一、Catalog定义
????????Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。数据处理最关键的方面之一是管理元数据。 元数据可以是临时的,例如临时表、或者通过 TableEnvironment 注册的 UDF。 元数据也可以是持久化的
二、Catalog在Flink中实现讲解
2.1Catalog源码定义
????????Catalog的定义在org.apache.flink.table.catalog.Catalog,可以看到它是一个接口,具体如下:
public interface Catalog {
''''
}
????????Catalog包含了主要的方法:包括获取数据库信、表、视图、表列信息、函数Function、分区Partition等信息的增删查改。
2.1Catalog继承关系
????????下图为Catalog接口继承图
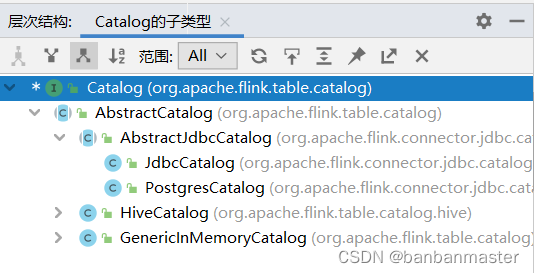
????????可以看到,Catalog的子类为AbstractCatalog,它有3个实现类,GenericInMemoryCatalog,HiveCatalog,AbstractJdbclog,也就是它可以把Catalog信息保存在内存、Hive、Jdbc(目前仅支持Postgre)中。默认的是保存在内存中。
三、Catalog信息保存在Hive测试
????????要验证多个source读取同一张Kafka表如何处理,我们把Catalog信息保存在MySQL中进行测试。
首先是创建Catalog
3.1创建Hive Catalog
????????启动SQL客户端
./sql-client.sh
????????创建 Hive Catalog
启动Flink sqlclient
$FLINK_HOME/bin/sql-client.sh
创建CATALOG的语法为:
create catalog hive_catalog with (
'type' = 'hive',
'default-database' = 'catalogtest',
'hive-conf-dir' = '/opt/hive/apache-hive-3.1.2-bin/conf/'
);
其中hive-conf-dir为本地hive的配置文件路,即$HIVE_HOME/conf
USE CATALOG hive_catalog ;
3.2 创建Kafka主题,并且往其中写数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
往Kafka队列中写入数据,格式为:string,int
>abs,12
>saz,43
.......
3.3在Flink创建Kafka表
CREATE TABLE mykafka (name String, age int) with (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'test',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'connector.properties.group.id' = 'testGroup',
'format.type' = 'csv',
'update-mode' = 'append'
);
其中testGroup为默认的groupid
四、测试数据
4.1 第一组消费者使用已经注册的表去消费
select * from mykafka;
4.2第二组消费者使用已经注册的表去消费
select * from mykafka /*+ OPTIONS('connector.properties.group.id' = 'testGroup111') */;
????????这里使用了hint语法,可以直接消费数据,如果找不到表,需要创建一下catalog(flink官网有默认的catalog设置)
4.3停止第二组消费者,继续往kafka中写数据,再重启第二组消费者
????????首先暂停第二组消费者,然后往Kafka主题中发送数据,接着写入数据后,再重新消费,会观察到数据是从消费停止后开始消费的,这也就说明了这2组消费者是独立的。
五、结论
????????Flink的Catalog支持存储在内存(默认)、Hive、JDBC(仅支持Postgre)中,如果注册完一张Kafka的表默认已经指定了groupId,如果要通过不同的groupId来消费数据,可以通过hint语法指定groupId消费。
????????除此之外,还可以通过修改源码的方式,在使用时指定groupId来读取。