Phishpedia: A Hybrid Deep Learning Based Approach to Visually Identify Phishing Webpages
使用机器学习方法,利用屏幕截图,检测钓鱼网站。
过去的方法,要么是准确率低,要么是缺乏解释性。该方法在准确率的同时提供了解释性,并且不需要大量的钓鱼网站作为训练集。
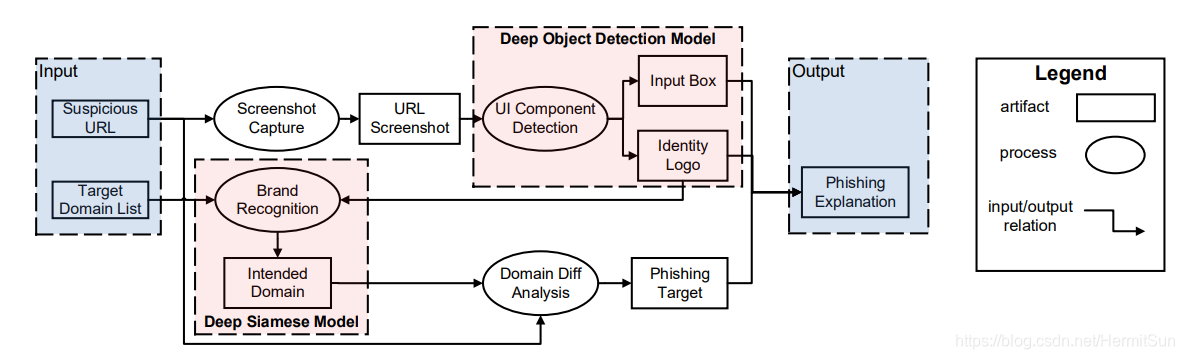
检测分为两步:识别UI组件 + 识别商标brand。识别UI组件第一个是基于HTML,第二个是基于和目标网站的对比,但识别商标是个很麻烦的事,作者认为只需要关注top 100的网站的商标即可,经验研究表明大部分攻击者会选择知名网站来进行高仿。
此外,提供了一个公开的钓鱼网站数据集。
个人认为,因为前人更多关注的是整个截图的相似性,只考虑了图片本身,忽略了其他信息。本文引入了对UI组件本身的check,并且单独分离出了商标作为特征,因而取得了改进效果。但存疑的两个地方是,第一个是只选择商标的一个很小的子集,是否真能起到很好的效果;第二个是仍然需要不小的训练集, 只不过训练集从钓鱼网站本身变成了商标啥的,相当于玩了一个文字游戏,让人以为是无监督(或者半监督)方法。
A Large-Scale Interview Study on Information Security in and Attacks against Small and Medium-sized Enterprises
很少见的经验研究,以调查形式开展。主要是回答了几个关于中小微企业安全现状的问题,得到了一些结论。
- 公司员工往往感觉不到自己被攻击。换言之,风险意识较低。
- 公司的安全措施往往就是防火墙、杀毒软件等等外部防护,内部的安全措施较少。
- 公司一般会受到那种大范围(不是针对特定目标特化的)的攻击,如DDoS。
- 不同行业受到的攻击不同,如能源行业易受CEO欺诈,通信行业易受DDoS。
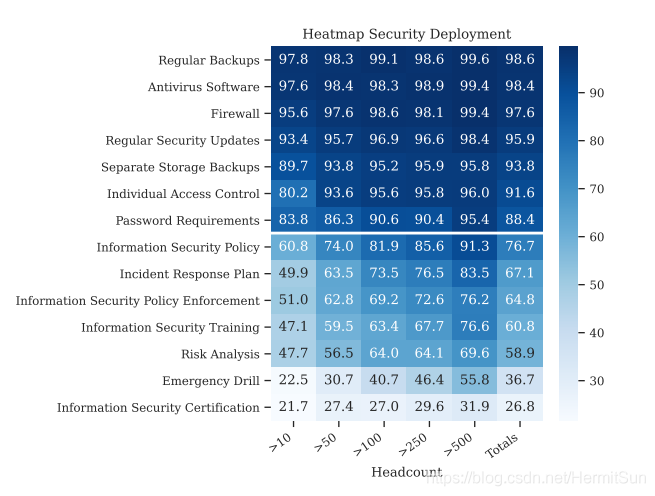
其中关于经验研究的方法很有意思,定量和定性分析都有用到。是一个很正规的调查。
Understanding Malicious Cross-library Data Harvesting on Android
PolyScope: Multi-Policy Access Control Analysis to Compute Authorized Attack Operations in Android Systems
缺乏足够的领域知识,暂时搁置这两篇移动安全相关的文章。