вЛЁЂЧАжУХфжУ
- IDEA
- MavenАВзАХфжУ
- Scala(ПЩбЁ)
- Java
- Hadoop.dll(ПЩФмашвЊ,ОпЬхПДгаЮоЯрЙиДэЮѓаХЯЂ)
- hadoop-lzo-0.xx.xx.jar(ШчЙћФуЕФАцБОЙ§Ип,ашвЊЕНЙйЭјЯТдиИпАцБО,mvnrepositoryВжПтРяУцзюИп0.4.15;ЮвЪЧspark 2.2.0,гУЕФhadoop-lzo-0.4.21.jar;ШчЙћФуЪЙгУЕФSpark/HadoopАцБОБШНЯЕЭ,ПЩвджБНгЪЙгУpomвРРЕМДПЩ)
ЖўЁЂВйзїВНжш
- IDEAжааТНЈвЛИіProject/Module
- pom.xmlжав§ШыЯрЙивРРЕ(SparkЁЂHadoopЕШЕШ)
- БраДЖСШЁlzoЮФМўДњТы
- ВтЪддЫаа
- ДђАќЕНЗўЮёЦїдЫаа
Ш§ЁЂВйзїЫЕУї
1КЭ2ТдЙ§,НВвЛЯТ3ЁЂ4ЁЂ5,ДэЮѓвЛАудкетШ§ИіНзЖЮГіЯжЁЃ
(вЛ)БраДЖСШЁlzoЮФМўДњТы
БиаыЕФФкШн:
val conf = new Configuration()
conf.set("dfs.client.use.datanode.hostname", "true")
conf.set("io.compression.codecs", "org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.GzipCodec,com.hadoop.compression.lzo.LzopCodec")
conf.set("io.compression.codec.lzo.class", "com.hadoop.compression.lzo.LzoCodec")
hostnameЪЧгУгкгаФкЭтЭјIPЕФЧщПіЯТ,евЕНСЫдЊЪ§ОнЕЋЮоЗЈНЈСЂСЌНгЕФХфжУ;
КѓУцСНИіХфжУ,дђЪЧгУгкЖСШЁlzoЮФМў,ЗёдђЛсБЈДэ: java.io.IOException: Codec for file hdfs:xxx.lzo not found, cannot run
import com.hadoop.mapreduce.LzoTextInputFormat
val value = ss.sparkContext
.newAPIHadoopFile(hdfsLzoPath, classOf[LzoTextInputFormat], classOf[LongWritable], classOf[Text], conf)
.mapPartitions(p => p.map(row => row._2.toString))
етвЛВПЗжОЭЪЧЕїАќЖСШЁСЫ,зЂвтLzoTextInputFormatЕФАќЪЧЗёе§ШЗ
(Жў)ВтЪддЫаа
ШчЙћдЫааБЈДэ:ERROR lzo.LzoCodec: Cannot load native-lzo without native-hadoop,ФЧОЭЪЧУЛгаЯрЙиЕФЛЗОГвРРЕЁЃ
ШчЙћЪЧLinuxЛЗОГ,дђЪЧУЛгаАВзАlzoКЭlzop(.a),ШчЙћЪЧБОЕиПЊЗЂЛЗОГ,дђЪЧУЛгаlzoЕФвРРЕ(.dll)ЁЃ
НтОіАьЗЈ:LinuxАВзАlzoАќ,ШчЙћЪЧWindows,дђНЋdllЮФМўЬэМгЕНhadoop_homeФПТМжа

(Ш§)ДђАќЕНЗўЮёЦїдЫаа
ШчЙћАцБОБШНЯЕЭ,жБНгв§гУmvnrepositoryЕФвРРЕзјБъ,вЛАуВЛДцдкдЫааЮЪЬт,ШчЙћЪЧв§ШыЕФjarАќ,дђгаПЩФмЛсБЈДэ,ERROR lzo.LzoCodec: Cannot load native-lzo without native-hadoopЁЃетИіДэЮѓКЭЩЯУцЕФДэЮѓЪЧвЛбљЕФ,ЕЋВЛЪЧЛЗОГЮЪЬт,ЖјЪЧДђАќЙ§ГЬжа,БОЕивРРЕУЛгаБЛвЛВЂДђШыjarАќЁЃНтОіАьЗЈ:НЋБОЕиЕФjarжЦзїЮЊвРРЕ,в§ШыЕНpomжаЁЃ
- жДаа:mvn install:install-file -Dfile=hadoop-lzo-0.4.21-SNAPSHOT.jar -DgroupId=hadoop-lzo -DartifactId=hadoop-lzo -Dversion=0.4.21 -Dpackaging=jar
ИёЪН:
mvn install:install-file
-Dfile=jarАќЕФЮЛжУ
-DgroupId=pomЮФМўРяЕФgroupId
-DartifactId=pomЮФМўРяЕФartifactId
-Dversion=pomЮФМўРяЕФversion
-Dpackaging=jar
- дкpomжае§ГЃв§ШыМДПЩ
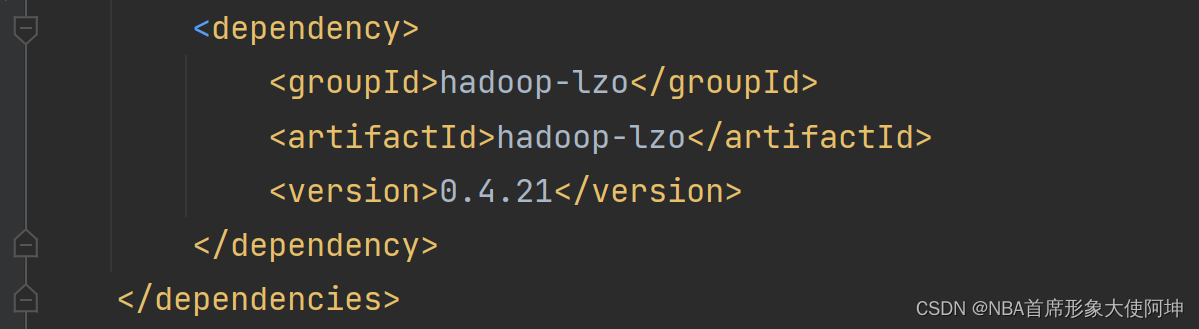
вВПЩвдПМТЧеввЛИігаИпАцБОhadoop-lzoЕФВжПтЕижЗ,ХфжУЕНmaven.setting.xmlжа