数据准备
UserPO
@Data
@EqualsAndHashCode(callSuper = true)
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@Document(collection = "user")
public class UserPO extends BasePO {
private String name;
private String description;
}
UserGroupPO
@Data
@EqualsAndHashCode(callSuper = true)
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@Document(collection = "user_group")
public class UserGroupPO extends BasePO {
private String name;
private String description;
private List<Long> userIds;
}
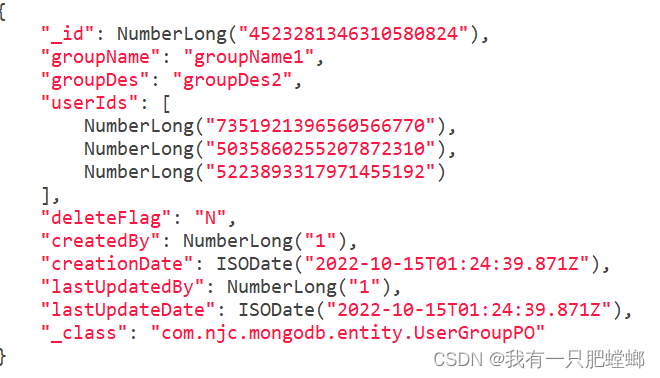
用户数据

用户组数据
?
条件查询
match:and 匹配
查询用户组 id 等于 1,且删除标识等于 N 的数据
db.getCollection("user_group").aggregate([{
"$match": {
"$and": [{
"_id": NumberLong("1")
}, {
"deleteFlag": "N"
}]
}
}]);
match:or 匹配
查询用户 name 等于 nn 或者 description 等于 dd 的数据
db.getCollection("user").aggregate([{
"$match": {
"$or": [{
"name": "nn"
}, {
"description": "dd"
}]
}
}]);
?
聚合查询
查询用户组里的用户详情
拆分数据
unwind:将文档中的某一个数组类型字段拆分成多条
实现:根据 userIds 把用户组拆分了多行
db.getCollection("user_group").aggregate([{
"$match": {
"$and": [{
"_id": NumberLong("2809813774582045833")
}, {
"deleteFlag": "N"
}]
}
}, {
"$unwind": "$userIds"
}]);

关联查询
?
lookup:关联查询,类似于 MySQL 的 left jion 效果
实现:根据 userIds 查询用户详情,注意:查出来的 user 是个数组
- from 同一个数据库下等待被Join的集合。
- localField 源集合中的match值,如果输入的集合中,某文档没有 localField
这个Key(Field),在处理的过程中,会默认为此文档含
有 localField:null的键值对。 - foreignField待Join的集合的match值,如果待Join的集合中,文档没有foreignField
值,在处理的过程中,会默认为此文档含有 foreignField:null的键值对。 - as 为输出文档的新增值命名。如果输入的集合中已存在该值,则会覆盖掉
db.getCollection("user_group").aggregate([{
"$match": {
"$and": [{
"_id": NumberLong("4523281346310580824")
}, {
"deleteFlag": "N"
}]
}
}, {
"$unwind": "$userIds"
}, {
"$lookup": {
"from": "user",
"localField": "userIds",
"foreignField": "_id",
"as": "user"
}
}]);

?
控制显示
project 控制字段显示与否
实现: 删除无用字段,
- 普通列({成员:1 | true}):表示要显示的内容
- “_id” 列({“_id”:0 | false}):表示 “_id” 列是否显示
db.getCollection("user_group").aggregate([{
"$match": {
"$and": [{
"_id": NumberLong("4523281346310580824")
}, {
"deleteFlag": "N"
}]
}
}, {
"$unwind": "$userIds"
}, {
"$lookup": {
"from": "user",
"localField": "userIds",
"foreignField": "_id",
"as": "user"
}
}, {
"$project": {
"user": 1,
"_id": 0,
}
}]);

?
字段置顶
arrayElemAt:将指定文档提升到顶级并替换所有其它字段。该操作会替换输入文档中的所有现在字段,包括_id字段
replaceRoot:返回存在于给定数组的指定索引上的元素
实现:把 user 的第一个元素提至顶级
db.getCollection("user_group").aggregate([{
"$match": {
"$and": [{
"_id": NumberLong("4523281346310580824")
}, {
"deleteFlag": "N"
}]
}
}, {
"$unwind": "$userIds"
}, {
"$lookup": {
"from": "user",
"localField": "userIds",
"foreignField": "_id",
"as": "user"
}
}, {
"$project": {
"user": 1,
"_id": 0,
}
}, {
"$replaceRoot": {
"newRoot": {
"$arrayElemAt": ["$user", 0]
}
}
}]);
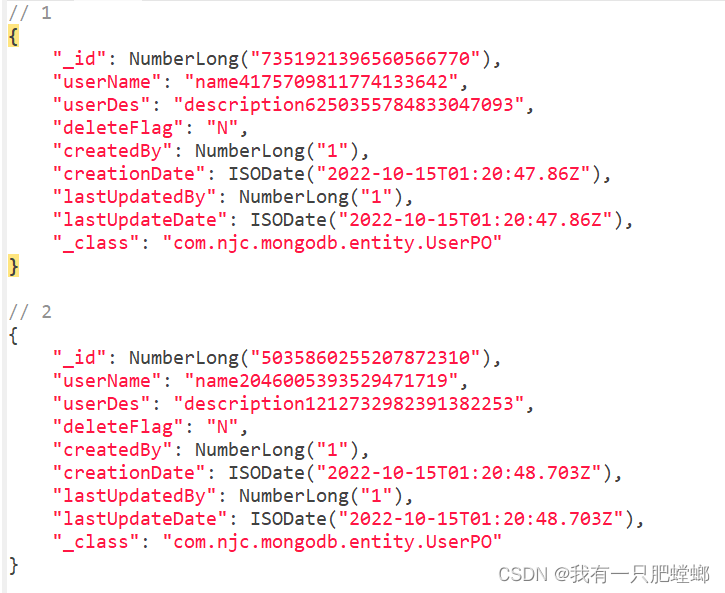
此数据格式已经非常漂亮,符合日常返回格式,完成了需求
?
合并字段
mergeObjects:将多个文档合并为一个文档,如果要合并的文档包含相同的字段名,则结果文档中的字段具有该字段最后一个合并文档中的值
实现:保留 userGroup 的信息
db.getCollection("user_group").aggregate([{
"$match": {
"$and": [{
"_id": NumberLong("4523281346310580824")
}, {
"deleteFlag": "N"
}]
}
}, {
"$unwind": "$userIds"
}, {
"$lookup": {
"from": "user",
"localField": "userIds",
"foreignField": "_id",
"as": "user"
}
}, {
"$replaceRoot": {
"newRoot": {
"$mergeObjects": [{
"$arrayElemAt": ["$user", 0]
}, "$$ROOT"]
}
}
},{
"$project": {
"user": 0
}
}]);

?
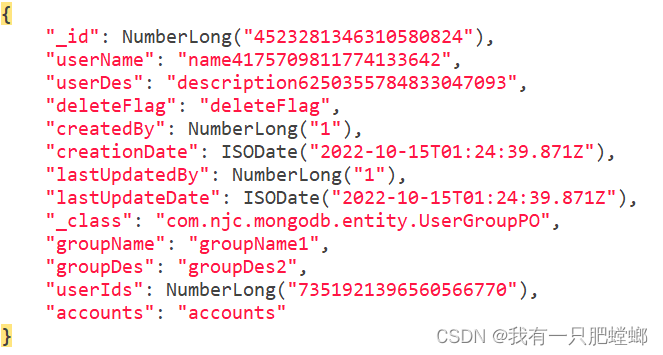
新增字段
set:字段存在则修改,无则新增
实现:
db.getCollection("user_group").aggregate([{
"$match": {
"$and": [{
"_id": NumberLong("4523281346310580824")
}, {
"deleteFlag": "N"
}]
}
}, {
"$unwind": "$userIds"
}, {
"$lookup": {
"from": "user",
"localField": "userIds",
"foreignField": "_id",
"as": "user"
}
}, {
"$replaceRoot": {
"newRoot": {
"$mergeObjects": [{
"$arrayElemAt": ["$user", 0]
}, "$$ROOT"]
}
}
}, {
"$project": {
"user": 0
}
}, {
"$set": {
"accounts": "accounts",
"deleteFlag": "deleteFlag"
}
}]);
?
模糊查询
count:计算总数
实现:查询 user 表的总条数
db.getCollection("user").aggregate([
{
"$count": "total"
}
]);

?
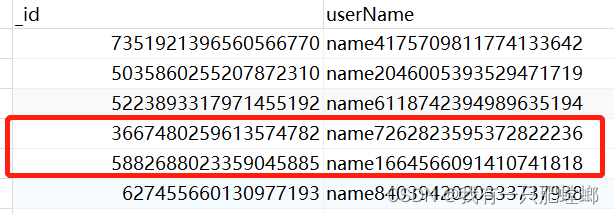
分页查询
分页:对数据做分页处理
跳过 3 条数据,从第 4 条起,显示 2 条
- skip:跳过多少条
- limit:显示多少条
db.getCollection("user").aggregate([
{
"$skip": 3
},
{
"$limit": 2
}
]);
?
分页查询加总数
分页查询需要同时返回总数和数据
facet:在同一组输入文档的单一阶段中处理多个聚合管道;每个子管道在输出文档中都有自己的字段,其结果存储在文档数组中
db.getCollection("user").aggregate([
{
"$facet": {
"metadata": [{
"$count": "total"
}],
"records": [{
"$skip": 0
}, {
"$limit": 10
}]
}
}
]);

metadata 不太符合常规数据结构,把它去掉,把 total 提上顶层
db.getCollection("user").aggregate([
{
"$facet": {
"metadata": [{
"$count": "total"
}],
"records": [{
"$skip": 0
}, {
"$limit": 2
}]
}
},
{
"$replaceRoot": {
"newRoot": {
"$mergeObjects": [{
"$arrayElemAt": ["$metadata", 0]
}, "$$ROOT"]
}
}
},
{
"$project": {
"metadata": 0
}
}
]);
