文章目录
一 DWM层-跳出明细计算
1 需求分析与思路
(1)什么是跳出
跳出: 用户成功访问了网站的一个页面后就退出,不再继续访问网站的其它页面。而跳出率就是用跳出次数除以访问次数。
关注跳出率,可以看出从某几个网站引流过来的访客是否能很快的被吸引,渠道引流过来的用户之间的质量对比,对于应用优化前后跳出率的对比也能看出优化改进的成果。
(2)计算跳出行为的思路
首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来。那么要抓住几个特征:
-
该页面是用户近期访问的第一个页面(新的会话)
这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。
-
首次访问之后很长一段时间(自己设定,一般为30min),用户没继续再有其他页面的访问。
这第一个特征的识别很简单,保留last_page_id为空的就可以了。但是第二个访问的判断,其实有点麻烦,首先这不是用一条数据就能得出结论的,需要组合判断,要用一条存在的数据和不存在的数据进行组合判断。而且要通过一个不存在的数据求得一条存在的数据。更麻烦的它并不是永远不存在,而是在一定时间范围内不存在。那么如何识别有一定失效的组合行为呢?
最简单的办法就是Flink自带的复杂事件处理(CEP)技术。CEP非常适合通过多条数据组合来识别某个事件。
用户跳出事件,本质上就是一个条件事件加一个超时事件的组合。
(3)实现思路
实现思路如下:
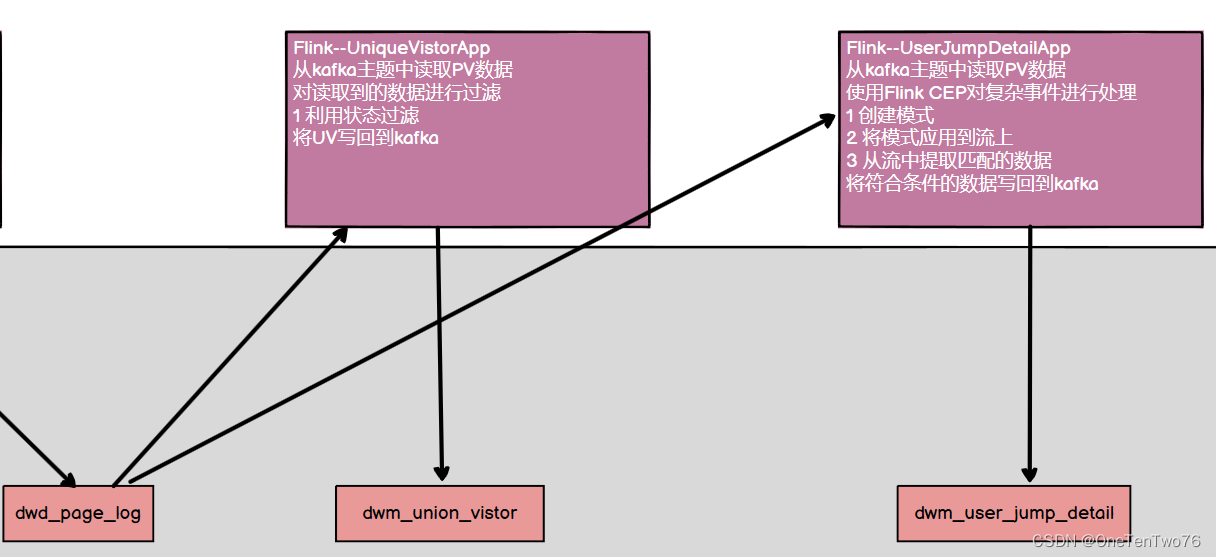
- 从kafka中读取数据。
- 使用CEP对数据进行过滤。
- 该页面是用户近期访问的第一个页面。
- 如果在指定时间内,有当前设备对网站其他页面的访问,说明发生了跳转。
- 反之,则发生了跳出。
- 可以使用within指定匹配的时间;涉及到了时间,flink1.12默认的时间语义就是事件时间语义,需要指定watermark以及提取事件时间字段。
- 使用CEP编程步骤
- 定义pattern
- 将pattern应用到流上
- 从流中按照指定的模式提取数据

2 读取数据
从kafka的dwd_page_log主题中读取页面日志。
(1)代码编写
/**
* 用户跳出明细统计
*/
public class UserJumpDetailAPP {
public static void main(String[] args) throws Exception {
//TODO 1 基本环境准备
//1.1 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.2 设置并行度
env.setParallelism(4);
//TODO 2 检查点设置(略)
//TODO 3 从kafka中读取数据
//3.1 声明消费主题以及消费者组
String topic = "dwd_page_log";
String groupId = "user_jump_detail_app_group";
//3.2 获取kafka消费者对象
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, groupId);
//3.3 读取数据封装流
DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
//TODO 4 对读取的数据进行类型转换 String -> JSONObject
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject);
jsonObjDS.print(">>>");
env.execute();
}
}
(2)测试
启动相关进程,模拟日志生成,查看是否可以正常接收到数据。
3 通过Flink的CEP完成跳出判断
(1)确认添加了CEP的依赖包
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
(2)设定时间语义为事件时间并指定数据中的ts字段为事件时间
由于这里涉及到时间的判断,所以必须设定数据流的EventTime和水位线。这里没有设置延迟时间,实际生产情况可以视乱序情况增加一些延迟。
增加延迟把forMonotonousTimestamps换为forBoundedOutOfOrderness即可。
注意:flink1.12默认的时间语义就是事件时间,所以不需要执行。
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// TODO 5.指定watermark以及提取事件时间字段
SingleOutputStreamOperator<JSONObject> jsonObjWithWatermark = jsonObjDS.assignTimestampsAndWatermarks(
WatermarkStrategy.<JSONObject>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject jsonObj, long recordTimestamp) {
return jsonObj.getLong("ts");
}
}
)
);
(3)根据日志数据的mid进行分组
因为用户的行为都是要基于相同的Mid的行为进行判断,所以要根据Mid进行分组。
// TODO 6 按照mid进行分组
KeyedStream<JSONObject, String> keyedDS = jsonObjWithWatermark.keyBy(jsonObj -> jsonObj.getJSONObject("common").getString("mid"));
(4)配置CEP表达式
跳出 or 跳转的3个条件
- 必须是一个新会话,lastPageId为空
- 访问了其他页面
- 不能超过一定时间
// TODO 7 定义pattern
Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject>begin("first").where(
// 条件1:开启一个新的会话访问
new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObj) throws Exception {
String lastPageId = jsonObj.getJSONObject("page").getString("last_page_id");
if (lastPageId == null || lastPageId.length() == 0) {
return true;
}
return false;
}
}
).next("second").where(
// 条件2:访问了网站的其他页面
new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObj) throws Exception {
String pageId = jsonObj.getJSONObject("page").getString("page_id");
if (pageId != null && pageId.length() > 0) {
return true;
}
return false;
}
}
)
// within方法:定文匹配模式的事件序列出现的最大时间间隔。
// 如果未完成的事件序列超过了这个事件,就会被丢弃:
.within(Time.seconds(10));
(5)根据表达式筛选流
// TODO 8 将pattern应用到流上
PatternStream<JSONObject> patternDS = CEP.pattern(keyedDS, pattern);
(6)提取命中的数据
a 从模式中提取
在获得到一个PatternStream之后,可以应用各种转换来发现事件序列。推荐使用PatternProcessFunction。
PatternProcessFunction有一个processMatch的方法在每找到一个匹配的事件序列时都会被调用。 它按照Map<String, List<IN>>的格式接收一个匹配,映射的键是模式序列中的每个模式的名称,值是被接受的事件列表(IN是输入事件的类型)。 模式的输入事件按照时间戳进行排序。为每个模式返回一个接受的事件列表的原因是当使用循环模式(比如oneToMany()和times())时, 对一个模式会有不止一个事件被接受。
b 处理超时的部分匹配
当一个模式上通过within加上窗口长度后,部分匹配的事件序列就可能因为超过窗口长度而被丢弃。可以使用TimedOutPartialMatchHandler接口 来处理超时的部分匹配。这个接口可以和其它的混合使用。也就是说你可以在自己的PatternProcessFunction里另外实现这个接口。 TimedOutPartialMatchHandler提供了另外的processTimedOutMatch方法,这个方法对每个超时的部分匹配都会调用。
c 便捷的API
前面提到的PatternProcessFunction是在Flink 1.8之后引入的,从那之后推荐使用这个接口来处理匹配到的结果。 用户仍然可以使用像select/flatSelect这样旧格式的API,它们会在内部被转换为PatternProcessFunction。
使用方法:
- 设定超时时间标识 timeoutTag。
- flatSelect方法中,实现PatternFlatTimeoutFunction中的timeout方法。
- 所有out.collect的数据都被打上了超时标记。
- 本身的flatSelect方法因为不需要未超时的数据所以不接受数据。
- 通过SideOutput侧输出流输出超时数据。
// TODO 9 从流中提取数据
//9.1 定义侧输出流标记,FlinkCDC会将超时数据匹配放到侧数据流中
OutputTag<String> timeoutTag = new OutputTag<>("timeoutTag");
// 9.2 提取数据
// patternDS.select(
// timeoutTag,
// new PatternTimeoutFunction<JSONObject, String>() {
// @Override
// public String timeout(Map<String, List<JSONObject>> pattern, long timestamp) throws Exception {
// return null;
// }
// },
// new PatternSelectFunction<JSONObject, String>() {
// @Override
// public String select(Map<String, List<JSONObject>> map) throws Exception {
// return null;
// }
// }
// );
SingleOutputStreamOperator<String> resDS = patternDS.flatSelect(
timeoutTag,
// 处理超时数据 -- 跳出,需要进行统计
new PatternFlatTimeoutFunction<JSONObject, String>() {
@Override
public void timeout(Map<String, List<JSONObject>> pattern, long timestamp, Collector<String> out) throws Exception {
List<JSONObject> jsonObjectList = pattern.get("first");
for (JSONObject jsonObj : jsonObjectList) {
out.collect(jsonObj.toJSONString());
}
}
},
// 处理完全匹配的数据 -- 跳转,不在此需求统计范围之内
new PatternFlatSelectFunction<JSONObject, String>() {
@Override
public void flatSelect(Map<String, List<JSONObject>> map, Collector<String> collector) throws Exception {
}
}
);
// 9.3 从侧输出流中获取超时数据(跳出)
DataStream<String> jumpDS = resDS.getSideOutput(timeoutTag);
jumpDS.print(">>>>");
(7)利用测试数据完成测试
{common:{mid:101},page:{page_id:home},ts:10000} ,
{common:{mid:102},page:{page_id:home},ts:12000},
{common:{mid:102},page:{page_id:good_list,last_page_id:home},ts:15000},
{common:{mid:102},page:{page_id:good_list,last_page_id:detail},ts:30000}
//3.3 读取数据封装流
// DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
DataStream<String> kafkaDS = env
.fromElements(
"{\"common\":{\"mid\":\"101\"},\"page\":{\"page_id\":\"home\"},\"ts\":10000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"home\"},\"ts\":12000}",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"home\"},\"ts\":15000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"detail\"},\"ts\":30000} "
);
输出结果:
>>>>:3> {"common":{"mid":"101"},"page":{"page_id":"home"},"ts":10000}
4 写回kafka
将跳出数据写回到kafka的DWM层。
// TODO 10 将跳出明细写到kafka的dwm层主题
jumpDS.addSink(MyKafkaUtil.getKafkaSink("dwm_user_jump_detail"));
5 测试
将测试数据注释掉,打开kafka数据源。
打开zookeeper、kafka、日志采集服务、kafka消费者、BaseLogApp、UserJumpDetailAPP,查看输出结果。