一、Hadoops大数据生态
1、Mapreduce
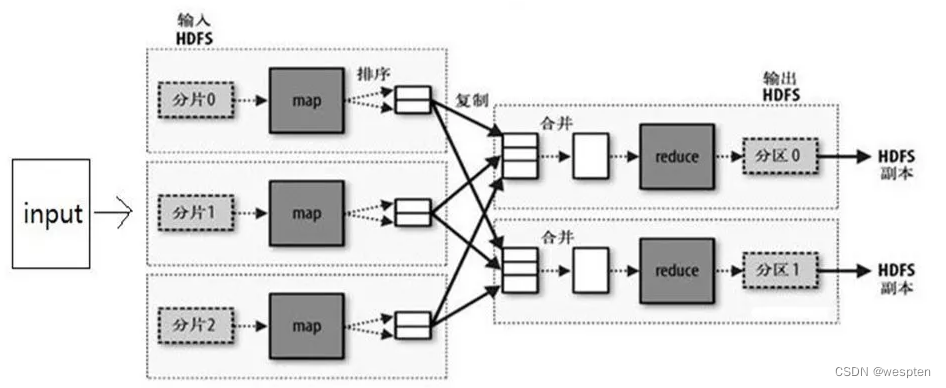
MapReduce是一种编程模型,用于支持能够并行处理的大型数据集,且其封装了并行计算、容错、数据分布、负载均衡等细节问题。
MapReduce 是 Hadoop 生态系统和 Spark 中的一个重要组件,其原理是分治算法(Divide-and-Conquer):通过把工作拆分成较小的数据集,完成一些独立任务,来支持大量数据的并行处理。
- MapReduce 从用户那里获取整个数据集,把它分割为更小的任务(MAP),然后把它们分配到各个工作节点。
- 一旦所有工作节点成功地完成了它们各自的独立任务,就会聚合(REDUCE)各独立任务的结果,然后返回整个数据集的结果。
通常,Map 和 Reduce 函数是用户定义的函数,它们解决了以往需要用代码解决的业务用例。
2、HDFS
HDFS(Hadoop File System)是 Hadoop 的分布式文件存储系统。
当数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统,是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。分布式文件管理系统有很多,HDFS 只是其中一种。
- HDFS 将大文件分解为多个 Block(最基本的存储单位),每个 Block 保存多个副本(默认 3 个),HDFS 默认 Block 大小是 128MB,以一个 256MB 文件来说,则共有 256/128 = 2 个 Block。
- 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间 。
- HDFS 提供容错机制,副本丢失或者宕机时自动恢复。
1. HDFS特点
- 通透性:让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
- 容错性:即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
- 适用于一次写入多次查询的情况(不可在线修改,只能下载修改后再上传)。
- 不支持并发写情况(比如一份数据分 8 块,那么得按顺序来写,而不能同时)。
- 不适用于小文件。
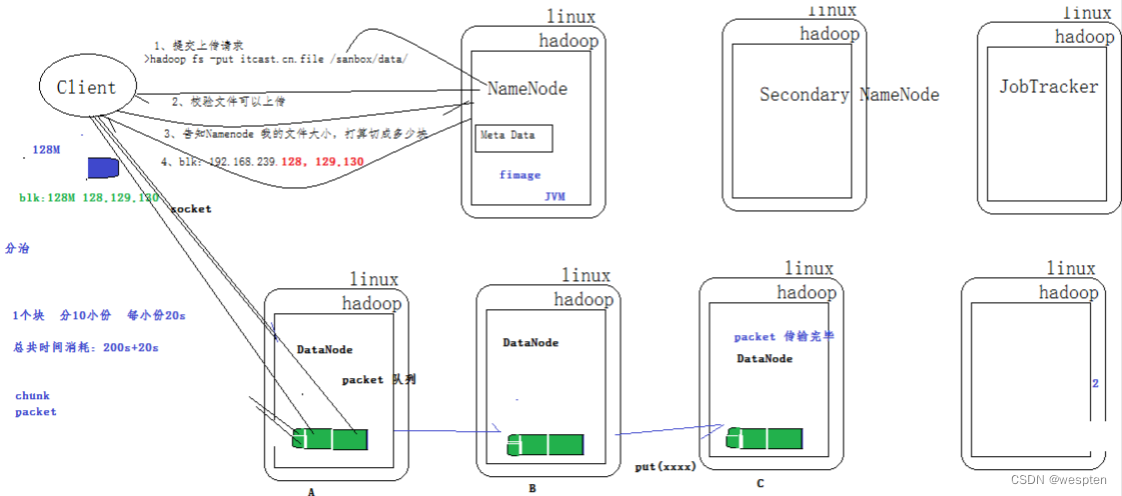
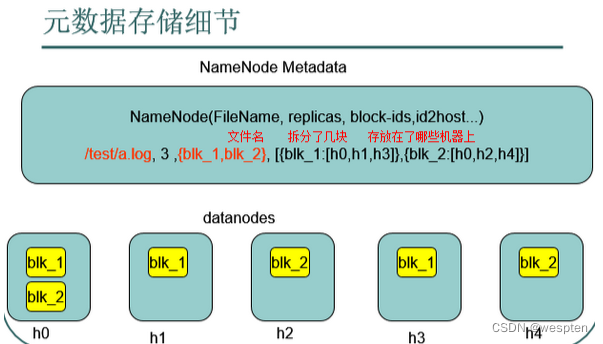
2. HDFS的架构:主从结构
-
主节点只有一个:NameNode
-
从节点有很多个:DataNode
NameNode 负责:
- 保存元数据信息:如文件属性,服务器,文件怎么存。
- 接收用户操作请求。
- 维护文件系统的目录结构。
- 管理文件与 block 之间关系、block 与 datanode 之间关系。
DataNode 负责:
- 存储文件。
- 文件被分成 block 存储在磁盘上。
- 为保证数据安全,文件会有多个副本。
- 心跳检测。
3. HDFS的Shell
hadoop fs:该命令可以用于其他文件系统,不止是hdfs文件系统内,也就是说该命令的使用范围更广。
hadoop dfs:专门针对 hdfs 分布式文件系统。
hdfs dfs:和上面的命令作用相同,相比于上面的命令更为推荐。当使用 hadoop dfs 时实质内部会被转为 hdfs dfs 命令。
参数说明:
-help [cmd] //显示命令的帮助信息
-ls <path> //显示当前目录下所有文件
-ls -R(递归) -h(大小单位)
-du(s) <path> //显示目录中所有文件大小
-count[-q] <path> //显示目录中目录和文件的数量
-mv <src> <dst> //移动多个文件到目标目录
-cp <src> <dst> //复制多个文件到目标目录
-rm(r) //删除文件(夹)
-put <localsrc> <dst> //本地文件复制到hdfs
-copyFromLocal //同put
-moveFromLocal //从本地文件移动到hdfs
-get [-ignoreCrc] <src> <localdst> //复制文件到本地,可以忽略crc校验
-getmerge <src> <localdst> //将源目录中的所有文件排序合并到一个文件中
-cat <src> //在终端显示文件内容
-text <src> //在终端显示文件内容
-copyToLocal [-ignoreCrc] <src> <localdst> //复制到本地
-moveToLocal <src> <localdst>
-mkdir <path> //创建文件夹
-touchz <path> //创建一个空文件3、数据采集、存储、计算
1. 数据采集和 DataFlow
对于数据采集主要分为三类,即结构化数据库采集、日志和文件采集、网页采集。
对于结构化数据库,采用 Sqoop 是合适的,可以实现结构化数据库中数据并行批量入库到 HDFS 存储。
对于网页采集,前端可以采用 Nutch,全文检索采用 Lucense,而实际数据存储最好是入库到 Hbase 数据库。
对于日志文件的采集,现在最常用的仍然是 Flume 或 Chukwa,但是如果对于日志文件数据需要进行各种计算处理再入库的时候,往往 Flume 并不容易处理,这也是为何可以采用 Pig 来做进一步复杂的 DataFlow 和 Process 的原因。
数据采集类似于传统的 ETL 等工作,因此传统 ETL 工具中的数据清洗、转换、调度等都是相当重要的内容。这一方面是要基于已有的工具,进行各种接口的扩展以实现对数据的处理和清洗,一方面是加强数据采集过程的调度和任务监控。
2. 数据存储库
在这里先谈三种场景下的三种存储和应用方式,即 Hive,Impala、Hbase,其中三者都是基于底层的 HDFS 分布式文件系统。
- Hive 重点是 Sql-Batch(批处理)查询,适用于海量数据的统计类查询分析。
- Impala 重点是?Ad-Hoc(点对点)模式和交互式查询。Hive 和 Impala 都可以看作是基于 OLAP(Online analytical processing,联机分析处理)模式的。
- Hbase 重点是支撑业务的 CRUD(增删改查)操作,如各种业务操作下的处理和查询。
1)Hive
- Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 重点是 Sql-Batch(批处理)查询,适用于海量数据的统计类查询分析。
- Hive 数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供 SQL 查询功能,能将 SQL 语句转变成 MapReduce 任务来执行。
- Hive 的优点是学习成本低,可以通过类似 SQL 语句实现快速 MapReduce 统计,使 MapReduce 变得更加简单,而不必开发专门的 MapReduce 应用程序。
2)Impala
- Impala 是 Cloudera 公司主导开发的新型查询系统,它提供 SQL 语义,能查询存储在 Hadoop? 的 HDFS 和 HBase 中的 PB 级大数据。已有的 Hive 系统虽然也提供了 SQL 语义,但由于 Hive 底层执行使用的是 MapReduce 引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速,Impala 本身是基于内存的 MPP(Massively Parallel Processing,大规模并行处理)机制。
- Impala 重点是?Ad-Hoc(点对点)模式和交互式查询。Hive 和 Impala 都可以看作是基于 OLAP(Online analytical processing,联机分析处理)模式的。
3)HBase
- HBase 是一个分布式的、面向列的开源数据库,是 Apache 的 Hadoop 项目的子项目,该技术来源于 Fay Chang 所撰写的 Google 论文“Bigtable:一个结构化数据的分布式存储系统”。
- 就像 Bigtable 利用了 Google 文件系统(File System)所提供的分布式数据存储一样,HBase 在 Hadoop 之上提供了类似于 Bigtable 的能力。
- HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是 HBase 基于列的而不是基于行的模式。
如何对上面三种模式提供共享一致的数据存储和管理服务,HCatalog 是基于 Apache Hadoop 之上的数据表和存储管理服务,提供统一的元数据管理。不需要知道具体的存储细节当然是最好的,但是 Hcatalog 本身也还处于完善阶段,包括和 Hive、Pig 的集成。
对于 MapReduce 和 Zookeeper 本身就已经在 Hbase 和 Hive 中使用到了。如 Hive 的 HQL 需要通过 MapReduce 解析和合并等。
3. 实时流计算
数据的价值越来越被企业重视,被称为是 21 世纪的石油。
当存储了大规模的数据,我们要干什么呢,当然是分析数据中的价值,Hadoop 的 MapReduce 主要用于离线大数据的分析挖掘,比如电商数据的分析挖掘、社交数据的分析挖掘、企业客户关系的分析挖掘等,最终的目标就是 BI(商业智能)了,以提高企业运作效率,实现精准营销及各个垂直领域的推荐系统、发现潜在客户等等。在这个数据化时代,每件事都会留下电子档案,分析挖掘日积月累的数据档案,我们就能理解这个世界和我们自己更多。
但 MR 编写代码复杂度高,且由于磁盘 I/O,分析结果周期长,现实世界中我们对数据分析的实时性要求越来越高,基于内存计算的 Spark 来了。Hadoop+Spark 正在替代 Hadoop+MR 成为大数据领域的明星,Cloudera 正在积极推动 Spark 成为 Hadoop 的默认数据处理引擎。
同时 Twitter 也推出了 Storm 用来解决实时热点查询和排序的问题。
4、RPC
RPC(Remote Procedure Call,远程过程调用协议)用于不同进程之间的方法调用。
由远程过程调用中直接基于 TCP 进行远程调用,数据传输在传输层 TCP 层完成,更适合对效率要求比较高的场景。RPC 采用 C/S 模式,主要依赖于客户端和服务端之间建立 Socket 连接进行。
- 首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。
- 在服务器端,进程保持睡眠状态直到调用的信息到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息。
- 最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
Hadoop 的整个体系结构就是构建在 RPC 之上(见 org.apache.hadoop.ipc),Server 和 Client 都由 Hadoop 完成。
5、序列化
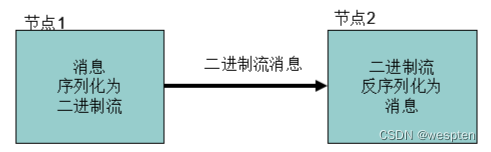
1. Hadoop 序列化的作用
- 序列化在分布式环境的两大作用:进程间通信,持久化存储。
- Hadoop 节点间通信。
2. Hadoop 序列化的特点
- 紧凑:高效使用存储空间。
- 快速:读写数据的额外开销小。
- 可扩展:可透明地读取老格式的数据。
- 互操作:支持多语言的交互。
6、Spark vs Hadoop
有个常见问题是:当 MapReduce 已经成为 Hadoop 中的一部分时,为什么还要使用 Spark?或者,当 Spark 构建在 Hadoop 生态系统之上时,它有什么优势?
Apache Spark 是一个通用的集群计算系统。和 MapReduce 一样,它是与一组计算机(节点)一起工作、并行处理,来提高响应的时间。
MapReduce 采用拆分-应用-合并的策略进行数据分析,把拆分后的数据存储到集群的磁盘上。
相比之下,Spark 在其数据存储之上使用内存,可以在整个集群中并行地加载、处理数据。不过,跟 MapReduce 不同的是,Spark 集群有内存特性。它的内存特性能让 Spark Clusters 把数据缓存到节点上,而不是每次都从磁盘中获取数据(因为数据量巨大,所以通常需要很长时间的读写操作),变成了每个节点的一次性操作。比起 MapReduce,Spark 更有速度优势,因为它的数据分布和并行处理是在内存中完成的。
Spark 的流行,是因为它在内存中处理数据集,所以可以提供快速的结果和 MapReduce 所缺少的实时处理能力。
Spark 功能特点:
- 高速(Speed)→因为它是内存处理的。
- 缓存(Caching)→Spark 有一个缓存层来缓存数据,加速处理进程。
- 部署(Deployment)→可以部署在 Hadoop 集群或自己的 Spark 集群中。
- 多语言(Polyglot)→代码可以用 Python、Java、Scala 和 R 编写。
- 实时(Real-time)→开发它的目的就是为了支持“实时”用例。
Spark 和 Hadoop 之间几个关键的区别:
| Hadoop | Spark | |
| 性能 | 由于磁盘操作, 与 Spark 相比,MapReduce 相对较慢。 | 由于内存计算,与 MapReduce 相比,速度更快。 (Spark 在内存中运行要快 100 倍,在磁盘上快了 10 倍。 但当有其他需要资源的服务正在运行时,执行速度可能会降低。) |
| 数据处理 | 可用于批量处理(即连续步进式处理,sequential step-wise processing)。 | 可用于批量、实时和图形的方式处理。 |
| 机器学习 | Hadoop 使用 Mahout 进行代数运算,但缺乏 ML 库支持。 | Spark 有一个大型的 ML 库来构建管道、执行超参数调优(hyperparameter tuning)。 |
| 易于学习 | MapReduce 没有交互模式,内置 API 的数量相对较少。 需要大量编程。 | Spark 有很多高级 API,所以编程和交互较少。 |
| 成本 | Hadoop 更便宜,因为它只需要更多的磁盘存储空间。 | Spark 需要更高的 RAM 才能在内存中运行,所以成本更高。 |
| 容错 | Hadoop 跨多个节点复制数据,所以具有容错性。 | Spark RDD 因为它的内存特性,所以也具有一定的容错性 |
总结:
- 当系统需要更便宜、更独立的时间以及更大的容错能力时,要选择 Hadoop。
- 当算法是迭代的,并且需要交互式数据处理或机器学习时,就要选择 Spark。在需要实时分析/预测结果的时候,选择 Spark 也有一定优势。
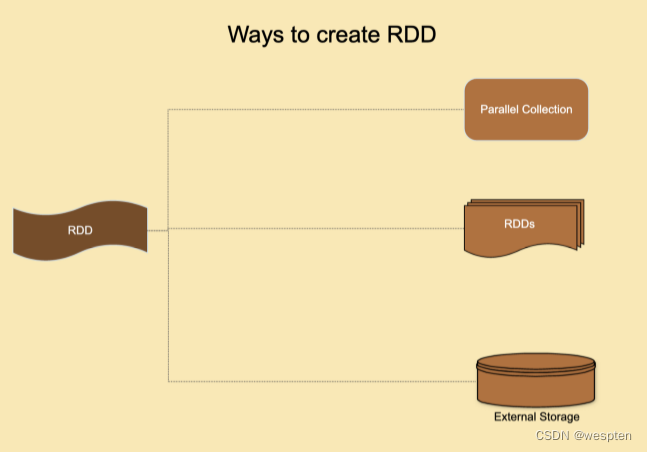
7、RDD(Resilient Distributed Dataset)
Spark 数据的内存处理是使用弹性分布式数据集(Resilient Distributed Datasets----RDD)完成的,用户必须指定操作。
RDD 是提供 Spark 特性的支柱,负责数据的分发以及所有节点内存中操作。
- Spark 提供的主要概念是一个弹性的分布式数据集(RDD),它是跨集群节点划分的元素集合,可以进行并行的操作。RDD是通过从 Hadoop 文件系统(或任何其他 Hadoop 支持的文件系统)中的文件或驱动程序中现有的 Scala 集合开始,然后对其进行转换来创建的。用户还可以要求 Spark 将 RDD 持久化在内存中,或缓存 RDD 来提高性能,从而能让它在并行操作中有效地重用。最后,RDD 会自动从节点故障中恢复。
- RDD 是不可变的,这在自我恢复中起了很大的作用。不可变意味着需要存储用于生成 RDD 的转换序列。这是一个有向无环图(DAG),可以把数据集复制到多个节点上。所以,如果处理数据集分区的特定节点发生故障,集群管理器就可以把这个节点分配给沿袭的其他节点,并恢复正在处理的数据。
- RDD 是一种无模式的数据结构,可以处理结构化和非结构化数据。所有的操作都是在 RDD 上完成的,从一个 RDD 转换到另一个 RDD,最终把它们存储在持久存储中。它是一个不可变的分布式对象的集合,这些对象甚至可以是用户自定义的类别。RDD 支持延迟评估,直到执行了某一个操作,结果才被评估。转换产生新的 RDD,操作产生结果。
8、Spark 生态
Spark 生态系统的设计分为两层――第一层是 Spark Core,第二层是含有 libraries 和 API 的包。
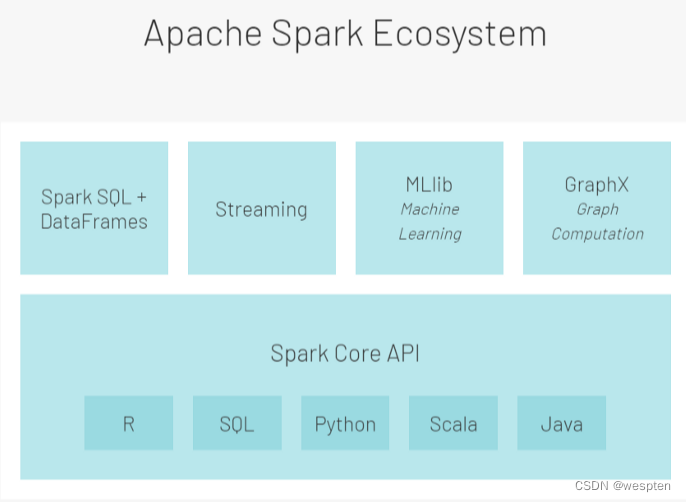
第一层 Spark Core 层:Spark Core 是 Spark 生态系统的基础核心组件,整个生态系统都建立在它之上。
- 引擎(Spark Engine):SPARK ENGINE 的计算引擎负责执行调度(将任务分解成更小的任务、调度任务、并行处理)、监控(报告故障)、和基本的 IO 功能(向集群提供数据)。它也是与集群管理器和数据管理器交互的管理中枢。
- 管理(Management): Spark 集群可以通过 Hadoop YARN、Mesos 或 Spark 集群管理器进行管理。
- 库(Library): Spark 生态系统包括 Spark SQL(用于 RDD 或外部数据源的类似 SQL 查询的运行)、Spark Mlib(用于机器学习)、Spark Graph X(用于构建更好的数据可视化图)、Spark 流(用于同一应用程序中的批量处理和流水式处理)。
- 存储(Storage):数据可以存储在?Hadoop 文件系统(HDFS)、AWS 的 S3 系统、本地存储中,同时支持 SQL 和 NoSQL 数据库。
第二层 Saprk Core API 层:含有 libraries 和 API 的包。
Apache Spark Core API(在 R、SQL、Python、Scala 和 Java 中可用)最初是用来编写数据处理逻辑的。这些基于 RDD 的 API ,缺少了一些性能优化器。但是,因为没有额外的开销,所以它们还为用户提供了最大程度的个人定制和灵活性,可以根据公司的要求进行编程。
为了克服核心 API 的不足,提供更有针对性的支持,Apache Spark 在核心 API 的基础上引入了第二层。第二层通常分为 4 组逻辑 API/库:
- SparkSQL 和 Dataframes:这允许用户在 Spark 数据帧上执行 SQL 命令。它们主要用于结构化和半结构化数据。
- Streaming:这些 API 用于处理连续传入的无界数据流。
- Mllib:这个库支持所有可以部署在 Spark 框架上的机器学习活动。
- GraphX:是一个能让图形处理算法实施到可用数据集的库。
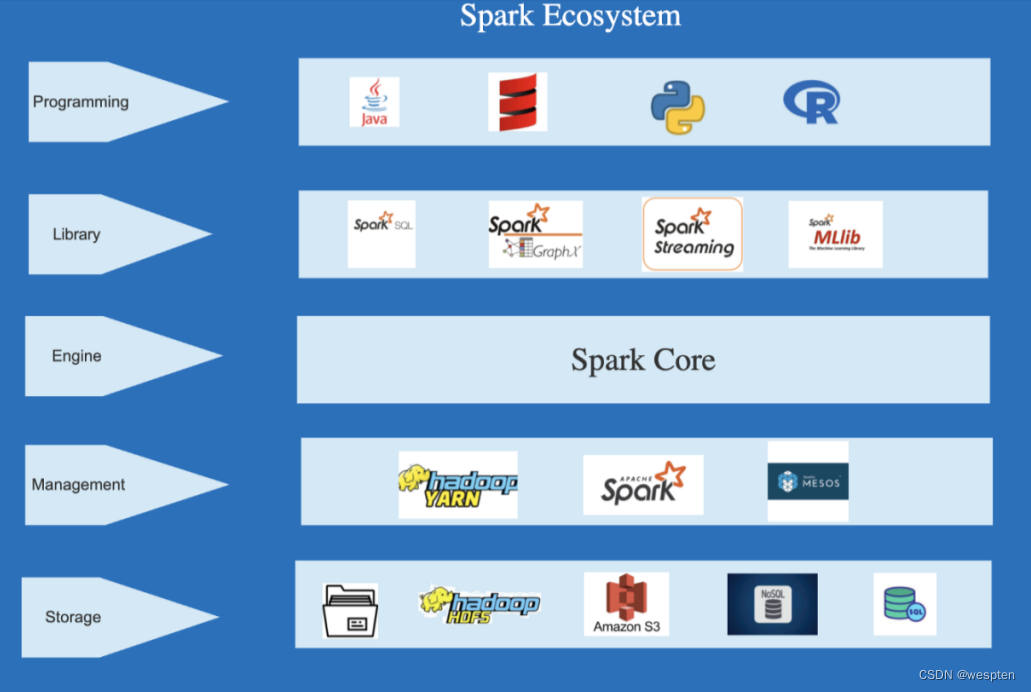
Spark 是由一个驱动节点(Driver Node)、集群管理器(Cluster Manager)和多个辅助节点(Secondary Node)组成的。
- 驱动节点包含具有 Spark 环境的驱动程序,驱动程序把用户提交的程序转换为 DAG。
- Spark 环境在集群管理器的帮助下,把任务(作业的可执行部分)分配给次要节点。
- 集群管理器负责分配驱动程序(执行作业所需的资源)。
- 次要节点负责执行任务,并将结果返回到环境的地方?。
Spark 主要有以下三种工作模式:
- 批处理模式――调度作业,并且有一个队列用于运行该作业的批处理,此过程无需人工干预。
- 流水式(Stream)处理模式――当数据流到来时,程序进行运行和处理
- 交互(Interactive)模式――用户在 shell 上执行命令,主要用于开发目的。
二、Hive简介
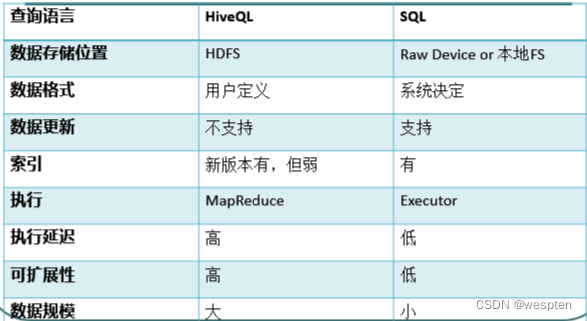
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据的提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者开发自定义的 mapper 和 reducer 来处理内建的?MapReduce?所无法完成的复杂的分析工作。
Hive 是 SQL 解析引擎,它将 SQL 语句转译成 MapReduce Job 然后在 Hadoop 执行。
Hive 的表其实就是 HDFS 的目录/文件夹,按表名把文件夹分开,表里的数据对应的是目录里的文件。如果是分区表,则分区值是子文件夹,可以直接在 M/R Job 里使用这些数据。
Hive 系统架构:?
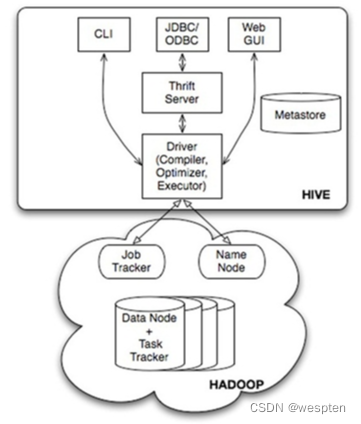
1)用户接口主要有三个:CLI、JDBC/ODBC 和 WebUI
- CL:即 Shell 命令行。
- JDBC/ODBC:Hive 的 Java,与使用传统数据库 JDBC 的方式类似。
- WebGUI:通过浏览器访问 Hive。
2)Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等。metastore 默认使用内嵌的 derby 数据库作为存储引擎 。
- Derby 引擎的缺点:一次只能打开一个会话 ;在不同目录执行能打开多个会话,但已不是同个库。
- 使用 Mysql 作为外置存储引擎,则可多用户同时访问。
3)解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(Plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
4)Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(但包含 * 的查询,比如 select * from table 则不会生成 MapRedcue 任务)。
三、Hive配置管理
1. Hive 安装配置
- 上传并解压 tar 包:tar -zxvf hive-0.9.0.tar.gz -C /cloud/
- 配置 mysql metastore(切换到 root 用户),以及 HIVE_HOME 环境变量
- 自动读取环境变量 HADOOP_HOME
- cp hive-default.xml.template hive-site.xml
- 修改 hive-site.xml(删除所有内容,只留一个 <property></property>),添加如下内容:
<property>
? ? ? <name>javax.jdo.option.ConnectionURL</name>
? ? ? <value>jdbc:mysql://itcast04:3306/hive?createDatabaseIfNotExist=true</value>
? ? ? <description>JDBC connect string for a JDBC metastore</description>
? ? </property>
? ? <property>
? ? ? <name>javax.jdo.option.ConnectionDriverName</name>
? ? ? <value>com.mysql.jdbc.Driver</value>
? ? ? <description>Driver class name for a JDBC metastore</description>
? ? </property>
? ? <property>
? ? ? <name>javax.jdo.option.ConnectionUserName</name>
? ? ? <value>root</value>
? ? ? <description>username to use against metastore database</description>
? ? </property>
? ? <property>
? ? ? <name>javax.jdo.option.ConnectionPassword</name>
? ? ? <value>123</value>
? ? ? <description>password to use against metastore database</description>
? ? </property>2. Mysql 配置
安装 hive 和 mysq 完成后,将 mysql 的连接 jar 包拷贝到 $HIVE_HOME/lib 目录下。
如果出现没有权限的问题,在 mysql 进行授权(在安装 mysql 的机器上执行):
mysql -uroot -p
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;
-- *.* 表示所有库下的所有表
-- % 表示任何IP地址或主机都可以连接
FLUSH PRIVILEGES;3. Hive 运行模式
Hive 的运行模式即任务的执行环境,分为本地与集群两种。
我们可以通过 mapred.job.tracker 来指明。设置方式如下:
hive > SET mapred.job.tracker=local
4.?Hive 启动方式
命令行模式
- 直接输入 /hive/bin/hive?的执行程序,或者输入:hive --service cli
web 界面
- hive web 界面的 (端口号 9999) 启动方式:hive --service hwi &
- 用于通过浏览器来访问 hive :http://hadoop0:9999/hwi/
远程服务
- hive 远程服务 (端口号10000) 启动方式:hive --service hiveserver &
四、Hive 数据类型及表结构
1. 数据类型
基本数据类型:
- tinyint/smallint/int/bigint
- float/double
- boolean
- string
复杂数据类型:
- Array/Map/Struct
- 没有 date/datetime
2. 数据存储
- Hive 的数据存储基于 Hadoop HDFS。
- Hive 没有专门的数据存储格式。
- 存储结构主要包括:数据库、文件、表、视图。
- Hive 默认直接加载文本文件(TextFile),还支持 Sequence file、RC file。
- 创建表时,指定 Hive 数据的列分隔符与行分隔符,Hive 即可解析数据。
3. 数据库
- Hive 类似传统数据库的 DataBase,默认数据库“default”。
- 使用 hive 命令后,若不使用 hive>use <数据库名>,则使用系统默认的数据库。可以显式使用 hive> use default;
- 创建一个新库:hive> create database test_dw;
4. 数据表
- Table:内部表
- Partition:分区表
- External Table:外部表
- Bucket Table:桶表
1)内部表
- 与数据库中的 Table 在概念上是类似的。
- 每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路径为:/warehouse/test。warehouse 是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录。
- 所有的 Table 数据(不包括 External Table)都保存在这个目录中。
- 删除表时,元数据与数据都会被删除。
示例:加载数据文件 inner_table.txt。
-- 创建表
create table inner_table (key string);
-- 加载本机的数据
load data local inpath '/root/inner_table.txt' into table inner_table;
-- 查看数据
select * from inner_table;
select count(*) from inner_table;
-- 删除表
drop table inner_table;2)分区表
Partition 对应于数据库的 Partition 列的密集索引。
在 Hive 中,表中的一个 Partition 对应于表下的一个子目录,所有的 Partition 的数据都存储在对应的目录中。例如:test 表中包含 date 和 city 两个 Partition,则:
- 对应于 date=20130201, city = bj 的 HDFS 子目录为:/warehouse/test/date=20130201/city=bj
- 对应于 date=20130202, city=sh 的HDFS 子目录为:/warehouse/test/date=20130202/city=sh
示例:分区表的建表语句。
CREATE TABLE tmp_table -- 表名
(
?title? ?string, -- 字段名称 字段类型
?minimum_bid? ? ?double,
?quantity? ? ? ? bigint,
?have_invoice? ? bigint
)
COMMENT '注释:XXX' -- 表注释
PARTITIONED BY(pt STRING) -- 分区表字段(如果文件非常之大,采用分区表可以快过滤出按分区字段划分的数据),且分区不能是已存在的字段,否则会报错。
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001'? ?-- 字段是用什么分割开的
STORED AS SEQUENCEFILE; -- 用哪种方式存储数据,SEQUENCEFILE是hadoop自带的文件压缩格式示例:加载数据文件 partition_table.dat。
-- 创建分区表
create table partition_table(rectime string, msisdn string) partitioned by(daytime string, city string) row format delimited fields terminated by '\t' stored as TEXTFILE;
-- 加载数据到分区
load data local inpath'/home/partition_table.dat' into table partition_table partition (daytime='2013-02-01', city='bj');
-- 查看数据
select * from partition_table;
select count(*) from partition_table;
-- 删除表?
drop table partition_table;
-- 增加分区
alter table partition_table add partition (daytime='2013-02-04',city='bj');
-- 删除分区
alter table partition_table drop partition (daytime='2013-02-04',city='bj');
-- 元数据,数据文件删除,但目录daytime=2013-02-04还在3)外部表
- 外部表指向已经在 HDFS 中存在的数据,可以创建 Partition。
- 它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
- 内部表的创建过程和数据加载过程可以在同一个语句中完成。在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
- 外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接。
示例:创建数据文件 external_table.dat。
-- 创建表
create external table external_table1 (key string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/home/external';
-- 在HDFS创建目录/home/external
-- hadoop fs -put /home/external_table.dat /home/external
-- 在hive中也可直接操作hdfs
-- hive> dfs -put?/home/external_table.dat /home/external
-- 加载数据
LOAD DATA INPATH '/home/external_table1.dat' INTO TABLE external_table1;
-- 查看数据
select * from external_table;
select count(*) from external_table;
-- 删除表
drop table external_table;五、HQL
1. HQL 基础语法
进入 Hive 中直接执行 hql:
-- 查看表
SHOW TABLES; ?-- 查看所有的表
SHOW TABLES '*TMP*'; ?-- 支持模糊查询
SHOW PARTITIONS TMP_TABLE; ?-- 查看表有哪些分区
DESCRIBE TMP_TABLE; ?-- 查看表结构
-- 查看数据
select * from partition_table;
select count(*) from partition_table;Hive 命令执行 hql:
-- 执行hql
hive -f /home/arch02/hive_create_object.hql;
hive -S -hivevar hv_date="201701" -f /opt/mcb/web/lib/hql/BI_DWD_CDR_ANALYSIS_MONTH.hql;
-- 查看创建了哪些表
hive -e “show tables”;
-- 查看某个表的表结构
hive -e “describe table_name”
-- 删除分区
hive -e "ALTER TABLE BI_DWD_CDR_ANALYSIS_DAY DROP PARTITION(pt='20170101')";
-- 删除分区文件:
hadoop fs -rm -r /user/hive/warehouse/BI_DWD_CDR_ANALYSIS_DAY/pt=20170101;
创建分区:
hive -S -e "ALTER TABLE BI_DWD_CDR_ANALYSIS_DAY ADD PARTITION(pt='20170101') LOCATION '/user/hive/warehouse/BI_DWD_CDR_ANALYSIS_DAY/pt=20170101'";Hive 生成数据文件:
-- 1)在 Hive 中执行
INSERT OVERWRITE DIRECTORY '/user/arch/BI_DW_RTS_GLOBAL_D_20170101' select * from BI_DW_RTS_GLOBAL_D a where pt='20170101';
-- 2)查看文件是否成功生成
hadoop fs -ls /user/arch/2. 数据导入与加载
注意:
- 表格式 orcfile 表示压缩格式,可以节约大量存储空间,但 orc 还有个特点就是不能直接 load 数据。要想 load 数据,我们要建一个存储格式为 textfile 的中间表,再把数据抽取过去。
- 导入的文本数据不需要带标题行。
1)从本地文件导入数据
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
-
- overwrite:可选,先删除原来表数据,然后再加载新数据。
- partition:这里是指将inpath中的所有数据加载到那个分区,并不会判断待加载的数据中每一条记录属于哪个分区。
local:
- 可选,从本地文件系统中加载,而非 hdfs。load data [local] inpath,是一个服务器端的指令,它是在服务器端执行。因此指定 local 时表明加载的文件为本地文件,但是这里的 local,在 hive 中指的是 hiveserver 服务所在的机器,而不是 hivecli 或 beeline 客户端所在的机器(生产环境大都是 hiveserver 和 hivecli 不在同一个机器)。
- 解决方法一:把要加载的文件上传到 hiveserver 所在的服务器(这一般是不可能的事情),然后执行 load data local inpath [path] [overwrite] into table table_name.
- 解决方法二(推荐):先将本地文件上传至 hdfs,然后使用 load data inpath [hdfspath] [overwrite] into table table_name.
- 注意:load 完了之后,会自动把 INPATH 下面的源数据删掉,其实就是将 INPATH 下面的数据移动到 /usr/hive/warehouse 目录下了。
两种方式验证数据是否导入成功:
- 在 Hive 中执行查询语句。
- 查看 hdfs 文件系统中的 load_data_local 目录下面是否有刚刚上传的 load_data_local.txt 文件,查看命令为:hadoop fs -ls /usr/hive/warehouse/bigdata17.db/load_data_local。
2)从 HDFS 导入数据
将本地 txt 格式数据文件上传到服务器任意目录下,并在该目录下使用命令将文件上传到 HDFS 目录中:
hdfs dfs -put user_day.txt /tmp
查询是否上传成功:
hdfs dfs -ls /tmp
在Hive中执行导入命令:
LOAD DATA INPATH '/user/wangjs/user_day.txt' OVERWRITE INTO TABLE bdp_dw.dw_user_day_zxp;
注意:从 hdfs 文件系统导入数据成功后,会把 hdfs 文件系统中的 load_data_hdfs.txt 文件删除掉。
3)从其它 Hive 表中导入数据
insert into table load_data_local2 select * from load_data_local;
导入数据到分区表分为静态方式和动态方式两种方式。
- 静态方式
必须显式的指定分区值,如果分区有很多值,则必须执行多条 SQL,效率低下。
insert into table load_data_partition partition(age=25) select name from load_data_local;
-- 若要覆盖原有数据,则将 into 改成 overwrite- 动态方式
这种方式要注意目标表的字段必须和 select 查询语句字段的顺序和类型一致,特别是分区字段的类型要一致,否则会报错。
首先,启动动态分区功能:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;若一张表有两个以上的分区字段,如果同时使用静态分区和动态分区导入数据,静态分区字段必须写在动态分区字段之前。
insert overwrite table par_dnm partition(sex='man', dt) select name, nation, dt from par_tab;实现 sex 为静态分区,dt 为动态分区(不指定到底是哪日,让系统自己分配决定)。
- 将数据插入多个表
Hive 还支持一条 sql 语句中将数据插入多个表的功能,只需将 from 关键字前置即可。
from load_data_local
insert overwrite table load_data_partition partition (age)
select name, age
insert overwrite table load_data_local3
select *
;上面的 sql 语句同时插入到表 load_data_partition 和 load_data_local3 表中。这种方式非常高效,对于大数据量并且要将数据插入到多个表的情况下,建议用这种方式。
4)创建表的同时导入数据
create table load_data_local3 as select * from load_data_local;
新建的 load_data_local3 表没有分区,因此 create ... as 不能用来复制分区表。
5)将表数据导出成文本文件
hive -e 'select * from irbas.dw_user_day;' > dw_user_day.txt
3. 日期格式转换
在解析数据时会遇到两种不同的日期格式:yyyymmdd 和 yyyy-mm-dd,此类型之间的转换主要有两种思路。
第一种方法:from_unixtime + unix_timestamp 。
--20180905 转成 2018-09-05
select from_unixtime(unix_timestamp('20180905','yyyymmdd'),'yyyy-mm-dd')
from dw.ceshi_data;
--结果:2018-09-05
--2018-09-05 转成 20180905
select from_unixtime(unix_timestamp('2018-09-05','yyyy-mm-dd'),'yyyymmdd')
from dw.ceshi_data;
--结果:20180905第二种方法:substr + concat 。
--20180905 转成 2018-09-05
select concat(substr('20180905',1,4),'-',substr('20180905',5,2),'-',substr('20180905',7,2)) from dw.ceshi_data
--结果:2018-09-05
--2018-09-05 转成 20180905
select concat(substr('2018-09-05',1,4),substr('2018-09-05',6,2),substr('2018-09-05',9,2)) from dw.ceshi_data
--结果:20180905六、Beeline
Beeline 是 Hive 2 新的命令行客户端工具(Hive 0.11 版本引入),它是基于 SQLLine CLI 的 JDBC 客户端。
Hive 客户端工具后续将使用 Beeline?替代 HiveCLI?,并且后续版本也会废弃掉 HiveCLI?客户端工具。
Beeline 支持嵌入模式(embedded mode)和远程模式(remote mode)。:
- 在嵌入式模式下,运行嵌入式的 Hive(类似 Hive CLI);
- 而远程模式可以通过 Thrift 连接到独立的 HiveServer2 进程上。
从 Hive 0.14 版本开始,Beeline 使用 HiveServer2 工作时,它也会从 HiveServer2 输出日志信息到 STDERR。
1. 常用参数
The Beeline CLI 支持以下命令行参数:
- --autoCommit=[true/false]:进入一个自动提交模式。如 beeline --autoCommit=true
- --autosave=[true/false]:进入一个自动保存模式。如 beeline --autosave=true
- --color=[true/false]:显示用到的颜色。如 beeline --color=true
- --delimiterForDSV= DELIMITER:分隔值输出格式的分隔符。默认是“|”字符。
- --fastConnect=[true/false] :在连接时,跳过组建表等对象。如 beeline --fastConnect=false
- --force=[true/false]:是否强制运行脚本。如 beeline--force=true
- --headerInterval=ROWS:输出的表间隔格式,默认是100。如 beeline --headerInterval=50
- --help:帮助:beeline --help
- --hiveconf property=value :设置属性值,以防被 hive.conf.restricted.list 重置。如 beeline --hiveconf prop1=value1
- --hivevar name=value:设置变量名。如 beeline --hivevar var1=value1
- --incremental=[true/false] :输出增量
- --isolation=LEVEL:设置事务隔离级别。如 beeline --isolation=TRANSACTION_SERIALIZABLE
- --maxColumnWidth=MAXCOLWIDTH:设置字符串列的最大宽度。如 beeline --maxColumnWidth=25
- --maxWidth=MAXWIDTH:设置截断数据的最大宽度。如 beeline --maxWidth=150
- --nullemptystring=[true/false]:打印空字符串。如 beeline --nullemptystring=false
- --numberFormat=[pattern]:数字使用DecimalFormat。如 beeline --numberFormat="#,###,##0.00"
- --outputformat=[table/vertical/csv/tsv/dsv/csv2/tsv2]:输出格式。如 beeline --outputformat=tsv
- --showHeader=[true/false]:显示查询结果的列名。如 beeline --showHeader=false
- --showNestedErrs=[true/false]:显示嵌套错误。如 beeline --showNestedErrs=true
- --showWarnings=[true/false]:显示警告。如 beeline --showWarnings=true
- --silent=[true/false]:减少显示的信息量。如 beeline --silent=true
- --truncateTable=[true/false]:是否在客户端截断表的列。
- --verbose=[true/false]:显示详细错误信息和调试信息。如 beeline --verbose=true
- -d <driver class>:使用一个驱动类。如 beeline -d driver_class
- -e <query>:使用一个查询语句。如 beeline -e "query_string"
- -f <file>:加载一个文件。如 beeline -f filepath;多个文件则用 -e file1 -e file2
- -n <username>:加载一个用户名。如 beeline -n valid_user
- -p <password>:加载一个密码。如 beeline -p valid_password
- -u <database URL>:加载一个 JDBC 连接字符串。如 beeline -u db_URL
参数说明:
这里比较相近的两个参数是 -i 与 -f,其中这两个参数的主要区别从字面上就可以很好的区分了:
- -f 执行 SQL 文件后就直接退出 Beeline 客户端,一般编写需要执行的 HQL。
- -i? 执行 SQL 文件后进入 Beeline 客户端。一般为初始化的参数设置 hive 中的变量。
2. 使用示例
beeline 的用法与 hive-cli 用法基本相同。
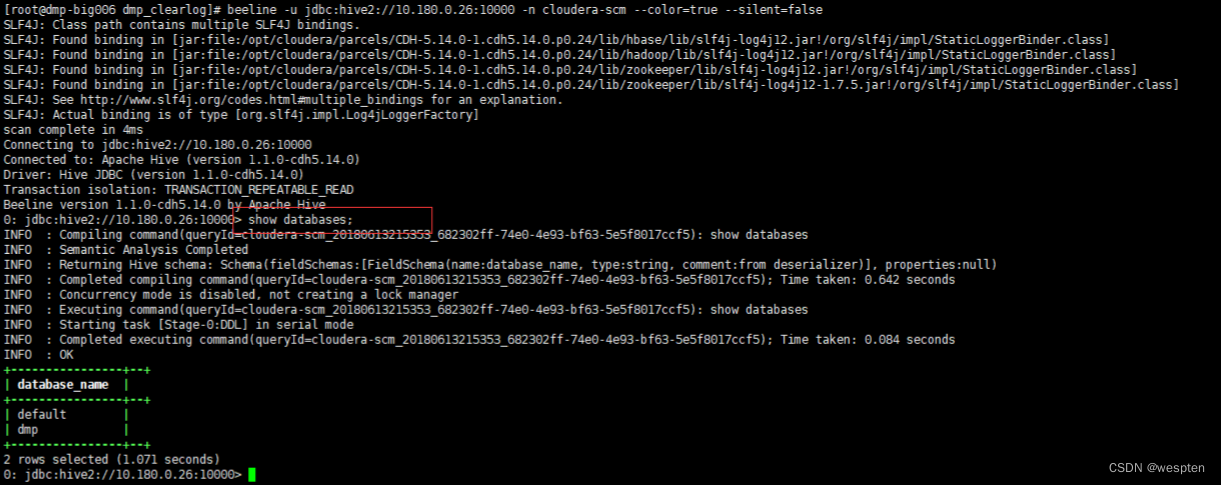
方式一:以 cloudera-scm 的身份 以jdbc 的方式连接远程的 hiveserver2。
beeline -u jdbc:hive2://10.180.0.26:10000 -n cloudera-scm
方式二:类似 hive-cli 的执行脚本功能。
nohup beeline
-u jdbc:hive2://10.180.0.26:10000 -n cloudera-scm
--color=true --silent=false
--hivevar p_date=${partitionDate} --hivevar f_date=${fileLocDate}
-f hdfs_add_partition_dmp_clearlog.hql >> $logdir/load_${curDate}.log通过 jdbc 连接到 beeline 后,就可以对 hive 进行操作了。