Ŀ¼
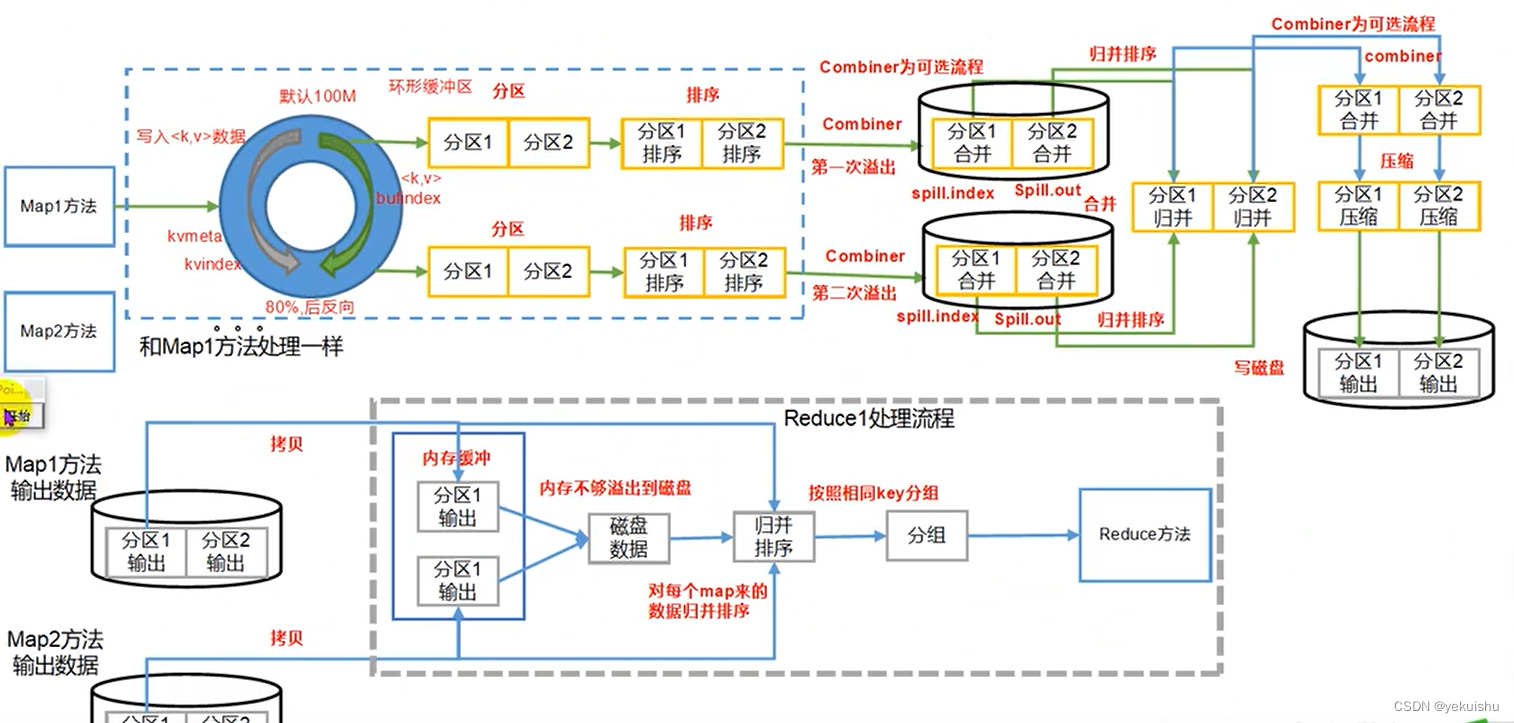
1��Map��
(1)������д(Spill)����:ͨ������mapreduce.task.io.sort.mb��mapreduce.map.sort.spill.precent����ֵ,����_Spill���ڴ�����,����Spill����,�Ӷ����ٴ���IO
(2)���ٺϲ�(Merge)����:ͨ��mapreducetask.io.sort.factor����,����Merge���ļ���Ŀ,����Merge�Ĵ���,�Ӷ�����MR����ʱ�䡣
(3)��Map֮��,��Ӱ��ҵ����ǰ����,�Ƚ���Combine����,����I/O.
set hive.mmap.aggr=true;
(4)shuffle�ε�ѹ��,���紫�䡣
2��Reduce��
(1)��������Map��Reduce��:��������Map��Reudce��Ŀ
(2)����Map��Reduce����:����mapreduce.job.reduce.slowstart.completedmaps����,ʹMap���е�һ���̶Ⱥ�,ReduceҲ��ʼ����,����Reduce�ĵȴ�ʱ�䡣
(3)���ʹ��Reduce:��ΪReduce�������������ݼ���ʱ������������������ġ�?
3�����õ��Ų���
| ���ò���? | ����˵�� |
| mapreduce.map.memory.mb | һ��MapTask��ʹ�õ���Դ����(��λMB),Ĭ��Ϊ1024,���MapTaskʵ��ʹ�õ���Դ��������ֵ,��ᱻǿ��ɱ�� |
| mapreduce.reduce.memery.mb | һ��ReduceTask��ʹ�õ���Դ����(��λMB),Ĭ��Ϊ1024,���MapTaskʵ��ʹ�õ���Դ��������ֵ,��ᱻǿ��ɱ�� |
| mapreduce.map.cpu.vcores | ÿ��MapTask��ʹ�õ����cpu core��Ŀ,Ĭ��:1 |
| mapreduce.reduce.cpu.vcores | ÿ��ReduceTask��ʹ�õ����cpu core��Ŀ,Ĭ��:1 |
| mapreduce.reduce.shuffle.parallelcopies? | ÿ��ReduceȥMap�� ȡ���ݵIJ�����,Ĭ��ֵ��5 |
| mapreduce.reduce.shuffle.merge.percent | Buffer�е����ݴ��ٱ�����ʼд����̡�Ĭ��ֵ0.66 |
| mapreduce.reduce.shuffle.input.buffer.perceent | Buffer��Сռreduce�����ڴ�ı���,Ĭ��0.7.������������ֵ,��ʼ��д�� |
| mapreducereduce.reeduce..inputbuffer.percent | ָ�����ٱ������ڴ��������buffer�е�����,Ĭ��ֵ��0.0 |
| mapreduce.task.io.sort.mb | ���λ�������С |
| mapreduce.map.sort.spill.precent | ���λ�������д���� |
| mapreducetask.io.sort.factor | һ��������ļ����� |
?
?
4 Hadoopѹ������
4.1 MR֧�ֵ�ѹ������
��6-8
| ѹ����ʽ | ���� | �㷨 | �ļ���չ�� | �Ƿ���з� |
| DEFAULT | �� | DEFAULT | .deflate | �� |
| Gzip | gzip | DEFAULT | .gz | �� |
| bzip2 | bzip2 | bzip2 | .bz2 | �� |
| LZO | lzop | LZO | .lzo | �� |
| Snappy | �� | Snappy | .snappy | �� |
Ϊ��֧�ֶ���ѹ��/��ѹ���㷨,Hadoop�����˱���/������,���±���ʾ:
��6-9
| ѹ����ʽ | ��Ӧ�ı���/������ |
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
ѹ�����ܵıȽ�:
��6-10
| ѹ���㷨 | ԭʼ�ļ���С | ѹ���ļ���С | ѹ���ٶ� | ��ѹ�ٶ� |
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
snappy | A fast compressor/decompressor
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses?at about 250 MB/sec or more and?decompresses?at about?500 MB/sec or more.
4.2 ѹ����������
Ҫ��Hadoop������ѹ��,�����������²���(mapred-site.xml�ļ���):
��6-11
| ���� | Ĭ��ֵ | �� | ���� |
| io.compression.codecs ?? (��core-site.xml������) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | ����ѹ�� | Hadoopʹ���ļ���չ���ж��Ƿ�֧��ij�ֱ������ |
| mapreduce.map.output.compress | false | mapper��� | ���������Ϊtrue����ѹ�� |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | mapper��� | ʹ��LZO��LZ4��snappy��������ڴ˽�ѹ������ |
| mapreduce.output.fileoutputformat. compress | false | reducer��� | ���������Ϊtrue����ѹ�� |
| mapreduce.output.fileoutputformat. compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer��� | ʹ�ñ������߱������,��gzip��bzip2 |
| mapreduce.output.fileoutputformat. compress.type | RECORD | reducer��� | SequenceFile���ʹ�õ�ѹ������:NONE��BLOCK |
4.3 ����Map�����ѹ��
����map�����ѹ�����Լ���job��map��Reduce task�����ݴ�������������������:
����ʵ��:
1.����hive�м䴫������ѹ������
hive (default)>set hive.exec.compress.intermediate=true;
2.����mapreduce��map���ѹ������
hive (default)>set mapreduce.map.output.compress=true;
3.����mapreduce��map������ݵ�ѹ����ʽ
hive (default)>set mapreduce.map.output.compress.codec=
?org.apache.hadoop.io.compress.SnappyCodec;
4.ִ�в�ѯ���
hive (default)> select count(ename) name from emp;
3.��һ����Ĭ�ϴ�����ORC�洢��ʽ,�������ݺ�Ĵ�СΪ
2.8 M??/user/hive/warehouse/log_orc/000000_0
��Snappyѹ���Ļ�С��ԭ����orc�洢�ļ�Ĭ�ϲ���ZLIBѹ������snappyѹ����С��
4.�洢��ʽ��ѹ���ܽ�
��ʵ�ʵ���Ŀ��������,hive�������ݴ洢��ʽһ��ѡ��:orc��parquet��ѹ����ʽһ��ѡ��snappy,lzo��
4.4 ����Reduce�����ѹ��
��Hive�����д�뵽����ʱ,�������ͬ�����Խ���ѹ��������hive.exec.compress.output������������ܡ��û�������Ҫ����Ĭ�������ļ��е�Ĭ��ֵfalse,����Ĭ�ϵ�������Ƿ�ѹ���Ĵ��ı��ļ��ˡ��û�����ͨ���ڲ�ѯ����ִ�нű����������ֵΪtrue,������������ѹ�����ܡ�
����ʵ��:
1.����hive�����������ѹ������
hive (default)>set hive.exec.compress.output=true;
2.����mapreduce�����������ѹ��
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
3.����mapreduce�����������ѹ����ʽ
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =
?org.apache.hadoop.io.compress.SnappyCodec;
4.����mapreduce�����������ѹ��Ϊ��ѹ��
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5.����һ���������Ƿ���ѹ���ļ�
hive (default)> insert overwrite local directory
?��/opt/module/datas/distribute-result�� select * from emp distribute by deptno sort by empno desc;
5 SMB join
? ? ? ? ȫ��Sort Merge Bucket Join��
2.1.6.1 ����
? ? ? ? �����С��Ӧ��ʹ��MapJoin�������Ż�,��������Ǵ���Դ��,�������shuffle,�Ǿͷdz�����,��һ��������˵,�ڶ������׳��쳣,��ʱ�Ϳ���ʹ��SMB Join��������ܡ�SMB Join����bucket-mapjoin������bucket,��ʵ����map�����join����,������Ч�ؼ��ٻ����shuffle����������SMB join��������Map join���Ƶ��ֲ�ͬ�� ? ? ? ?
2.1.6.2 ����
bucket mapjoin?? ?SMB join
set hive.optimize.bucketmapjoin = true;?? ?set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
һ������bucket������һ����bucket����������?? ?�����bucket��=���bucket��
bucket�� == join��?? ?Bucket �� == Join �� == sort ��
������Ӧ����map join�ij�����?? ?������Ӧ����bucket mapjoin �ij�����
2.1.6.3 ע������
? ? ? ? hive�����������join�ı��Ƿ��Ѿ�����bucket��sorted,��Ҫ�û��Լ�ȥ��֤join�ı�����sorted,����������ݲ���ȷ��
? ? ? ? �������취:
hive.enforce.sorting ����Ϊ true������ǿ������ʱ,�����ݵ����л����ǿ������,Ĭ��false��
��������ʱͨ����sql����distributed c1 sort by c1 ���� cluster by c1
����,������ʱ������CLUSTERED��SORTED,����:
create table test_smb_2(mid string,age_id string)
CLUSTERED BY(mid) SORTED BY(mid) INTO 500 BUCKETS;
����,�漰����Ͱ����������ȫ����Ϊ:
--д������ǿ�Ʒ�Ͱ
set hive.enforce.bucketing=true;
--д������ǿ������
set hive.enforce.sorting=true;
--����bucketmapjoin
set hive.optimize.bucketmapjoin = true;
--����SMB Join
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
����MapJoin������(hive.auto.convert.join��hive.auto.convert.join.noconditionaltask.size),�������ƶ�Ͱ������load����(hive.strict.checks.bucketing)����ֱ��������hive����������,������sql��������
�Զ�����SMB����(hive.optimize.bucketmapjoin.sortedmerge)Ҳ�����������н�����ǰ���á�?
6����������ģʽ
set hive.exec.mode.local.auto=true;
��ʱhive�������������Ƿdz�С�ġ������������,Ϊ��ѯ����ִ�������ʱ�����Ŀ��ܻ��ʵ��job��ִ��ʱ��Ҫ��Ķࡣ���ڴ�����������,hive����ͨ������ģʽ�ڵ�̨�����ϴ������е�������С���ݼ�,ִ��ʱ������Ա�����
��һ��job��������������������ʹ�ñ���ģʽ:����
- 1.job���������ݴ�С����С�ڲ���:hive.exec.mode.local.auto.inputbytes.max(Ĭ��128MB) ��
- 2.job��map������С�ڲ���:hive.exec.mode.local.auto.tasks.max(Ĭ��4) ����
- 3.job��reduce������Ϊ0����1
���ò���hive.mapred.local.mem(Ĭ��0)����child jvmʹ�õ�����ڴ�����
7��ʲô�����ֻ��һ��reduce
�ܶ�ʱ����ᷢ�������в������������,��������û�����õ���reduce�����IJ���,������һֱ��ֻ��һ��reduce����;��ʵֻ��һ��reduce��������,����������С��hive.exec.reducers.bytes.per.reducer����ֵ�������,��������ԭ��:
a)û��group by�Ļ���,�����select pt,count(1) from popt_tbaccountcopy_mes where pt = ��2012-07-04�� group by pt; д�� select count(1) from popt_tbaccountcopy_mes where pt = ��2012-07-04��; ���dz�����,ϣ����Ҿ�����д��
b)����Order by
disticnt ��Ҫ�ж��Ƿ�������
c)Count(Distinct) ȥ��ͳ��
������С��ʱ������ν,��������������,����COUNT DISTINCT������Ҫ��һ��Reduce Task�����,��һ��Reduce��Ҫ������������̫��,�ͻᵼ������Job�������,һ��COUNT DISTINCTʹ����GROUP BY��COUNT�ķ�ʽ�滻:
4)���Ƶѿ������IJ�ѯ���Թ�ϵ�����ݿ�dz��˽���û�����������ִ��JOIN��ѯ��ʱ��ʹ��ON������ʹ��where���,������ϵ���ݿ��ִ���Ż����Ϳ��Ը�Ч�ؽ�WHERE���ת�����Ǹ�ON��䡣���ҵ���,Hive������ִ�������Ż�,���,������㹻��,��ô�����ѯ�ͻ���ֲ��ɿص������
8��ʸ������ѯ
hive��Ĭ�ϲ�ѯִ������һ�δ���һ��,��ʸ������ѯִ����һ��hive����,Ŀ���ǰ���ÿ��1024�ж�ȡ����,����һ���Զ�������¼����(�����ǶԵ�����¼)Ӧ�ò���,ע��:Ҫʹ��ʸ������ѯִ��,�ͱ�����ORC��ʽ�洢���ݡ�
set hive.vectorized.execution.enabled=true;