配置Hadoop集群
在master虚拟机上配置hadoop
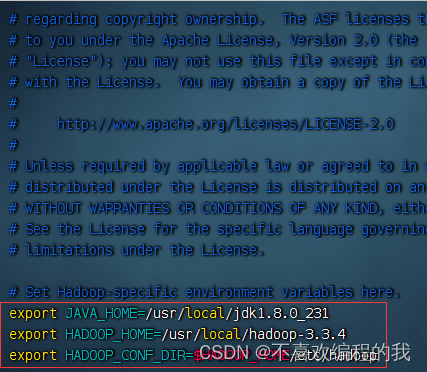
编辑Hadoop环境配置文件 - hadoop-env.sh
命令:cd $HADOOP_HOME/etc/hadoop,进入hadoop配置目录
命令:vim hadoop-env.sh
命令source hadoop-env.sh,让配置生效


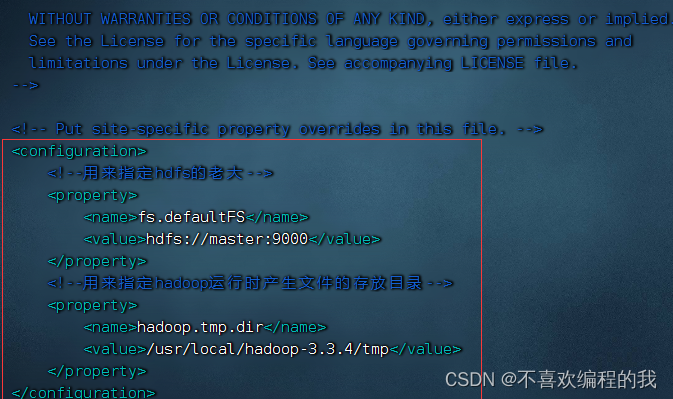
编辑Hadoop核心配置文件 - core-site.xml
命令:vim core-site.xml
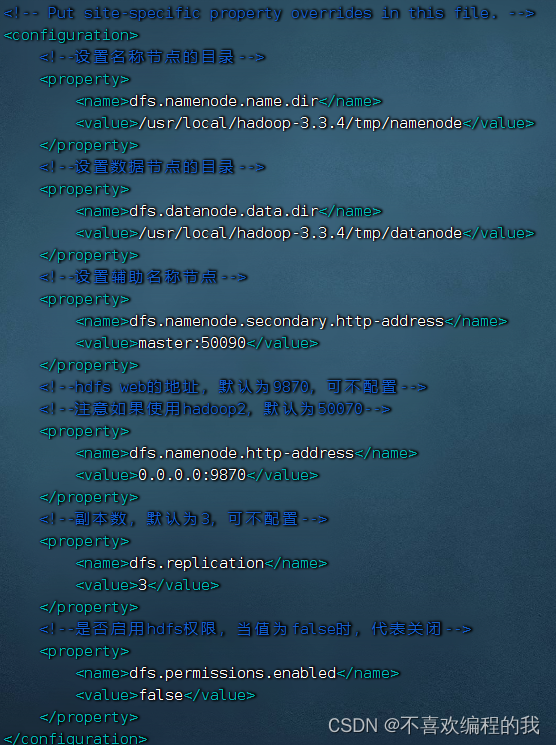
编辑HDFS配置文件 - hdfs-site.xml
命令:vim hdfs-site.xml
编辑MapReduce配置文件 - mapred-site.xml
命令:vim mapred-site.xml

编辑yarn配置文件 - yarn-site.xml
命令:vim yarn-site.xml

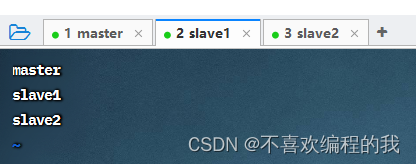
编辑workers文件确定数据节点
执行命令:vim workers
在slave1虚拟机上安装配置hadoop
将master虚拟机上的hadoop分发到slave1虚拟机

将master虚拟机上环境配置文件分发到slave1虚拟机
命令:scp /etc/profile root@slave1:/etc/profile

在slave1虚拟机上让环境配置生效
切换到slave1虚拟机
命令:source /etc/profile
在slave2虚拟机上安装配置hadoop
将master虚拟机上的hadoop分发到slave2虚拟机

将master虚拟机上环境配置文件分发到slave2虚拟机
命令:scp /etc/profile root@slave2:/etc/profile

在slave2虚拟机上让环境配置生效
切换到slave2虚拟机
命令:source /etc/profile

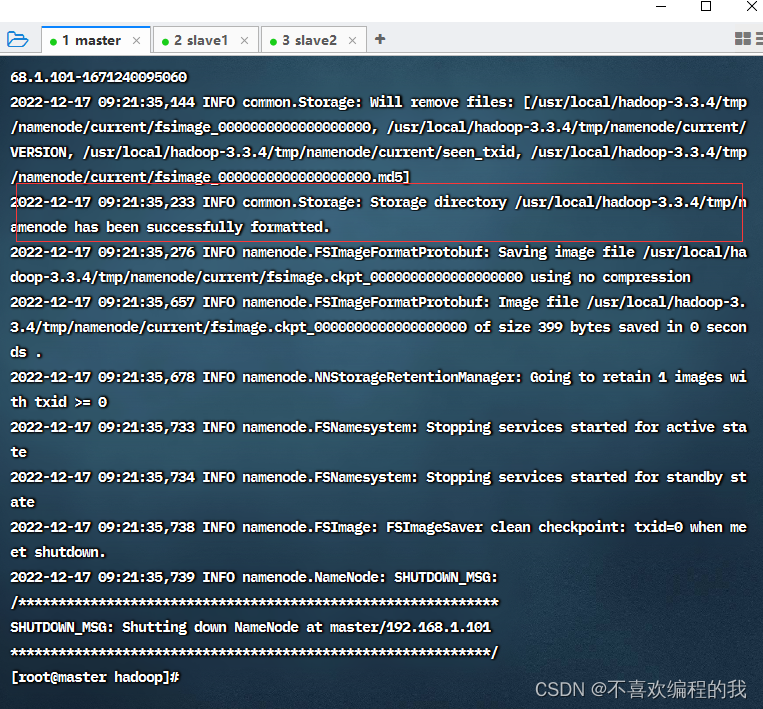
格式化文件系统
初次启动HDFS集群时,必须对主节点进行格式化处理。
命令:hdfs namenode -format
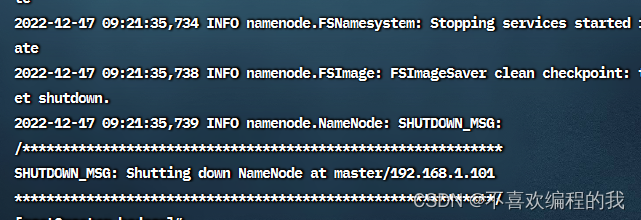
查看名称节点格式化成功的信息
启动和关闭Hadoop集群
start-all.sh命令,一起启动hdfs和yarn服务,也可以分开启动两种服务。
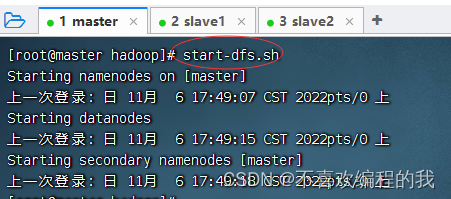
启动hdfs服务
执行命令:start-dfs.sh
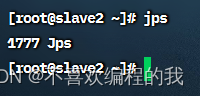
查看虚拟机上的进程


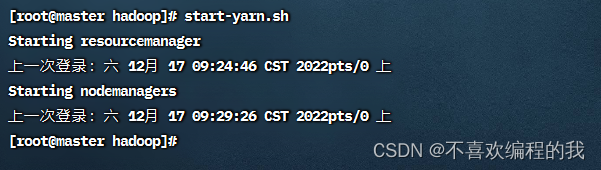
启动yarn服务
命令:start-yarn.sh
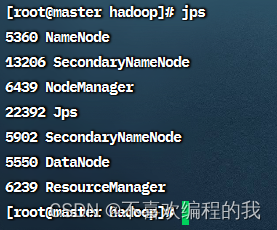
查看master虚拟机的进程
命令jps


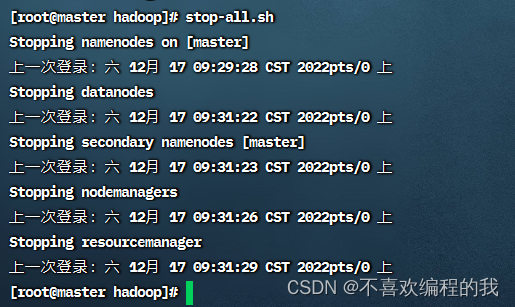
主节点上停止Hadoop集群
命令:stop-all.sh