一、HBase前置知识
- mysql是b+树存储?
- Hbase之所以快是因为?
- ?利用了顺序io
- ?利用了内存存储 将上一次查询的数据放入内存,下次直接在内存查看

二 、 Hbase简介

?面向行就是 类似于mysql那种,一行存储许多字段,即使那个字段没有初始化,他也会给他占用存储空间,比较浪费
面向列 后面说 但是他类似于k,v键值对
非结构化数据 比如爬虫爬的html标签
半结构化数据 json 每个json里面的kv都是不一样的
结构化数据 就是mysql那种 每条信息的字段我都是自定义好的
?三、数据模型

?Row Key就是一行 一个记录
Time Stamp就是时间戳 表明某一个时间点我插入的数据
CF1是列族的意思 q1 q2是列名 val1 是具体的值
列族+列名可以固定一个属性值,但由于时间戳的存在,他的值不唯一
他的查询就是 先看行号 再看是哪个列族,哪个列名 哪个时间戳
3.1 Row Key

?字典序就是不同字符的ascll码值顺序比较 如 a在b前面 1在2前面??
3.2?Column Family列族& qualifier列

一个列族里面可以有一堆列?
3.3?Timestamp时间戳

3.4 cell单元格

四、Hbase架构
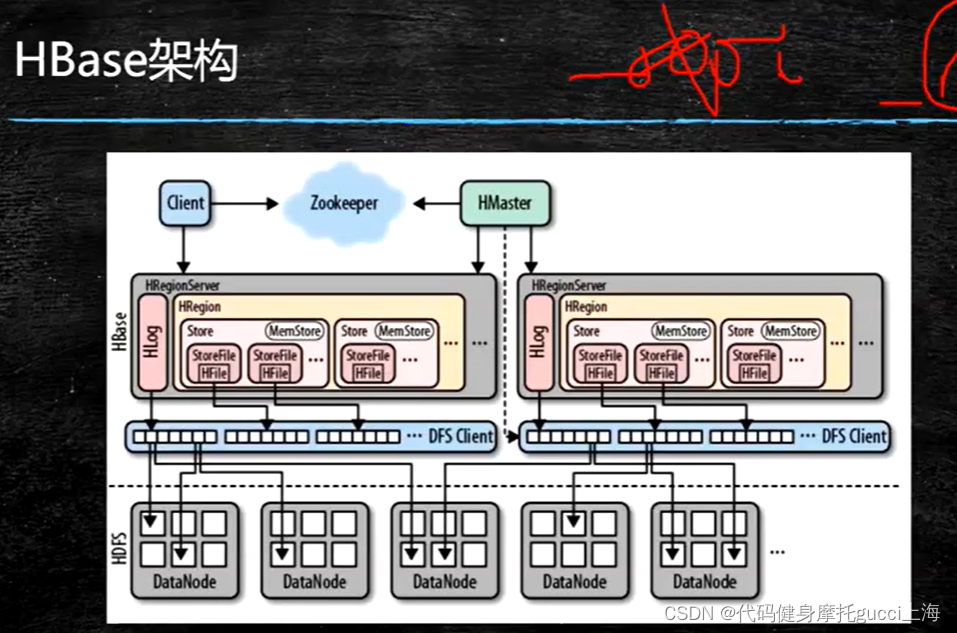
?client客户端负责对Hbase读写东西??
Hbase主从架构,HMaster主? HRegionServer是从
HLog类似于mysql里的日志, HRegion类似于mysql里的一个表,store类似于列族,MemStore就是存在内存,StoreFile存在磁盘
写具体流程:
- zookeeper里会有 元数据的存储地址(元数据他就是指示我某个资源在某个地方 类似于索引的一种东西)
- 第一次访问 先访问zookeeper获取元数据存在哪个 HRegionServer里面
- 第二次就去对应的HRegionServer找到我的目标表对应的地址
- 第三次就可以去目标表所在HRegionServer直接进行读写
- 找到目标表 也要找到目标的列族 也就是store,对其Memstore进行读写。
- MemStore有一个大小限制,只有在溢写的情况或者用户强行存储才会持久化到磁盘StoreFile里面。 如果这些文件太小或者达到某一个阈值时候 也会有一个合并文件compaction的操作 他包括major和minor(合并大规模文件 小规模数量文件)
通常zookeeper也会存储少量元数据,比如在某次访问后,可以将对应表名存在zookeeper中,如果我访问某个表问了zookeeper,他告诉我表不存在 那我直接返回
写的时候 肯定是先写日志Hlog 防止出现断电内存丢失这种情况 然后才进行读写,Hlog存在内存,对接有一个Logsync这样一个线程,每一秒就溢写Hlog的内容到磁盘,这样就能最大限度的防止数据丢失
读具体流程:
- 走到HRegionServer并找到对应列族store了,读的话 Memstore除了是写的缓存,他也可以看做一部分读缓存
- 因为 你当时写的时候 可能还没有进行溢写,那么你刚才写的东西磁盘没有 只有内存有,所以读会先访问Memstore
- 看完Memstore后再看? 一个blockcache这个读缓存?
- blockcache没有再去看 磁盘Hfile
- 通常 为了后续查看的方便,刚读的内容会放进blockcache里? ?它采用是LRU原则。 这就有一个麻烦的地方,以后我再读Hbase的时候,就不太能用select *这种查看全部信息,因为每次查看完我都会更新blockcache,浪费了大量时间不说 而且我前面好不容易缓存的内容也会被刷写掉。? ?但是 blockcache也有一定的机制,他的内存为了支持LRU会分为三块,一块是访问一次就会放进去的,另外几块是访问多次才会刷写进内存,所以select *只能是会对访问一次那个块造成影响
五、Client和zookeeper

?client的cache并不是上面的blockcache
六、?Master和RegionServer

?Master主要是观察各个regionServer的状态,保证能做到负载均衡。或者是哪个regionserver挂掉了(他挂了数据不会丢,因为看起来是数据存在Hbase,其实还是存在了HDFS的DataNode里) 他会将那个传hdfs的接口黑别的regionserver。
常见的负载均衡案例:? 比如常用的表都只在一个regionserver里,我的master就要将这些表分一下 给别的server。
又或者是 某一个表里面一直不停的在存数据,变得异常巨大,这时候 regionserver就会把这个大表一分为二,然后去问问master哪个server空闲啊,我把这半个表送给他们。


?每次溢写都是写一个新的文件 并存在hdfs里面? 文件合并(在hdfs里面合并的)也有说道 慢慢看
这个Hfile合并操作非常有必要,因为 比如我第一次溢写 int a = 1存成一个文件放入磁盘,然后我读取这个文件,我的blockcache里面a是1
第二次溢写 a = 2了,又是一个新的文件了
那我第二次读取的时候 我先读memstore啥也没有,读取blockcache是之前的旧数据了,这就很麻烦
所以经常会进行一个文件的合并,而且合并之后 我会保证数据是最新的(第一个文件a=1,第二个a=2,合并之后只有a=2),除此之外 好像Hbase也有一个机制 类似于索引 即便没有合并之前我读的时候,也会看一看这个值是否更改过,索引是blockCache和磁盘的索引,?