 ?
?
 ?
?
��������:5914��
Ԥ���Ķ�ʱ��:28����
Ϊʲôд��ƪ����
�����Ϊ����Ŀ���õ����ݳ־û�,�������Ǻܼ�����,��������һ��ֱ��SQLite�Ϳ��Խ���ˡ�
����һֱ����ʹ��SQLiteȷʵ����Ҫ�Լ�������ݿ�,����������,���е��Է�������ַ������⡣���Կ���ʹ��iOS��Core Data������
��������һ�����Ϻ�,���ֺܶ���붼�Ѿ��dz¾ɵ��ˡ�����ƻ���ٷ��ĵ��ṩ�Ĵ���������δ�������µ�Swift�汾�������������Լ�дһƪ����������һ��˼·���뷨�������������˿��ٵ�����,����Ҫ֪����Ȼ,��Ҫ֪������Ƶ�����Ȼ,�����������Ÿ�����Ӧ�֡�
ʲô��Core Data
����дapp�϶�Ҫ�õ����ݳ־û�,˵����,���ǰ����ݱ�������,app��ɾ���Ļ����Լ�����д��
iOS�ṩ���ݳ־û��ķ����кܶ�,���������ض���;��
����ܶ�����֪��UserDefaults,��ʱ�������������Ӧ��������Ϣ;��NSKeyedArchiver���Ѵ����еĶ���Ϊ�ļ�,����������¶�ȡ��
����и����õı��淽ʽ�����Լ������ļ�,ֱ���ڴ����ļ��н��ж�д��
�����������ӵ�ҵ������,�����ղؼ�,�û���д�Ķ�������,SQLite���Ǹ����ʵķ����ˡ��������ݿ��֪ʶ,������Ͳ�����,���е㼼��������ͯЬ������
Core Data��SQLite���˸���һ���ķ�װ,SQLite�ṩ�����ݵĴ洢ģ��,���ṩ��һϵ��API,�����ͨ��API��д���ݿ�,ȥ������Ҫ���������ݡ�����SQLite�洢�����ݺ����д�����е�����(����һ����Ķ���)��û�����õ���ϵ,�������Լ���д����ȥһһ��Ӧ��
��Core Dataȴ���Խ��һ�������ڳ־û���ʹ�����һһ��Ӧ��ϵ��Ҳ����˵,�㴦��һ����������ݺ�,ͨ������ӿ�,�������Զ�ͬ�����־û�����,������Ҫ��ȥʵ�ֶ���Ĵ��롣
���� ������־û� ������ �������ϵӳ��(Ӣ�ļ��ORM)��
�����������Ҫ������,Core Data���ṩ�˺ܶ����õ�����,����ع�����,����У��ȡ�

ͼ1: Core Data��Ӧ��,���̴洢�Ĺ�ϵ
����ģ���ļ� - Data Model
��������Core Dataʱ,������Ҫһ�������������ģ�͵ĵط�,����ģ���ļ���������Ҫ�������ļ����͡����ĺ���.xcdatamodeld��ֻҪ����Ŀ��ѡ �½��ļ���Data Model ���ɴ�����
Ĭ��ϵͳ�ṩ������Ϊ Model.xcdatamodeld ����������Ȼ�� Model.xcdatamodeld ��Ϊ�������ļ�����
����ļ����൱�����ݿ��еġ��⡱��ͨ���༭����ļ�,�Ϳ���ȥ���Ӷ����Լ���Ҫ�������������͡�
����ģ���еġ����� - Entity
����xcode�е��Model.xcdatamodeldʱ,�ῴ��ƻ���ṩ�ı༭��ͼ,�����и���Ŀ�İ�ťAdd Entity��
ʲô��Entity��?���ķ���С�ʵ�塱,����������Ͳ������ø��ַ�����������������Ѷ��ˡ�
���������ģ���ļ��������ݿ��еġ��⡱,��ôEntity���൱�ڿ���ġ�������ô����ͼ��ˡ�Entity�������㶨�����ݱ������͵����ʡ�
�������������ģ�����������ͼ�����Ϣ��,��ô����Ȼ��,�һ��뽨��һ����Book��Entity��
�����ԡ� - Attributes
������һ����ΪBook��Entityʱ,�ῴ����ͼ������д��Attributes,����֪��,�����Ƕ���һ����ʱ,��ȻҪ��������,��ı������Ϣ���ⲿ����Ϣ��Attributes,��������ԡ�
Book��Entity:
| ������ | ���� |
|---|---|
| name | String |
| isbm | String |
| page | Integer32 |
����,���Ͳ��ִ��Ǵ����֪��Ԫ��������,�������в��ġ�
ͬ��,Ҳ����������һ������:Reader��Entity������
Reader��Entity:
| ������ | ���� |
|---|---|
| name | String |
| idCard | String |

ͼ2: ����Ŀ�д�������ģ���ļ�
����ϵ�� - Relationship
������ʹ��Entity�༭ʱ,���˿�����Attributesһ��,������������Relationshipsһ��,��������ʲô��?
�ص���������,������ͼ�����Ϣʱ,���鼮�Ͷ��ߵ���Ϣ,����������Ϣ�˴��ǹ�����,����ʵ�����Ǵ�������ϵ��
����һ����,����ij�����߽�����,���������ݸ���ô�洢?
ֱ�۵��������ٶ���һ�ű��������������ϵ������Core Data�ṩ�˸���Ч�İ취 - Relationship��
��Relationship��˼·��˼��,��һ����A��ij������B����,���ǿ�������Ϊ�Ȿ��A��ǰ�ġ������ߡ��Ǹö���B,������B�ġ������顱��A��
�������������Կ���,Relationship�������Ĺ�ϵ��˫���,��A��B������ij�ַ�ʽ�γ�����ϵ,�������ʽ������������ġ�
��Reader��Relationship�µ��+�ż���Ȼ����Relationship������������borrow,��ʾ���ߺ���Ĺ�ϵ�ǡ����ġ�,��Destination��ѡ��Book,����,���ߺ��鼮�Ĺ�ϵ��ȷ���ˡ�
���ڵ�����,Inverse,ȴû�ж���������,����Ϊʲô?
��Ϊ�������ڶ����˶��ߺ���Ĺ�ϵ,ȴû�ж�����Ͷ��ߵĹ�ϵ����ס,��ϵ��˫��ġ�
�ͺñ��㶨����A��B�ĸ���,��ҲҪͬʱȥ����B��A�Ķ���һ���������������������Ǵ�����һ�ߵ���ϵ��
���������,���ǿ�ʼѡ��Book��һ��,��Relationship�������µ�borrowBy,Destination��Reader,��ʱ����Inverseһ��,�ᷢ�ֵ�����borrow,ֱ�ӵ��ϡ�
������Ϊ�����ڶ���Book��Relationship֮ǰ,�����Ѿ�������Reader��Relationship��,���Ե����Ѿ�֪���˶��ߺ��鼮�Ĺ�ϵ,����ֱ��ѡ�ϡ���һ��ѡ����,��ô��Reader��Relationship��,���ǻᷢ��Inverseһ�����Զ�����ΪborrowBy����Ϊ������ʱ���Ѿ���ȫ������˫���Ĺ�ϵ,�Զ����˲��롣
��һ��һ���͡�һ�Զࡱ -?
to one��to many
���ǽ���Reader��Book֮�����ϵ��ʱ��,�������ǵ���ϵ��֮�仹©��һ�����ڡ�
����һ���鱻һ�����߽�����,���Ͳ��ܱ���һ�����߽���,����һ�����߽���ʱ,ȴ���Խ�ܶ౾�顣
Ҳ����˵,һ����ֻ�ܶ�Ӧһ������,��һ������ȴ���Զ�Ӧ�౾�顣
����� һ��һ��to one �� һ�Զ��to many ��
Core Data������������������ϵ,��������������RelationShip�������Ӧ�Ĺ�ϵ��,������������Ҳ����Ŀ�С�(��Ŀ���û���ֿ�����xcode���Ͻǵİ�ť����,����������Ŀû����Relationship������,���Զ�������,����xcode��Сbug)��
��Relationship����������,��һ������ΪType,�����������ѡ��,һ����To One(Ĭ��ֵ),��һ������To Many�ˡ�
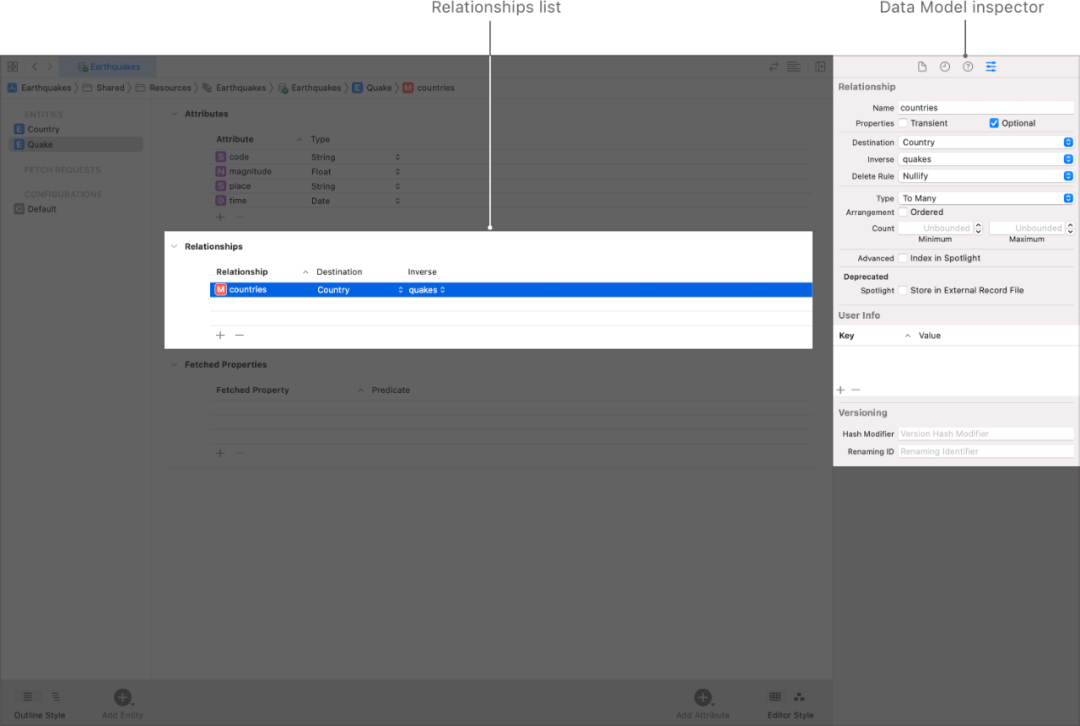
ͼ3: ����ģ�͵Ĺ�ϵ����
Core Data��ܵ����ֿ� -
NSPersistentContainer
������������Core Data������������Ϣ��,���Dz�û�в����κ�����,�ͺñ�ͼ����Ѿ��ƶ���ͼ��Ĺ淶 - һ����Ӧ�������֡�isbm��ҳ������Ϣ,�淶��Ȼ�ƶ���,ȴû����������������
��ô��ô���ܲ����ʹ���������,�����Ҫͨ�������浶��ǹ�ĺ�Core Data���ˡ�
����Core Data�Ĺ��ܽ�Ϊǿ��,����ֳɶ����������������,һ����ѧϰ������Dz�����,��������,���Ժ����һ�ֱ�һһ�г���
Ҫ����Щ��˾��ְ�����,���Dz��ò����һ��Ҫ���ܵ���,��NSPersistentContainer,��Ϊ�����Ǵ���������Ա�ġ��ֿ��ࡱ��
���NSPersistentContainer,��������ͨ�������Core Data���ĵ�һ��Ŀ�ꡣ������ż��������Ǻ�Core Data����ҵ�����Ĺ���,�������õ���Щ����֮��,�Ϳ������ɵķ��������ˡ������������� - Container �̺��ŵ���˼,���� �ֿ⡢��������װ�䡣
������ʽ�Ĵ����д�ĵ�һ��,������Ҫ��ʹ��Core Data��ܵ�swift�ļ���ͷ����������:
import?CoreData
?����,��iOS 10֮ǰ,��û��
NSPersistentContainer�����,����Core Data�ṩ�ļ��ָ�˾��ְ�Ĺ���,���Ƕ�Ҫд����һһ���,д�����Ĵ����Ϊ����,����NSPersistentContainer������һ��ʼ���е�,����ƻ�������������Ż������Ľ�����ơ�

ͼ4: NSPersistentContainer��������Ա�Ĺ�ϵ
NSPersistentContainer��
��ʼ��
���½���UIKIT��Ŀ��,�ҵ����ǵ�AppDelegate��,дһ����Ա����(������,������ֱ���ú�������������):
private?func?createPersistentContainer()?{
????let?container?=?NSPersistentContainer(name:?"Model")
}
����,NSPersistentContainer��Ľ����������,����"Model"�ַ����������ǽ�����Model.xcdatamodeld�ļ����������������ʱ��,���Dz���Ҫ(Ҳ��Ӧ��)����.xcdatamodeld����
�����Ǵ�����NSPersistentContainer����ʱ,��������˻����ij�ʼ��,������һЩ���ܿ����ϴ�ij�ʼ��,���籾�س־û���Դ�ļ��ص�,����û�����,���DZ������NSPersistentContainer�ij�Ա����loadPersistentStores���������
private?func?createPersistentContainer()?{
????let?container?=?NSPersistentContainer(name:?"Model")
????container.loadPersistentStores?{?(description,?error)?in
????????if?let?error?=?error?{
????????????fatalError("Error:?\(error)")
????????}
????????print("Load?stores?success")
????}
}
?�Ӵ�����ƵĽǶȿ�,Ϊʲô
NSPersistentContainer��ֱ���ڹ��캯����������ݿ�ļ���?����漰��һ���������Ŀ���ԭ��,�����캯���ij�ʼ��Ӧ����(ԭ����)������ԭ�Ӽ���,���ġ��Ϳ����ڴ����,���������ܿ������,�ڴ�֮��Ĵ洢�ռ䴦��(�������,����),Ӧ���������ṩ��Ա��������ɡ���������Ϊ�˱����ڹ��캯���г���ʱ�������Բ������⡣
����������Ϣ���ṩ�� -?
NSManagedObjectModel
���������Ѿ����в��ɹ���ʼ����Core Data�IJֿ������NSPersistentContainer��,����ȥ���ǿ���ʹ���������������ȡ��Ϣ��,�����Ѿ���ģ���ļ������˶��ߺ��鼮������Entity��,��λ�ȡ������Entity����Ϣ?
�����Ҫ�õ�NSPersistentContainer�ij�Ա,��managedObjectModel,�ó�Ա���DZ�����˵��NSManagedObjectModel���͡�
Ϊ�˽���NSManagedObjectModel���ṩʲô,��ͨ�����º������ṩ˵��:
private?func?parseEntities(container:?NSPersistentContainer)?{
????let?entities?=?container.managedObjectModel.entities
????print("Entity?count?=?\(entities.count)\n")
????for?entity?in?entities?{
????????print("Entity:?\(entity.name!)")
????????for?property?in?entity.properties?{
????????????print("Property:?\(property.name)")
????????}
????????print("")
????}
}
Ϊ��ִ�������������,��Ҫ��createPersistentContainer,���������parseEntities:
private?func?createPersistentContainer()?{
????let?container?=?NSPersistentContainer(name:?"Model")
????container.loadPersistentStores?{?(description,?error)?in
????????if?let?error?=?error?{
????????????fatalError("Error:?\(error)")
????????}
????????
????????self.parseEntities(container:?container)
????}
}
�����������,����ͨ��NSPersistentContainer�����NSManagedObjectModel���͵ij�ԱmanagedObjectModel,��ͨ����������ļ�Model.xcdatamodeld���������úõ�Entity��Ϣ,��ͼ��Ͷ��ߡ�
������������������Entity��Ϣ,����������ȷ�Ļ�,��ӡ�����ĵ�һ��Ӧ����Entity count = 2��
container�ij�ԱmanagedObjectModel��һ����Ա��entities,����һ������,��������Ա�����ͽ�NSEntityDescription,�������һ����֪����ר����������Entity��ز�����,�����û��Ҫ�����ˡ�
ʾ��������,�����entity�����,��ӡentity������,Ȼ���������,������entityʵ��,���ű���entityʵ����properties����,�������Ա��������NSPropertyDescription�Ķ�����ɡ�
��������Property,���ò�����˵����,ѧϰһ�ż�����˵�����֮һ���������������,�Ͼ���ͬ����֮������������һ��ͳһ,����Ҫ��������һ�¡�
��Core Data�����ﻷ����,һ��Entity��������Ϣ�������,֮ǰ�Ѿ������Entity��Relationship�����ˡ�����Щ��Ϣ������ͳ��Ϊproperty��NSPropertyDescription�����־���֪��,���Ǵ���property�õġ�
ֻҪ����һЩ֪ʶ�����������,����ȥ��ӡ�����ݾͲ��Ѷ���:
Entity?count?=?2
Entity:?Book
Property:?isbm
Property:?name
Property:?page
Property:?borrowedBy
Entity:?Reader
Property:?idCard
Property:?name
Property:?borrow
���ǿ���,��ӡ�����������õ�ͼ����4��property,���һ����borrowedBy,�������Ǹ�Relationship,��ǰ����������Attribute,����Ҹոն�property��˵����һ�µġ�
Entity��Ӧ����
��ƪ���Ǿͽ���,Core Data��һ�� ����-��ϵӳ�� �־û�����,����������Model.xcdatamodeld�Ѿ�����������Entity,��ô����ڴ�����Ҫ��������,�Dz��ǻ��ж�Ӧ����?
����ȷʵ���,�����㻹����Ҫ�Լ�ȥ��������ࡣ
�������Model.xcdatamodeld�༭�����е�Book���Entity,���Ҳ���������,�����������������༭�Ĺ������Entity����Ϣ,����Entity���ֵ�Name���������������Book,���·�����һ��Class��,��һ�����Ǹ�Entity������Ϣ,��Ŀ�е�Name��������Ҫ���������,Ĭ������Entity��������ͬ,Ҳ����˵,����Ҳ��Book�����Ը��벻��,������˼·�Լ��ŶӵĹ淶��
����Entity��Ӧ����,���̳���NSManagedObject��
Ϊ�˼�����һ��,���ǿ����ڴ����б�д��һ����Ϊ����:
var?book:?Book!?//?���������,��ҵ���ֵ
���д����һ�б���ͨ����,��˵�����������Ѿ�������������Book�����,��Ȼ���Ͳ����ܱ���ͨ����
���Խ��,��������ͨ����˵������Ҫ�����Լ���д,�Ϳ���ֱ��ʹ��������ˡ�
?��������,�ٷ��̳���һ������������Ϊ
Entity�� + MO,�����������Entity��ΪBook,��ô����ǰ��չٷ��̵̳�����,����������б༭Class������ΪBookMO,����MO��ž���Model Object�ļ�ưɡ�����������Ϊ������,�Ͳ����κθ�����,
Entity��ΪBook,��ô����Ҳһ��ΪBook��
?����,��Ҳ�����Լ�ȥ����
Entity��Ӧ����,�����и��ô��ǿ��Ը�������һЩ����Ĺ���֧��,�ⲿ��Core Data�ṩ�˱�д�Ĺ淶,���Ǵ�ʱ������������������Ӵ�����,�����ڳ��������
����ҵ��IJ���Ա -?
NSManagedObjectContext
����������Ҫ¡�ؽ���NSPersistentContainer���µ�һ������������صĴ�,��ԱviewContext,����ȥ���Ǻ�ʵ�����ݴ�,������ɾ������Ĵ����,��Ҫͨ�������Ա���ܽ��С�
viewContext��Ա��������NSManagedObjectContext��
NSManagedObjectContext,����˼��,����������ǹ�������������ġ��Ӵ�������,���ĺ����ݵı���,ɾ������,��,��һ��������Ϊ��ڡ�
�ӽ��������Ա��ʼ,���Ǿ���ʽ�� �������� �Ľ�,��ʽ���뵽 �����Ͳ������� �ĽΡ�
���ݵIJ��� -?
NSEntityDescription.
insertNewObject
������ǰ���֪ʶ,�Ϳ�����ʽ̤�����ݴ�����ѧϰ�ˡ�
����,�����ȳ��Դ���һ��ͼ��,��һ��createBook���������С�ʾ����������:
private?func?createBook(container:?NSPersistentContainer,
????????????????????????name:?String,?isbm:?String,?pageCount:?Int)?{
????let?context?=?container.viewContext
????let?book?=?NSEntityDescription.insertNewObject(forEntityName:?"Book",
????????????????????????????????????????????????????into:?context)?as!?Book
????book.name?=?name
????book.isbm?=?isbm
????book.page?=?Int32(pageCount)
????if?context.hasChanges?{
????????do?{
????????????try?context.save()
????????????print("Insert?new?book(\(name))?successful.")
????????}?catch?{
????????????print("\(error)")
????????}
????}
}
�����������,��ֵ�ù�ע�IJ��־���NSEntityDescription�ľ�̬��Ա����insertNewObject��,���Ǿ���ͨ�����������������Ҫ�������ݵĴ���������
insertNewObject��Ӧ�IJ���forEntityName��������Ҫ�����Entity��,������ֵ�Ȼ����������֮ǰ�����õ�Entity�е����ֲ���,����ͳ����ˡ���Ϊ����Ҫ����������,������������־���Book��
��into�����������ǵĴ�����ɾ��ĵĴ�NSManagedObjectContext���͡�
insertNewObject���ص�������NSManagedObject,��ǰ����,��������Entity��Ӧ��ĸ��ࡣ��Ϊ����Ҫ������Entity��Book,�����Ѿ�֪����Ӧ��������Book��,�������ǿ��Է��Ĵİ���ת��ΪBook���͡�
���������ǾͿ��Զ�Bookʵ�����г�Ա��ֵ,���ǿ��Ծ�ϲ�ķ���Book��ij�Ա����������Entity�����б༭�õ�,���Ƿ��㼫�ˡ�
��ô��������,�����ǰ�Book�༭��ɺ�,�Dz���������ݾ�����˳־û���,��ʵ���ǵġ�
����Ҫ��һ��Core Data���������:��ԭ��Core Data���֮��,�κ�ԭ����������ڴ漶�IJ���,�����Զ�ͬ�������̻�������ý����,ֻ�п��������������洢����,�Ż������洢��������ô����Ȼ������Ϊ��ĺ���,���dz������ܿ��ǡ�
Ϊ����İ����ݱ�������,��������ͨ��context(��NSManagedObjectContext��Ա)��hasChanges��Աѯ���Ƿ������иĶ�,����иĶ�,��ִ��context��save������(�ú����Ǹ������쳣�ĺ���,������do��catch��������)��
����,�����鱾�IJ��������д���ˡ����������ǰ����ŵ����ʵĵط����С�
���Ƕ�createPersistentContainer������:
private?func?createPersistentContainer()?{
????let?container?=?NSPersistentContainer(name:?"Model")
????container.loadPersistentStores?{?(description,?error)?in
????????if?let?error?=?error?{
????????????fatalError("Error:?\(error)")
????????}
????????
????????//self.parseEntities(container:?container)
????????self.createBook(container:?container,
????????????????????????name:?"�㷨(��4��)",
????????????????????????isbm:?"9787115293800",
????????????????????????pageCount:?636)
????}
}
������Ŀ,�ῴ�����´�ӡ���:
Insert?new?book(�㷨(��4��))?successful.
����,�鱾�IJ��빤��˳�����!
?��Ϊ���ʾ��û��ȥ���ж�,���������������,��ô�����������������Ϊ"�㷨(��4��)"��
book��¼��
���ݵĻ�ȡ
����ǰ�����֪ʶ���̵�,����ȥ������ֻҪ �Ǻ��� �ͳ���,��ȡ��ʾ������:
private?func?readBooks(container:?NSPersistentContainer)?{
????let?context?=?container.viewContext
????let?fetchBooks?=?NSFetchRequest<Book>(entityName:?"Book")
????do?{
????????let?books?=?try?context.fetch(fetchBooks)
????????print("Books?count?=?\(books.count)")
????????for?book?in?books?{
????????????print("Book?name?=?\(book.name!)")
????????}
????}?catch?{
????????
????}
}
�������ݴ�����Ȼ�����ǵ����ݲ�������context,��������ȡ��������ϸ�����ǽ���һ��ר�ŵ���,NSFetchRequest�����,��Ϊ���Ǵ�����ȡ�����и��ָ���������,����Core Data�����һ������ģʽ,��ֻҪ��NSFetchRequest�����Ӧ������,����Book,����֪��Ӧ�ô���ʲô���͵Ķ�Ӧ����,������,���ǿ���ͨ��Entity��ΪBook������ֱ���õ�Book���͵�����,���Ǻܷ��㡣
��ӡ���:
Books?count?=?1
Book?name?=?�㷨(��4��)
���ݻ�ȡ������ɸѡ -?
NSPredicate
ͨ��NSFetchRequest���ǿ��Ի�ȡ���е�����,�������Ǻܶ�ʱ����Ҫ���ǻ��������Ҫ���ض�������,ͨ������ɸѡ����,����ʵ�ֻ�ȡ��������Ҫ������,��ʱ����Ҫ�õ�NSFetchRequest�ij�Աpredicate�����ɸѡ,������ʾ,����Ҫ�������� �㷨(��4��) ���顣
���µĴ���ʾ����,������֮ǰʵ�ֵ�readBooks����������������:
private?func?readBooks(container:?NSPersistentContainer)?{
????let?context?=?container.viewContext
????let?fetchBooks?=?NSFetchRequest<Book>(entityName:?"Book")
????fetchBooks.predicate?=?NSPredicate(format:?"name?=?\"�㷨(��4��)\"")
????do?{
????????let?books?=?try?context.fetch(fetchBooks)
????????print("Books?count?=?\(books.count)")
????????for?book?in?books?{
????????????print("Book?name?=?\(book.name!)")
????????}
????}?catch?{
????????print("\(error)")
????}
}
ͨ������:
fetchBooks.predicate?=?NSPredicate(format:?"name?=?\"�㷨(��4��)\"")
���Ǵ��鼮��ɸѡ������Ϊ �㷨(��4��) ����,��Ϊ����֮ǰ�Ѿ�������Ȿ��,���Կ�����ȷɸѡ������
ɸѡ������֧�ִ�С�Ա�,��
fetchBooks.predicate?=?NSPredicate(format:?"page?>?100")
������ɸѡ��page��������100���鼮��
���ݵ���
������Ҫ������ʱ,����˵����Ҫ�� isbm = "9787115293800" �Ȿ��������Ϊ �㷨(��5��) ,���������´���ʾ��:
let?context?=?container.viewContext
let?fetchBooks?=?NSFetchRequest<Book>(entityName:?"Book")
fetchBooks.predicate?=?NSPredicate(format:?"isbm?=?\"9787115293800\"")
do?{
????let?books?=?try?context.fetch(fetchBooks)
????if?!books.isEmpty?{
????????books[0].name?=?"�㷨(��5��)"
????????if?context.hasChanges?{
????????????try?context.save()
????????????print("Update?success.")
????????}
????}
}?catch?{
????print("\(error)")
}
�����������,������ѭ�� ��ȡ���ġ����� ��˼·,���õ�ɸѡ���鱾,Ȼ�����鱾������,�����ֱ��ĺ�,context����֪�����ݱ�����,��ʱ���ж������Ƿ���(ʵ���ϲ���Ҫ�ж�����Ҳ֪��������,ֻ�dz��ڱ���淶����������ж�),�������,�ͱ�������,ͨ�������ʽ,�ɹ�������������
���ݵ�ɾ��
���ݵ�ɾ����Ȼ��ѭ ��ȡ���ġ����� ��˼·,�ҵ�������Ҫ��˼·,����ɾ������ɾ���ķ�����ͨ��context��delete������
����������,����ɾ�������� isbm="9787115293800" ���鼮:
let?context?=?container.viewContext
let?fetchBooks?=?NSFetchRequest<Book>(entityName:?"Book")
fetchBooks.predicate?=?NSPredicate(format:?"isbm?=?\"9787115293800\"")
do?{
????let?books?=?try?context.fetch(fetchBooks)
????for?book?in?books?{
????????context.delete(books[0])
????}
????if?context.hasChanges?{
????????try?context.save()
????}
}?catch?{
????print("\(error)")
}
��չ�ͽ�������Ľ���
�������һ�����ߵ�����,��ô����Core Data�Ļ���֪ʶ����˵�Ѿ����յIJ���ˡ���Ȼ��,�ⲿ�ֻ��������ճ������Ѿ����������ˡ�
����Core Data�����Ľ��ײ���,����������о�һ��:
Relationship���ֵĿ���,��ʵ��ͨ��֮ǰ��֪ʶ���Զ�����ɡ��ع�����,�����:
UndoManager��Entity��Fetched Property���ԡ����
contextһ��������ݵij�ͻ���⡣�־û���Ĺ���,����Ǩ���ļ���ַ,���ö���洢Դ�ȡ�
����������ⶼ�����Լ���һ��̽��,������ƪ���µĽ��ⷶΧ�������������ų��ᵥ������̽����
����
Core Data��Ȧ���DZȽϳ������ġ������á��Ŀ��,��Ҫ����Ϊ�����Ĺ��ܺͻ��ƽ�Ϊ���������⡣�����Ѿ�������ȵ�Ŭ����ͼ����ƵĽǶ�ȥ�����ÿ��,ϣ����������������
����
https://developer.apple.com/documentation/coredata


Ҳ���㻹�뿴
(��������±�������鿴)
��ѭ Google Ӧ��ָ�ϵ� Retrofit + Coroutine ��װ

Kaggle TOP1:�����ʱ��Trickֱ��ը��



