云计算-基于hadoop-2.7.7从0开始搭建
文章目录
一、环境准备
-
VMware16.4 https://www.vmware.com/products/workstation-pro/workstation-pro-evaluation.html
-
Centos7.9 https://mirror.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/
-
Xshell7&Xftp7 https://www.xshell.com/zh/free-for-home-school/
-
hadoop-2.7.7 https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
hadoop 其它版本 https://archive.apache.org/dist/hadoop/common/
二、必备基础知识
一、 Hadoop是什么?用来干嘛的?
Hadoop是一个能够对大量数据进行分布式处理的软件框架;是由Apache基金会所开发的 分布式系统基础架构 。Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。我们可以在不了解分布式底层细节的情况下,开发分布式程序并充分利用集群的威力进行高速运算和存储。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。
HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
Hadoop的优势
- 高可靠性: Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
- 高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。
- 高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
- 高容错性: 能够自动将失败的任务重新分配。
Hadoop架构图如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vxN8VyMR-1666088257338)(C:\Users\yxn\Downloads\001)]](https://img-blog.csdnimg.cn/064080e4ffef4de79a9e90b993acbf55.png)
参考链接 https://baike.baidu.com/item/Hadoop/3526507 百度百科
二、Hadoop 的组成
-
4个核心 (hadoop 2.x)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uZeXcrng-1666088257339)(C:\Users\yxn\Downloads\image-20221018105101320.png)]](https://img-blog.csdnimg.cn/6fab4486e98e4430bb7ec6f383d40cdf.png)
ps:虽然上述四个模块构成了Hadoop的核心,不过还有其他几个模块。这些模块包括:Ambari、Avro、Cassandra、Hive、 Pig、Oozie、Flume和Sqoop,它们进一步增强和扩展了Hadoop的功能。
ps:Hadoop 的三个版本
Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce只负责运算。
Hadoop3.x时代,在组成上没有变化。
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks
Apache 版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks 文档较好。
- HDFS 框架概述
① NameNode(nn): 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块所在的 DataNode 等。作用如下:
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block)映射信息;
(4)处理客户端读写请求。
② DataNode(dn): 在本地文件系统存储文件块数据,以及块数据校验和。作用如下:
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
③ Secondary DataNode(2nn): 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。并非NameNode的热备份。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。作用如下:
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ;
(2)在紧急情况下,可辅助恢复NameNode。
- Yarn 结构概述
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sfzzb4SU-1666088257340)(C:\Users\yxn\Downloads\002)]](https://img-blog.csdnimg.cn/0c65b4b461754ee69677820c735d7709.png)
YARN ,是一种资源协调者,是 Hadoop 的资源管理器。
**① ResourceManager(RM):**整个集群资源(内存、CPU等)的老大
(1)处理客户端请求。
??(2)监控 NodeManager。
??(3)启动或监控 ApplicationMaster。
??(4)资源的分配与调度。
② NodeManager(NM): 单个任务运行的老大
(1)管理单个节点上的资源。
??(2)处理来自 ResourceManager 的命令。
??(3)处理来自 ApplicationMaster 的命令。
??(4)资源的分配与调度。
③ ApplicationMaster(AM): 单个节点服务器资源老大
(1)负责数据的切分。
??(2)为应用程序申请资源并分配给内部的任务。
??(3)任务的监控与容错。
④ Container(容器): 相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、网络等。
Container 是 Yarn 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
- MapReduce 架构概述
MapReduce 将计算过程分为两个阶段:Map 阶段和 Reduce 阶段。
① Map 阶段并行处理输入的数据。
② Reduce 阶段对 Map 结果进行汇总。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2nJC0dx5-1666088257341)(C:\Users\yxn\Downloads\image-20221018110133629.png)]](https://img-blog.csdnimg.cn/4b6fd18181464d72b0ae4c5b68e878e1.png)
- HDFS、YARN、MapReduce三者关系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zqBqvrcs-1666088257341)(C:\Users\yxn\Downloads\image-20221018110348141.png)]](https://img-blog.csdnimg.cn/73896049a9564e8c8ddab90e65d27eec.png)
- 大数据技术生态体系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H2jkZR95-1666088257341)(C:\Users\yxn\Downloads\003)]](https://img-blog.csdnimg.cn/5070555f06f54570be2b7f91e81adc14.png)
三、关于hadoop集群安装的三种方式对比
1.单机模式( Local/Standalone Mode)
单机模式是Hadoop的默认模式。这种模式在一台单机上运行,没有分布式文件系统HDFS,而是直接读写本地操作系统的文件系统。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。默认情况下,Hadoop处于该模式,用于开发和调试(MapReduce程序的应用逻辑)。
2.伪分布模式(Pseudo-Distributed Mode)
这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
3 . 全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。最低要求3个及以上的实体机或者虚拟机组件的机群来实现。
4. 为什么伪分布式要比单机慢?
众所周知MapReduce是基于硬盘的计算引擎,计算一个结果就会存入硬盘,reduce计算时会从硬盘中取出再进行计算,在单机模式下硬盘就是我们的自身的Linux系统,但是分布式的情况下,硬盘是我们的hdfs分布式文件系统,存取数据会有一层映射,故而慢。既然这样的话,那为何还要有分布式文件系统?原因就是大数据时代,单机硬盘存不下大量数据,只能通过分布式存储。
四、主要名词解释
- 集群
集群(Cluster)是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,在单一系统的管理下,共同协作完成同一个任务。集群中每一个计算机叫作节点,每个节点都实现相同的业务,但是每个节点并不是缺一不可的。其主要作用是缓解并发压力和进行单点故障转移。
集群一般被分为三种类型:高可用集群、负载均衡集群和高性能运算集群。
- 分布式系统
分布式系统是将不同功能或不同地点、拥有不同数据的多台计算机通过网络连接起来,由控制系统统一管理,完成大规模信息处理的计算机系统。在分布式文件系统中,一种业务拆分成多个子业务,部署在多台计算机节点上,对外提供服务。其主要作用是大幅度地提高效率,缓解服务器的访问和存储压力。
常见的分布式系统有分布式文件系统、和分布式计算系统。
- 负载均衡
负载均衡(Load Balance)是指将负载(工作任务)进行平衡,分摊到多个操作单元上进行运行,例如FTP服务器、Web服务器、企业核心。和其他主要任务服务器等,从而协同完成工作任务。负载均衡构建在原有网络结构之上,它提供了一种透明且廉价有效的方法用于扩展服务器和网络设备的带宽,加强网络数据处理能力,增加吞吐量,提高网络的可用性和灵活性。负载均衡中每个节点分配到的任务基本均衡。
三、开始安装hadoop-2.7.7
初始环境配置
由于我安装的Centos镜像是CentOS-7-x86_64-Minimal-2009.iso 也就是最小化,所以要配置一些东西,如果已弄好的请忽略这一步。
- 更新 & 升级
yum update -y && yum upgrade -y
- 安装 ssh服务、net-tools.x86_64工具包、vim、jps
yum install openssh-server -y
yum install net-tools.x86_64 -y
yum install vim -y
yum install java-1.8.0-openjdk-devel.x86_64 -y
- 防火墙设置
systemctl stop firewalld # 关闭防火墙
systemctl disable firewalld # 禁止防火墙开机启动
- 将当前的liunx时间设置为北京时间
yum install ntp ntpdate ntpdate -u cn.pool.ntp.org
单机模式安装
- 下载 hadoop-2.7.7 ,这里我直接从官网下载,要是嫌慢也可以先下载好在传进去
# 方法一
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
# 方法二
scp ./hadoop-2.7.7.tar.gz root@192.168.242.130:/usr/local/
- 解压到指定目录(目录根据自己习惯自行选择,这里参考很多教程使用的是 /usr/local/)
tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local/
mv hadoop-2.7.7 hadoop # 重命名
chmod 777 /usr/local/hadoop #为该目录提升权限,避免操作失败
- 安装JDK-1.8
yum install java-1.8.0-openjdk -y
? 安装完成后输入 java -version 查看 如下图所示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9RESQPrv-1666088257342)(C:\Users\yxn\Downloads\image-20221018152548109.png)]](https://img-blog.csdnimg.cn/1e57d0c201f6470e996b740158c92acc.png)
- 配置Hadoop和JDK的环境变量
# 1.先找到java的安装路径,这里的/usr/bin/java 是which java后的结果
ll /usr/bin/java
ll /etc/alternatives/java
结果如下图: (这里 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64/jre就是java的真实路径,复制!要用)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cI9XOsYm-1666088257342)(C:\Users\yxn\Downloads\image-20221018155002989.png)]](https://img-blog.csdnimg.cn/e7786d1d3c4641e895bac6eb5919d98f.png)
# 2.用vim编辑器打开配置文件
vim /etc/profile
# 3.在末尾添加以下内容
#HADOOP
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# java
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASS_PATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
# :wq 保存退出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gp6e00pH-1666088257343)(C:\Users\yxn\Downloads\image-20221018161531359.png)]](https://img-blog.csdnimg.cn/9a34f2f8174a4e5b95e7f1212149f1e5.png)
# 4.激活环境变量
source /etc/profile
# 5.查看hadoop 版本信息
hadoop version
内容如下表示 Hadoop和JDK均已安装成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PNcwviH1-1666088257343)(C:\Users\yxn\Downloads\image-20221018161712942.png)]](https://img-blog.csdnimg.cn/1159d464999e41da9d4abb68c65eca86.png)
其 目录如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WNdaxECM-1666088257343)(C:\Users\yxn\Downloads\image-20221018162340317.png)]](https://img-blog.csdnimg.cn/5494fd81f83b47889639eb9768c88bfe.png)
官方 Grep 案列
课程没做要求,暂且不赘述
官方 WordCount 案例
课程没做要求,暂且不赘述
伪分布式安装
- 配置集群,修改 Hadoop 的配置文件(/usr/local/hadoop-2.7.7/etc/hadoop 目录下)
# 为了区分我们重命名以下hadoop根目录为hadoop
cd /usr/local
mv hadoop hadoop-2.7.7 # 重命名
cd hadoop-2.7.7/etc/hadoop
## 更改后要 将用vim /etc/profile 将配置文件里面的hadoop也改为hadoop-2.7.7 然后再source /etc/profile 刷新环境变量 !!!!
# 同时将主机名称也进行重命名方便配置(这里将其重命名为hoodoop101)
hostnamectl set-hostname hoodoop101
# 如不重命名也行 下面文件中的所有hoodoop101换成自己主机的IPv4地址即可,或者使用127.0.0.1
? ① core-site.xml
vim core-site.xml # 打开文件后在<configuration></configuration>插入以下内容
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hoodoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop-2.7.7/data/tmp</value>
</property>
</configuration>
? ② hadoop-env.sh
vim hadoop-env.sh # 打开文件后更改以下内容
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64/jre
③ hdfs-site.xml
vim hdfs-site.xml # 打开文件后在<configuration></configuration>插入以下内容
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- 启动集群
# 1.格式化 NameNode(第一次启动时格式化,以后就不要总格式化)
hdfs namenode -format
# 2.启动 NameNode
hadoop-daemon.sh start namenode
# 3. 启动 DataNode
hadoop-daemon.sh start datanode
-
查看集群
① 查看是否启动成功 输入
jps得到如下图所示表示启动成功![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EeCkmMxK-1666088257343)(C:\Users\yxn\Downloads\image-20221018172347311.png)]](https://img-blog.csdnimg.cn/78ec15ea611b48a28fa484c99301f997.png)
② web 端查看 HDFS 文件系统
http://192.168.242.129:50070或者http://localhost:50070自己的 IP 地址可以使用
ifconfig或者ip addr命令查看
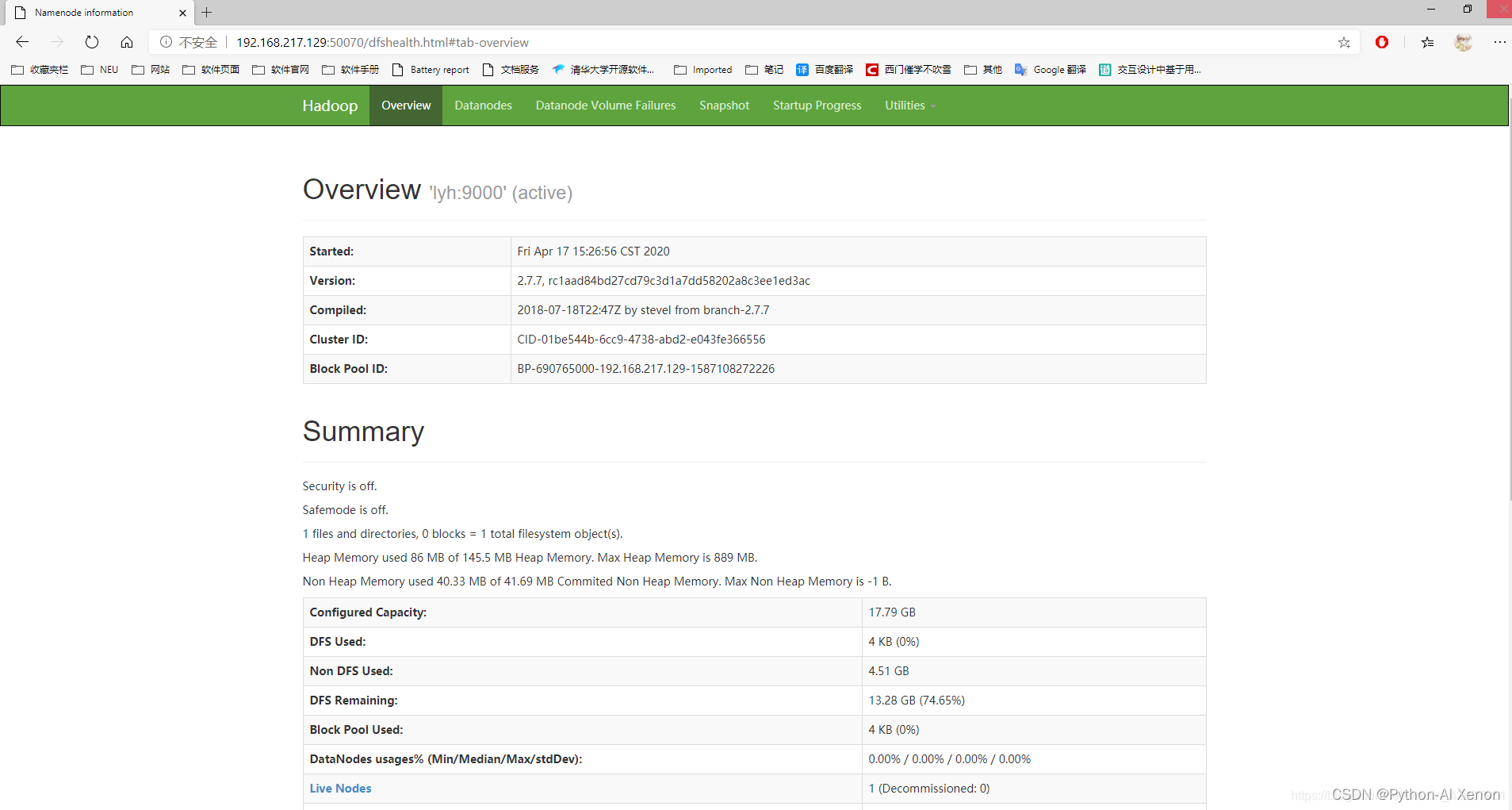
出现该界面就成功了!
全分布式安装
正在更新中…
可能遇到的问题
uname -rs 检查已安装的内核版本
Other
vim中有3中方法可以跳转到指定行(首先按esc进入命令行模式):
1、ngg/nG (跳转到文件第n行,无需回车)
2、:n (跳转到文件第n行,需要回车)
3、vim +n filename (在打开文件后,跳转到文件的第n行)