更新磁盘,而是先记录在日志中,在适当时候在写到磁盘中。
redo log是物理日志,记录对XXX表空间YYY页的ZZZ偏移位置做了NNN更新。当事务提交时,先将更新记录在redo Log文件中并将其持久化
到磁盘即可,当发生崩溃,虽然缓存中脏页没有更新到磁盘,但是可以根据redo log文件进行恢复。
undo log 和 redo log的区别:
undo log记录事务提交前的状态,更新前的值,用于事务回滚;
redo log记录事务提交后的状态,更新后的值,用于数据恢复,持久化
事务提交前发生崩溃使用undo log来恢复,提交后崩溃使用redo log 恢复;
为什么将数据写入redo log文件比较快?
redo log文件记录时顺序写,而更新数据库磁盘是随机写,随机写速率远远低于顺写。
redo log直接写入磁盘嘛?
NO,redo log也有自己的缓冲区。所以redo log什么时候刷盘写入到磁盘的时机很重要。
主要有以下几个时机:
MySQL服务器正常关闭;
记录空间超过redo log缓冲区大小一半;
InnoDB后台线程1秒钟刷新一次;
每次事务提交根据配置的参数情况进行写入;
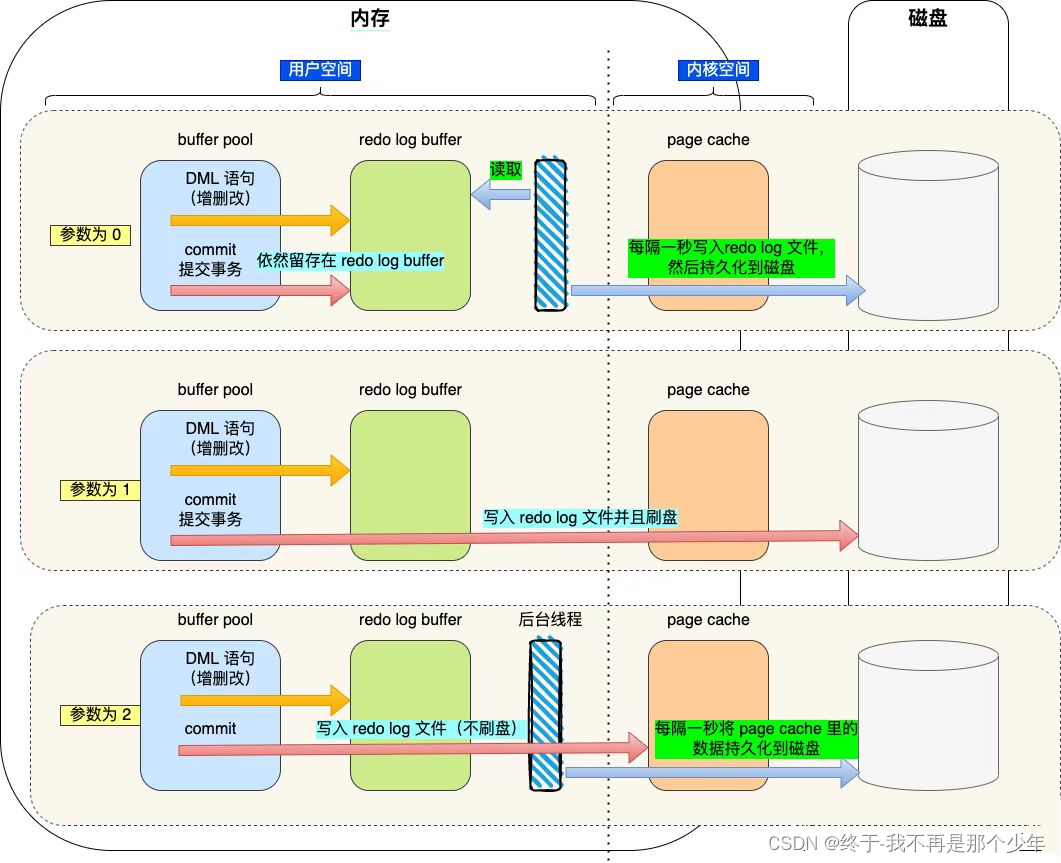
参数InnoDB_flush_log_at_trx_commit可以设置为0、1、2
参数为0:提交事务redo log只停留在redo log Buffer中,不会主动触发写入磁盘操作;
参数为1:提交事务时将redo log buffer中的redo log写入到磁盘,保证MySQL异常重启后不会丢失数据;
参数为2:将redo log buffer中的redo log写入到redo log文件中(并不是持久化到磁盘,因为操作系统也有page Cache),
意味写入操作系统的缓存。
所以当参数为0或者2时神魔时候写入到磁盘呢?
0:引擎后台线程隔1S调用waite()将redo log buffer中内容写入到Page Cache中,再调用fsync()将Page Cache中内容持久化到磁盘,
所以会导致1S钟数据丢失;
2:引擎后台线程隔1S调用fsync()将Page Cache内容持久化到磁盘,只有在操作系统崩溃情况下会导致1S钟数据丢失,MySQL异常退出不会有影响;
redo log文件满了怎么办?
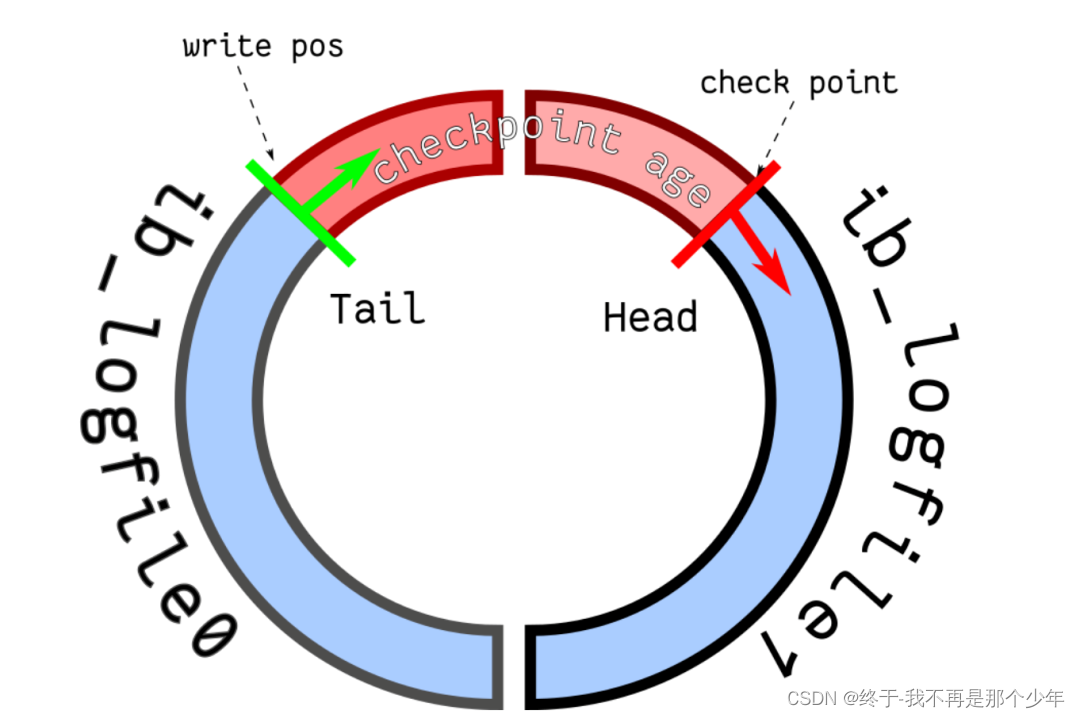
InnoDB引擎中有重做日志文件组,有两个redo log文件组成(ib_logfile0、ib_logfile1),以循环方式写入两个文件,
write pos记录写的位置,check point记录要擦数的位置,都是顺时针移动。
当write pos追到check point时,导致没有空间进行记录,需要将redo log文件持久化到磁盘,所以MySQL服务器会阻塞,等待重做日志文件组腾出空间。因此在并发操作中,redo log文件大小的配置和参数InnoDB_flush_log_at_trx_commit的配置非常重要,不然会影响系统性能。
为什么需要binlog?
MySQL的Server层在更新一条记录后待事务提交时候,会将该事物执行过程中产生变更操作(show和select操作不会记录)的binlog统一写入binlog文件中。
最开始 MySQL 里并没有 InnoDB 引擎,MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。
而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用 redo log 来实现 crash-safe 能力。
binlog和redo log的区别?
- binlog是Server层实现的日志,所有引擎都可以使用; redo log是InnoDB引擎实现的日志;
- 两者文件格式不同:
binlog有三种格式类型:
STATEMENT(默认格式):每条修改数据的SQL都会记录到binlog中(逻辑操作),主从复制的slave端再根据SQL重现。但是关于动态函数的操作(now)会导致主从库结果不一致;
ROW:记录数据最终被修改为神魔样子,不会出现动态函数的问题。但是每行数据的变化都会被记录,导致binlog文件过大,而STATEMENT格式只会记录一条语句。
MIXED:上面两种的结合,看情况使用STATEMENT或者ROW模式。
- 写入方式不同:
redo log是循环写,会覆盖。
binlog追加写,满了就创建新的
- 用途不一样:
redo log用于掉电故障恢复
binlog主从复制、备份操作
主从复制是如何实现的?
异步、二进制形式(binlog)
基本分为三个阶段:
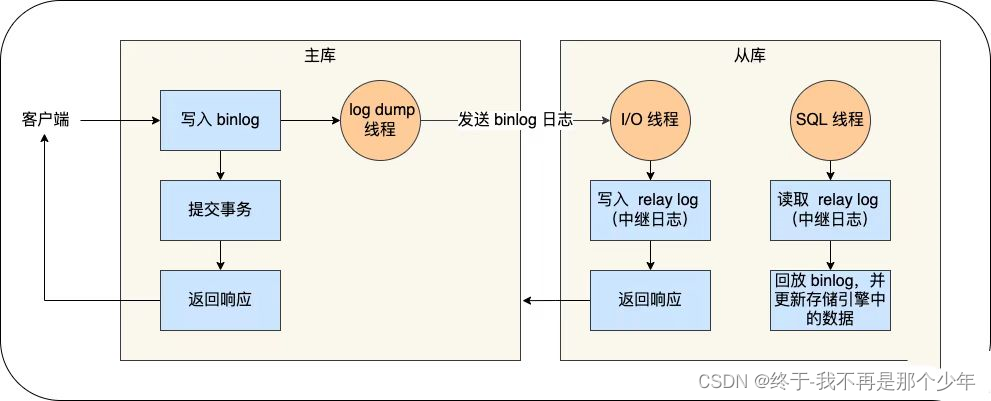
- 写入binlog:主库写binlog文件,提交事务,更新本地存储数据
- 同步binlog:binlog复制到从库上,从库把binlog暂存到中继日志中
- 回放binlog:从库SQL线程读取中继日志更新存储引擎中的数据
主从复制模型:
- 同步复制:主库提交事务等待所有从库复制完成
- 异步复制:主库提交事务不等待从库
- 版同步复制:只要有一个从库复制完成就可
binlog何时刷盘?
事务提交后会把binlog cache中的完整事务写入到binlog文件中,并清空binlog cache。
但是并没有持久化到磁盘中,还在文件系统的page cache中,如上提write速度较快因为不涉及磁盘I/O。只有执行fsync才会持久化到磁盘中(此过程速度较慢)
MySQL中参数sync_binlog可设置刷入到磁盘的频率:
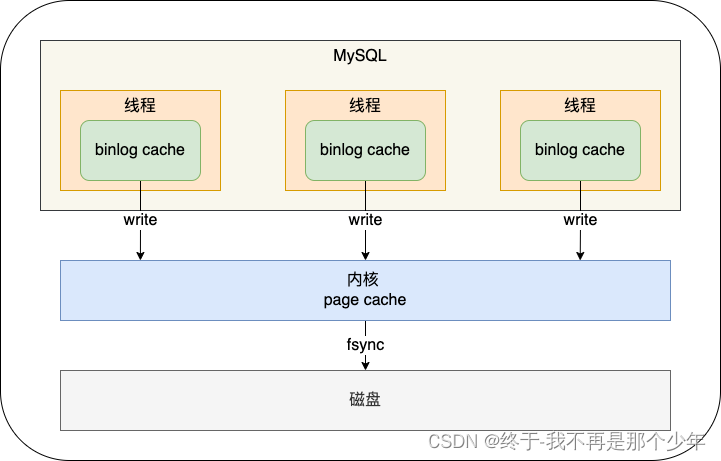
- sync_binlog = 0提交事务只write,不会fsync,后续操作交给操作系统;
- sync_binlog = 1:每次write都会fsync;
- sync_binlog = N:提交事务都write,积累N个失误才会fsync;
事务提交的两个阶段
事务提交后redo log和binlog都需要持久化到磁盘,这两个是独立的逻辑,可能会出现一个成功一个失败的情况:
- redo log刷盘成功,MySQL宕机机,binlog还没有写入磁盘,重启后会导致主库可以恢复,从库无法恢复,主从不一致;
- binlog成功,redo log失败,从库执行了相关的操作,但是主库重启后无法恢复,导致主从不一致;
所以为了保持主从库的一致性,必须保证两个日志逻辑上是一致的,提出了两阶段提交,分别是准备(Prepare)和提交(Commit):
MySQL会同时维护binlog日志与InnoDB的redo log,为保证两者的一致性,MySQL使用了内部事务XA,XA事务由binlog作为协调者,存储引擎是参与者。
两阶段的提交流程如下:
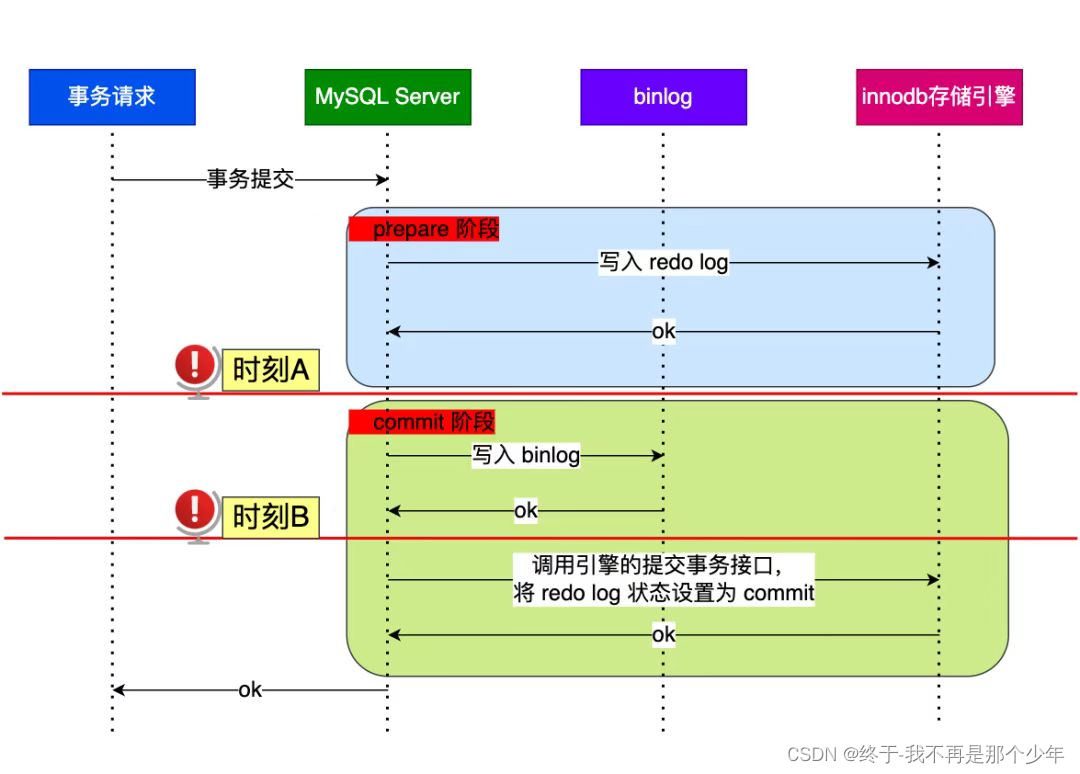
- Prepare:将内部事务的ID(XID),写入到redo log,并将redo log对应的事务状态设置为prepare,然后将redo log刷新到硬盘;
- Commit:把XID写入到binlog,将binlog刷入硬盘,调用引擎的提交事务接口,将redo log状态设置为commit;
遇到MySQL宕机后,会按照顺序扫扫描redo log,碰到处于Prepare状态的redo log,用XID,查看binlog中是否存在此XID:如果存在说明binlog也完成了写入磁盘,则提交事务,如果不存在,说明binlog还没有写入到磁盘,则回滚事务,从而保证了主从一致。
事务没有提交,redo log也会被写入磁盘吗?
会的,事务执行过程中redo log也是写入在redo log buffer中,后台线程将redo logbuffer中的数据一秒钟持久化一次。
两阶段提交的问题?
- I/O次数高,每次事务的提交都会进行两次fsync(刷盘)。
- 多个事务时无法保证两者的顺序是一致性,还需要加锁,性能不佳。
所以引出了组提交
当有所个失误提交时,会将多个binlog 的刷盘合并成一个,减少磁盘I/O的次数,将commit分为三个阶段:
- flush阶段:多个事务按进入顺序将binlog从cache写入文件(不刷盘);
- sync阶段:对binlog文件做fsync操作(多个事务的binlog合并刷盘);
- commit阶段:各个事务按顺序做InnoDB commit操作;
上面内个极端都有一个队列,每个阶段都有锁保护,保证了事务写入的顺序,第一个进入队列的事务会成为leader,全权负责整队的操作。
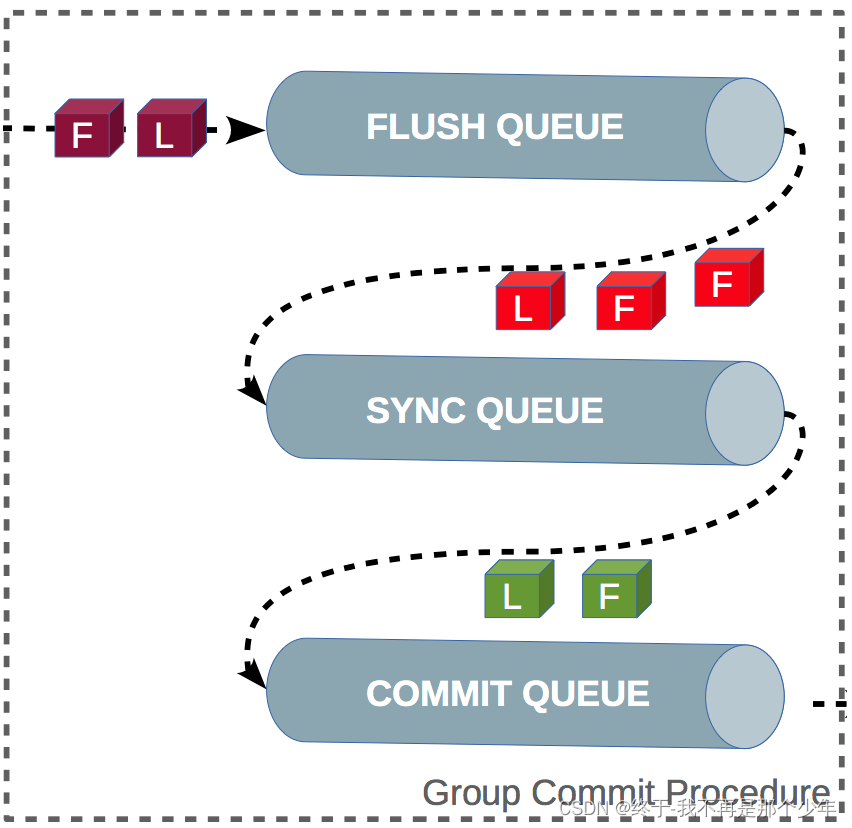
redo log有组提交吗?
在5.7版本中,Prepare阶段不在让各个事务各自执行redo log刷盘操作。将组提交推迟到flush阶段。
MySQL磁盘I/O很高,有什么优化方法?
- 延迟binlog刷盘操作,减少binlog的刷盘次数
- 将sync_binlog设置为大于1 的值,每次提交事务都write,延迟binlog刷盘时机。但是掉电可能会丢掉N个事务的binlog日志;
- redo log文件持久化时只write不去操作fsync。
以上内容和图片参考告别鸽子,从我做起
就是这事,散会。