
导读:作为短视频应用最重要的组件,播放器扮演了至关重要的角色;对于短视频App来说,播放相关的性能直接影响到核心用户体验,围绕播放器做一系列的优化是性价比极高的技术投资。
全文3680字,预计阅读时间12分钟。
一、背景介绍
作为短视频应用最重要的组件,播放器扮演了至关重要的角色;对于短视频App来说,播放相关的性能直接影响到核心用户体验,围绕播放器做一系列的优化是性价比极高的技术投资。经过持续的重构和优化,好看视频Android端的视频播放体验基本达到秒开效果,瞬间起播,滑动流畅度也明显提高。我们先来看看重构前后的对比。
重构前:很容易观察视频起播前有明显的停顿,中低端机格外明显。
重构后:几乎感受不到播放切换的停顿感。
本次就和大家分享一下好看视频Android端重构中的想法和心得,主要侧重于架构、性能优化方面。
二、好看视频历史回顾――单播放器
好看视频2016年起源于hao123的图文信息流,历经4年,确立了信息流模式的卡尺播放模式。在2020年的Q3,好看视频开启了沉浸式全屏播放项目,最终推全。
由于历史原因,好看视频一直是单播放器架构:全局一个播放器,飘在所有View的最上层,跟随着左右滑动的ViewPager和上下翻页的RecyclerView(竖划翻页配合使用了PagerSnapHelper)同时移动。
mViewPager.addOnPageChangeListener(new ViewPager.OnPageChangeListener() {
@Override
public void onPageScrolled(int position, float positionOffset, int positionOffsetPixels) {
mVideoView.moveVideoViewByX(positionOffsetPixels);
}
}
mRecyclerView.addOnScrollListener(new RecyclerView.OnScrollListener() {
@Override
public void onScrolled(RecyclerView recyclerView, int dx, int dy) {
mVideoView.moveVideoViewByY(dy);
}
});
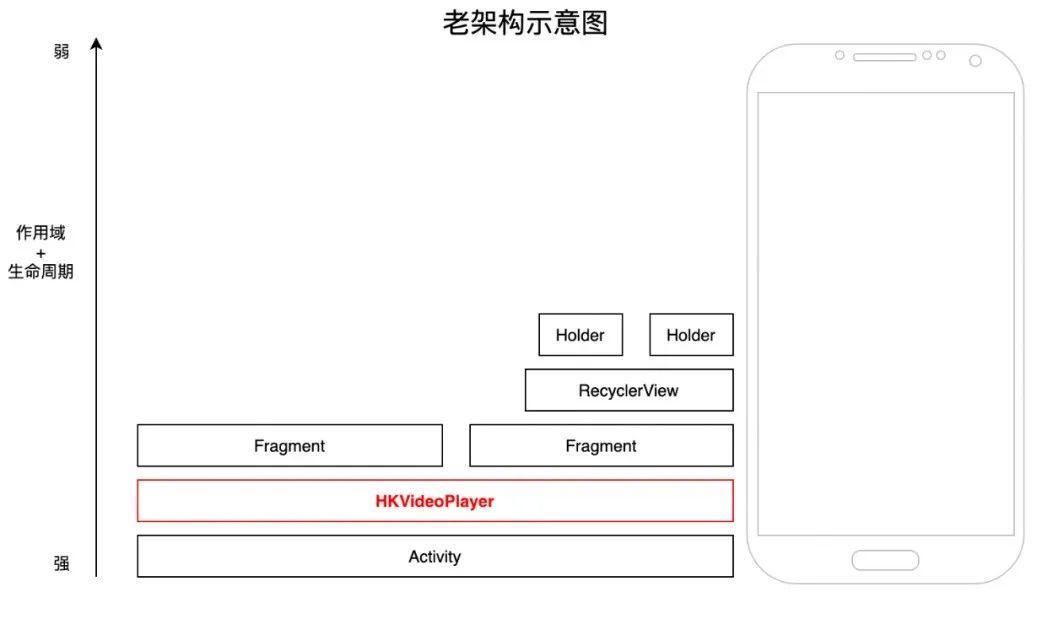
老架构的核心特点是,播放器有极高的生命周期和作用域(和当前Activity一致),且低作用域和生命周期的组件又直接持有Context控制和操作播放器。播放器全局单例虽然逻辑上简单,但实现上并不简约,主要存在几个明显问题
1、业务耦合严重,开发效率低
-
播放器和业务代码耦合严重,多个核心类代码1万+行,维护成本高,对新人极其不友好。播放器在初始化时就有221个View,各个View之间的隐藏和显示逻辑复杂,函数括号嵌套层次非常深,维护成本极高。Feed列表只承载视频封面图,导致广告/直播等第三方业务既要负责holder的展示,又要独立创建高层级的播放器进行控制,代码复杂度极高。
-
播放器状态控制复杂紊乱,从Activity、Fragment、ViewPager、RecyclerView、RecyclerViewAdapter、RecyclerViewHolder、每个View都能直接控制全局的单例播放器,生命周期难以追踪,播放相关的bug和用户反馈定位十分困难。
2、性能问题尾大不掉
- 由于播放器是飘在所有View的最上层,导致某些业务的View如果需要在最顶层,只能放在播放器内部再重新实现一遍。
RecyclerViewHolder中的某些View,既要在holder中又要在播放器的View中,再加上历史的陈旧代码,线上大量出现播放器View初始化时的ANR和卡顿

播放器本身的复杂度又使得性能的优化难度和风险极大,再加上历史原因,这就导致了老架构feed滑动性能很差,滑动卡顿在中端机上十分明显,和竞品差距巨大,以火焰图为例:
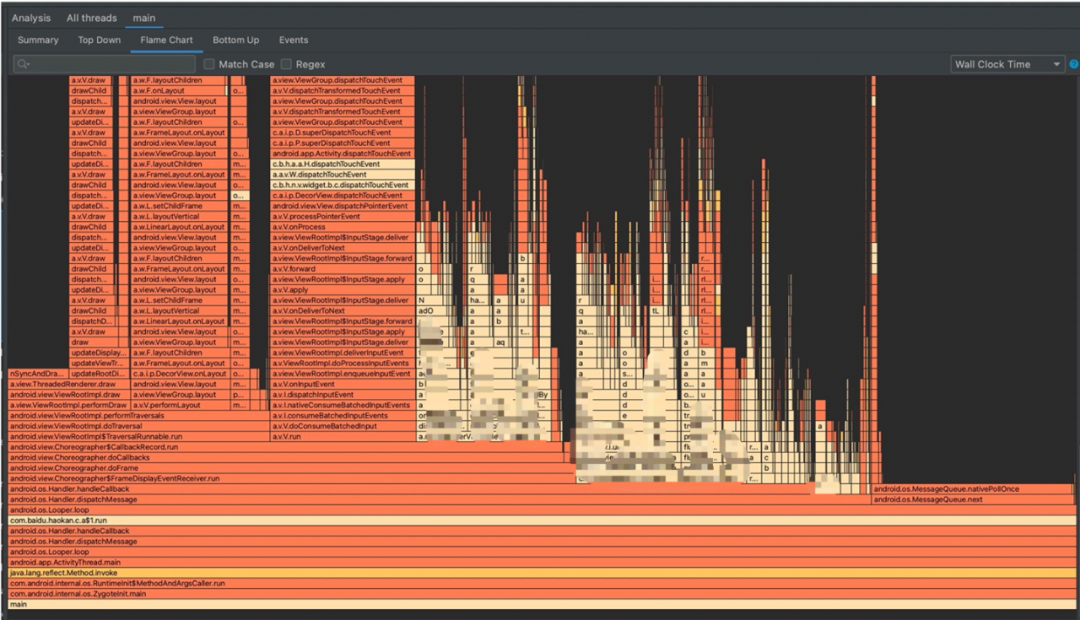
-
Feed列表滑动需要同步播放器进行卡尺滑动(包括播放器复位等),导致启播速度人为劣化。
-
低级别组件需要持有Activity级别的句柄,非常容易产生内存泄漏。
-
无法直接获取Activity句柄的业务,大量通过EventBus分发消息和控制逻辑,导致播放控制混乱(EventBus事件混乱和组件生命周期事件冲突等)。EventBus不仅加剧了内存泄漏的风险,还导致一些列的性能问题。
三、好看视频重构项目――多播放器
不破不立
我们最终决定围绕播放器来对现有代码进行重构,将全局单例的播放器下沉到每个holder中,便于业务隔离和灵活调用播放器。在提高架构合理性从而提升团队开发效率的同时,顺带解决部分性能问题:立项之时,仅仅架构优化可能不足以说服众人,但性能的优化带来的基础体验的优化,不容小觑。可能对于客户端来说,往往是带有性能优化的重构,才是完美的重构。
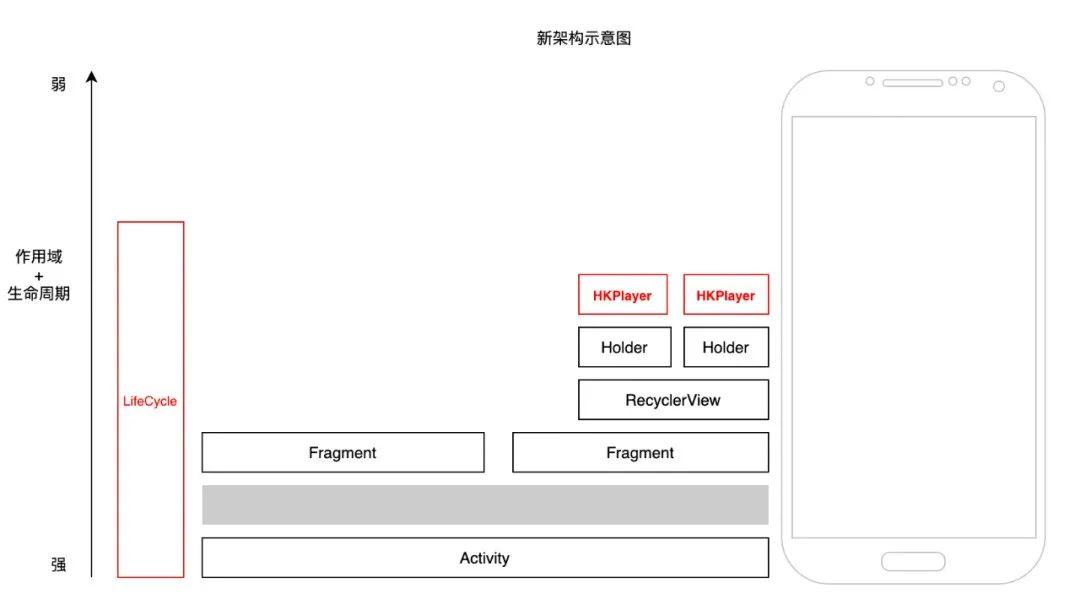
新架构:多播放器实例,每个holder独有播放器,播放器跟随自己的holder滑动;播放器和业务解耦。
新架构的显著特点,就是降低了播放器作用域和生命周期:
-
在holder内实现播放器状态自洽管理,直播/广告等业务仅在holder就可以实现自身业务(包括播放控制等),减少无用逻辑,降低代码耦合。
-
通过LifecycleLite分发播放相关事件,降低对EventBus的依赖,降低组件间耦合和内存泄漏风险。
-
利用自定义PageSnapHelper等组件,集中优化Feed列表启播/预加载等核心播放体验。
”多快好省“,可以说新架构只实现了前三个,但对于客户端来说,刻意”节省内存“不见得是好主意。一个播放器大约占用10M的虚拟内存,大部分情况下App同时存在2-3个播放器实例,以20-30M的”空间“换取”时间“(开发节省的时间+性能提升的时间),看起来就是大赚小亏的买卖。
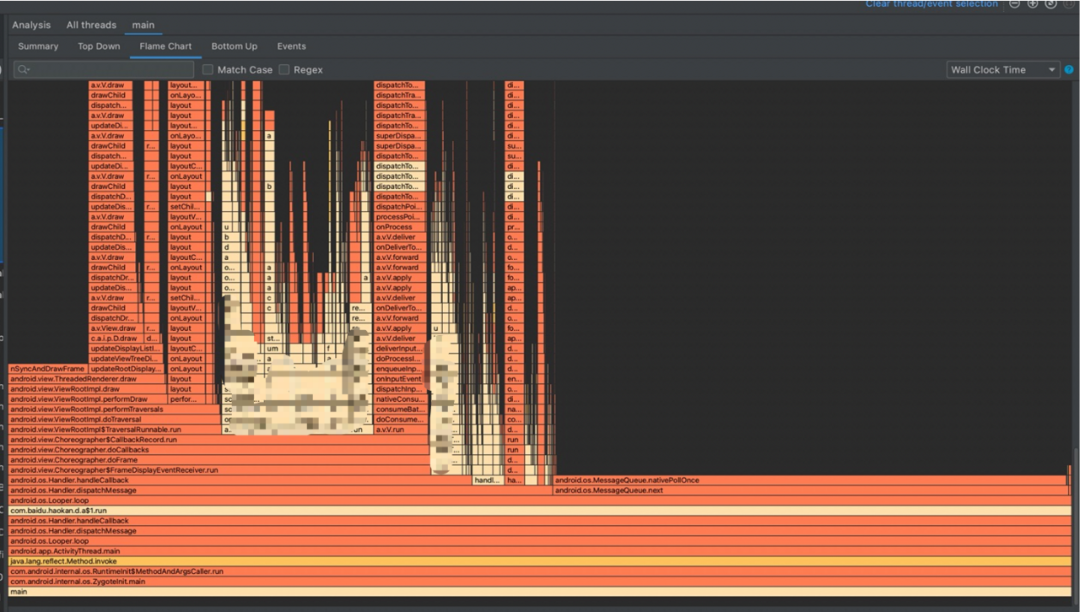
不论是从火焰图,还是从线上统计的掉帧率和业务卡顿、ANR来看,新架构明显具有更优秀的滑动性能和体验。而且即使目前依然耗时的部分,也比较容易修复和缓解。
重构前后的掉帧率对比:
轻微掉帧次数/10分钟 | 严重掉帧次数/10分钟 | |
重构前 | 350 | 77 |
重构后 | 150 | 18 |
关于起播时间的优化
视频起播时间,对于短视频App来说至关重要,如果用户要等待很久的缓冲才能看到视频开始播放,离开App的概率就会增加。在老架构下,单播放器实例会让针对起播时间的专项优化难以实现,而新架构则为此优化提供了架构层面的支持。
1、关于播放器创建的时机
根据RecyclerView的机制,当前视频在播放时,下一个视频的holder会提前调用onBindViewHolder准备页面和数据,所以可以在RecyclerViewHolder的onBind时就初始化下一个待播放视频的播放器。
@Override
public void onBindViewHolder(@NonNull RecyclerView.ViewHolder holder, int position) {
if (holder instanceof ImmersiveBaseHolder) {
((ImmersiveBaseHolder) holder).onBind(getData(position), position);
holder.createPlayer();
}
}
2、关于播放器开始播放(start)的时机
一般情况下,我们会在RecyclerView的onScrollStateChanged中判断列表滑动的状态,当RecyclerView滑动停止时再起播,并结束上一个视频的播放。
mRecyclerView.addOnScrollListener(new RecyclerView.OnScrollListener() {
@Override
public void onScrollStateChanged(RecyclerView recyclerView, int newState) {
if (newState == SCROLL_STATE_SETTLING) {
currentHolder.player.prepareAysnc();
lastHolder.player.stopAndRelease();
}
}
});
这种方式固然可行,但我们能不能把播放器播放的时机再提前呢?
当我们将手指放在屏幕时,View随着手指滑动而上下滑动;当我们松开手指时,PagerSnapHelper会计算要跳转的视频,并根据速度和剩余的滑动距离计算时间,通过SmoothScroller做惯性滚动动画――我们考虑下,如果在松开手指的一刻,换句话说,当我们明确知道了下一个待播放的视频时,就赶紧播放它,会有什么效果?
几乎秒播
从播放器调用prepareAsync到首帧渲染(onInfo的MEDIA_INFO_VIDEO_RENDERING_START回调),大概需要300-500ms,而从手指开屏幕到滑动结束,也接近200-300ms。一般来说,起播速度在200ms左右用户几乎可以认为是”秒开“,所以提前起播对用户体验的提升巨大。
// PagerSnapHelper.java
@Override
protected LinearSmoothScroller createSnapScroller(RecyclerView.LayoutManager layoutManager) {
return new LinearSmoothScroller(mRecyclerView.getContext()) {
@Override
protected void onTargetFound(View targetView, RecyclerView.State state, Action action) {
int nextPosition = state.getTargetScrollPosition();
adapter.getHolder(nextPosition).player.start();
adapter.getHolder(currentPosition).player.stopAndRelease();
}
}
}
// 重点在 onTargetFound 此时已经成功定位被选择的holder
甚至在性能一般的机器上,可以考虑更深层次的优化,在onBindViewHolder中创建播放器后,立即prepare播放器,但不调用start。此类优化需要对播放器的生命周期掌握极其熟练,处理不当很容易导致多个视频同时播放或者其他的隐藏bug,需要格外小心。
3、更早的起播
有同学可能会问,为什么不在holder刚出现在屏幕中的时候就起播呢?比如说在holder的attachToWindow中
这样会导致一个问题,由于起播过早,当屏幕停下来之后,视频已经播放了1-2s,对用户来说体验会很奇怪,永远看不到完整的短视频,体验非但没有变好,反而更差。
但这个思路并不是毫无用处,他适用于一种特殊格式的视频流:对于feed中出现有直播流的情况。提前起播直播流(假设是flv或者rtmp),但不播放直播的声音,等到滑动结束后再开始播放直播的声音,效果就很赞。直播的特点在于,用户不需要从第一帧看起,而且直播的起播往往比短视频要慢,提前起播对于直播来说是十分完美的解决方案,这个思路也是很多App的实现方式。
关于新架构的整体收益
从开发效率上来说,普遍的主观反映,提高了最少20%的开发效率,代码更加好找,”历史包袱“也少了很多。
从技术指标上来看,用户感知的起播时间大幅提高了150ms,网络不差的情况下基本能做到视频秒开;而且后续的优化也更简单,我们也在持续不断的优化每个细节。
从业务指标上看,留存率,人均播放视频数,使用时?等指标均有不同程度的上涨,商业化收益也有所上涨,业务收益十分明显。
四、浅谈播放器预加载
所谓”预加载“,指的是提前下载好一定长度的视频,当要播放该视频的时候,播放器只需要下载一小部分,甚至可以直接立即起播。
1、关于预加载的文件大小问题
加载太少,完全失去了秒开的效果;加载太多,对带宽来说又是一种浪费(当然,如果用户十分活跃,滑动意愿强,可以预加载好完整的下一个视频),一般来说,300K-500K是一个常见的选择。
$pip install qtfaststart
$qtfaststart -l 曾经的你.mp4
ftyp (32 bytes)
moov (6891 bytes)
free (8 bytes)
mdat (3244183 bytes)
对于普通长度的短视频来说,300K可以包含几帧的数据,如上图所示,文件头占了不到100K,我们再看看帧的情况。
$ffprobe 曾经的你.mp4 -show_frames | grep -E 'pict_type|coded_picture_number|pkt_size'
pkt_size=28604
pict_type=I
coded_picture_number=0
pkt_size=145
pkt_size=479
pkt_size=568
pict_type=B
coded_picture_number=3
pkt_size=476
pkt_size=531
pkt_size=1224
pict_type=B
coded_picture_number=2
pkt_size=703
视频的第一帧是关键帧I帧,大约占了30K,B和P帧体积相对较小,所以不难估计300K可以渲染不少帧数,基本满足我们的需求;如果视频较长或者码率较大,预加载长度应当适度增加,最佳方案是后端转码端提前计算好数据,端上根据这个建议值来加载对应的大小。
大多数播放器为了播放流畅度和音视频同步的需要,本地都会有一个缓冲buffer,有的逻辑是按照帧数设置,比如说20帧,也有的是根据时间来设置,比如1-2秒,并不一定300K就一定能起播,需要本地测试具体数值,必要时需要修改播放器内核的配置。大部分情况下,好看的视频在300K时,自研的播放器能够顺利起播。
2、关于预加载的时机问题
预加载时机如果太晚,几乎没有效果;如果太早,可能会跟当前正在播放的视频抢夺宝贵的带宽资源,可能会导致起播速度收益递减,甚至造成严重的卡顿。想象一下,如果我们快速滑动ABC三个视频,此时AB视频正在预加载,正在播放的C视频,C下面的D也在预加载,C的起播时间不但不会降低,反而还会提升!
我们必须要遵守一个原则:视频预加载绝对不能影响到当前视频的播放。一个简单的方案就是,当前视频缓冲到一定比例,再进行下个视频的预加载。当然还有更加细致的方案,比如说动态计算当前已缓冲的进度(onBufferingUpdate回调)和播放进度(getCurrentPosition),如果当前已经缓冲好的时间足够支撑到后续播放,就可以提前开启下个视频的预加载;当前视频如果已经完播(onComplete回调),则可以放心大胆的对下个视频加载更多长度。
另外,**在视频被滑走之后,播放器和预加载应当立即停止,释放无用带宽;**否则,在网络抖动的情况下,预加载的竞争会显著加剧卡顿。
好看视频新架构逐渐放量之后,播放卡顿率提高不少。我们经过紧急排查,将怀疑的对象放到了视频预加载策略上。重新梳理确定了预加载的细节后,卡顿率下降到之前水平,且用户感知起播时间也没有蜕化,收效很大。
3、关于预加载库AndroidVideoCache
https://github.com/danikula/AndroidVideoCache
这个库近些年不再更新,bug很多,issue也不少,不适于在生产环境,但不失为学习预加载库设计和实现的好资源,该库的设计验证了一个计算机界的箴言:
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。
Any Problem in computer science can be sovled by another layer of indircetion.
VideoCache作为播放器和远端资源(CDN)的中间层,一方面从远端缓存视频到本地,一方面本机又开启了一个server,响应来自播放器的请求。
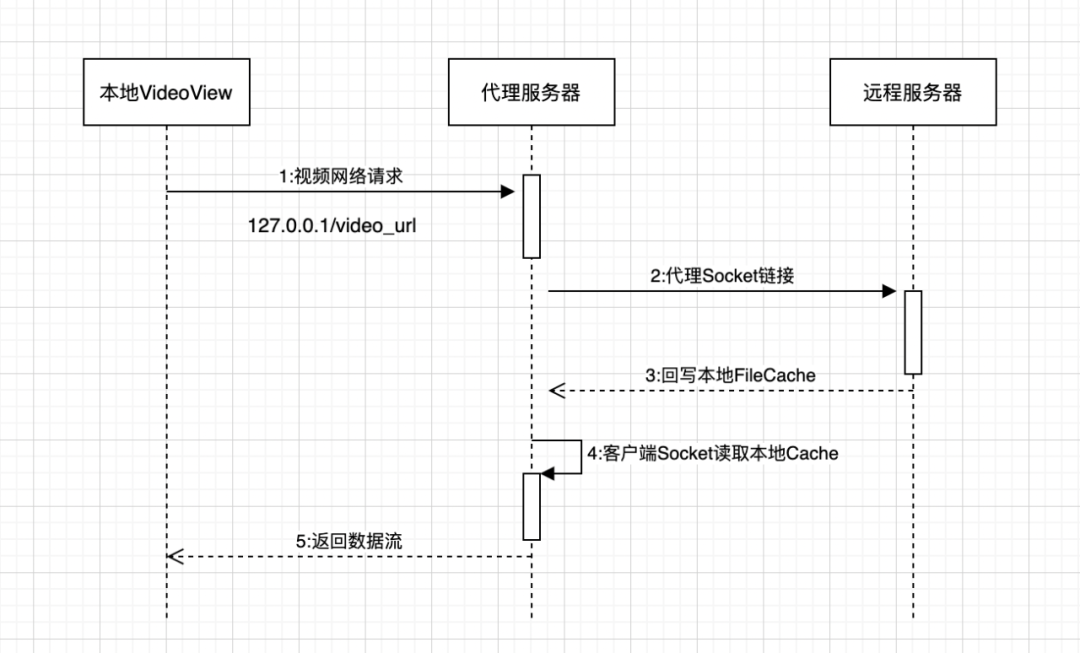
但这个库原本并不支持预加载固定数的字节,只支持全部下载,我们可以先简单的实现一下部分预加载的功能。
// in HttpProxyCacheServer.java
static final int PRELOAD_CACHE_SIZE = 300 * 1024;
public void preload(Context context, String url, int preloadSize) {
socketProcessor.submit(new PreloadProcessorRunnable(url, preloadSize));
}
private final class PreloadProcessorRunnable implements Runnable {
private final String url;
private int preloadSize = PRELOAD_CACHE_SIZE;
public PreloadProcessorRunnable(String url, int preloadSize) {
this.url = url;
this.preloadSize = preloadSize;
}
@Override
public void run() {
processPreload(url, preloadSize);
}
}
private void processPreload(String url, int preloadSize) {
try {
HttpProxyCacheServerClients clients = getClients(url);
clients.processPreload(preloadSize);
clientsMap.remove(url);
} catch (ProxyCacheException | IOException e) {
e.printStackTrace();
}
}
public void stopPreload(String url) {
try {
HttpProxyCacheServerClients clients = getClientsWithoutNew(url);
if(clients != null) {
clients.shutdown();
}
} catch (ProxyCacheException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
// HttpProxyCacheServerClients.java
public void processPreload(int preloadSize) throws ProxyCacheException, IOException {
startProcessRequest();
try {
clientsCount.incrementAndGet();
proxyCache.processPreload(preloadSize);
} finally {
finishProcessRequest();
ProxyLogUtil.d(TAG, "processPreload finishProcessRequest");
}
}
// HttpProxyCache.java
public void processPreload(int preloadSize) throws IOException, ProxyCacheException {
long cacheAvailable = cache.available();
if (cacheAvailable < preloadSize) {
byte[] buffer = new byte[DEFAULT_BUFFER_SIZE];
int readBytes;
long offset = cacheAvailable;
while ((readBytes = read(buffer, offset, buffer.length)) != -1) {
offset += readBytes;
if (offset > preloadSize) break;
}
ProxyLogUtil.d(TAG, "preloaded url = " + source.getUrl() + ", offset = " + offset + ", preloadSize = " + preloadSize);
}
}
// 仅供学习使用,不适用生产环境
这样一来,我们就有了比较基础的预加载(preload)和取消预加载(stopPreload)功能, 本身这个库的实现并不复杂,有时间和人力完全可以自己开发一套适合自己业务的基础库。
最近“端智能”概念很火,相比于预估点击率(ctr)等尝试增强推荐效果的各种想法,基于播放器的预加载的策略调优,可能是端智能最容易落地的方向。反证来看,前者如果有收益,那完全可以移植到推荐和算法端。后者理论上可以做到真正的“多快好省”:在显著提高用户感知的起播速度基础上,保证不退化卡顿,还不会因为预加载增加太多的带宽资源。
五、浅谈播放器卡顿
对于播放场景较多的App来说,在ANR和卡顿数据里,播放器必定占据一席之地。以ijkplayer为例,release函数耗时明显,甚至通过抓trace都能看到。

播放器的创建和销毁都是耗时的操作,很容易将主线程阻塞住,导致App卡顿甚至ANR。最直观的解决方案就是将release函数放到子线程执行,效果立竿见影;但如果是日活百万以上的应用,会新增不少SIGABRT等native错误,crash率提高很多。原因也很简单,同一个播放器,主线程和子线程同时操作player必然存在线程冲突问题;某个线程已经release了播放器,另外的线程还在不断调用播放器的接口。
1 long ijkmp_get_duration(IjkMediaPlayer *mp)
2 {
3 assert(mp);
4 pthread_mutex_lock(&mp->mutex);
5 long retval = ijkmp_get_duration_l(mp);
6 pthread_mutex_unlock(&mp->mutex);
7 return retval;
8 }
通过addr2line或者ndk-stack定位到有大量崩溃发生在第5行,mp为空指针导致crash。这个不难猜测,既然App没有crash在第3行的assert语句而崩溃在了后面,说明必定发生了在这把锁控制之外的线程问题。一个简单的解决方案是再次加入判空处理,但此方案依然不能完全杜绝crash。
static long ijkmp_get_duration_l(IjkMediaPlayer *mp)
{
if (mp == NULL) {
return 0;
}
return ffp_get_duration_l(mp->ffplayer);
}
// NOTICE: 此方案仍存在线程冲突问题
想要完全解决,一个更优雅的方案是:
1、将同一个播放器的所有操作,包括创建和销毁等都放在同一个子线程,建议放在一个HandlerThread中;
2、业务侧单独增加变量isPlayerReleased,在播放器销毁之前将此变量置为true,后面对播放器的所有操作都要直接忽略;
需要注意的是,除了业务侧主动调用播放器之外,ijkplayer本身也有一个线程在操作内核,播放器本身会周期性的主动回调给业务。
// in https://github.com/bilibili/ijkplayer/blob/master/android/ijkplayer/ijkplayer-java/src/main/java/tv/danmaku/ijk/media/player/IjkMediaPlayer.java
private static class EventHandler extends Handler {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MEDIA_PREPARED:
player.notifyOnPrepared();
return;
case MEDIA_PLAYBACK_COMPLETE:
player.stayAwake(false);
player.notifyOnCompletion();
return;
case MEDIA_BUFFERING_UPDATE:
long bufferPosition = msg.arg1;
if (bufferPosition < 0) {
bufferPosition = 0;
}
...
此处也需要加入isPlayerReleased控制,在重新编译播放器内核之后,线上跟播放器相关的crash几乎消失
六、架构、性能优化的意义
大规模的性能优化,能显著提高应用的用户体验,进一步会提高业务的核心指标,尤其对于用户增长和商业变现更有裨益。单纯的技术性指标,比如冷启动速度和滑动流畅度,并不能让所有人信服,但如果我们能将之转化为业务指标的增益,认可度就会大大提高。比如说,启动速度的优化往往会带来留存率的提升,流畅度的优化可能会提高消费类指标;既然技术服务于业务,那技术很可能也能够通过数据来证明自己的收益。如果我们负责的是电商App,可能会提高订单转化率千分之一;如果我们负责的是信息流资讯App,可能会提高人均观看视频个数、图文feed阅读量、使用时长,甚至还有可能因为展现和消费以及使用时长上涨,直接提高商业化收入。
所以我们不妨先把技术放在一旁,先把自己当做产品经理,以普通的业务迭代需求来替代技术优化来思考。我们精心设计AB实验,在代码中主动加入AB实验开关,盯紧AB实验后台,随时查看用户反馈,带着业务数据汇报收益。师出有名,我们就算不能证明用户体验明显变好,起码也能证明没有变得更差。一旦我们让技术优化的收益深入人心,即使是小型的优化也立即有了存在的正当理由。
当然,并不是所有的优化都适合AB实验,如果业务迭代十分频繁,优化又不能在短时间内完成,等待我们的将是无穷和无情的代码冲突。”大胆假设,小心求证“,只要有了合适机会,我们就应该设计AB实验并时刻盯紧AB实验大盘看数据,无论是对业务RD还是性能RD,或者架构RD。
推荐阅读:
---------- END ----------
百度Geek说
百度官方技术公众号上线啦!
技术干货 ・ 行业资讯 ・ 线上沙龙 ・ 行业大会
招聘信息 ・ 内推信息 ・ 技术书籍 ・ 百度周边
欢迎各位同学关注